「神经网络加速器架构」最新2022概述进展

如今, 随着数据需求的增长以及硬件算力性能的提升, 人工智能得到越来越广泛的应用. 其中, 神经网络算法已经被成功地用于解决一些实际问题, 例如人脸识别、自动驾驶等. 尽管这些算法有着 卓越的表现, 但其在传统硬件平台上的计算性能仍然不够高效. 因而, 一些为神经网络算法定制的计 算平台应运而生. 本文将总结一些典型的神经网络加速器架构设计, 包括计算单元、数据流控制、所加速的不同神经网络的特点, 以及在新兴计算平台上设计加速器的考量等. 最后我们也将提出对神经 网络加速器未来的展望.
https://www.sciengine.com/SSI/article;JSESSIONID=48bd889f-2952-4623-8d60-bcf04561b5f8?doi=10.1360/SSI-2021-0409&scroll=
1 引言
当前, 人工智能(artificial intelligence, AI)已经在生活中无处不在, 例如手机的人脸识别、 汽车的自动驾驶、广告的自动推荐等. AI之所以能被广泛应用, 与三大因素密切相关: 算法、数据与算力. 数据为算法提供“学习"的来源, 也是算法所应用的对象; 硬件则为算法的实际运行提供算力支撑. 但随着摩尔定律(Moore's law)不断逼近物理极限, 传统通用的硬件平台已经难以高效处理AI算法, 特别是复杂的神经网络(neural network, NN)的推理与训练. 因而, 为NN定制硬件加速平台已经成为一个重要并且热门的话题.
1.1 研究背景
长期以来人类一直在努力尝试创造具有智能意识的人造生物, 这也就是所谓AI概念的起源. 美国达特茅斯学院(Dartmouth College)最早于1956年便开始了关于AI的立项研究
ML算法最初是为模仿人类大脑行为所设计的. 与人脑中的生物神经系统类似, 机器学习算法中的两个基本功能单元是突触(synapse)和神经元(neuron). 突触负责信息处理, 神经元负责特征提取. 而神经元模型又有很多种类, 例如sigmoid, ReLU以及Integrate-and-Fire
1.2 研究现状
虽然大数据应用的井喷推动了ML算法的发展, 但也为其在传统计算系统上的数据处理速度及可扩展性带来了极大的挑战. 这是因为在传统的冯 ⋅ 诺依曼(John von Neumann)架构上, 数据处理与数据存储是分开的两个部分. 因此, 处理器与片下存储器之间频繁的数据交换限制了系统的性能与能效. 这一问题无疑又会因为AI应用中海量的数据处理而进一步加剧. 因而, 专门为AI应用所定制的计算平台也就应运而生. 这些定制的计算平台有些是基于传统冯 ⋅ 诺依曼架构平台的改进, 而有些则是完全一个单独的加速平台. 而大多数的定制设计都基于一个共识: 与计算相比, 访存所占的延迟与能耗要大得多. 所以, 解决了“内存墙" (memory wall) [3]的问题就可以大幅度提升性能和能效. 最近的AI加速器设计通常利用大量的高并行计算和存储单元. 这些单元以二维阵列的形式排布来支持NN中的矩阵向量乘法(matrix-vector multiplication). 除此之外, 片上网络(network on chip, NoC) [4]、高带宽内存(high bandwidth memory, HBM) [5]以及数据重用(data reuse) [6]等技术进一步优化了加速器中的数据传输. 除了传统的基于互补金属氧化物半导体(complementary-symmetry metal-oxide-semiconductor, CMOS)的设计之外, 例如忆阻器(metal-oxide resistive random access memory, ReRAM)等新型存储器件也被应用于AI加速器的设计中 [7-9]. 这些新型存储器件都有存储密度高、访寸延迟低并且可以进行存内计算(processing-in-memory, PIM)等特点. 以ReRAM为例, ReRAM阵列不仅可以存储NN的权重, 也可以在模拟域进行原位的MVM (matrix-vector multiplication)计算. 与基于CMOS等设计相比, 基于ReRAM的AI加速器利用模拟域低能耗计算可以在能效上有3 ∼ 4个数量级的提升 [10]. 而运算过程中因模拟噪声信号所产生的计算偏差则可以通过ML算法上的优化被消除. 但是, 基于ReRAM的AI加速器也同样存在着一些问题. 例如其中数模(digital-to-analog converter, DAC)与模数(analog-to-digital converter, ADC)转换电路的能耗与面积可以分别占到总能耗的66.4%和总面积的73.2% [11].
1.3 本文章节介绍
本文主要关注面向ANN的加速器架构设计. 我们将总结关于深度神经网络(deep neural network, DNN)加速器设计的最新进展. 第2节主要介绍NN的相关基础知识以及ReRAM的工作原理; 第3节介绍片上NN处理单元; 第4节介绍独立的NN加速器; 第5节介绍基于新型存储器件的加速器; 第6节介绍软硬件协同设计及面向新型应用的加速器; 第7节对未来NN加速器设计进行展望.
