机器之心&ArXiv Weekly Radiostation
参与:杜伟,楚航,罗若天
本周的重要论文有谷歌大脑与普林斯顿大学等机构提出的超越 Adam 的二阶梯度优化以及 DeepMind 研究者提出的直接建模网格的新模型 PolyGen。
CausalML: Python Package for Causal Machine Learning
Replacing Mobile Camera ISP with a Single Deep Learning Model
Second Order Optimization Made Practical
PolyGen: An Autoregressive Generative Model of 3D Meshes
The DIDI Dataset: Digital Ink Diagram Data
Deflecting Adversarial Attacks
A Primer in BERTology: What we know about how BERT works
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)。
论文 1:
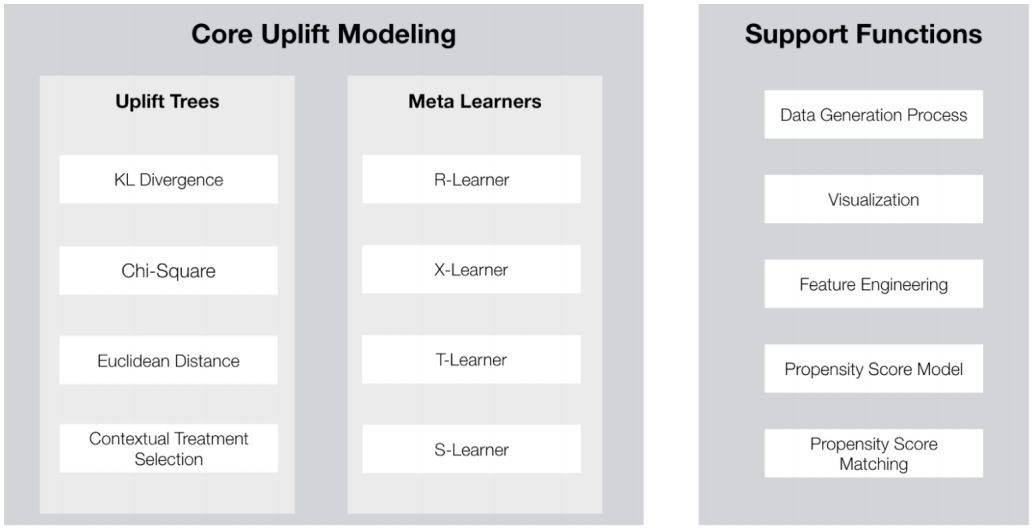
CausalML: Python Package for Causal Machine Learning
摘要:
在本文中,来自 Uber 的研究者推出了
针对因果推理和机器学习算法的 Python 实现
。近年来,结合因果推理和机器学习的算法早已成为热门话题。CasualML 包通过该领域一系列方法的 Python 实现,力图缩小方法论理论研究与实际应用之间的差距。
本文着重介绍了 CasualML 包的核心概念、应用范围和应用实例。此外,研究者计划将来添加更多 SOTA 增益模型,并探索更多融合机器学习与因果推理的建模方法以解决优化问题。
![]()
推荐:
Uber 推出的 CausalML 包能够解决
目标优化、因果关系影响分析和个性化
等问题。
论文 2:
Replacing Mobile Camera ISP with a Single Deep Learning Model
摘要:
移动端的成像的分辨率和质量从 2000 年开始持续地发展着。在 2010 年后,当移动端设备变得性能更好之后,重图像信号处理(ISP)系统也得到了显著的提升。现代的移动端 ISP 系统相对负载,包含了多个低层级和全局性的图像处理任务,包括图像去马赛克、白平衡和曝光矫正、降噪和锐化、色彩和伽马补正等。但是硬件对于移动摄像头的限制依然存在:较小的传感器和紧凑的镜头使得图像失去很多细节、噪声很高,生成的色彩也很一般。
