CVPR 2017五大研究前沿 | 腾讯AI Lab深度解析
感谢阅读腾讯AI Lab,我们将深度解析本届CVPR热门研究。第一部分是五大前沿领域的重点文章解析,包括低中层视觉、图像描述生成、3D视觉、计算机视觉与机器学习、弱监督下的图像识别等。第二部分是CVPR及我们计算机视觉团队简介等。接下来的两篇文章中,我们将对顶级会议ACL和ICML做类似深度解读,敬请期待。
腾讯AI Lab去年四月成立,今年是首次参展CVPR,共计六篇文章被录取(详情见文末),由计算机视觉总监刘威博士带队到现场交流学习。


腾讯AI Lab展台及CV科学家在Poster环节介绍论文
从研究领域和前沿思考出发,我们重点关注了五大领域的前沿研究,以下为重点论文评述。


在计算机视觉领域里,低中层视觉问题更关注原始视觉信号,与语义信息的联系相对松散,同时也是许多高层视觉问题的预处理步骤。本届CVPR有关低中层视觉问题的论文有很多,涵盖去模糊、超分辨率、物体分割、色彩恒定性(Color constancy)等多个方面,方法仍以深度学习为主。
其中在超分辨率有关的工作中,较为值得关注来自Twitter的Ledig等人所著文章[1]。这是第一篇将生成对抗网络(Generative Adversarial Network,简称GAN)思想用于图像超分辨率的研究(具体结构见下图)。以前的超分辨率方法,大都使用平均平方误差(Mean Square Error,简称MSE)导出的损失函数(loss),直接最小化MSE loss虽能得到不错的超分辨率结果,但难以避免细节上的模糊,这是MSE本身设计问题导致的。
[1]Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. Ledig C, Theis L, Huszár F, et al. In Proceedings of CVPR 2017.

虽然后来阿斯利康DNA测序机构的Johnson与斯坦福大学的Alahi等人[2]在ECCV 2016时中提出使用Perceptual loss替代MSE loss,获得了细节更丰富的超分辨率结果,但仍然有进步的空间。而Ledig等人的这篇论文在Perceptual Loss基础上加入GAN loss,约束超分辨率结果需符合自然图像分布规律,使超分辨率结果获得了非常逼真的细节效果。此方法也并非全无缺点,由于GAN loss考虑的是自然图像的整体分布,与具体输入图像(即测试图像)无关,因此恢复的图像细节可能并不忠实于原图,类似「捏造」出假细节,因此不适用于一些追求细节真实性的应用。
[2] Perceptual Losses for Real-Time Style Transfer and Super- Resolution. Johnson J, Alahi A, Fei-Fei L. In Proceedings of ECCV 2016.

使用GAN loss生成的结果(黄色方框)能够落在自然图像分布上(红色方框集合)。MSE loss虽能获得平均意义上的最小误差(蓝色方框),但却没落在自然图像分布上(红色方框的集合),因而丢失了很多图像细节。
未来,将GAN loss引入到视频超分辨率的解决方案中是一个很自然的扩展,相信很快会有研究工作出现。值得一提的是,Twitter的这批研究人员在本届CVPR还有一篇关于视频超分辨率的论文[3],虽未引入GAN Loss,但通过更好帧间对齐方法提升了视频超分辨率的可视化效果。
[3] Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation. Caballero J, Ledig C, Aitken A, et al. In Proceedings of CVPR 2017.
