IJCAI 2018 | 让CNN跑得更快,腾讯优图提出全局和动态过滤器剪枝
选自IJCAI
作者:Shaohui Lin、Rongrong Ji、Feiyue Huang 等
机器之心编译
参与:panda
网络剪枝是一种加速 CNN 的常用方法。厦门大学和腾讯优图的一项研究提出了一种全新的全局和动态过滤器剪枝方法,能够实现更好的剪枝效果且具有更好的适应性。该论文已被将于当地时间 7 月 13-19 日于瑞典斯德哥尔摩举办的 IJCAI-18 接收。
在 ICML 2018 与 IJCAI 2018 大会期间(今年都在斯德哥尔摩),腾讯将举办 Tencent Academic and Industrial Conference (TAIC),诚邀全球顶尖 AI 学者、青年研究员与腾讯七大事业群专家团队探讨最前沿 AI 研究与应用。
1 引言
卷积神经网络(CNN)已经在多种不同应用中取得了显著的成功,其中包括图像分类 [He et al., 2016; Krizhevsky et al., 2012; Simonyan and Zisserman, 2014]、目标检测 [Girshick et al., 2014] 和形义分割 [Long et al., 2015]。但是,这样出色的表现也伴随着显著的计算成本——如果没有高效的图形处理器(GPU)的支持,将这些 CNN 部署到实时应用中会非常困难。因此,卷积网络加速已经成为了一大新兴研究方向。
在卷积神经网络加速方面的近期研究工作可分为三大类,即:低秩分解、参数量化和网络剪枝。其中,网络剪枝得到的研究关注正越来越大,由于这种方法的过滤器参数和中间激活较少(轻内存的在线推理非常需要这一点),所以有内存占用量小的优势。
网络剪枝方法又可以进一步被分为非结构化剪枝和结构化剪枝两类。
非结构化剪枝 [LeCun et al., 1989; Hassibi and Stork, 1993; Han et al., 2015a; 2015b] 的目标是直接对每一层的参数单独剪枝,这会导致出现不规则的内存访问情况,从而对在线推理的效率产生不利影响,在这种情况下,通常还需要设计专用硬件 [Han et al., 2016] 或软件 [Liu et al., 2015; Park et al., 2017] 来进一步加速被剪枝的非结构化 CNN。