经典的 ISP 系统依然无法完全解决这些问题,因此在优化的过程中,软件会尝试通过平滑化图像或采用「水彩效应」的方式隐藏问题——这些方法都应用在了现在的旗舰设备上。通过深度学习模型有可能解决这些问题,而且模型可以被部署在 NPU 或 AI 芯片上,从而应用于智能手机中。虽然如此,移动端 ISP 系统的应用韩式局限于场景分类或亮光图像的后处理上。
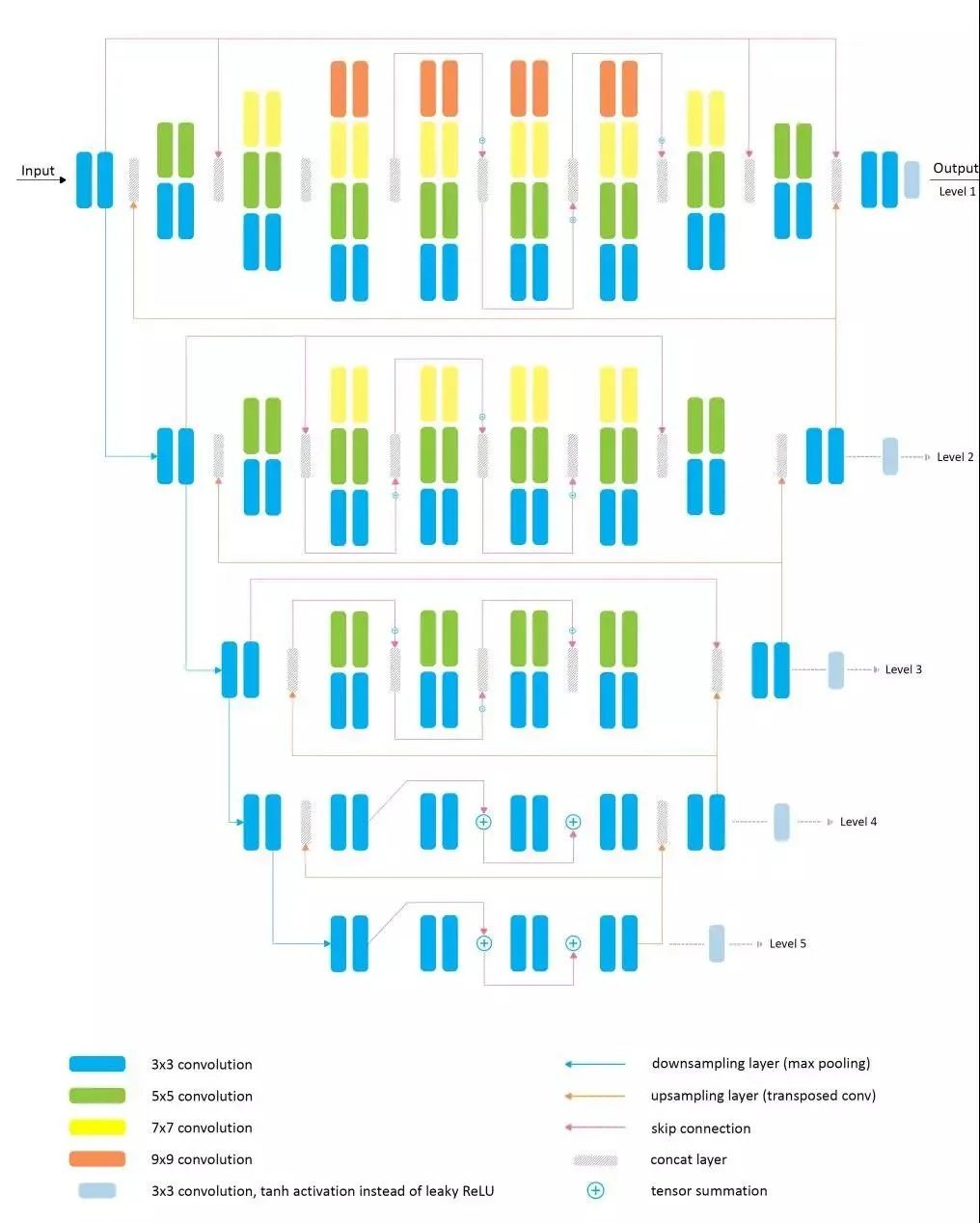
在本文中,来自苏黎世理工的研究者则提出了一个名为 PyNET 的新算法,可以
学习到整个 ISP 的 pipeline,并且这个算法只需要一个深度学习模型
。为了完成这个任务,这个框架被学习用来从传感器信息来绘制 RAW Bayer 数据,并生成目标高质量的 RGB 图像。其本质上能够包含所有的细粒度图像修改步骤。
![]()
![]()
研究者用 PyNET 模型得到的重建图像示例,发现这与华为 ISP 得到的图像质量非常接近,虽然二者在色彩和质地上都不如 Canon 5D DSLR。
![]()
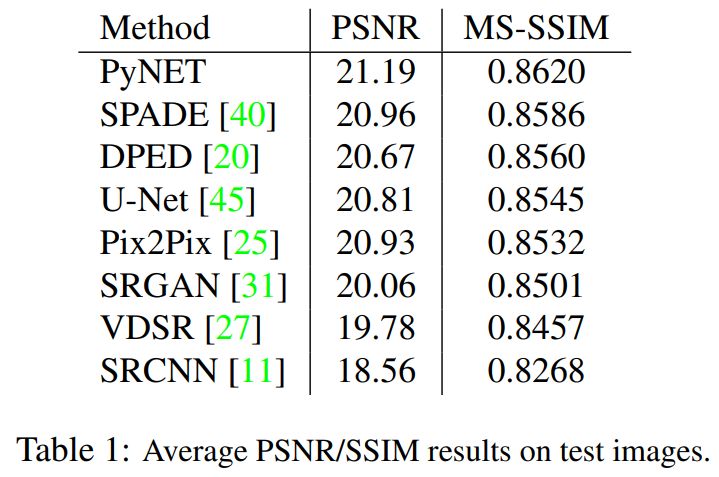
研究者针对 PyNET 和其他深度学习方法进行了定量评估,其 PSNR(峰值信噪比)和 MS-SSIM 结果如上。可以看出 PyNET 在两项指标上都高于其他深度学习模型。
推荐:
在本文中,研究者
利用 PyNET 模型得到的重建图像可以轻松达到华为 P20 ISP 的水平,甚至可以媲美佳能单
反,在定量评估、用户评估和与其他手机的对比中都有出色的表现。
论文 3:
Second Order Optimization Made Practical
摘要:
目前,无论是从理论还是应用层面来说,机器学习中的优化都是以随机梯度下降等一阶梯度方法为主。囊括二阶梯度和/或二阶数据统计的二阶优化方法虽然理论基础更强,但受限于计算量、内存和通信花销等因素,二阶梯度优化方法的普及度不高。然而在
谷歌大脑与普林斯顿大学等
研究者的努力下,二阶梯度优化终于在实战大模型上展现出独特的优势。
研究者表示,为了缩短理论和实际优化效果之间的差距,该论文提出了一种
二阶优化的概念性验证,并通过一系列重要的算法与数值计算提升,证明它在实际深度模型中能有非常大的提升
。具体而言,在训练深度模型过程中,二阶梯度优化 Shampoo 能高效利用由多核 CPU 和多加速器单元组成的异构硬件架构。并且在大规模机器翻译、图像识别等领域实现了非常优越的性能,要比现有的顶尖一阶梯度下降方法还要好。
![]()
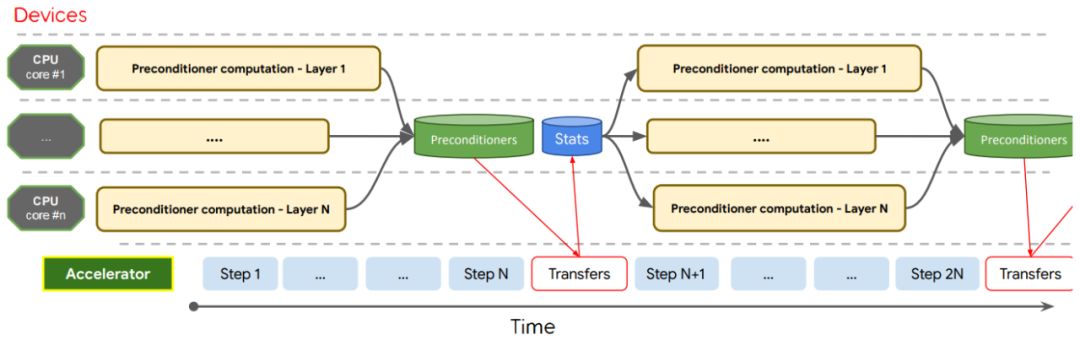
