进阶|对于node直出,鹅厂大神都做了什么
前端爱好者的知识盛宴

此干货供稿者乃鹅厂大神--樊东东
当小编提出能否将其干货文章发表在公众号上时
大神一口答应并发出爽朗的笑声
嘻嘻嘻...
还送上了其前端开发者github的200star整理的文档
小编小心翼翼的收下
并附在了原文链接中!
各位技友各取所需~
正文
web前端发展路程
web页面最开始都是一个个静态页面,再加上些动态效果,但资源都是静态的。人们想根据需要,不同的用户、不同的场景生成不同的页面,这就有了asp、jsp等动态页面生成技术,这个时候的web开发者基本前后端一起写。
ajax的兴起,前端能做的事更多了、更复杂了,前端门槛和地位也更高了,这时候催生了前后端分离。
前端从后端拿数据,然后只需要关注页面逻辑,后端只需要提供接口不用关注复杂的前端逻辑,专业的专注的做自己喜欢和擅长的事,大家开发起来似乎都很爽。
然鹅,移动H5的兴起,人们对产品体验的重视,移动H5的起始白屏时间让大家难以忍受,为了减少白屏时间、提升页面加载速度和利于SEO,这时候就有了服务器直出。
什么是服务器直出
直出跟传统的jsp等服务器动态生成页面不完全相同
原先页面交互没有现在这么复杂,jsp等服务器动态生成页面的年代,大多还是表单提交的方式,直接刷新整个页面。
服务器直出我理解为服务器动态生成页面和ajax技术的结合。打个比方,页面有main、a、b三个模块,为了提升页面加载速度,main模块内容在服务器端生成好,a和b模块内容在浏览器端通过ajax加载数据的方式。
似乎服务器直出也并一定需要node。但假如main模块含有一个列表模块c,服务器端先生成十条记录,浏览器端需要加载更多的话,再从后端拉取数据动态生成。这时候就涉及到View层的前后端代码复用,node因为用js写的,天生就适合用来做服务器直出。前后端分离嚷嚷了辣么久,这时候前端同学也要写服务器端了。
前端的地位更高了。
前不久参加AlloyTeam的前端大会,学习了QQ兴趣部落的node直出的经验ppt,现在分享下我们团队的实践经验。
Node直出
1.纯前端
代码架构随着业务的发展改变的
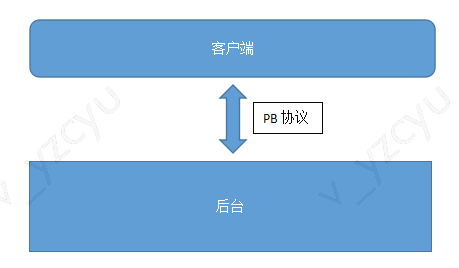
最开始我们的产品没有H5页面,只有客户端。后台通过PB协议提供接口给客户端。
后来有了H5的需求,主要用作信息展示,没有登陆,不涉及数据提交和修改
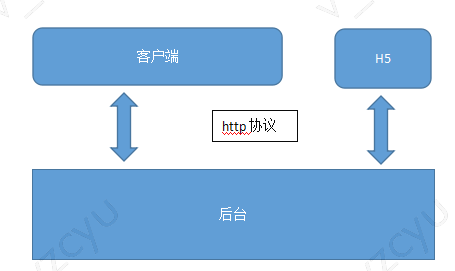
因为只是数据展示,页面交互不多不复杂,我们用了轻量的模版引擎art-template,打包编译用webpack结合gulp。数据通过ajax的方式拉取,在浏览器端渲染生成页面,先把功能实现。
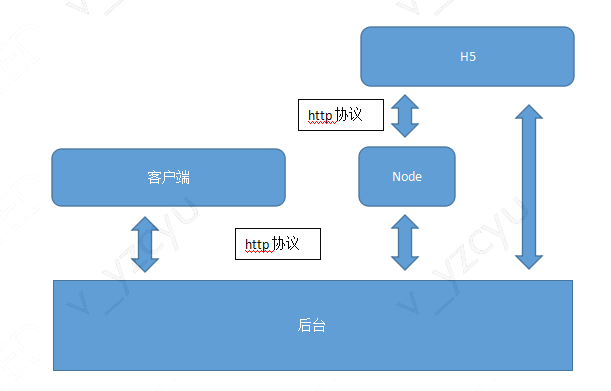
2.node直出—V层复用
产品和开发都是有洁癖的,为了提高页面加载速度、减少白屏时间和利于SEO,我们采用了直出的模式。
3.ajax请求合并
有些页面,除了主要内容在服务器端生成,很多关联内容在浏览器端ajax调用多个后台接口生成。有了node做服务器,可以将ajax调用封装下,连续多个请求可以合并成一个请求通过node层转发。
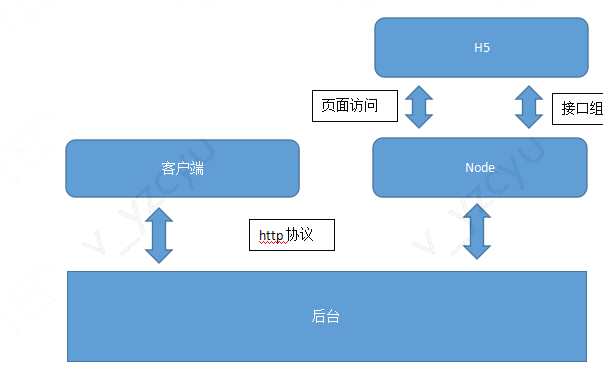
4.M层以及更多的模块复用
这时候服务器直出的工作已经完成了,在网上看的一些关于直出的文章,差不多就讲到这里了。不同的是很多人利用react、vue等流行的框架做直出,我们这里用不到这么重的框架只用了art-template做模版引擎前后端复用,原理是差不多的。
码农追求优化的脚步是永不停歇的,还可以做更多么?
现在软件架构大家都喜欢说自己是基于MVC模式的,到目前为止,我们前后端只是复用了V层。后台提供的一个数据接口,node端调用,浏览器端也会调用,一样的功能但这得写两份调用代码。某个工具方法,前后端都会用到,但前后端的环境不同、api不同,例如获取浏览器ua,
在浏览器端