粗略统计,本届CVPR有16篇视觉描述生成相关论文,其中有8篇图像描述生成相关论文,其他论文多集中在视频描述生成方向。我们重点关注了其中几个较有代表性的研究:
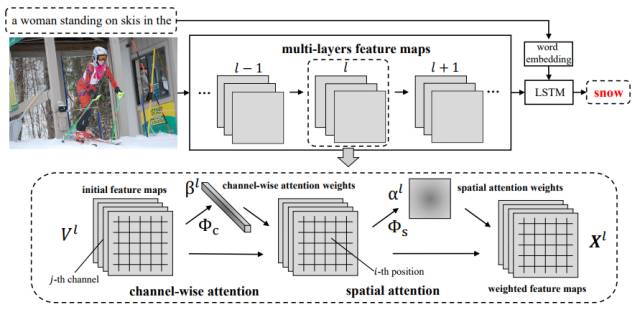
1)SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
这篇论文由腾讯AI Lab和浙江大学等机构合作完成,主要讨论了视觉注意力模型在空间与通道上的作用。该模型能动态提取随时间变化的上下文注意力信息。传统的注意力模型通常是针对空间设计的,例如在产生图像的描述的过程中,模型的注意力模型会注意图像的不同区域。但会忽略CNN中的通道和多层中的信息。这篇论文提出了一个全新模型SCA-CNN,可针对CNN中的空间和通道信息设计新的注意力模型。在图像描述生成任务中,该模型表现出了良好性能。
2)Self-Critical Sequence Training for Image Captioning
IBM Watson研究院发表的这篇论文直接优化了CIDEr评价标准(Consensus-based image description evaluation)。由于此目标函数不可微,论文中借鉴基础的强化学习算法REINFORCE 来训练网络。 该文提出了一个新的算法SCST(Self-critical Sequence Training),将贪婪搜索(Greedy Search )结果作为 REINFORCE 算法中的基线(Baseline),而不需要用另一个网络来估计基线的值。这样的基线设置会迫使采样结果能接近贪婪搜索结果。在测试阶段,可直接用贪婪搜索产生图像描述,而不需要更费时的集束搜索(又名定向搜索,Beam Search)。除了SCST,此论文也改进了传统编码器-解码器框架中的解码器单元,基于Maxout网络,作者改进了LSTM及带注意力机制的LSTM。综合这两个改进,作者提出的方法在微软的图像描述挑战赛MS COCO Captioning Challenge占据榜首长达五个月,但目前已被其他方法超越。
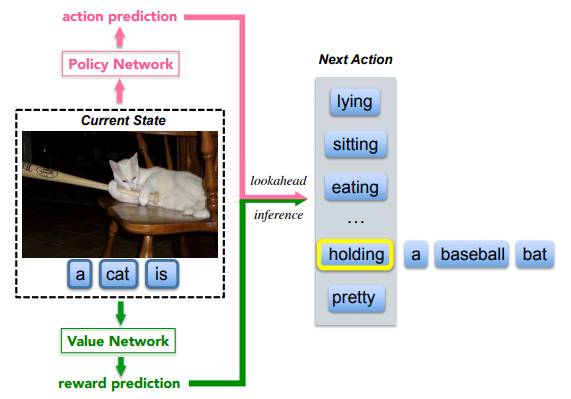
3)Deep Reinforcement Learning-based Image Captioning with Embedding Reward
由Snapchat与谷歌合作的这篇论文也使用强化学习训练图像描述生成网络,并采用Actor-critic框架。此论文通过一个策略网络(Policy Network)和价值网络(Value Network)相互协作产生相应图像描述语句。策略网络评估当前状态产生下一个单词分布,价值网络评价在当前状态下全局可能的扩展结果。这篇论文没有用CIDEr或BLEU指标作为目标函数,而是用新的视觉语义嵌入定义的Reward,该奖励由另一个基于神经网络的模型完成,能衡量图像和已产生文本间的相似度。在MS COCO数据集上取得了不错效果。
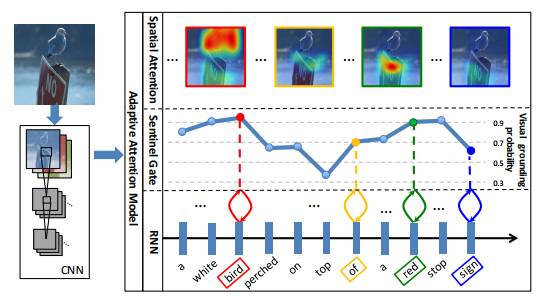
4)Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning
弗吉尼亚理工大学和乔治亚理工大学合作的这篇论文主要讨论自适应的注意力机制在图像描述生成中的应用。在产生描述语句的过程中,对某些特定单词,如the或of等,不需要参考图像信息;对一些词组中的单词,用语言模型就能很好产生相应单词。因此该文提出了带有视觉哨卡(Visual Sentinel)的自适应注意力模型,在产生每一个单词的时,由注意力模型决定是注意图像数据还是视觉哨卡。