2 背景介绍
本节主要介绍关于DNN的背景知识以及一些在本文中涉及的重要概念. 另外, 本节也将简要介绍ReRAM及其在NN加速计算中的应用.
2.1 神经网络推理与训练
总体来说, 一个DNN模型可以看成是一个根据高维输入给出有效预测的复杂的参数化函数. 这个预测的过程则被称为推理(inference). 而获得参数的过程则被称为训练(training). DNN的训练在训练数据集上完成. 训练的目标则是不断减小一个预先定义的损失函数(loss function). DNN的参数也被称为权重(weight), 权重在训练过程中通过随机梯度下降(stochastic gradient descent, SGD)等方法被不断优化. 在每一次训练中, 首先进行前向传播(forward pass)来计算损失函数; 然后再进行反向传播(back propagate)来反传误差; 最后, 每一个参数的梯度都被计算并且累计. 如果要完全训练一个大规模的DNN, 训练过程可能要持续一百万次甚至更多. 一个DNN通常由许多神经网络层(NN layer)组成. 我们把第 l 层记作函数 f l , 那么一个包含 L 层网络的简单的DNN的推理可以写作
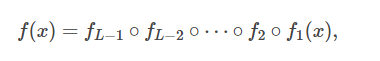
其中 x 为DNN的输入. 由此例可知, 每一层的输出其实只作为下一层的输入, 因而整个DNN的推理过程可以看作是一个链式计算的过程. 在DNN的训练中, 数据的前向传播过程和推理一致, 但其反向传播过程与之相反. 并且前向传播过程中每一层的中间结果都会在反向传播过程中被重新利用来计算误差(这是由于反向传播的链式法则). 这无疑大大加剧了数据之间的依赖性. 图 1 表明了训练与推理过程中的区别. 一个DNN也可能会包含卷积层(convolutional layer), 全连接层(fully connected layer)以及一些其他非线性层(如激活函数ReLU, sigmoid, 池化层(max pooling)以及批标准化层(batch normalization)). 在反向传播过程中, 矩阵乘法以及卷积仍然基本保持其计算模式不变. 细节上的区别是在反向传播过程中, 原来的权重矩阵以转置的形式参与反向传播计算, 而卷积核也以旋转的形式参与梯度下降的计算.

2.2 计算模式
尽管一个DNN模型会包含很多层, 但矩阵乘法和卷积占了超过90%的计算量. 而这两者也是DNN加速器设计优化的主要对象. 对于一个矩阵乘法而言, 如果我们用 I c , O c 和 B 分别表示输入通道数(input channel)、输出通道数(output channel)以及批量输入大小(batch size), 那么推理的计算过程可以写成
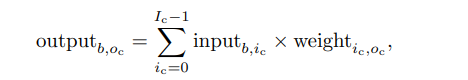
其中 i c 是输入通道的标号, o c 是输出通道的标号( 0 ≤ o c < O c ), b 是批量输入样本中的标号( 0 ≤ b < B ). 在这个矩阵向量乘法中每一个输入可以被所有的输出通道重用, 而每一个权重则可以被所有批量输入重用.
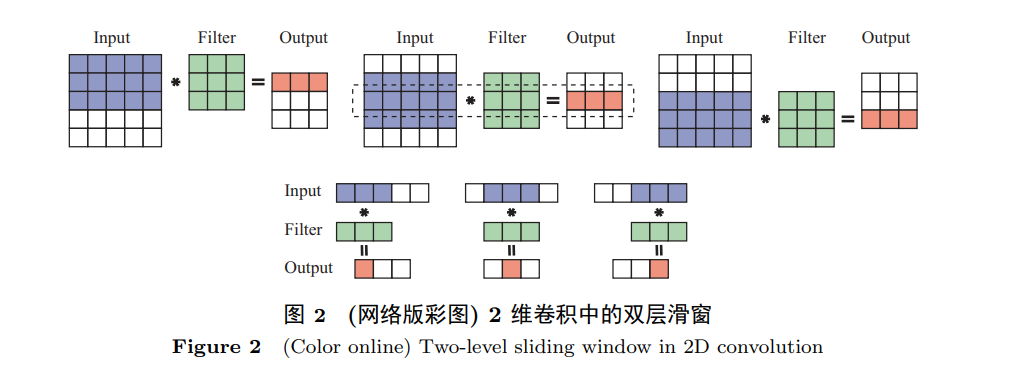
DNN中的卷积实际上可以被看成是矩阵乘法的扩展. 卷积的作用从直观上来讲可以说是增加数据的局部联系性. 与一般的矩阵乘法相比, 在卷积计算中, 每一个输入元素被一张2维特征图所替代, 每一个权重元素被一个2维卷积核(convolution kernel/filter)替代. 其计算模式是一种“滑窗"式计算. 如图 2所示, 卷积核从输入特征图的左上角开始滑向右下角. 这个过程可以表示为
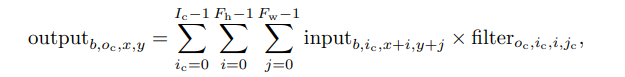
其中 F h 和 F w 分别是卷积核的高度和宽度, i 和 j 分别是2维卷积核的行索引和列索引, x 和 y 分别是2维输入特征图的行索引和列索引, 并且满足条件 0 ≤ b < B , 0 ≤ o c < O c , 0 ≤ x < O h , 0 ≤ y < O w , 其中 O h 和 O w 分别为输出特征图的高度和宽度.