在服务器端

那么可不可以做到在业务逻辑层调用模块A,不管是浏览器端引用还是服务器端引用,业务层都不需要关心模块A底层如何实现,只需要关心模块A提供了什么功能。
打个比方:后台提供数据接口A,浏览器端ML模块调用A,服务器端MF模块调用A。浏览器端调用不了MF模块,会报错。服务器端调用不了ML模块,会报错。现在统一用模块MT,浏览器端和服务器端都可以引用MF来调用A。可以理解为MT模块自动适配自己是ML还是MF。
我们想要的是不光复用V层,也能复用M层。
有人会说在代码里判断是服务器端还是浏览器端执行不同代码。but,我们用webpack编译,最后生成的文件可能会包含很多服务器端才用的上的模块,引用的第三方库可能也会运行服务器端才有的api,在浏览器端会报错。
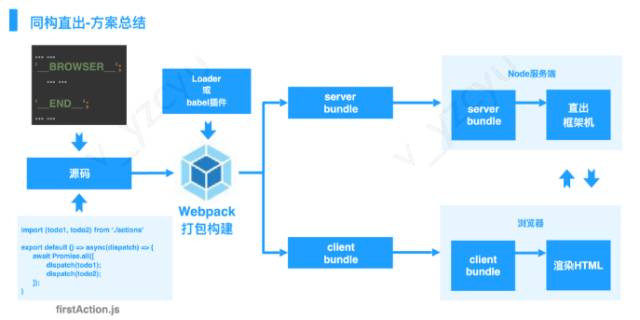
如何实现?经过一番思考和资料查询,决定在源码编译这个层面区分前后端代码。
在源文件中,包含前后端各自代码,用条件判断语句包裹,在编译的过程中根据配置对源文件中内容进行选择过滤,前端引用为前端生成的文件, 后端引用为后端生成的文件。虽然也有点麻烦,但可以在工具方法层集中处理,更进一步通用代码,对业务层代码透明。
5.源码编译成前后端各自使用的代码
AlloyTeam兴趣部落直出讲座的ppt上给出的方案如下