在图像描述生成方面,本届CVPR还有很多其他方面的研究工作。包括在《Incorporating Copying Mechanism in Image Captioning for Learning Novel Objects》中,微软亚洲研究院将复制功能(Copying Mechanism)引入图像描述生成学习新物体,《Attend to You: Personalized Image Captioning With Context Sequence Memory Networks》一文用记忆网络(Memory Network)来定制个性化的图像描述生成。
近年来,由于视频数据大大丰富,也有一系列的工作讨论视频描述生成,包括复旦大学与英特尔合作的《Weakly Supervised Dense Video Captioning》,和杜克大学与微软合作的《Semantic Compositional Networks for Visual Captioning》等。
近年来,3D计算机视觉快速发展,被广泛应用在无人驾驶、AR或VR等领域。在本届CVPR,该研究方向亦受到广泛关注,并体现出两大特点:一方面其在传统多视图几何如三维重建等问题上有所突破,另一方面它也和现今研究热点,如深度强化学习等领域紧密结合。我们将对以下两个方向做进一步介绍:
1) Exploiting Symmetry and/or Manhattan Properties for 3D Object Structure Estimation From Single and Multiple Images
这篇论文为腾讯AI Lab、约翰霍普金斯大学及加州大学洛杉矶分校合作发表,作者主要讨论从二维图像中进行人造物体(如汽车、飞机等)的三维结构重建问题。事实上,绝大多数人造物体都有对称性以及曼哈顿结构,后者表示我们可以很容易在欲重建的人造物体上找到三个两两垂直的轴。如在汽车上,这三个轴可为两个前轮、两个左轮及门框边缘。作者首先讨论了基于单张图片的物体三维结构重建,并证明了仅用曼哈顿结构信息即可恢复图像的摄像机矩阵;然后结合对称性约束,可唯一地重建物体的三维结构,部分结果如下图所示。

然而,在单张图像重建中,遮挡和噪声等因素会对重建结果造成很大影响。所以论文后半部分转到了多张图像基于运动恢复结构(Structure from Motion, 简称SfM)及对称信息的物体三维重建中。事实上,SfM算法涉及到对二维特征点进行矩阵分解,而添加对称性约束后,我们并不能直接对两个对称的二维特征点矩阵直接进行矩阵分解,因为这样不能保证矩阵分解得到同样的摄像机矩阵以及对称的三维特征点坐标。在文章中,作者通过进一步利用对称性信息进行坐标轴旋转解决了这个问题。实验证明,该方法的物体三维结构重建及摄像机角度估计均超出了之前的最好结果。
2) PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning
本文由德国德累斯顿工业大学(TU Dresden)与微软联合发表,主要通过强化学习估计物体6D姿态。传统姿态估计系统首先对物体姿态生成一个姿态假设池(a Pool of Pose Hypotheses),接着通过一个预先训练好的卷积神经网络计算假设池中所有姿态假设得分,然后选出假设池中的一个姿态假设子集,作为新假设池进行Refine。以上过程迭代,最后返回得分最高的假设姿态作为姿态估计的结果。
但传统方法对姿态假设池Refinement的步骤非常耗时,如何选择一个较好姿态假设子集作为姿态假设池就变得尤为重要。本文作者提出了一同基于策略梯度的强化学习算法来解决这个问题。该强化学习算法通过一个不可微的奖励函数来训练一个Agent,使其选取较好的姿态假设,而不是对姿态假设池中的所有姿态进行Refine。
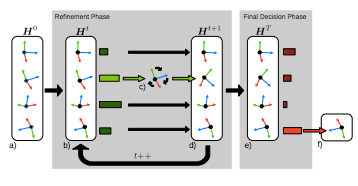
强化学习的步骤如上图所示。首先给强化学习Agent输入一个较大初始姿态假设池,然后该Agent通过对其策略采样,选择一个新的强化学习池,并对其进行Refine。上述过程达到一定次数后,最后求得的姿态假设池中得分最高的姿态假设即为所求得姿态。实验表明该方法在大大提高运行速度时,还得到超出此前最佳算法的估计结果。