不难发现, 一个卷积核要被重复应用到输入特征图的所有部分. 这使得卷积运算中的数据重用比矩阵乘法中更为复杂. 可以把这个2维的“滑窗"看成是两个层级: 第1个层级是把“滑窗"看成是几行权重在特征图上自上而下滑动, 由此进行行间数据重用; 第2个层级是“滑窗"的某一行都自左至右滑动, 由此进行行内数据重用. 尽管矩阵乘法和卷积的计算模式不同, 但是卷积也可以通过Toeplitz变换转换为矩阵乘法, 但这将付出一定量数据冗余的代价 [12].
2.3 忆阻器平台
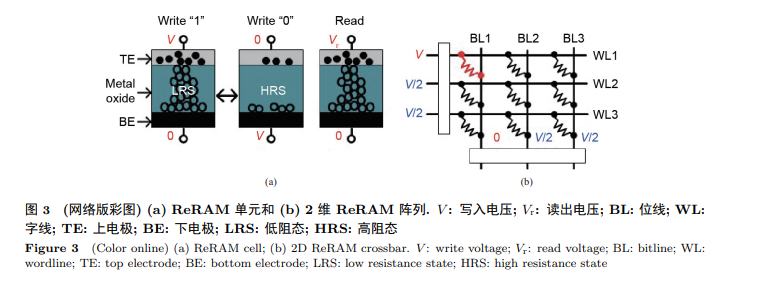
ReRAM是一种用电阻单元来存储数据信息的新型非易失性存储器件. 如图 3(a)所示, 每一个ReRAM单元都在上下电极之间有一个金属氧化物夹层. 这个单元的电阻值可以通过写入电流或者电压而设定. 写入电流的脉冲宽度及电压的大小决定了所要设定的电阻值的大小. 当读出数据信息时, 只需要在此器件上加一个小的感应电压, 输出电流的大小反应了电阻值的大小, 进而可获 得所存储的数据信息. 除此之外, 由许多ReRAM单元组成的ReRAM阵列可以进行原位的MVM计算. 这可以应用到加速NN的MVM计算上. 如图 3(b)所示, 输入向量作为输入信号以电压的形式加到字线上. 而矩阵的每一个元素作为电导值则被预先写入ReRAM阵列中. 每一个位线的累积电流则可以看成是两个向量内积的结果. 因而一个阵列的所有输出则可看成是一个MVM的结果. MVM的输出作为中间结果会被进一步处理从而得到最终结果.
3 片上加速器
其实神经网络加速硬件单元最早作为通用处理器的辅助单元 [13], 加速被NN替代的某些通用程序中的“近似程序段"(approximate program), 从而实现加速通用程序处理的目的. 注意, 这里的近似程序段是指可以通过训练一个NN模型模仿其行为并且被NN替代后其精度损失可以在接受范围内的程序. 随着NN应用的范围越来越广泛, 其作用也不再仅仅局限于近似计算领域, 专门为NN的计算定制加速硬件也变得更有必要.
3.1 神经处理单元
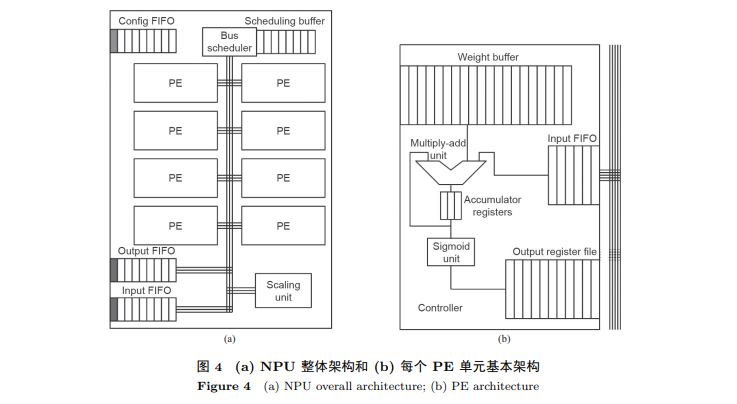
神经处理单元(neural processing unit, NPU) [13]是加速通用程序段中可以用NN做近似计算(approximate computation)来替代的部分, 例如为索贝尔边缘检测(sobel edge detection)和快速傅立叶变换(fast Fourier transform)而设计的专用硬件. 为了在NPU上执行一个程序, 程序员需要手动注释近似程序段. 当编译器开始编译时将被注释的程序段编译为NPU指令, 然后相关的计算任务便从CPU转交到NPU执行. NPU的硬件设计非常简单. 如图 4所示, 每个NPU有8个处理单元(processing engine, PE). 每个PE都负责一个“神经元"计算, 即乘加之后再进行sigmoid非线性处理. 所以这个NPU只能处理简单的多层感知机(multiple layer perception, MLP) NN模型.
