吴恩达学生Awni Hannun:图文演示如何用CTC进行序列建模(下)
Inference
训练好模型后,我们就需要根据给定输入计算可能的输出,更准确地说,我们需要计算:
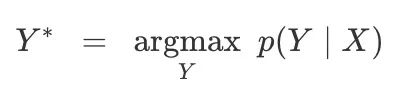
一种启发式方法是根据每个时间步长计算路径的可能性,它能计算最高概率:
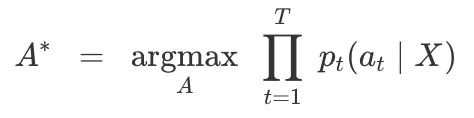
之后,我们反复collapse并删除空白标记ϵ得到Y。
这种启发式方法对于大多数程序都运行良好,尤其是当概率集中于某条路径时。但是,由于没有考虑到单个输出可能有多个对齐的事实,它有时也会错过真正的高概率输出。
对此我可以举个例子。假设输出[a, a, ϵ]和[a, a, a]的概率比[b,b,b]低,但它们的概率之和高于后者。在这种情况下,启发式方法会给出Y=[b]这样的错误结论,因为它忽视了[a, a, ϵ]和[a, a, a]可以折叠为一个输出,而真正的答案应该是Y=[a]。
对于这个问题,我们可以通过修改集束搜索来解决。鉴于有限的计算,集束搜索并不能真正找到Y,但它至少能通过更多计算帮助我们更好地权衡路径性质,从而最大限度地接近最好的解。
常规的集束搜索算法会在每个输入中计算一组假设路径。这组假设基于原路径集合产生,通过扩展路径,算法会选择其中得分最高的几种路径作为当前路径。
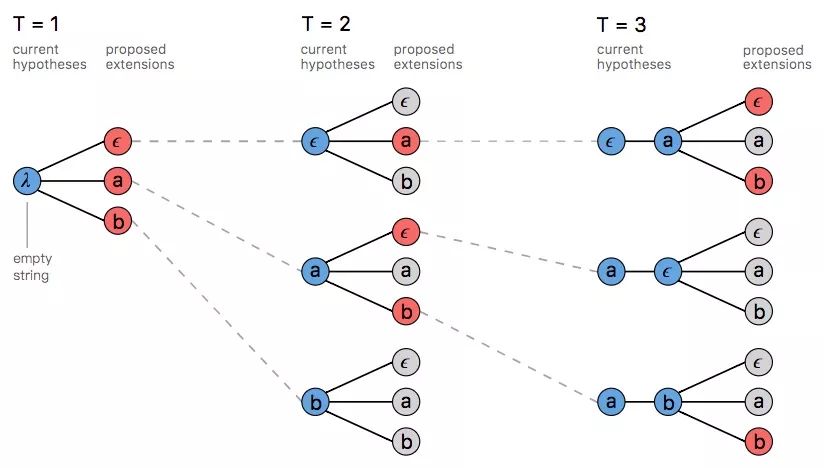
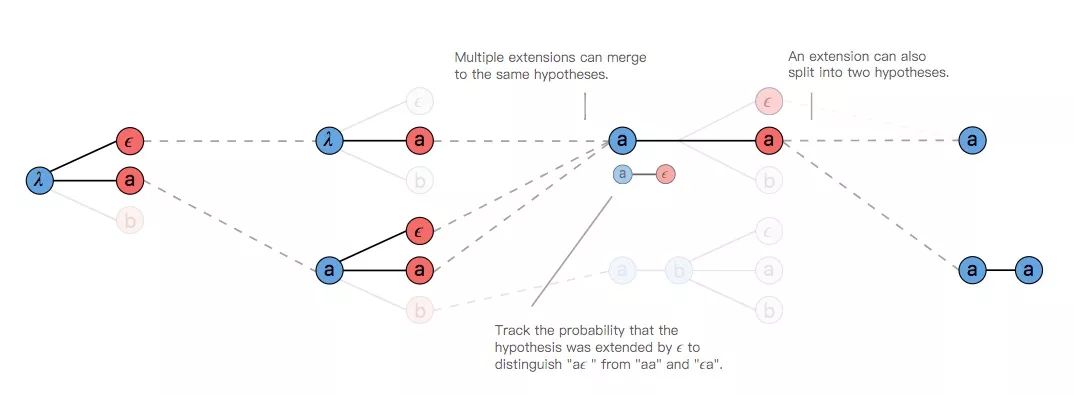
如果要处理多条路径映射到同一输出这种情况,我们可以修改vanilla集束搜索,即不保留束中的对齐列表,而是折叠重复字符并去除存储在输出中的ϵ。在搜索的每一步,我们都会根据映射到假设的所有路径累计来给定相应分数。
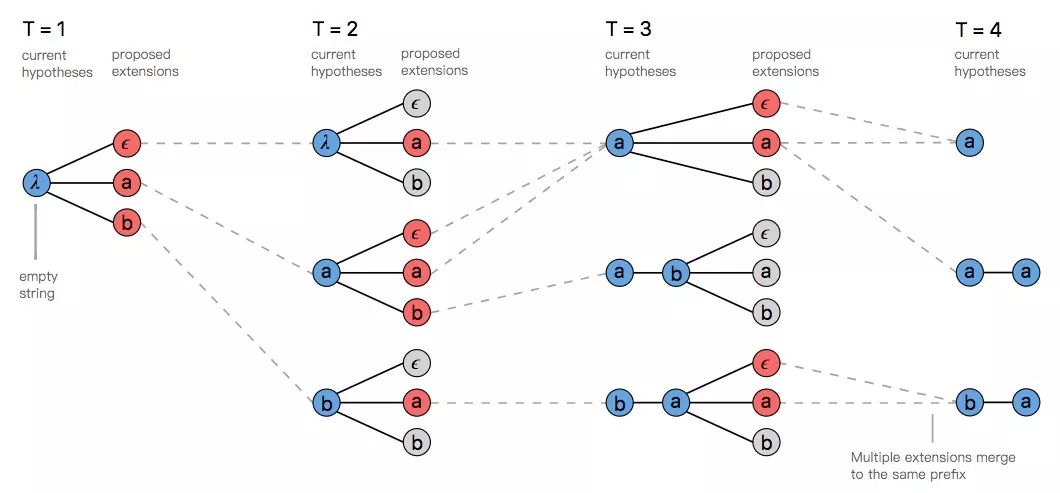
标记出现重复时,集束搜索会提议扩展映射前两个输出,如上图T3所示,其中红‘a’由是蓝[a]的扩展,因此[a]和[a, a]都是有效输出。
当我们将[a]扩展为[a, a]时,我们只需统计之前以空白标记ϵ结尾的所有路径的概率(位于字符中间的ϵ也要统计)。同样的,如果是扩展到[a],那我们计算的就是不以ϵ结尾的所有路径概率。
鉴于此,我们需要跟踪当前输出在搜索树中前两处输出。无论是以ϵ结尾还是不以ϵ结尾,如果我们在剪枝时为每一种假设做好得分排序,我们就能在计算中使用组合分数。
这个算法的实现并不需要太多代码,而且它十分巧妙,我用Python写了一个示例,可访问github查看。
在一些语言识别问题中,也会有人在输出中加入语言模型来提高准确率,所以我们也可以把语言模型作为做inference的一个考虑因素:

L(Y)能通过语言模型标记计算Y的长度,它同时也是插入字符的奖励。如果 L(Y)是一个基于单词的语言模型,那它计数的是Y中的单词数量;如果是一个基于字符的语言模型,那它计数的就是Y中的字符数。语言模型的一个突出特点是它只为单词/字符扩展前的形式计分,不会统计算法每一步扩展时的输出,这一点有利于短前缀词汇的搜索,因为它们在形式上更稳定。
集束搜索可以添加语言模型得分和单词插入项奖励,当提出扩展字符时,我们可以在给定前提下为新字符添加语言模型评分。
CTC属性
到目前为止,我们提到了CTC的一些重要特性,在接下来这个章节中,我们将更深入地了解这些属性及它们带来的影响。
有条件的独立
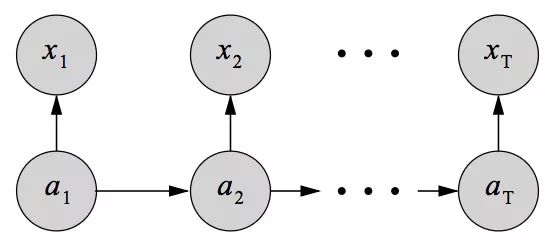
CTC最广为人知的一个缺点是它的有条件的独立性假设。
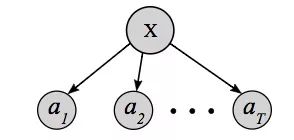
上图是一个CTC模型,可以看到,输入一个X,该模型的每个输出都有条件地独立于其他输出,对于大多数序列排序问题而言,这种假设不是一个好思路。
假如我们有一个音频,内容为“三个A(triple A)”,那么一个有效的转录可能是“AAA”,如果CTC预测转录的第一个字母是‘A’,那下一个字母是‘A’的概率应该远高于‘r’,但是这种有条件的独立性假设不允许CTC这样做。
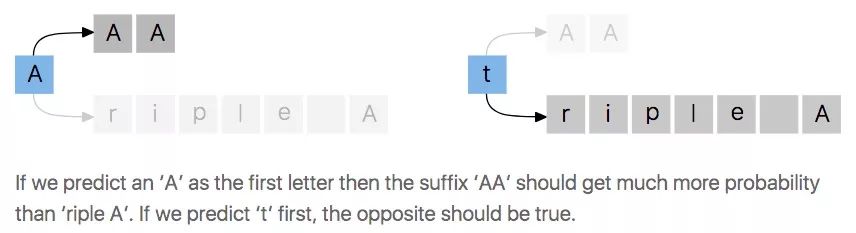
事实上,利用CTC建立的语音识别器并既不能学习输出型语言模型,也不能学习条件依赖型语言模型,它只能通过包含的独立语言模型来提高准确性。
当然,这种假设虽然会产生不小的麻烦,但也不是一无是处,它能使模型迅速适应相互对立的新场景。如果我们用和朋友的通话录音训练识别器生成语音答复信息,由于立场不同,同一模型可能会把语音内容归类为完全不同的两个领域,而CTC的模型可以弥补这一点,它能在立场转换时更换新的语言模型。
对齐属性
CTC算法不要求对齐,目标函数在所有路径上都是边缘化的,虽然它确实对输入X和输出Y之间的对齐规律做了一系列假设,并计算了相关概率,但模型并不知道它们之间的概率分布。在一些问题中,CTC最终会把大部分概率集中到具体某一条路径中。当然,也有例外。
如上文所述,CTC只允许单调对齐,这在语音识别问题中可能是一个有效的假设,但对于机器翻译等其他问题而言,目标语句中的future word可以与其在源语句中的形式相对应,这种单调对齐的假设是不准确的。
CTC的另一个重要特征是输入和输出的关系是多对一。在某些情况下,这种设定并不理想,因为有时我们会希望输入X和输出Y之间是严格的一对一关系,或者一个输入能对应到多个输出。例如,字符‘th’可以对齐到单个音素输入,但CTC不允许这种操作。
多对一的特性意味着输出的时间步长要比输入短,这对于语音识别和手写识别没有太大影响,因为输入会比输出长很多,但在一些Y比X长的问题里,CTC就不奏效了。
CTC和其他算法
