伯克利星际争霸II AI「撞车」腾讯,作者:我们不一样
机器之心报道
参与:晓坤、张倩
来自加州大学伯克利分校的研究者在星际争霸 II 中使用了一种新型模块化 AI 架构,该架构可以将决策任务分到多个独立的模块中。在虫族对虫族比赛中对抗 Harder(level 5)难度的暴雪 bot,该架构达到了 94%(有战争迷雾)和 87%(无战争迷雾)的胜率。只是腾讯等近期也在星际争霸 II 的 AI 架构上提出了模块化方法,而伯克利研究者甚至也发现二者是同期进行的研究。至于有没有撞车,看看他们怎么解释~
深度强化学习已经成为获取有竞争力游戏智能体的有力工具,在 Atari(Mnih et al. 2015)、Go(Silver et al. 2016)、Minecraft(Tessler et al. 2017)、Dota 2(OpenAI 2018)等许多游戏中取得了成功。它能够处理复杂的感觉输入,利用大量训练数据,通过自己摸索在不借助人类知识的情况下发展自身技能(Silver et al. 2017)。星际争霸 II 被公认为 AI 研究的新里程碑,但由于其视觉输入复杂、活动空间巨大、信息不完整且视野较广,星际争霸 II 仍然是困扰深度强化学习的一大挑战。实际上,直接的端到端学习方法甚至无法打败最简单的内建 AI(Vinyals et al. 2017)。
星际争霸 II 是一款实时策略游戏,包括搜集资源、搭建生产设备、研究技术及管理军队打败对手等。它的上一个版本(即星际争霸)受到了众多研究者的关注,包括分层规划(Weber, Mateas, and Jhala 2010)和树搜索(Uriarte and Ontan˜on 2016)(见 Ontan˜on et al. (2013) 的研究)。之前的多数方法都聚焦于大量手工设计,但因其无法利用玩游戏的经验,智能体还是无法打败职业玩家(Kim and Lee 2017)。
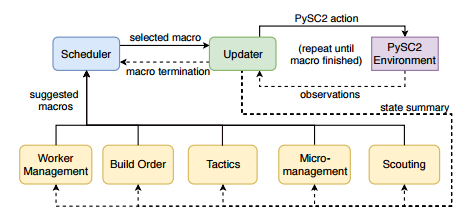
图 1:本文提出的针对星际争霸 II 的模块化架构
本文研究者认为,适当整合人类知识的深度强化学习可以在不损失策略表达性和性能的前提下有效降低问题的复杂性。为了实现这一目标,他们提出了一种灵活的模块化架构,可以将决策任务分到多个独立的模块中,包括劳工管理、构建顺序、策略、微管理及侦察等(见图 1)。每个模块可以手工设计或通过一个神经网络策略实现,这取决于该任务属于易于手工解决的常规任务,还是需要从数据中进行学习的复杂任务。所有模块向策划者推荐宏指令(预定义的动作序列),策划者决定它们的执行顺序。此外,更新者持续追踪环境信息,适应性地执行由策划者选择的宏指令。