3.2 可重构片上网络加速器
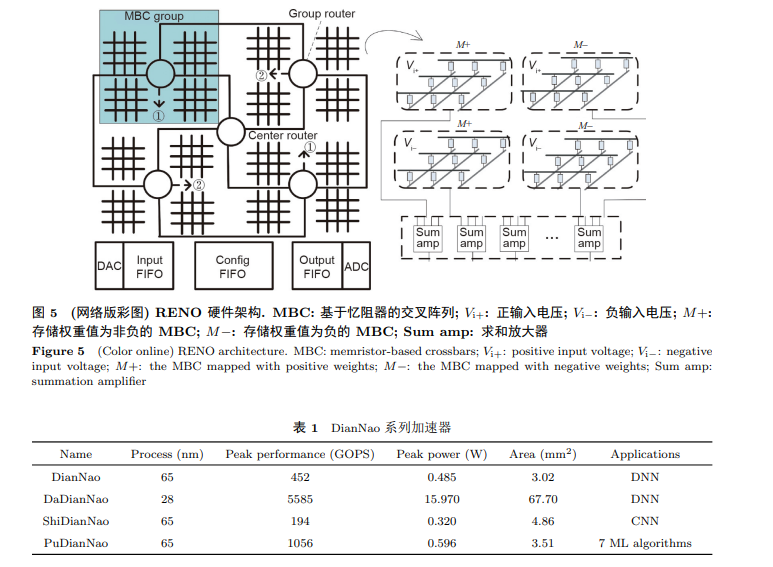
随着NN算法的不断发展, NN的应用不再局限于近似计算. 因此专门为NN的计算设计硬件平台就显得愈发重要. RENO [4]就是一个专为NN定制的硬件加速平台. 如图 5所示, RENO对于PE的功能设计采用了与NPU类似的想法. RENO的PE都是基于ReRAM的交叉阵列(crossbar). RENO利用ReRAM crossbar作为基本的计算单元去处理MVM. 每个PE都有4个ReRAM crossbar去处理正负输入与正负权重所对应的4个MVM. 在RENO中, 数据通路(router)主要用来负责PE之间的数据传输, 即把上一个PE模拟域获得的中间结果传递到下一个PE上去. 在RENO中, 输入和最终的输出是数字信号, 而所有的中间结果都是模拟信号. 因而, 只有当RENO和CPU之间传输数据时才需要DAC和ADC转换电路. 不难看出, 定制的片上加速器作为CPU的辅助单元, 可以帮助CPU高效地处理一些特定的任务. 但由于片上资源的限制(例如面积、功耗等因素), 片上加速器的设计预算有限. 因而其只能用来加速一些例如近似计算、简单的MLP的推理等计算量较小的应用.
4 神经网络加速器
为了支持更为复杂的DNN和CNN, 独立的专用NN加速器已经被提出并且在云端(cloud)和边缘端(edge)都获得了巨大的成功. 与传统的CPU和GPU相比, 这些定制的架构可以有更强的性能以及更高的能效. 在设计定制的架构时, 要特别考虑数据流的设计, 从而减小片上与片外的数据交互. 本节主要以DianNao系列 [14]以及张量处理单元 [15] (tensor processing unit, TPU)为例介绍独立的神经网络加速器并对其数据流设计进行分析.
4.1 DianNao
如表 tab1所示, DianNao系列有多个加速器. DianNao是这个系列的首款加速器. 如图 6所示, DianNao由以下部分组成: (1)由神经计算单元组成的计算模块(neural functional unit, NFU); (2)一个输入缓存( N B i n ); (3)一个输出缓存( N B o u t ); (4)一个突触权重缓存(synapse buffer, SB); (5) 一个控制处理器(control processor, CP). NFU是进行乘加操作以及非线性运算的基本单元, 并且采用流水线的方式进行计算. NFU没有采用传统的片上缓存, 而是用片上便签存储器(scratchpad memory)作为片上的数据存储. 与传统缓存相比, scratchpad可以被编译器控制并且更有利于通过编译控制来提高数据的局部性, 从而更好地进行数据重用. 尽管高性能的计算单元对于DNN加速器非常重要, 低效的缓存也可以很大程度地影响系统的能效及吞吐率. DianNao系列加速器提出了一种针对减小访存延时的特殊设计. 例如针对数据中心应用场景所设计的DaDianNao [16]在片上集成了大量嵌入式动态随机存取存储器(embedded dynamic random access memory, eDRAM)来尽可能避免对片外主存的读取. 同样的思路也适用于针对面向嵌入式场景的ShiDianNao [17]. ShiDianNao主要用来加速CNN. 由于CNN计算中存在大量的数据重用, 因而加速CNN所需的数据读取次数相对更少. 这就使得当CNN模型参数量小时, 我们就可以把CNN的权重全都存储到片上静态随机存取存储器(static random access memory, SRAM)上. 在这种情况下, 与DianNao对比, ShiDianNao避免了大量高延迟高能耗的片外访存, 并且可以将能效提高60倍. PuDianNao [18]是一个面向多种ML应用的加速器设计. 除了支持DNN的加速计算外, 它还支持像k均值(k-means)和分类树(claasification tree)这样的其他ML算法. 为了同时支持这些应用的不同数据访存模式, PuDianNao提出了“冷缓存" (cold buffer)和“热缓存" (hot buffer)来应对不同的数据重用方式. 除此之外, 一些如循环展开(loop unrolling)和循环分块(loop tiling)等编译技术也被应用, 从而形成一个软硬件协同设计的方法来增加片上数据的重用以及PE的实际利用率.