在这一节中,我会探讨CTC和其他序列建模算法之间的联系。
HMM模型
乍一看,隐马尔可夫模型(Hidden Markov Model,HMM)似乎和CTC完全不同,但是,它们在本质上还是很相似的。了解它们之间的关系将有助于我们把握CTC在序列建模中的优势,同时掌握在各种情况下调整CTC的方法。
让我们继续沿用之间的符号,X是输入序列,Y是长度从T到U的输出序列,p(Y|X)是输入X后输出为Y的概率。为了计算p(Y|X),我们可以用贝叶斯定理简化这个问题:
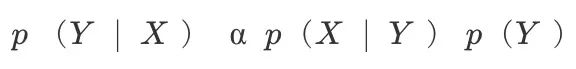
由于p(Y)可以是任何语言模型,让我们把关注点放在p(Y|X)。就像之前做的,我们同样设A为X与Y之间所有路径的集合,路径长度均为T,通过对齐我们可得到:
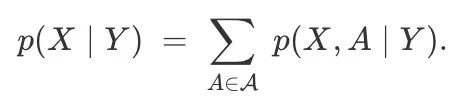
为了简化符号,我们先不考虑Y的条件限制,将其示意为p(·),这样我们就能利用两个假设列出一个标准的HMM:
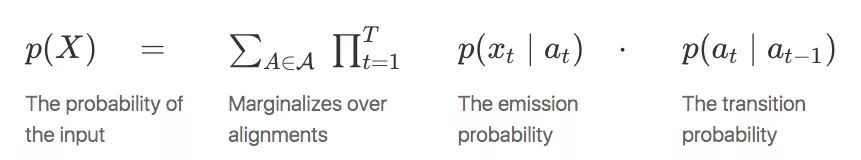
第一个假设具有马尔可夫性质,at独立于扩展前状态at-1;第二个假设则是当输入为at时,xt有条件地独立于其他所有输出。
现在我们只需要几个步骤就可以将HMM转换成CTC,看看这两个模型是如何相关的。首先,我们假设转录概率p(at∣at−1)是统一的,即有:
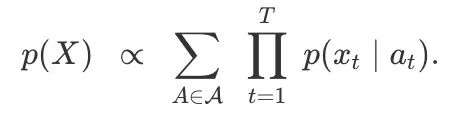
这个算式和CTC计算loss的算式只有两处不同,一是我们需要计算的是模型输入X后输出Y的概率,而不是针对Y计算X;二是如何产生集合A。对于这两个问题,我们依次来解决。
HMM可以用于估算p(a|x)的判别模型,要做到这一点,我们需要应用贝叶斯定理来改写模型:
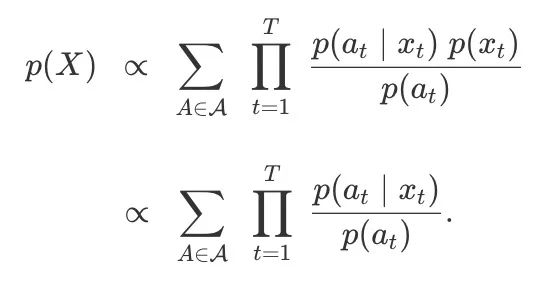
如果设a为X上的所有条件,而不是一个单独的字符,我们可以得到:

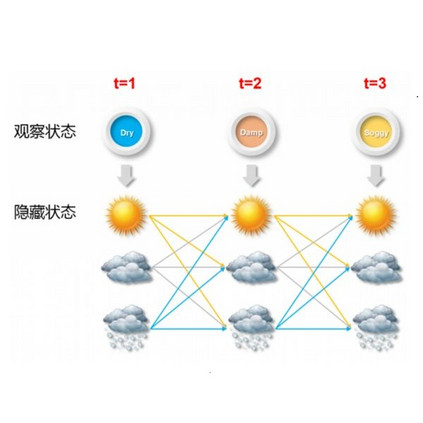
这时等式已经基本和CTC计算loss时一致了,我们可以进一步假设集合A也是一致的。事实上,HMM框架并没有规定A集合该由什么组成,模型的这部分可以根据具体问题进行设计。在很多情况下,可能这个模型并不适合长度为T的路径几何A和序列Y,这时我们就可以把HMM看做一个连接各状态的ergodic转录图,下图展示了模型在输入{ a ,b ,c }后各字符间的“隐状态”。
在我们的例子中,这个模型的转录需要与输出Y强烈相关,所以HMM应当能反映这一点。对此,一个可能的模型是一个简单的线性状态转换图,如下图所示,图中得出的结论是Y= [a, b],另外的常用模型还有Bakis和左右模型。
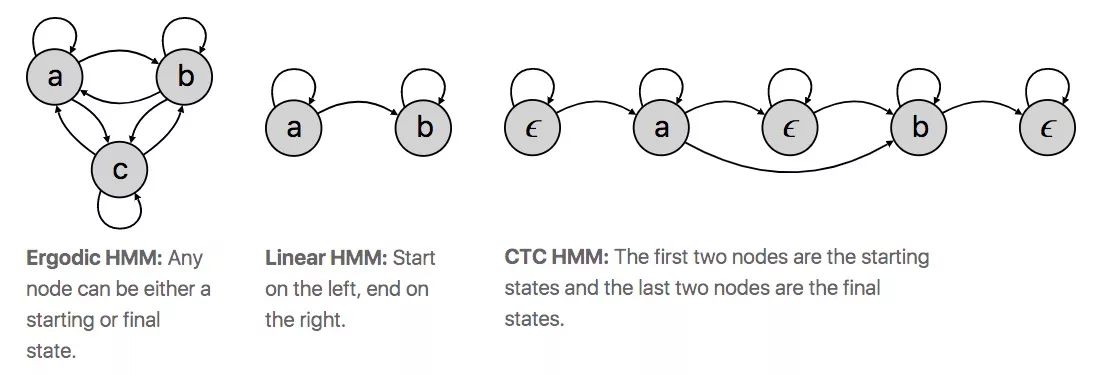