本文优化算法设计的时间轴。在每一步上计算所有张量的预调节器统计数据。预调节器只在每 N 步上计算,并且计算会分配给训练系统上可用的所有 CPU 核心。运算进行流水线处理,这样就实现了开销均摊。
![]()
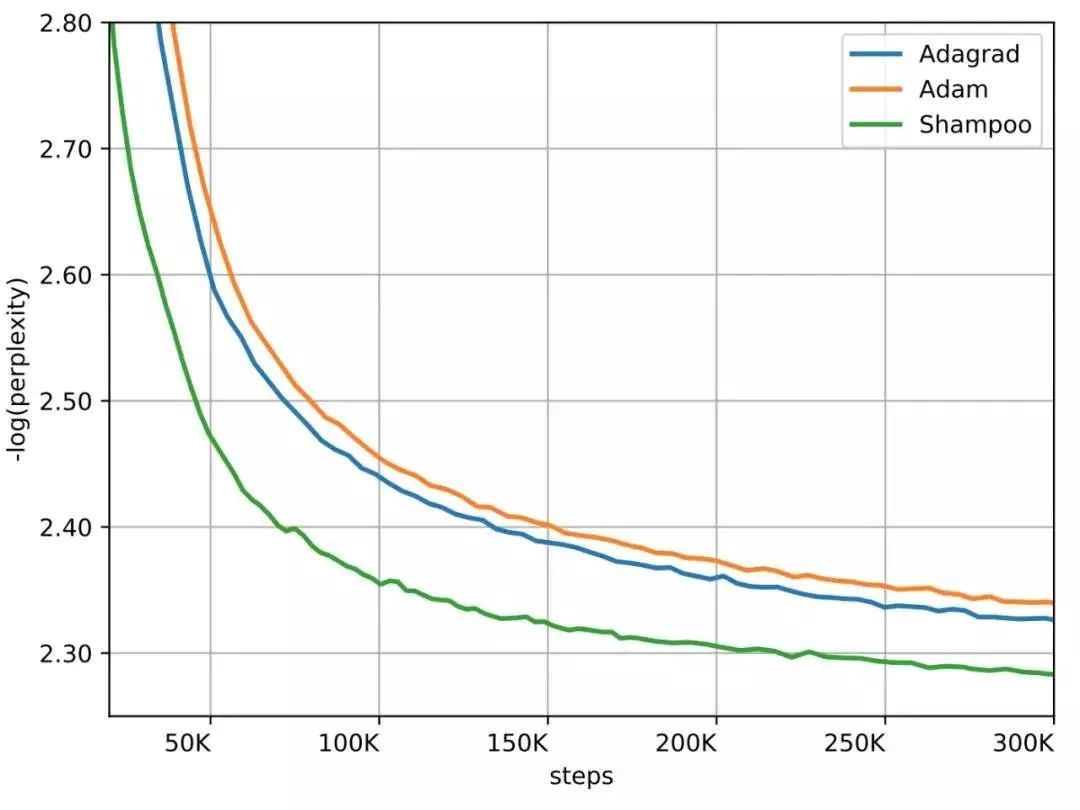
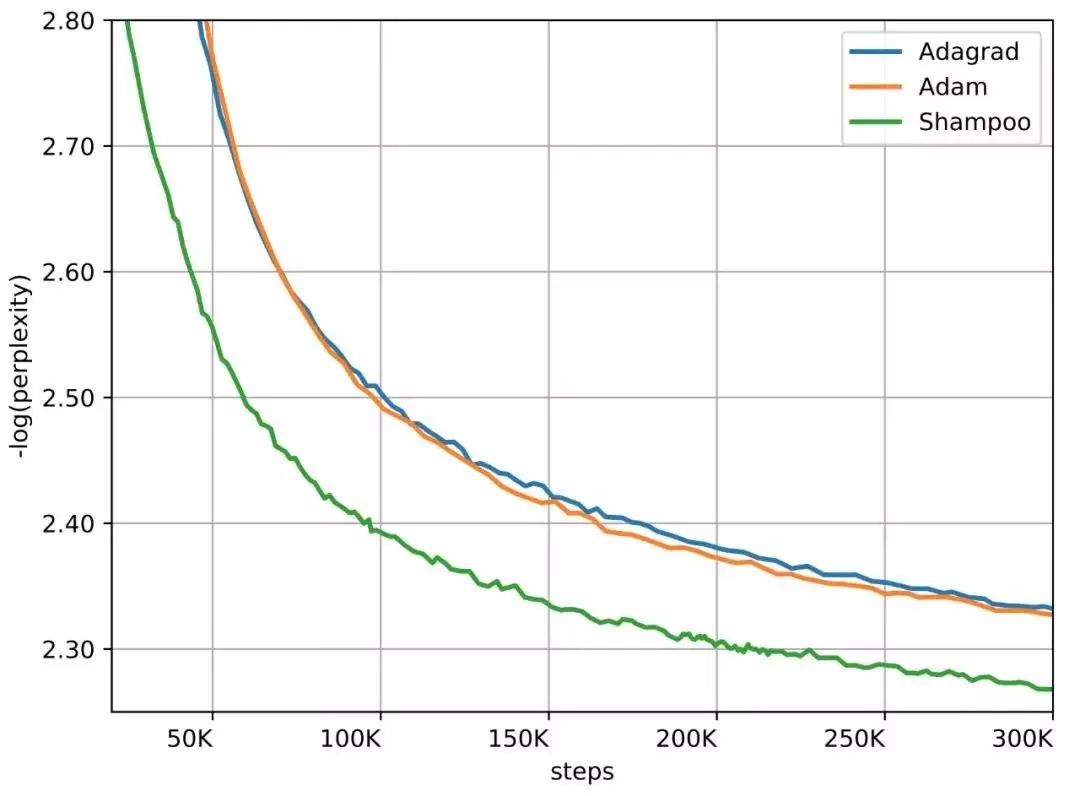
WMT'14 英法翻译数据集上的 Transformer 模型,Shampoo 二阶梯度算法的收敛速度在迭代数上快了 1.95 倍,且就算要计算二阶梯度,每一次迭代也只慢了 16%,总体上来说节省了 40% 的执行时间。
![]()
WMT'14 英法翻译数据集上的 Transformer-Big 模型,Shampoo 二阶梯度算法的收敛速度在迭代数上快了 2 倍,且就算要计算二阶梯度,每一次迭代也只慢了 40%,总体上来说节省了 30% 的执行时间。
推荐:
本文的亮点在于研究者提出了
真正应用的二阶梯度最优化器
,在实战大模型上展现出独特的优势。
论文 4:
PolyGen: An Autoregressive Generative Model of 3D Meshes
摘要:
在本文中,来自 DeepMind 的研究者提出了一种
直接建模网格的方法 PolyGen
,该方法利用 Transformer 架构来循序地预测网格的顶点和表面。文中提出的 3D 网格深度生成模型 PolyGen 以对象类、三维像素和图像等一系列输入为条件,同时由于该模型是概率性的,因此它可以生成捕获模糊场景中不确定性的样本。
实验表明,该模型能够生成高质量、可用的网格,并为网格建模任务创建对数似然基准。研究者表示,
PolyGen 模型能够生成连贯的、多样化的 3D 网格,并且相信可以扩展该模型在计算机视觉、机器人学和 3D 内容创建中的应用
。
![]()
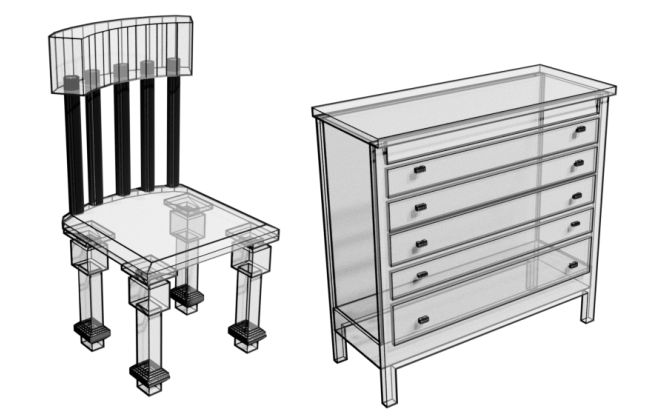
由 PolyGen 模型生成的类条件 N 边形效果展示图。
![]()
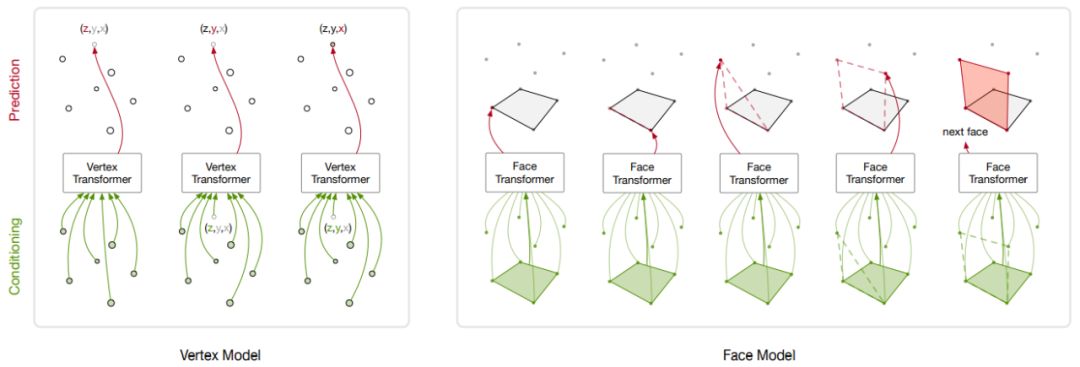
PolyGen 模型首先生成网格顶点(左),然后生成以这些顶点为先决条件的网格表面(右)。
纵轴上顶点由最低至最高循序地生成。
为了生成下个顶点,当前序列的顶点坐标作为语境传递给下个顶点 Transformer,它又为下个顶点坐标输出一个预测分布。
表面模型以一组顶点和当前序列的表面索引作为输入,同时输出一个顶点索引上的分布。
推荐:
本文的亮点在于,研究者将网格生成问题作为自回归序列建模来处理,同时
结合了 Transformers 和指针网络的优势
,从而能够灵活地建模长度可变的网格序列。