4.2 TPU
如图 7所示, Google在2017年提出了基于脉冲阵列(systolic array)的TPU [15]. 其实在2015年Google就已经开始使用其提出的第一代TPU在数据中心加速NN的推理. Systolic arrary的数据流是“权重固定" (weight stationary)的数据流, 并且是一个2维的单指令多数据流(single instruction multiple data, SIMD). 在此之后, Google又发布了面向云端应用的第二代TPU 1). 第二代TPU既可以处理DNN的推理也可以加速模型的训练. 它依然是基于脉冲阵列的架构并且引入了专用的向量处理单元.
1) Google I/O'17. California: Google cited 2019 Jan 18. https://events.google.com/io2017/.
4.3 寒武纪
除了独立的加速器设计之外, 相应的指令集(instruction set architecture)也被提出. 寒武纪 [19] (Cambricon)就是一个以load-store架构为基础, 集成标量、向量、 矩阵、逻辑、数据传输及控制指令的一个面向DNN加速的ISA. ISA设计考虑了数据并行、 定制的向量/矩阵操作指令以及对scratchpad memory的使用等多重因素.
4.4 数据流分析与架构设计
DNN和CNN的计算通常都需要大量的访存. 对于复杂而且参数量大的NN模型而言, 将模型的全部参数都放在片上是不可能的. 由于受限的片外带宽, 提高片上数据的重用以及减少片外数据的读取对于提高计算效率而言就显得尤为重要. Eyeriss [6]针对NN计算的特点提出了3种不同的数据流, 分别是“输入固定" (input-stationary, IS), “输出固定" (output-stationary, OS)以及“权重固定" (weight-stationary, WS). 在这3种数据流的基础上, 结合具体的加速器硬件设计, Eyeriss提出了“行"固定(row-stationary, RS)的数据流来进一步提高数据的重用(如图 8). 工业界的许多加速器产品也都重视数据流的设计与实现. 例如, WaveComputing 2) 为可重构阵列加速器提出了粗粒度调配的数据流, GraphCore 3) 则专门为图计算设计高效的架构及数据流. NN加速器常常作为CPU的协处理器来帮助其处理一些相对复杂的NN模型的加速(包括推理与计算). 虽然有更充足的硬件资源预算, 但是NN加速器与外部存储器链接的带宽依然非常受限. 其所需的数据本质上仍然需要从片外读取. 在一些条件下, 其产生的中间数据也仍需写到片外. 因而受限的片外带宽以及频繁的片外数据读取/写入成为了此类NN加速器的性能瓶颈.
2) HC29 (2017). Hot chips cited 2019 Jan 18. https://www.hotchips.org/archives/2010s/hc29/.
3) GraphCore. Bristol: GraphCore cited 2019 Jan 18. https://www.graphcore.ai/technology.
5 基于新型存储器件的加速器
ReRAM和HMC是两个具有代表性的能实现“存算一体" (PIM)的新型存储器件. PIM可以大大降低数据在计算平台上的移动, 从而降低数据传输所带来的延迟与能耗.