研究者还通过带有自行探索能力的强化学习进一步评估了这一模块化架构,着眼于这个游戏中可以从大量训练经验中获益的重要方面,包括构建顺序和策略。智能体是在 PySC2 环境中训练的(Vinyals et al. 2017),该环境中有个颇具挑战性的类人控制接口。研究者采用了一种迭代训练方法,首先训练一个模块,同时其他模块遵循非常简单的脚本化行为,然后用一个神经网络策略替换另一个模块的脚本化组成,在之前训练的模块保持固定的情况下继续训练。研究者评估智能体玩虫族 v.s. 虫族对抗梯形图上的内建 bot,在对抗「Harder」bot 时取得了 94%(有战争迷雾)或 87%(无战争迷雾)的胜率。此外,该方法的智能体在延伸测试图中泛化良好,并且取得了类似的性能。
本文的主要贡献在于展示了深度强化学习、自行探索与模块化架构及适当人类知识相结合可以在星际争霸 II 上取得有竞争力的表现。虽然本文聚焦于星际争霸 II,但将该方法泛化至其他现有端到端强化学习训练范式无法解决的复杂问题也是可能的。
论文:Modular Architecture for StarCraft II with Deep Reinforcement Learning

论文链接:https://arxiv.org/pdf/1811.03555.pdf
摘要:我们在星际争霸 II 中使用了一种新型模块化 AI 架构。该架构在多个模块之间分割责任,每个模块控制游戏的一个层面,例如建造次序选择或策略。有一个集中策划者会审查所有模块的宏指令,并决定它们的执行顺序。有一个更新者会持续追踪环境变化并将宏指令实例化为一系列可执行动作。该框架的模块可以通过人类设计、规划或强化学习独立地或联合地进行优化。我们应用深度强化学习技术的自我对抗来训练一个模块化智能体六个模块中的两个,在虫族对虫族比赛中对抗"Harder"(level 5)难度的暴雪 bot,达到了 94%(有战争迷雾)或 87%(无战争迷雾)的胜率。
模块化架构