计算机视觉与机器学习历来联系紧密,随着深度学习近年来在视觉领域取得的空前成功,机器学习更是受到更广泛的重视。作为机器学习一个分支,深度学习依然是计算机视觉领域绝对主流。但与前几年不同的是,纯粹用深度学习模型「单打独斗」解决某个视觉问题似乎不再流行。
从近两届CVPR论文看,深度学习模型与其它传统的机器学习分支模型的融合渐成趋势,既利用深度学习模型的优异性能,又利用传统模型的成熟理论基础,取长补短,进一步提高性能并增加了深度学习模型透明度。本届CVPR上这种融合趋势可分为两个具体方向:一个是传统机器学习模型方法与深度学习模型深度融合,让后者能设计更好模型;另一个是用传统机器学习理论解释或阐述深度学习模型性能。我们关注到相关的重点论文如下:
一、传统机器学习模型方法与深度学习模型深度融合
1)On Compressing Deep Models by Low Rank and Sparse Decomposition
矩阵的低秩稀疏分解是经典机器学习方法,假设一个大规模矩阵可分解为两个或多个低维度矩阵的乘积与一个稀疏矩阵的和,从而大大降低原矩阵表示元素个数。在这篇由优必选悉尼AI研究所、新加坡理工大学和悉尼大学共同完成的论文中,该方法被用来模拟深度学习的滤波参数矩阵,在保证模型性能同时,大大降低了参数个数,这对深度学习模型的进一步推广,尤其是智能手机端应用会有很大推动作用。类似文章还有杜克大学的这篇[1]。
[1] A compact DNN: approaching GoogLeNet-Level accuracy of classification and domain adaptation

2)Unsupervised Pixel–Level Domain Adaptation with Generative Adversarial Networks
领域自适应(Domain Adaptation)是迁移学习(Transfer Learning)的一种,思路是将不同领域(如两个不同的数据集)的数据特征映射到同一个特征空间,这样可利用其它领域数据来增强目标领域训练。深度学习模型训练需要大规模数据,这篇由谷歌发表的文章,提出的思路是对真实物体进行渲染(Rendering),制造大量人造渲染图像,从而帮助深度学习模型训练。
然而,渲染图像与真实图像之间有很大差异(比如背景差异),直接用渲染图像训练得到的深度学习模型并没有产生很好识别性能。本文将渲染图像和真实图像看作两个领域,并结合当前流行的生成对抗网络修正渲染图像,得到更加贴近真实图像的渲染图像(如下图所示:加上类似的背景)。最后再利用这些修正后的渲染图像训练深度学习模型,取得了很好效果。

二、传统机器学习理论解释或阐述深度学习模型性能
1)Universal Adversarial Perturbations
在现有研究和实际应用中,深度学习模型被观察到对样本噪声或扰动比较敏感,比如在原始图像上加一些很小的噪声或变形,都可能造成误分类。但对什么类型、多大幅度的噪声或扰动会引起这种错误,我们还知之甚少。洛桑联邦理工大学和加州大学洛杉矶分校合作的这篇论文对此问题进行了初步探索。
文章基本思想是围绕机器学习中的分类边界和间隔,在原始图像特征空间中计算出一个最小扰动向量,使原始图像跨过分类边界造成误分类。计算得到的这个最小扰动向量被称为通用扰动向量,因为该向量值与模型相关并与具体的图像独立。作者分析了VGG、GoogLeNet和ResNet-152等多个主流深度学习模型,发现其对于相对应的通用扰动向量非常敏感。这项研究对了解深度学习模型的分类边界和模型鲁棒性有很大帮助。
2)Global Optimality in Neural Network Training
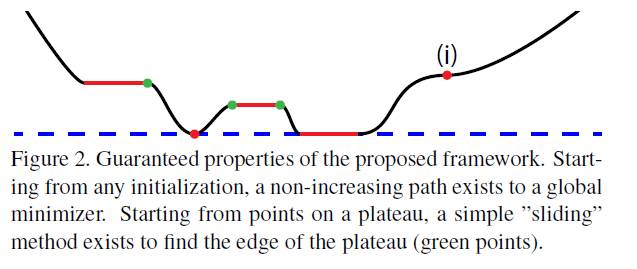