5.1 基于忆阻器的神经网络加速器
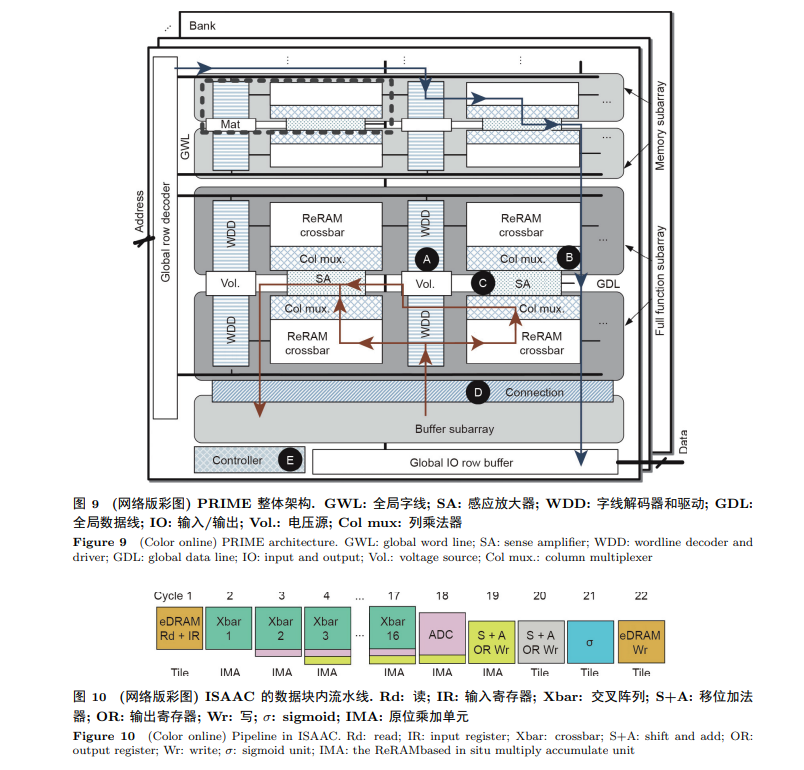
利用ReRAM进行DNN加速的主要思路是利用ReRAM阵列进行“原位"的MVM计算. PRIME [7], ISAAC [11]以及PipeLayer [8]是3个具有代表性的基于ReRAM的DNN加速器. PRIME的架构如图 9 所示. PRIME利用ReRAM同时对数据进行存储和计算. 在PRIME中, WDD可以根据输入的大小配置相应的电压. Col mux可以配置为模拟域减法和非线性激活函数电路(sigmoid). 两个不同ReRAM阵列的中间结果可以合并在一起然后发送到sigmoid 电路上进行下一步计算. PRIME中SA的精度也可以按照需求进行配置, 并且像ADC一样进行模拟信号到数字信号的转换. ISAAC [11]提出了一个数据块内流水线式的NN处理架构. 如图 10 所示, 这条流水线中结合了数据的编码与计算. IMA是基于ReRAM的原位乘加单元. 第一个周期, 数据先从eDRAM中被取出然后发送到计算单元. ISAAC中的数据格式是16比特定点数. 在计算过程中, 每一个周期都有1比特数据被发送到IMA中. IMA的结果被转换成数字信号形式存储. 针对一个数据的16个计算周期, 之前的结果不断移位与当前结果相加, 从而得到最终结果. 然后, 线性的最终结果被非线性函数计算电路处理, 最后写入eDRAM. PipeLayer [8]也采用了流水线的工作方式. 与ISAAC不同, PipeLayer每次处理的数据“粒度"更大, 以此来充分利用ReRAM计算单元的高并行性. PipeLayer也提出了两种并行计算的方式: 层内并行与层间并行. 对于层内并行, PipeLayer采用了一种数据并行的处理方式, 即用多个含有相同权重的处理单元去处理更多的输入数据; 而层间并行则采用模型并行的处理方式, 即含有模型不同层权重的处理单元同时运行. 中间结果被一直复用. 注意, 这时不同的处理单元同时得到的是来自不同输入的中间结果.
5.2 基于混合记忆立方体(HMC)的神经网络加速器
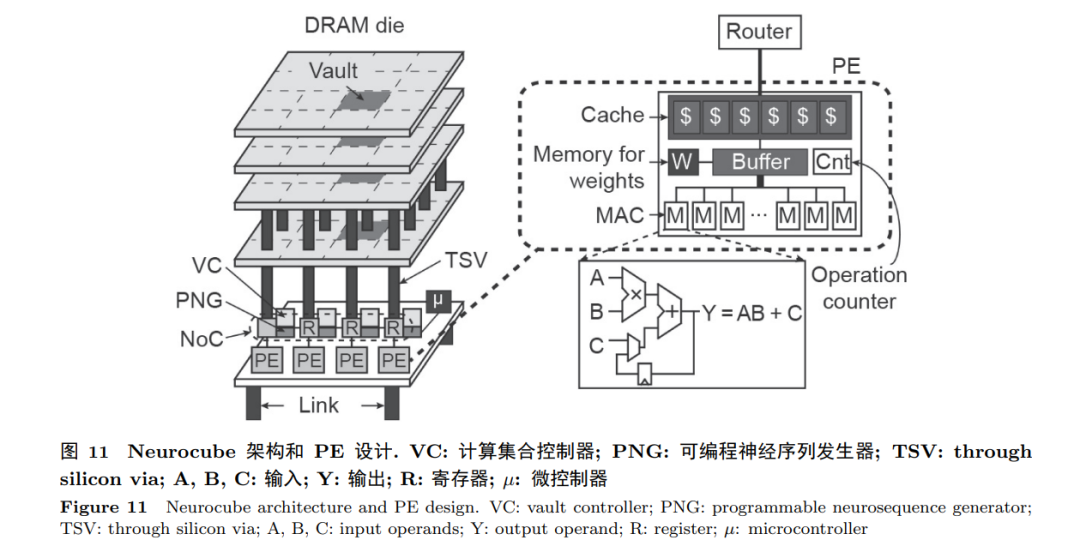
HMC将几个DRAM的存储芯片和逻辑层芯片竖直集成在一起. 这个集成体被划分为多个相对独立的“计算集合" (vault). HMC大存储量、高带宽、 低延迟的特点使得近存计算成为可能. 在一个基于HMC的加速器架构设计中, 计算和逻辑单元被放在逻辑层芯片上, DRAM的存储芯片则用来储存数据. Neurocube [20]和Tetris [21]是两个典型的基于HMC的DNN加速器. 如图11所示, Neurocube包含16个vault. 每个vault可以被看成一个子系统. 这个子系统包含一个可以做乘加的PE和一个负责数据包 在逻辑层芯片与DRAM存储芯片之间传输的数据通路. 每个vault也可以通过数据通路与其 他vault进行乱序数据发送与接收. 基于新型存储器件的加速器有效减少了数据的搬运, 并且尤其适合处理数据量/参数量较大的计算任务, 不再受“冯 ⋅ 诺依曼"架构的限制, 是未来加速器架构发展的重要方向.