结构化剪枝 [Anwar et al., 2015; Lebedev and Lempitsky, 2016; Wen et al., 2016; Li et al., 2016; Luo et al., 2017; Molchanov et al., 2017; Hu et al., 2016] 的目标则是直接以整体形式移除过滤器。这种方法的效率会高很多,而且不需要专用硬件或软件平台。比如,Anwar 等研究者 [Anwar et al., 2015] 为过滤器方面和通道方面的卷积过滤器选择引入了结构化的稀疏性,并基于此通过使用粒子滤波(particle filtering)来根据规则性剪枝过滤器。Luo 等人 [Luo et al., 2017] 隐含地将当前层中的卷积过滤器与下一层中的输入通道关联到了一起,并基于此通过下一层的输入通道选择来对当前层中的过滤器进行剪枝。
但是,现有的结构化剪枝方案都是以一种逐层固定的方式来剪枝卷积神经网络,这种方式的适应性更差、效率更低且效果也更差。首先,在局部剪枝中,需要迭代式的层方面的剪枝和局部的微调,这需要密集的计算。第二,对显著过滤器的错误剪枝是不可恢复的,这没有适应性而且剪枝后的网络不能得到最优表现。
在这篇论文中,我们提出了一种全新的全局和动态剪枝(GDP:global & dynamic pruning)方案,可以剪枝掉冗余的过滤器来解决上述两个问题,这能很大程度地加速剪枝后的网络,同时还能降低网络的准确度损失。
不同于之前的逐层固定过滤器剪枝方案,我们的关键创新是在所有网络层上全局地评估各个过滤器的重要度/显著性,然后在此基础上动态地和迭代地剪枝和调整网络,并且还带有重新调用在之前的迭代中被错误剪枝的过滤器的机制。图 1 展示了我们提出的框架的流程图。
我们首先初始化一个预训练的卷积网络,然后给所有过滤器施加一个全局掩模并使之等于 1(即确定对应过滤器是否被剪枝的外部开关。然后,我们设计一个全局判别函数来决定各个过滤器的显著性分数。这种分数能引导我们以全局的方式剪枝所有层上不显著的过滤器,即等价于将不显著的过滤器的掩模设为 0。最后,我们迭代式地调整这个稀疏网络并且以一种自上而下的方式动态地更新过滤器显著性。通过这样的操作,之前被掩蔽的过滤器还有重新被调用的可能,这能显著提升被剪枝后网络的准确度。在优化方面,GDP 可以被描述成一个非凸优化问题,然后可以使用贪婪的交替更新方法通过随机梯度下降有效求解。
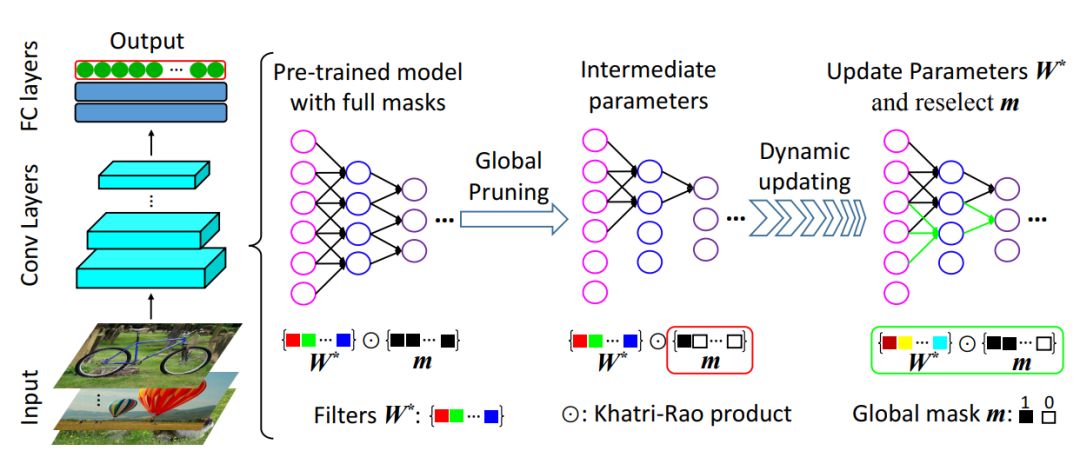
图 1:GDP 的图示。每个有颜色的矩形(比如红色矩形)都是过滤器集合 W∗ 中的一个过滤器,具有二元值的全局掩模 m 决定了过滤器的显著性(即表示对应的过滤器是显著的或不显著的)。首先,我们使用一个预训练的模型和一个完全全局掩模来初始化网络。然后,通过将冗余过滤器对应的掩模的值设为 0 来在所有层上以全局的方式将它们剪枝掉。最后,执行过滤器和全局掩模的迭代式动态更新,从而提升剪枝后网络的准确度。