论文 5:THE DIDI DATASET: DIGITAL INK DIAGRAM DATA
摘要:
在本文中,来自
谷歌研究院和苏黎世联邦理工学院
的研究者发布了一个具有动态图样信息的在线图纸绘制数据集,它是通过收集提示数据(prompted data)获得。通过结合机器学习与人类计算机交互技术,本研究旨在促进交互式图形符号理解。
![]()
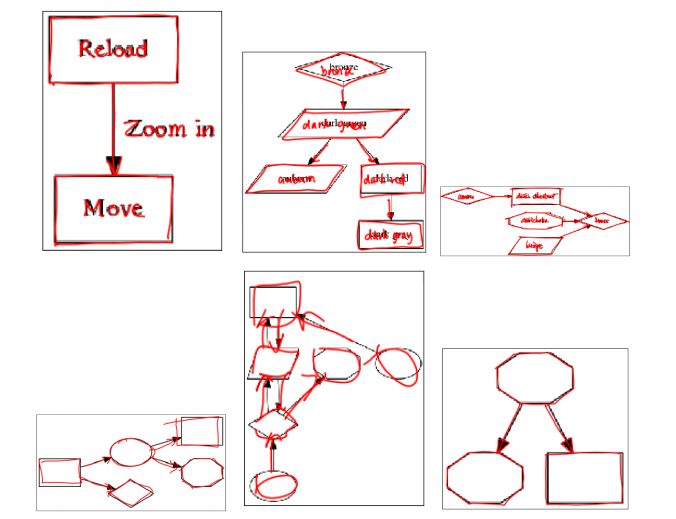
上面三张图的文本内容被各自的提示图像覆盖,下面三张图则没有文本内容被提示图像覆盖。
![]()
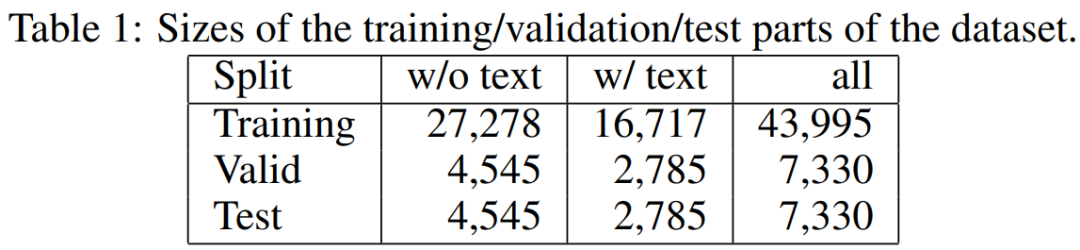
文中数据集的 2/8 数据用于验证和测试,剩余的 6/8 数据用于训练。
推荐:
研究者认为机器学习与人机交互二者对实际的图表创建和编辑而言至关重要,所以
发布此数据集旨在增强学术界对机器学习与人机交互结合的研究兴趣
。
论文 6:
Deflecting Adversarial Attacks
摘要:
在本文中,来自加州大学圣迭戈分校和谷歌大脑的研究者提出了一种
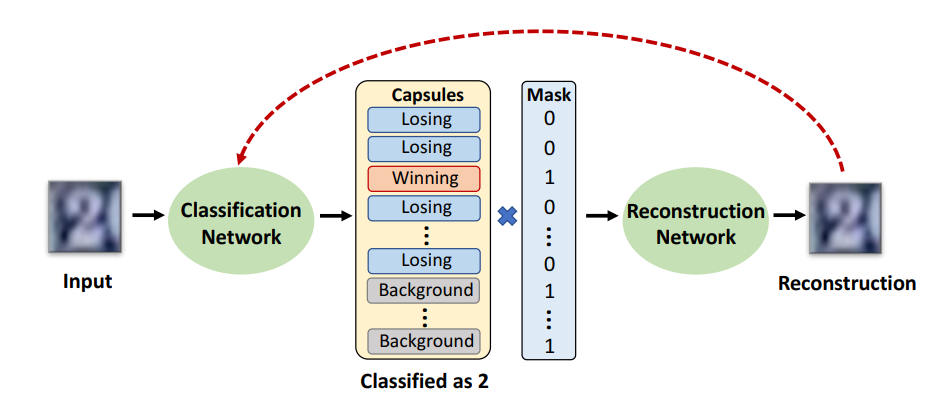
基于胶囊层的网络和检测机制
,它可以精确地检测到攻击,对于未检测到的攻击,它通常也可以迫使攻击者生成类似于目标类的图像(从而使它们偏转)。该网络结构由两部分组成:对输入进行分类的胶囊分类网络,以及根据预测的胶囊的姿态参数重建输入图像的重建网络。
此外,基于获胜胶囊重建的正负输入之间的差异,研究者还提出了两种新的攻击不可知的检测方法。实验证明,基于 SVHN 和 CIFAR-10 数据集上的三个不同的失真度量、CW 和 PGD,该方法可以
准确地检测白盒和黑箱攻
击。
![]()
推荐:
本文入选 ICLR 2020 论文,
与深度学习大佬 Geoffrey Hinton 合著完成
,论文一作 Yao Qin 现为谷歌大脑研究科学家。
论文 7:
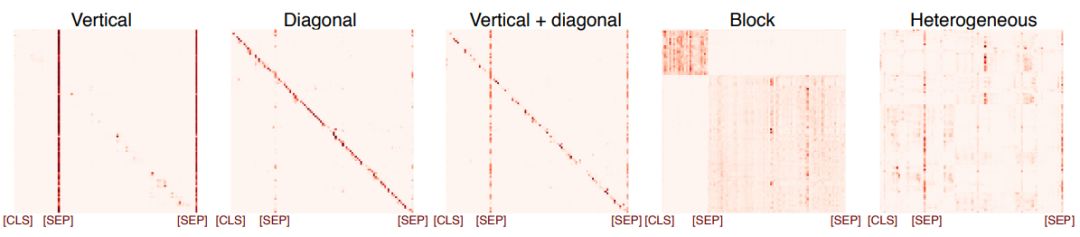
A Primer in BERTology: What we know about how BERT works
摘要:
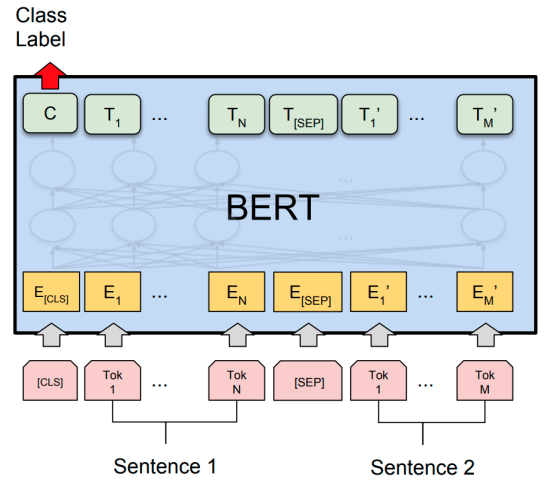
目前,基于 Transformer 的模型已经广泛应用于自然语言处理中,但我们依然对这些模型的内部工作机制知之甚少。在本文中,来自麻省大学洛威尔分校的研究者
对流行的 BERT 模型进行综述,并综合分析了 40 多项分析研
究。他们还概览了对模型和训练机制提出的改进,然后描画了未来的研究方向。
![]()
![]()
![]()
推荐:
本文作者希望这篇 BERT 综述论文能够
激发社区更多地关注那些尚未解决的重大研究课题
。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Differentiable Reasoning over a Virtual Knowledge Base. (from Bhuwan Dhingra, Manzil Zaheer, Vidhisha Balachandran, Graham Neubig, Ruslan Salakhutdinov, William W. Cohen)
2. Unsupervised Question Decomposition for Question Answering. (from Ethan Perez, Patrick Lewis, Wen-tau Yih, Kyunghyun Cho, Douwe Kiela)
3. Efficient Sentence Embedding via Semantic Subspace Analysis. (from Bin Wang, Fenxiao Chen, Yuncheng Wang, C.-C. Jay Kuo)
4. CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset. (from Qi Zhu, Kaili Huang, Zheng Zhang, Xiaoyan Zhu, Minlie Huang)
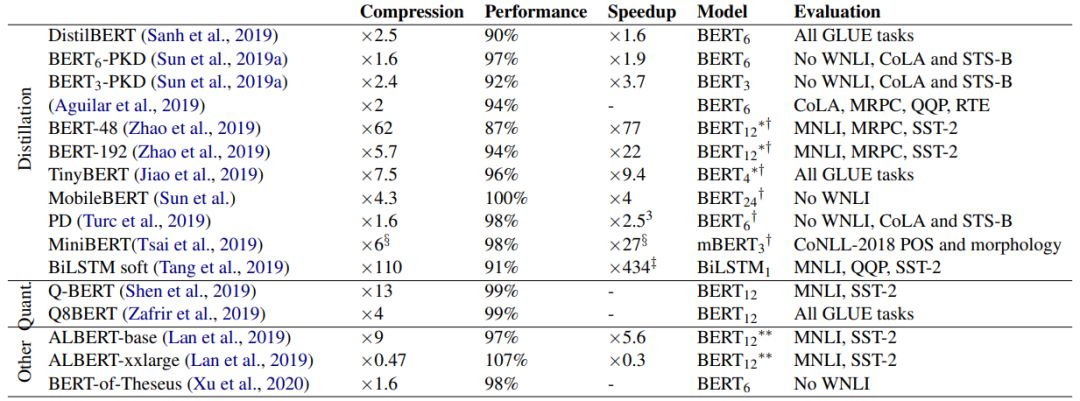
5. Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers. (from Zhuohan Li, Eric Wallace, Sheng Shen, Kevin Lin, Kurt Keutzer, Dan Klein, Joseph E. Gonzalez)
6. Few-shot Natural Language Generation for Task-Oriented Dialog. (from Baolin Peng, Chenguang Zhu, Chunyuan Li, Xiujun Li, Jinchao Li, Michael Zeng, Jianfeng Gao)
7. Integrating Boundary Assembling into a DNN Framework for Named Entity Recognition in Chinese Social Media Text. (from Zhaoheng Gong, Ping Chen, Jiang Zhou)
8. Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games. (from Ashutosh Adhikari, Xingdi Yuan, Marc-Alexandre Côté, Mikuláš Zelinka, Marc-Antoine Rondeau, Romain Laroche, Pascal Poupart, Jian Tang, Adam Trischler, William L. Hamilton)
9. Do Multi-Hop Question Answering Systems Know How to Answer the Single-Hop Sub-Questions?. (from Yixuan Tang, Hwee Tou Ng, Anthony K.H. Tung)
10. BERT Can See Out of the Box: On the Cross-modal Transferability of Text Representations. (from Thomas Scialom, Patrick Bordes, Paul-Alexis Dray, Jacopo Staiano, Patrick Gallinari)
1. Towards Universal Representation Learning for Deep Face Recognition. (from Yichun Shi, Xiang Yu, Kihyuk Sohn, Manmohan Chandraker, Anil K. Jain)
2. Kullback-Leibler Divergence-Based Fuzzy $C$-Means Clustering Incorporating Morphological Reconstruction and Wavelet Frames for Image Segmentation. (from Cong Wang, Witold Pedrycz, ZhiWu Li, MengChu Zhou)
3. Joint Unsupervised Learning of Optical Flow and Egomotion with Bi-Level Optimization. (from Shihao Jiang, Dylan Campbell, Miaomiao Liu, Stephen Gould, Richard Hartley)
4. Mnemonics Training: Multi-Class Incremental Learning without Forgetting. (from Yaoyao Liu, An-An Liu, Yuting Su, Bernt Schiele, Qianru Sun)