6 软硬件协同设计及面向新型应用的加速器
DNN加速器的性能也可以通过高效且适用于硬件计算特点的NN算法提升. 例如通过对NN的剪枝减少模型的参数量并且使其更加稀疏, 以此来减少数据访存. 而对NN中参数的量化则可以使NN计算更加低精度, 既能减少数据的存储量又能降低计算成本. 除此之外, 一些新型的应用, 如对抗神经网络(generative adversarial network, GAN)、 基于深度学习的推荐系统等, 为专用加速器等设计提出了新的要求.
6.1 稀疏神经网络加速
文献[22]提出在精度损失很小的情况下, NN模型中很大一部分的连接可以被剪枝, 即很大比例的权重可以被设置为0. 相应地, 很多加速这种稀疏神经网络的加速器也被提出. 例如EIE [23]是专为加速稀疏的权重矩阵计算而设计的, Cnvlutin [24]为加速稀疏的特征图输入而定制. 但是这些设计中额外的数据编码器与解码器也会带来附加的硬件开销. 有一些算法工作讨论了如何设计对于硬件加速友好的NN模型 [25,26]. 为了使得硬件更有效地加速稀疏NN模型, 文献 [25]将稀疏对象的粒度从每个权重提升到每个参数块, 从而减少复杂的硬件控制而节省额外的开销. 已经有一些加速器设计提出相应的技术方法来处理不规则访存以及缓解稀疏NN给硬件处理单元 之间带来不平衡的工作量的问题. 例如Cambricon-X [27]和Cambricon-S [28]就采用了一种软硬件协同的方法去解决稀疏NN模型计算中不规则访存的问题. ReCom [29] 则针对ReRAM平台提出了一种将权重和输入(包含中间结果)结构化压缩的方案来加速稀疏NN的推理. ReBoc [26]则在ReRAM平台上对采用“块循环"(block circulant)压缩方法的NN进行加速. par 除此之外, 最近对数据比特粒度的加速也得到了广泛的关注. PRA [30]对串行输入中每个数据中的“0"比特进行跳过操作, 因而节省了不必要的计算开销. 并且对此操作提出了相应的定制乘加器设计. Laconic [31]则对NN计算中的乘法进行比特粒度的分解, 从而可将必要的计算量降低到原来的1/40.
6.2 低精度神经网络加速
降低数据精度, 对NN的参数进行量化是提高NN加速器计算效率的另一种方式. 最近TensorRT [32]的结果显示, 在确保推理精度不损失的情况下, AlexNet, VGG以及ResNet等被广泛使用的NN模型可以被量化至8比特. 但当量化精度进一步降低时, NN模型的精度很难再得到保证. 许多复杂的量化方法也被相继提出. 但附加的硬件编码器与解码器的开销也随之增加. 所以研究者们试图在数据的精度以及整体系统的性能之间找到一个平衡点. 权衡各种因素的量化方法可以总结如下. (1) 权重和特征图被量化成不同的精度来减小NN推理精度的损失. 这可能会改变加速器架构中数据流的设计. (2) NN模型中不同的层或者不同的数据需要不同的量化策略. 总体来说, 一般NN的第一层与最后一层的数据需要更高的精度. 但这也会增加相关控制硬件的开销. (3) 还可以根据NN参数的数据分布来确定量化策略. 例如文献 [33]对大部分的权重和中间结果进行低精度量化并进行计算; 而对少数偏离大多数数据范围分布的数据, 则采用高精度量化.