在CTC算法中,我们有空白标记ϵ;而在HMM里,我们有允许交换子集的左右模型。CTC和HMM都有两个起始状态和两个接受状态。
容易造成混淆的一个原因可能是在HMM中,模型会因不同的输出Y而出现差异,事实上,这在语音识别领域是准确的,模型状态图的确会因输出Y出现一定变化。转录过程中的观察预计和概率函数是共享的。
最后就是如何用CTC对原始HMM模型做一些改进。首先,我们可以将CTC状态图看做一个特殊情况下的HMM,可以用来解决很多有趣的问题;因为空白标记可以被作为“隐状态”结合到HMM中,所以我们可以用Y表示其他“隐状态”。在一些问题中,这个模型可以给出一些可行的路径。
当然,也许最重要的是,CTC和HMM还是有一些区别的,它直接为p(X|Y)建模。判别式训练允许我们用RNN等方法解决问题。
Encoder-Decoder模型
Encoder-Decoder(编码-解码)模型可能是利用神经网络进行序列建模最常用的框架,它有一个编码器和一个解码器,其中编码器能把输入序列X映射为隐序列,解码器则消耗隐序列的表示产生输出的概率分配:
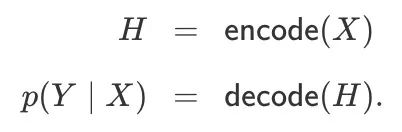
因为encode(⋅)和decode(⋅)具有典型的RNN框架,解码器可以有选择性地配备一个attention mechanism(注意力机制),已知隐序列H长度为T,解码器二次抽样后,H中路径的时间步长会变为T/s。
编码器:CTC模型的编码器可以是常用Encoder-Decoder模型中的任意一种编码器,如,它可以是多层双响卷积网络。当然,它也有一个限制,就是经多次取样的输入长度T/s不能小于输出长度。
解码器:我们可以把CTC模型的解码器视为一种简单的线性变换,然后用softmax归一化。
正如之前提到的,CTC建设输出序列中的字符都是条件性独立的,这是Encoder-Decoder模型应用于CTC的最大优势之一——它们可以模拟对输出的依赖。然而在实践中,CTC在语音识别等任务中仍然比较常用,因为我们可以通过外部语言模型来克服部分假设。
一些实用技巧
现在我们对CTC已经有了概念上的理解,接下来,我会介绍一些从业人员常用的实用技巧。
软件
即便你对CTC有深刻了解,自己写代码实现还是非常困难的,因此,一些开源软件工具必不可少:
warp-ctc。百度的开源软件warp-ctc是用C ++和CUDA编写,它可以在CPU和GPU上运行,支持Torch、TensorFlow和PyTorch。
TensorFlow内置的CTC loss和CTC beam search,可以在CPU上跑;
Nvidia也有一些支持CTC的开源工具,需要cuDNN7.0及以上环境。
数值稳定性