5. Are Gabor Kernels Optimal for Iris Recognition?. (from Aidan Boyd, Adam Czajka, Kevin Bowyer)
6. Robust Iris Presentation Attack Detection Fusing 2D and 3D Information. (from Zhaoyuan Fang, Adam Czajka, Kevin W. Bowyer)
7. GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation. (from Wallace Lira, Johannes Merz, Daniel Ritchie, Daniel Cohen-Or, Hao Zhang)
8. Temporal Sparse Adversarial Attack on Gait Recognition. (from Ziwen He, Wei Wang, Jing Dong, Tieniu Tan)
9. Fast Loop Closure Detection via Binary Content. (from Han Wang, Juncheng Li, Maopeng Ran, Lihua Xie)
10. Toward fast and accurate human pose estimation via soft-gated skip connections. (from Adrian Bulat, Jean Kossaifi, Georgios Tzimiropoulos, Maja Pantic)
1. Provable Meta-Learning of Linear Representations. (from Nilesh Tripuraneni, Chi Jin, Michael I. Jordan)
2. On Thompson Sampling with Langevin Algorithms. (from Eric Mazumdar, Aldo Pacchiano, Yi-an Ma, Peter L. Bartlett, Michael I. Jordan)
3. Robust Optimization for Fairness with Noisy Protected Groups. (from Serena Wang, Wenshuo Guo, Harikrishna Narasimhan, Andrew Cotter, Maya Gupta, Michael I. Jordan)