6.3 生成对抗神经网络加速
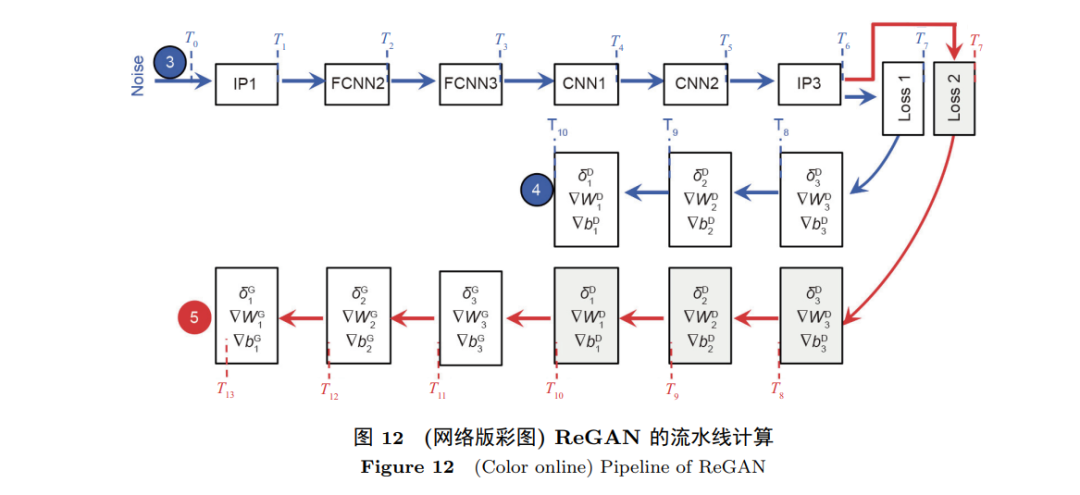
与CNN/GAN不同, GAN包含两部分, 分别是生成器(generator)和判别器(discriminator). Generator负责产生“假"的数据并提供给discriminator, 而discriminator则负责去学习如何辨别出这些“假"的数据. 这两部分被循环训练并且相互竞争. 在GAN的计算中包含一个新的算子叫转置卷积(transposed convolution). 与原来的卷积相比, transposed convolution包含上采样操作并把许多“0"值插入到特征图中. 如果transposed convolution被直接计算, 这无疑将引入许多冗余计算. 除此之外, 如果不存储这些上采样过程中所产生的“0", 那么对非0数据的访存又是极其不规则的. 总之, GAN的加速器必须要支持训练, 为transposed convolution定制计算数据流, 还要优化不规则的数据访存. ReGAN [9]提出了一个基于ReRAM的GAN加速器. 如图 12所示, 一个专门设计的层级流水线被提出来提高系统的吞吐率. 其中, “空间并行" (spatial parallelism)和“共享计算" (computation sharing)两项技术也被提出来进一步提高训练效率. 也有基于CMOS的GAN的加速器设计提出针对GAN的不同计算部分的数据流进行优化. GANAX [34]提出了基于SIMD-MIMD的加速器来提高generator和discriminator的运行效率. SIMD-MIMD的模式主要是用在一些涉及generator的上采样插入“0"的操作加速上, 而单独的SIMD模式则主要用在discriminator的CNN加速上.
7 展望
本节主要对DNN的训练加速器、基于ReRAM的加速器以及edge端的DNN加速器进行展望, 对其未来的发展趋势予以讨论.
7.1 DNN训练加速器
目前, 几乎大多数DNN加速器架构都专注于DNN推理优化, 只有少数部分支持NN的训练 [8]. 随着训练数据集和神经网络规模的增加, 单个加速器不再能够支持大型 DNN 的训练. 不可避免地需要部署一组加速器或多个加速器来训练 DNN. 文献 [35]提出了一种在加速器阵列上进行DNN训练的混合并行结构. 加速器之间的通信在加速器阵列上的 DNN 训练中占主导地位. 文献 [35]提出了一种通信模型来识别数据通信的产生位置以及通信量的大小. 在通信模型的基础上, 它还优化了分层并行性, 以最大限度地减少总通信量, 提高系统性能和能源效率.
7.2 基于ReRAM的DNN加速器
当前基于ReRAM的加速器 [7,8,11], 都假设忆阻器单元是理想的. 然而, 诸如工艺变化 [36]、电路噪声 [37]和耐久性问题 [38]等 现实挑战极大地阻碍了基于ReRAM 的加速器的实现. 未来, 在实际的基于 ReRAM 的 DNN 加速器设计中, 必须考虑这些非理想因素.
7.3 Edge端DNN加速器
在DNN应用中, 计算和内存密集型部分(例如, 训练)通常被卸载到cloud端具有强大算力的 GPU上, 只有某些轻推理模型部署在edge端设备(例如, 物联网或移动设备)上. 随着数据采集规模的快速增长, 拥有能够针对某些任务自适应学习或微调其 DNN 模型的智能边缘设备已经成为一种迫切的需求. 例如, 可穿戴设备会监控用户的健康. 由于显著的数据通信开销和隐私问题, 用户更倾向于在本地调整设备所使用的NN 模型, 而不是将感测到的健康数据发送回云端. 在其他应用中, 例如机器人、无人机和自动驾驶汽车, 经过静态训练的模型也无法有效处理随时间变化的环境条件. 然而, 将大量环境数据发送到cloud端进行增量训练所带来的数据传输的高延迟通常是不可接受的. 更重要的是, 许多现实生活场景需要实时执行多个任务和动态适应能力 [39]. 然而, 由于边缘设备严格的计算资源限制, 在边缘设备中进行这些计算极具挑战性. RedEye [40]是边缘 DNN 处理的加速器, 其中计算部分与传感部分集成在一起. 因而, 为边缘 DNN 设计轻量级、实时和节能的架构是下一步的重要研究方向.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NNA” 就可以获取《「神经网络加速器架构」最新2022概述进展》专知下载链接