常用深度学习网络中,往往会用到很多非线性函数,如Sigmoid激励函数和ReLu激活函数等,所以整个网络可被看做是一个非线性复合映射函数。这样的函数很大可能是非凸函数,在优化过程中存在很多局部最优解,增加了模型训练难度。但约翰霍普金斯大学的这篇论文证明,在网络构成函数满足一定假设时,能保证得到全局最优解。背后原理是使整个网络的搜索空间只包含全局最优解和平台解,而不存在局部最优解(如下图所示)。
该文的证明运用了机器学习中的矩阵分解和对应的优化理论。这项研究工作展示了全局最优解在深度神经网络中存在的条件,为我们设计更加容易训练的模型提供了有价值的指导。
深度学习成功的一大关键因素是大量训练数据,但现实场景中对海量数据作精细数据标注需要大量人力和财力,这就回到了计算机视觉中的基本问题:目标检测 (Object Detection)和语义分割(Semantic Segmentation)。本届CVPR也有论文关注弱监督下该问题的解决,我们将介绍两篇仅依赖图像级别标注的相关研究。
1)Deep Self-taught Learning for Weakly Supervised Object Localization
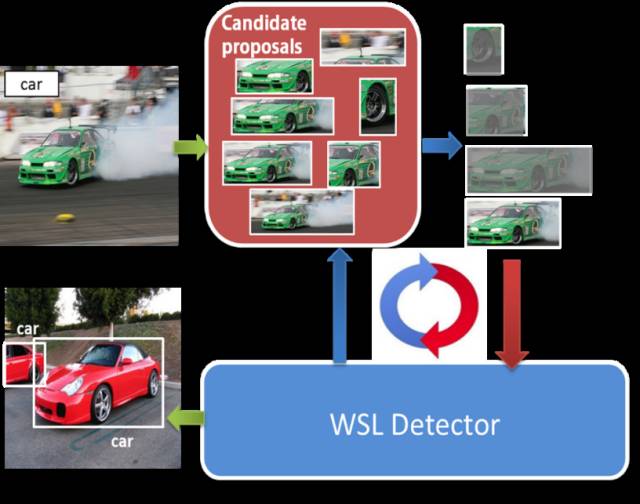
这篇最具代表性的目标检测论文由腾讯AI Lab和新加坡国立大学合作完成。在检测器训练时,该文提出了一种依靠检测器模型自主动态挖掘高质量正例样本的方法。鉴于CNN检测器有强大的拟合训练样本能力,错误训练样本 (False Positive)同样能获得较高类别置信度。但当检测器训练其它正例样本时,错误训练样本获得的类别置信度增量 (Relative Score Improvement) 较小,因此当检测器在训练其它Positive样本时,一个Object Proposal获得的类别置信度增量大小可有效反映该样本的真实质量 (True Positive或False Positive)。依赖类别置信度增量动态挖掘高质量训练样本,可有效增强检测器性能。 该文在PASCAL VOC 07和12目标检测任务上取得了目前最先进的效果。
2)Object Region Mining with Adversarial Erasing: a Simple Classification to Semantic Segmentation Approach
这篇有代表性的语义分割论文来自新加坡国立大学,提出了用分类网络解决语义分割的新方法。分类网络能提供目标物体的显著区域 (Discriminative Part),但语义分割要求对目标物体全部像素的精确预测,该文利用了一种逐步擦除显著区域方法,不断提高分类网络预测难度。当擦除显著区域和重新训练分类网络交替,按从主要到次要的顺序逐渐获得目标物体全部区域,训练出一个高性能语义分割网络模型。该方法在PASCAL VOC 07和12语义分割问题上取得了目前最佳效果。

一分钟数读CVPR
CVPR是近十年来计算机视觉领域全球最有影响力、内容最全面的顶级学术会议,由全球最大的非营利性专业技术学会IEEE(电气和电子工程师协会)主办。今年会议于7月21日至26日在美国夏威夷举行。
在评估会议的学术影响力指标上,本次会议均创新高 —— 论文有效提交数为2620篇(40%↑)、录取数为783篇(22%↑)、注册参会人数4950人(33%↑),并在新发布的2017谷歌学术指标中,成为计算机视觉与模式识别领域影响力最大的论文发布平台。
在产业影响力指标上,会议赞助金额近86万美元(79%↑),赞助商高达127家(30%↑),囊括了Google、Facebook及腾讯等科技巨头,也有商汤、旷视等众多初创企业。
录取论文涉及领域占比最高的五类是:计算机视觉中的机器学习(24%)、物体识别和场景理解(22%)、3D视觉(13%)、低级和中级视觉(12%)、分析图像中的人类(11%)。
大会共设44个研讨会(workshop)、22个教程辅导(tutorial)和14场竞赛,覆盖语言学、生物学、3D建模和自动驾驶等计算机视觉的细分领域。