我们在 ImageNet 2012 数据集 [Russakovsky et al., 2015] 上评估了新提出的 GDP,并且基于被广泛使用 AlexNet [Krizhevsky et al., 2012]、VGG-16 [Simonyan and Zisserman, 2014] 和 ResNet-50 [He et al., 2016] 实现了它。通过对比之前最佳的过滤器剪枝方法 [Wen et al., 2016; Li et al., 2016; Luo et al., 2017; Molchanov et al., 2017; Hu et al., 2016],结果表明新提出的 GDP 方案能得到更优的表现:在 AlexNet 上以 1.15% 的 Top-5 准确度损失实现了 2.12 倍的 GPU 加速,在 VGG-16 上以 1.45% 的 Top-5 准确度损失实现了 2.17 倍的 CPU 加速,在 ResNet-50 上以 2.16% 的 Top-5 准确度损失实现了 1.93 倍的 CPU 加速。
3 全局式动态剪枝
3.1 符号标记方法
CNN 可被看作是一种将输入图像映射成某个输出向量的前馈式多层架构。在 CNN 中,最耗时的部分是卷积层。让我们将第 l 层中的图像特征图集合表示为 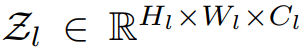
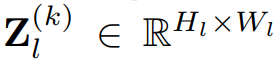
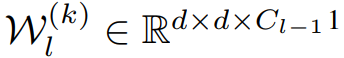
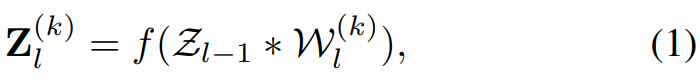
其中 f(*) 是一个非线性激活函数,比如修正线性单元(ReLU)。
在 Caffe [Jia et al., 2014] 和 TensorFlow [Abadi et al., 2016] 等很多深度学习框架中,基于张量的卷积算子通过降低输入和重新构造过滤器的形状而被重新形式化为了一种矩阵乘矩阵的乘法,比如:
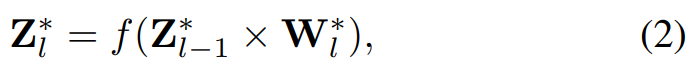
其中,矩阵 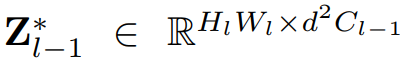
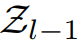
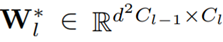
3.2 新提出的剪枝方案

算法 1:我们提出的全局式动态剪枝方案
我们的目标是以全局的方式剪枝冗余的过滤器。为此,可以直接将大型网络转换成紧凑的网络,而不重复地评估每个过滤器的显著性和逐层微调剪枝后的网络。我们引入了一种全局掩模,以在训练过程的每次迭代中临时掩蔽不显著的过滤器。基于此,公式 (2) 可改写为:
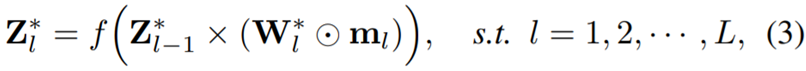
其中 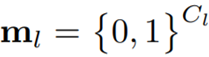
正如我们说过的,以一种不可恢复/固定的方式剪枝过滤器在实践中不够灵活且效果很差,这会给网络表现水平带来严重损失。注意,因为过滤器之间存在复杂的互连,所以过滤器显著性可以会在剪枝了特定的层后发生很大的变化 [Guo et al., 2016]。因此,动态剪枝(即从一种全局角度实现被掩蔽的过滤器的回滚)在提升剪枝后网络的可判别性(discriminability)方面有很高的需求。
为了更好地描述新提出的 GDP 的目标函数,我们将整个网络的过滤器表示为 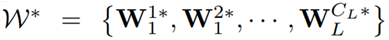
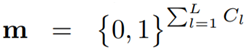
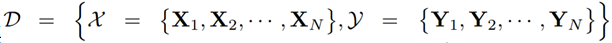
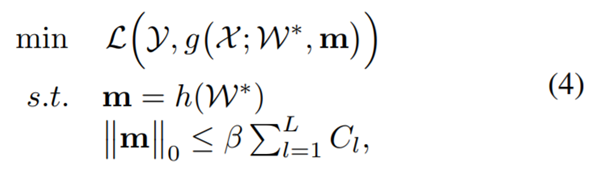
其中 L(·) 是被剪枝网络的损失函数,比如交叉熵损失。g(X; W*, m) 的输入为 X;具有过滤器 W* 和全局掩模 m,并使用它们将输入映射成一个 s 维的输出(s 是类别数)。h(·) 是用于决定过滤器的显著性值的全局判别函数,这取决于 W* 的预先知识。函数 h(·) 的输出是二元的,即如果对应的过滤器是显著的,则输出 1,否则输出 0。
(4) 式是我们的 GDP 框架的核心函数,这是非凸的,其求解方法将在 3.3 节介绍。β ∈ (0, 1] 是一个决定被剪枝网络的稀疏度的阈值。因为有 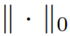
4 实验
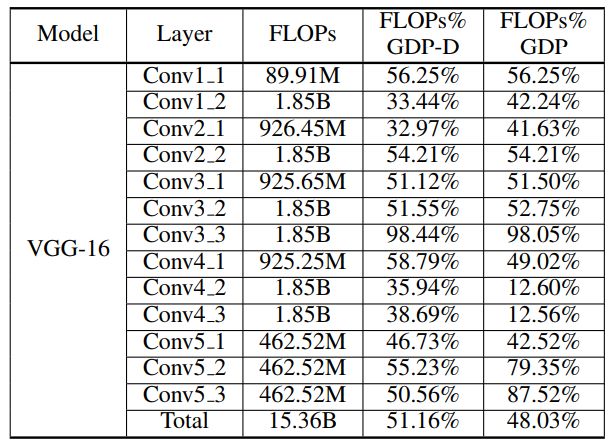
表 1:GDP 和 GDP-D(没有动态更新的全局剪枝)的 FLOPs 比较,其中 β 设为 0.7。FLOPs% 是指剩余的 FLOPs 所占的百分比。
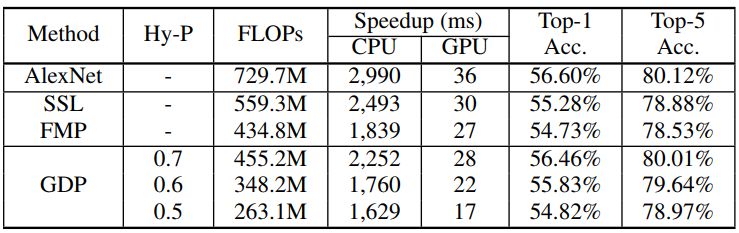
表 2:用于加速 AlexNet 的不同剪枝方法比较。Hy-P 表示超参数设置,批大小为 32(下面的表格都一样)
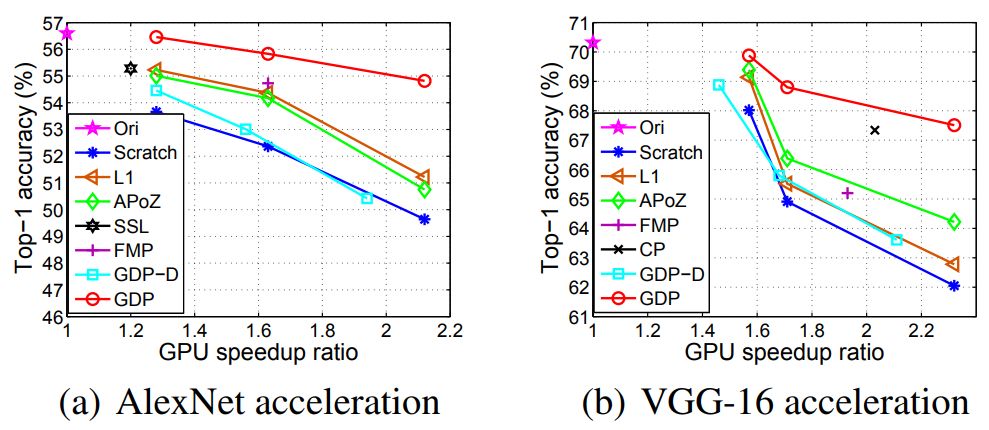
图 2:在加速 AlexNet 和 VGG-16 方面不同过滤器选择方案的比较。Scratch 表示从头开始训练的网络,Ori 表示原始 CNN,GDP-D 表示没有动态更新的全局剪枝。
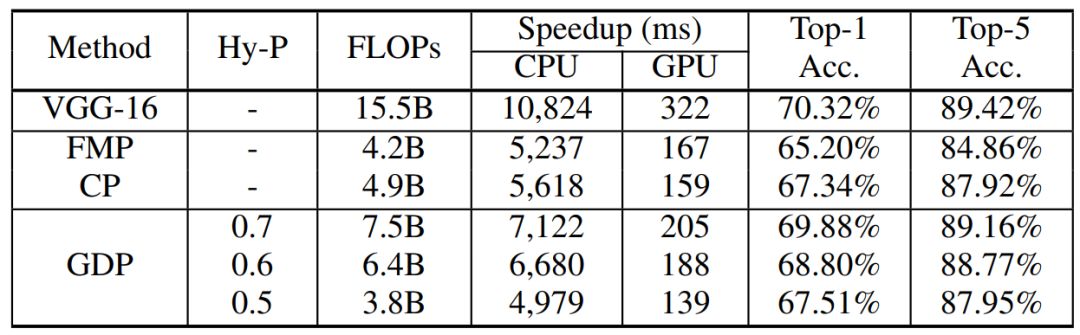
表 3:加速 VGG-16 的结果。