单纯计算CTC loss是很不稳定的,而避免这种情况的一种方面就是在每个时间步长规范α。具体的操作细节可以参考一些教材,那上面还会涉及渐变调整。在具体实践中,对于中等长度的序列,这种方法效果显著,但如果面对的较长的序列,那可以用log-sum-exp计算对数空间中的loss,并用log-sum-exp进行inference。
集束搜索
关于如何使用集束搜索,以下是一些小技巧:
任意输入一个X,然后进行集束搜索;
保存推理得到的输出¯Y及相应分数¯c;
计算¯Y的CTC实际得分c;
检查¯c是否约等于c,且前者是否小于后者。随着集束宽度增加,输出¯Y可能会发生变化,而¯c和c会越来越接近。
使用集束搜索的一个常见问题就是集束宽度大小,它是精度和运行时间之间的一个折衷。
参考文献
Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition Chan, W., Jaitly, N., Le, Q.V. and Vinyals, O., 2016. ICASSP.
Exploring Neural Transducers for End-to-End Speech Recognition Battenberg, E., Chen, J., Child, R., Coates, A., Gaur, Y., Li, Y., Liu, H., Satheesh, S., Seetapun, D., Sriram, A. and Zhu, Z., 2017.
Large scale discriminative training of hidden Markov models for speech recognition Woodland, P. and Povey, D.. Computer Speech & Language, pp. 25--47. Academic Press. DOI: 10.1006/csla.2001.0182
Connectionist Temporal Classification : Labelling Unsegmented Sequence Data with Recurrent Neural Networks Graves, A., Fernandez, S., Gomez, F. and Schmidhuber, J., 2006. Proceedings of the 23rd international conference on Machine Learning, pp. 369--376. DOI: 10.1145/1143844.1143891
Phone recognition on the TIMIT database Lopes, C. and Perdigão, F., 2011. Speech Technologies, Vol 1, pp. 285--302. DOI: 10.5772/17600
……
原文地址:https://distill.pub/2017/ctc/