表 1 总结了每个模块的作用和设计。在以下部分中,我们将详细描述我们实现的虫族智能体。请注意,此处介绍的设计只是实现此模块化体系架构的所有可能方法的一个实例。只要能与其他模块协同工作,就可以将其他方法(例如规划)合并到其中一个模块中。

表 1:在当前版本中每个模块的作用以及设计。FC=全连接网络。FCN=全卷积网络。
更新者
更新者作为记忆单位、模块的通讯枢纽以及 PySC2 的入口。
为了保证 AI 和人类的公平比较,Vinyal 等人(2017)定义了 PySC2 的观察输入,使其和人类玩家看到的相似,包括屏幕的图像特征地图以及小地图(例如单位类型、玩家身份等),和一系列非空间特征,如收集矿物的总数量。由于过去的动作、过去的事件和视野外的信息对于决策很重要,但不能直接从当前观察获取,智能体需要发展高效的记忆。尽管从经验中学习这样的记忆是可能的,我们认为适当手工设计的记忆也能达到类似的目的,同时也降低了强化学习的负担。表 3 列出了更新者维护的示例记忆。一些记忆(例如构建队列)可以从过去采取的动作推断出来。一些记忆(例如友好单位)可以通过检查所有单位名单推断出来。其它记忆(例如敌对单位)需要进一步处理 PySC2 观察,并与侦察模块协作才能推断出来。
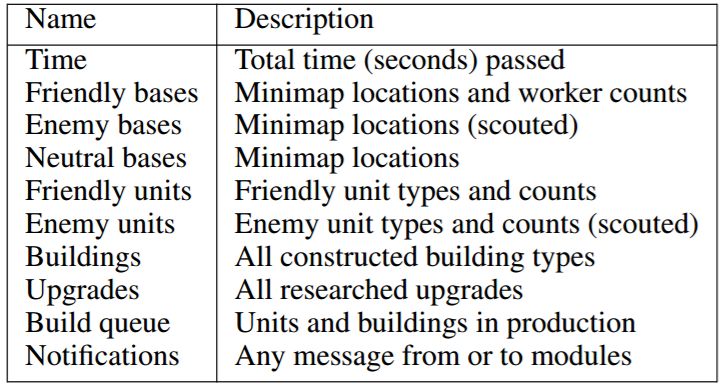
表 3:更新者维护的示例记忆。
宏指令
在玩星际争霸 II 时,人类通常从一系列的子程序中选择动作,而不是从原始环境动作选取。例如,为了构建一个新的基地,玩家识别到一个未被占领的中立基地,选择劳工,然后构建基地。这里我们将这些子程序命名为宏指令(如表 2 所示)。学习策略来直接输出宏指令可以隐藏更高级命令的一般执行细节,因此允许更高效地探索不同策略。
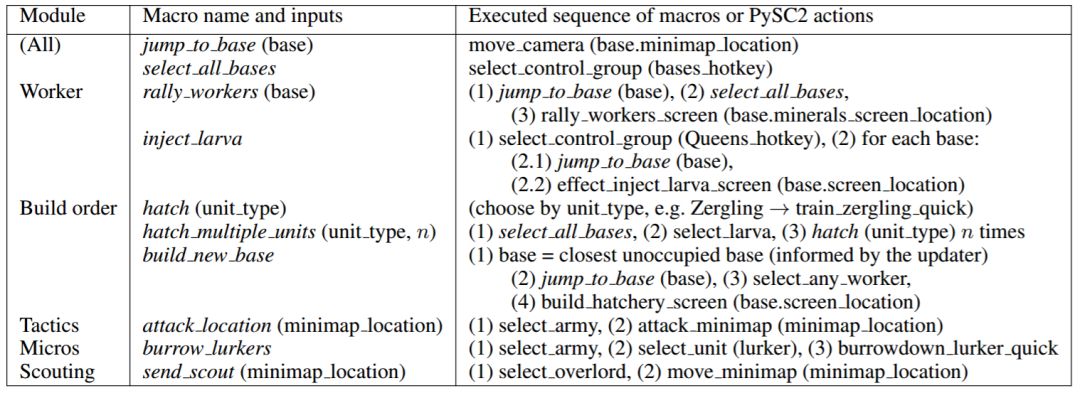
表 2:对每个模块可用的示例宏指令。一个宏指令(斜体字)由宏指令序列或 PySC2 动作构成(非斜体字)。更新者提供 base.minimap location、base.screen location 和 bases hotkey 等信息。
构建顺序
星际争霸 II 智能体必须平衡我们在许多需求之间的资源消耗,包括供应(人口容量)、经济、战斗单位、升级等。构建顺序模块在选择正确的构建策略方面起着至关重要的作用。例如,在游戏早期,智能体需要专注于创建足够的劳工来收集资源;而在游戏中期,它应该选择能够击败对手的正确类型的军队。尽管存在由专业玩家开发的许多有效构建顺序,在没有适应的情况下简单地执行一种顺序可能带来高度可利用的行为。智能体的构建顺序模块可以从大量的游戏经验中获益,而不是依赖复杂的 if-else 逻辑或规划来处理各种场景。因此,我们选择通过深度强化学习来优化该模块。