4. Simultaneously Evolving Deep Reinforcement Learning Models using Multifactorial Optimization. (from Aritz D. Martinez, Eneko Osaba, Javier Del Ser, Francisco Herrera)
5. Enhanced Adversarial Strategically-Timed Attacks against Deep Reinforcement Learning. (from Chao-Han Huck Yang, Jun Qi, Pin-Yu Chen, Yi Ouyang, I-Te Danny Hung, Chin-Hui Lee, Xiaoli Ma)
6. Rewriting History with Inverse RL: Hindsight Inference for Policy Improvement. (from Benjamin Eysenbach, Xinyang Geng, Sergey Levine, Ruslan Salakhutdinov)
7. Representation Learning Through Latent Canonicalizations. (from Or Litany, Ari Morcos, Srinath Sridhar, Leonidas Guibas, Judy Hoffman)
8. Learning to Simulate Complex Physics with Graph Networks. (from Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, Peter W. Battaglia)
9. On Feature Normalization and Data Augmentation. (from Boyi Li, Felix Wu, Ser-Nam Lim, Serge Belongie, Kilian Q. Weinberger)
10. Bridging the Gap between Spatial and Spectral Domains: A Survey on Graph Neural Networks. (from Zhiqian Chen, Fanglan Chen, Lei Zhang, Taoran Ji, Kaiqun Fu, Liang Zhao, Feng Chen, Chang-Tien Lu)
![]()