现场论文展示分三种形式:12分钟长演讲(Oral)4分钟短演讲(Spotlight)和论文海报展示(Poster),长短演讲共215场,海报展示112个。在参会心得上,我们建议重点参加口述演讲,会对精选文章做长或短的进一步解读;而海报展示数量多、内容杂,只在固定时段有,要用好地图和会程指引,有选择地、集中地参加此环节。展会区囊括各类企业,会从研究到应用进行展示讲解,可选择性参加。
腾讯AI Lab成立于2016年4月,专注于机器学习、计算机视觉、语音识别和自然语言理解四个领域「基础研究」,及内容、游戏、社交和平台工具型四大AI「应用探索」,提升AI的决策、理解及创造力,向「Make AI Everywhere」的愿景迈进。
腾讯AI Lab主任及第一负责人是机器学习和大数据专家张潼博士(详情可点链接),副主任及西雅图实验室负责人是语音识别及深度学习专家俞栋博士。目前团队共有50余位AI科学家及200多位应用工程师。
计算机视觉团队(CV团队)是最早组建的研究团队之一,目前有十多位基础研究科学家,大多拥有国内外院校博士学位,并与一个较大的应用工程师团队紧密合作,由计算机视觉和机器学习专家刘威博士领导。我们很注重对青年研究者的培养,团队中应届毕业的博士接近半数,也将继续在海内外招募不同级别的优秀研究者。
在基础和前沿研究方向上,CV团队聚焦中高层视觉,尤其视频等可视结构数据的深度理解,同时也在重要的交叉领域发力,如视觉+NLP、视觉+信息检索等。正在进行或计划中的研究项目兼具了挑战性和趣味性,包括超大规模图像分类、视频编辑与生成、时序数据建模和增强现实,这些项目吸引了哥伦比亚和清华等海内外知名大学的优秀实习生参与。
团队在本届CVPR上有六篇文章被录取,下面论文一提到的实时视频滤镜技术已在腾讯QQ手机版上线,实现了基础研究到产品应用的迅速转化,正是我们「学术有影响,工业有产出」目标的体现。
腾讯AI Lab共六篇论文入选本届CVPR
论文一:Real Time Neural Style Transfer for Videos
本文用深度前向卷积神经网络探索视频艺术风格的快速迁移,提出了一种全新两帧协同训练机制,能保持视频时域一致性并消除闪烁跳动瑕疵,确保视频风格迁移实时、高质、高效完成。
论文二:WSISA: Making Survival Prediction from Whole Slide Histopathological Images
论文首次提出一种全尺寸、无标注、基于病理图片的病人生存有效预测方法WSISA,在肺癌和脑癌两类癌症的三个不同数据库上性能均超出基于小块图像方法,有力支持大数据时代的精准个性化医疗。
论文三:SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
针对图像描述生成任务,SCA-CNN基于卷积网络的多层特征来动态生成文本描述,进而建模文本生成过程中空间及通道上的注意力模型。
论文四:Deep Self-Taught Learning for Weakly Supervised Object Localization
本文提出依靠检测器自身不断改进训练样本质量,不断增强检测器性能的一种全新方法,破解弱监督目标检测问题中训练样本质量低的瓶颈。
论文五:Diverse Image Annotation
本文提出了一种新的自动图像标注目标,即用少量多样性标签表达尽量多的图像信息,该目标充分利用标签之间的语义关系,使得自动标注结果与人类标注更加接近。
论文六:Exploiting Symmetry and/or Manhattan Properties for 3D Object Structure Estimation from Single and Multiple Images
基于曼哈顿结构与对称信息,文中提出了单张图像三维重建及多张图像Structure from Motion三维重建的新方法。
点击阅读原文了解更多