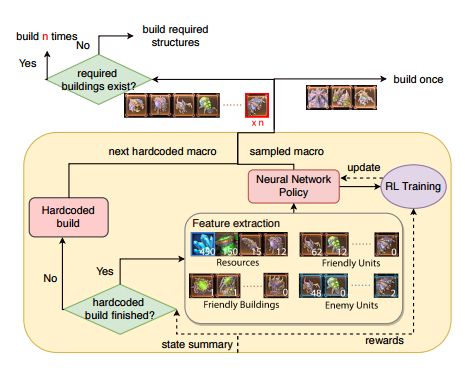
图 2:构建顺序模块的细节。
该部分还包括了策略、侦察、微管理、劳工管理、策划者模块,详情请参见原论文。
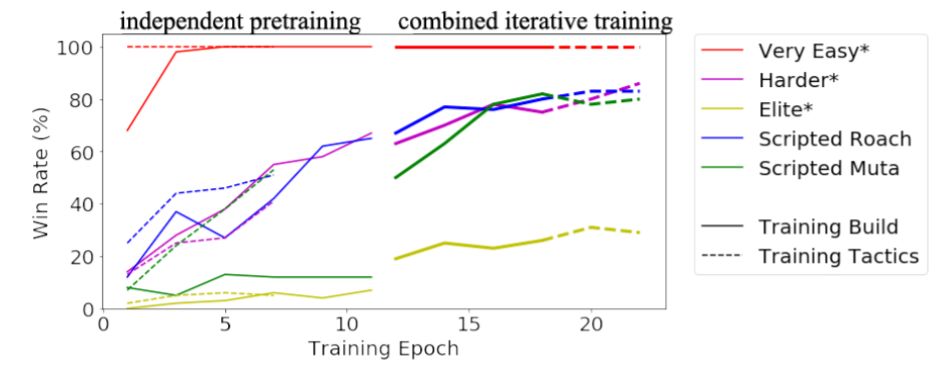
图 3:我们的智能体在面对不同难度的对手时的胜率。星号表示在训练过程中没有见过的内建 bot。1 epoch = 3 × 10^5 策略步。
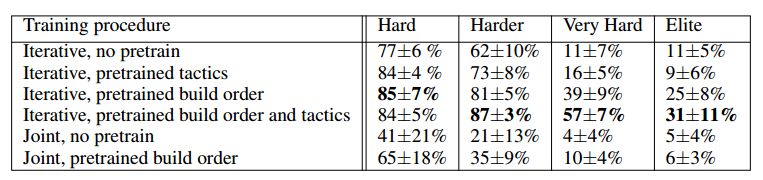
表 4:不同训练过程下和不同难度内建 bot 的最终胜率(3 个种子,每个种子 100 场比赛的平均值)。

表 5:和不同对手的胜率对比(100 场比赛)。括号里写的是预训练部分。「V」表示「非常」。从表中可以看出,我们的方法能超越简单的脚本智能体。

图 4:学习的军队组成。显示每种单位类型的总产出与战斗单位总数量的比值。
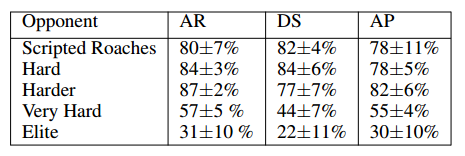
表 6:我们的智能体在不同地图面对不同对手时的胜率(100 场比赛)。我们的智能体仅在 AR 上训练。AR=深海礁岩(Abyssal Reef),DS=黑暗避难所(Darkness Sanctuary),AP=强酸工厂(Acid Plant)。
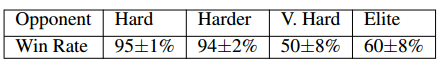
表 7:我们的智能体在深海礁岩中使用战争迷雾得到的胜率高出 10%(100 场比赛),这可能是因为学习到的构建顺序和战术可以更好地泛化到不完美信息,而内建智能体依赖于具体观察。
讨论
本研究与腾讯、罗切斯特大学和西北大学的联合研究《TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game》同时期开展,他们也提出了分层、模块化架构,并手工设计了宏指令动作。Berkeley 的研究者解释道,二者不同之处在于,本研究中的智能体是在模块化架构下仅通过自我对抗及与几个脚本智能体对抗来训练的,直到评估阶段才见到内建 bot。