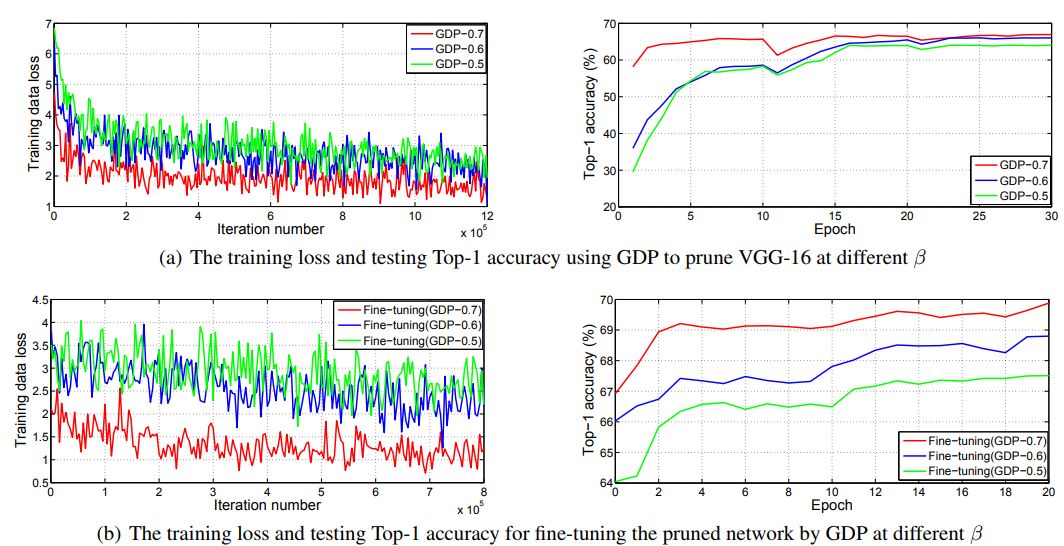
图 3:使用 GDP 方案剪枝 VGG-16 时采用不同 β 值的结果比较。(a) 使用 GDP 方案剪枝 VGG-16 时采用不同 β 值的训练损失和 Top-1 测试准确度;(b) 使用不同 β 值的 GDP 剪枝后的网络在微调后的训练损失和 Top-1 测试准确度。
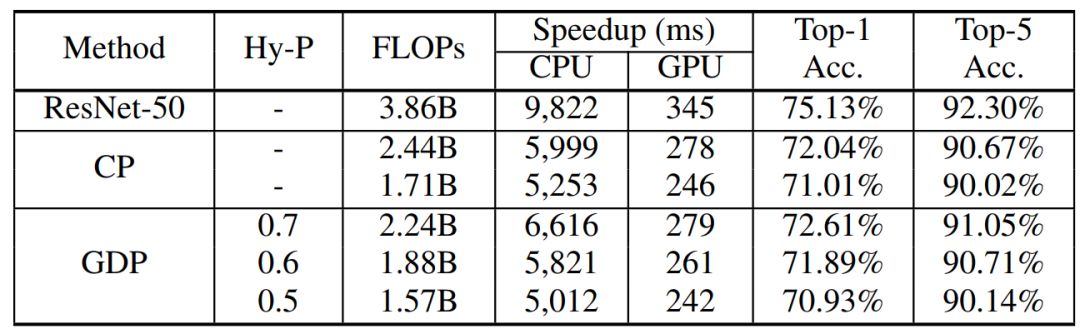
表 4:加速 ResNet-50 的结果。

图 4:在 VGG-16 的第一层上动态地更新过滤器、掩模和输出特征图。左:过滤器和掩模;右:输出特征图。在左列中,每个矩形都包含了过滤器和掩模,其中黑色框表示掩模没改变,红色框表示过滤器和掩模更新了。另外,其中仅有黑白两色的小矩形表示对应的过滤器是否显著,■ 表示显著,□ 表示不显著。在右列中,对应改变的特征图用红色框标出。
论文:通过全部和动态过滤器剪枝加速卷积网络(Accelerating Convolutional Networks via Global & Dynamic Filter Pruning)

论文地址:https://www.ijcai.org/proceedings/2018/0336.pdf
卷积神经网络加速近来得到了越来越多的研究关注。在文献中提出的各种方法中,过滤器剪枝一直都被视为一种有潜力的解决方案,这主要是由于其在网络模型和中间的特征图上都有显著的加速和降低内存的优势。为了做到这一点,大多数方法都倾向于以一种逐层固定的方式剪枝过滤器,这种方式无法动态地恢复之前被移除的过滤器,也不能在所有层上联合优化被剪枝的网络。在这篇论文中,我们提出了一种全新的全局和动态剪枝(GDP)方案,可剪枝冗余的过滤器,从而实现 CNN 加速。尤其值得提及的是,我们提出了一种基于每个过滤器的预先知识的全局判别函数,让 GDP 成了首个在所有层上全局地剪枝不显著过滤器的方法。另外,它还能在整个剪枝后的稀疏网络上动态地更新过滤器的显著性,然后恢复被错误剪枝的过滤器,之后再通过一个再训练阶段来提升模型准确度。特别要指出,我们通过使用贪婪的交替更新的随机梯度下降而有效地解决了新提出的 GDP 对应的非凸优化问题。我们进行了大量实验,结果表明,相比于之前最佳的过滤器剪枝方法,我们提出的方法在 ILSVRC 2012 基准的多种前沿 CNN 的加速上表现更优。

当地时间 7 月 14 日,腾讯将在斯德哥尔摩举办 Tencent Academic and Industrial Conference (TAIC),诚邀全球顶尖 AI 学者、青年研究员与腾讯七大事业群专家团队探讨最前沿 AI 研究与应用。点击阅读原文,参与报名。