上图是 TStarBots 的评估结果(有战争迷雾)。通过和表 4 对比我们可以发现,智能体在 L-4 到 L-7 级别的虫族对虫族对抗中取得的胜率普遍高于本文的研究。此外,Berkeley 的研究者并没有让智能体和作弊级别(L-8、9、10)的内建 bot 比赛。
不过,仅仅是这种表面的比较有失公允,它们还存在很多训练设置上的区别。例如,TStarBots 使用了单块 GPU 和 3840 块 CPU,而 Berkeley 在该研究中使用了 18 块 CPU;它们使用的强化学习算法也不同。关于两项研究中使用的方法,TStarBots 的论文中提出了两种架构:TStarBot1 和 TStarBot2,它们都包含了手工定义的宏操作,并且后者还拥有双层结构,可以兼顾微操层面的训练。其中 TStarBot1 定义了 building、production、upgrading、resource、combating 等宏操作。但是,TStarBot1 并没有类似本文中提出的更新者、策划者等模块,这些模块发挥的作用有更加广泛的含义,估计这也是研究者声称其方法具备更好泛化性能的原因。
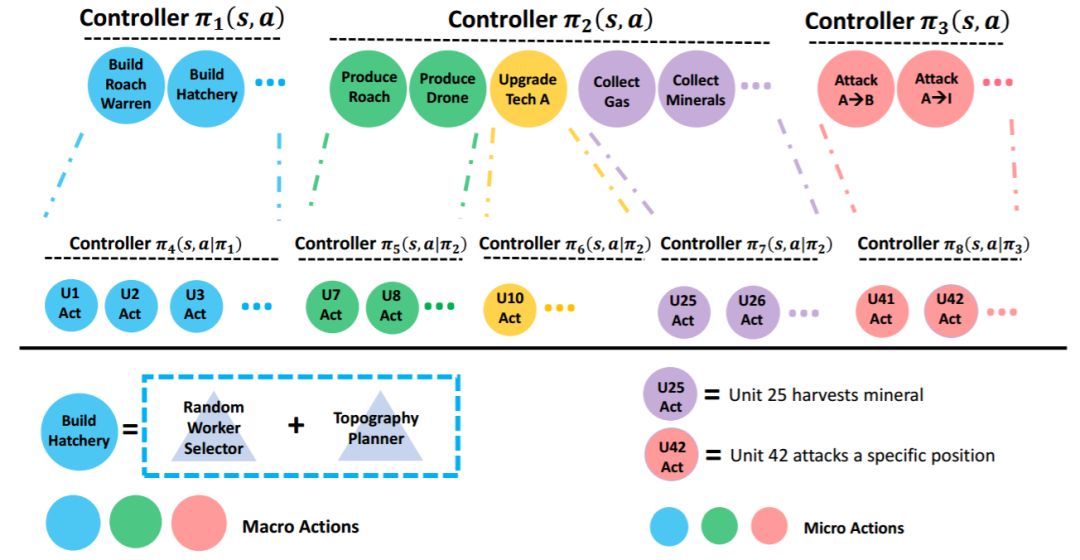
TStarBot2 双层结构。论文地址:https://arxiv.org/pdf/1809.07193.pdf
此外,南京大学近期也在星际争霸 II 上取得了不错的成绩。研究者让智能体通过观察人类专业选手游戏录像来学习宏动作,然后通过强化学习训练进一步的运营、战斗策略。他们还利用课程学习让智能体在难度渐进的条件下逐步习得越来越复杂的性能。在 L-7 难度的神族对人族游戏中,智能体取得了 93% 的胜率。这种架构也具有通用性更高的特点。
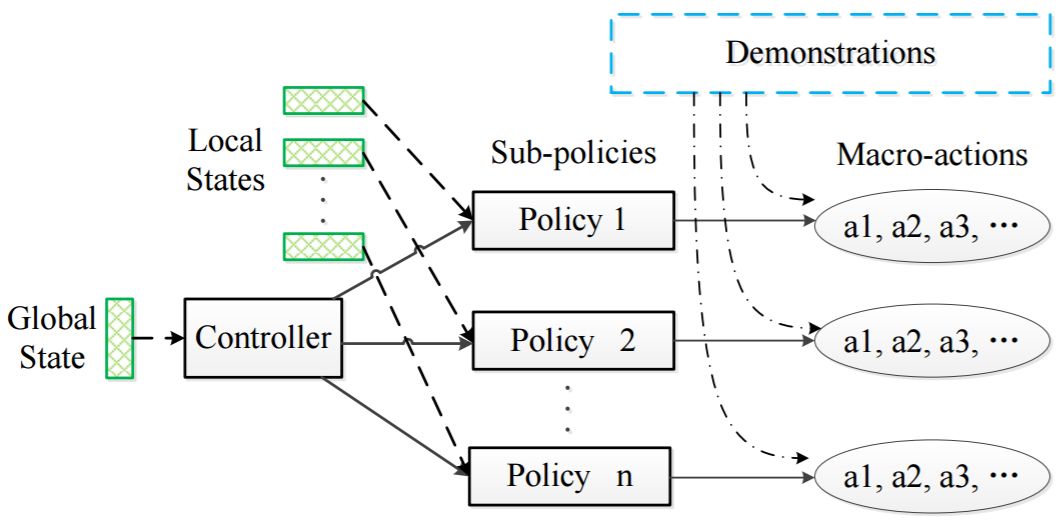
结合分层强化学习、自动生成宏动作和课程学习的架构。论文地址:https://arxiv.org/abs/1809.09095
总之,三项研究各有千秋,对架构设计的考量围绕着通用-专用权衡的主题,并且都抓住了宏指令(宏动作)定义的关键点,展示了分层强化学习的有效性。值得一提的是,这三项研究都是目前在星际争霸II 上能完成全场游戏的工作。

本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