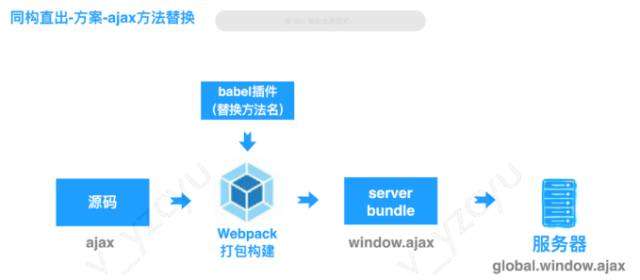
总结下,大概就是一份源码编译成两份代码。通过webpack的loader或babel插件,编译成server端运行的代码时,将__BROWSER__和__END__中间的代码去掉。
调用数据接口,编译前端代码的时候将方法名替换成前端用的方法名。
从ppt了解的信息推断,AlloyTeam很可能将源码编译成两份代码,服务器端执行的和浏览器端执行的。
6.webpack的loader根据环境生成不同的源码
我在网上找到一类根据条件输出不同代码的webpack的loader if-loader和ifdef-loader。其中if-loader只能判断if,没有判断else的功能。ifdef-loader用ts实现的,可能是为webpack1准备的,options只能在loader?后面追加条件。相比if-loader增加了else的判断。
如下所示:


编译成浏览器端的代码

笔者在ifdef-loader的基础上做了完善,新写了ifelse-loader:保留ifdef-loader的功能的基础上,options可以在webpack配置文件中用options配置,不用追加在loader?后的参数中。
配置
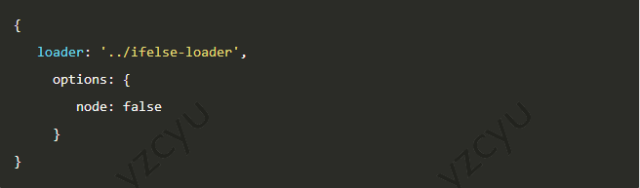
在node端如果引用原文件的话,为前端准备的代码会遗留在源文件中造成代码冗余。有些前端文件在es6的标准下会使用import等node不支持的语法,引用这些类库会在服务器端造成报错。
webpack在编译的时候将源文件a编译一份放到当前目录生成_node_a文件, node端引用a的时候会转而引用_node_a。因为node中每个模块的require都是独立的,没有统一的地方改写,所以另外写了个ISRequire包装原require
如下:
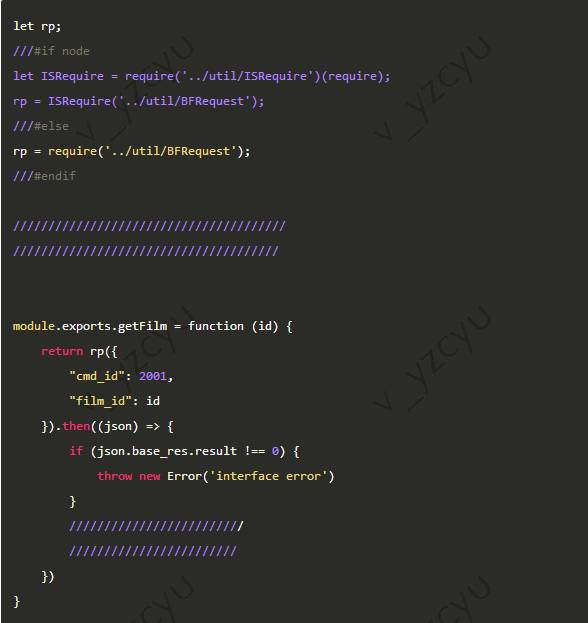
接口调用的源文件,BFRequest.js
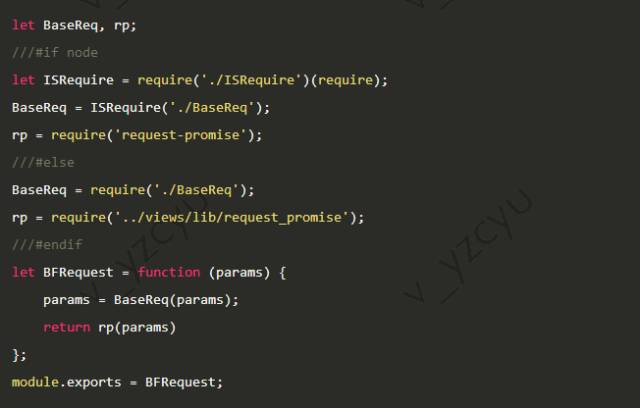
request-promise是服务器端http请求的模块,../views/lib/request_promise是浏览器端封装的ajax请求模块
BFRequest.js会另外生成一份_node_BFRequest.js
filmModel.js是前后端都会用到的模块,引用BFRequest.js调取数据
用ISRequire包裹require,node端用ISRequire读取BFRequest.js,实际读取的_node_BFRequest.js。
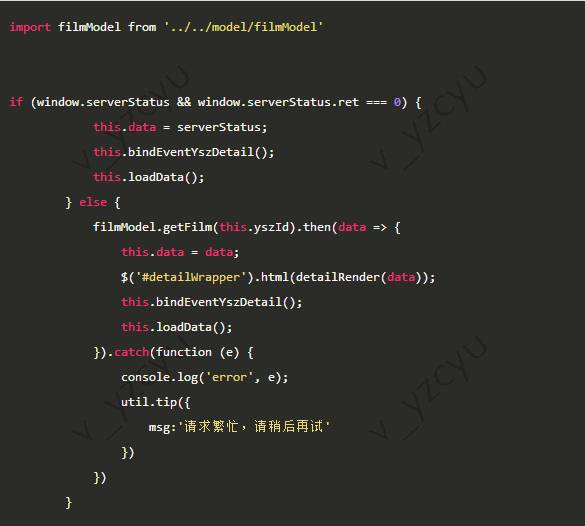
服务器端代码,引用filmModel.js
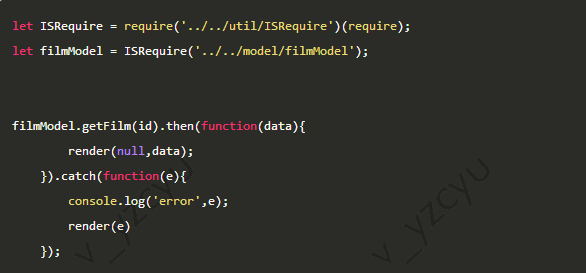
浏览器端代码,如果主内容生成失败,会引用filmModel.js继续尝试生成主内容。浏览器端保留内容全部动态生成的能力。
7.ifelse-loader结合静态文件存CDN的工程化实践
web开发者都知道静态文件存cdn的好处,但知易行难。
总结下静态文件存cdn在实践中遇到的问题:
简单点项目,静态资源丢cdn,手动改写html、css等文件中的资源引用为cdn路径。项目复杂点呢?每次都手动改写么?有些团队是重构和业务逻辑分不同人写的,重构可能不需要关心资源是不是cdn路径,直接丢给业务开发重构好的页面,手动修改引用路径是不现实的。
项目发布的时候,先发布静态资源还是先发布代码呢?先发布静态资源,覆盖了cdn资源,线上代码怎么办?先发布代码,cdn没有对应的静态资源,还是会有问题。这里就需要给静态资源打上指纹,发布到cdn的时候不会覆盖已有资源,接着发布代码就没问题了。开发环境下还是引用的本地目录,不可能每改点东西就发一次cdn吧。
知道要怎么做了,但到底要怎么做呢?张云龙在前端工程——基础篇介绍了思路。按照这个思路,我将静态资源放到一个发布目录,将文件名改成:路径.hash.ext的形式,将文件和hash的对应关系写在资源表文件中。如:
文件路径
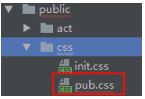
发布目录中的文件名
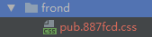
资源表

资源表还可以用来比对hash判断只发布有更新的静态资源,增量发布
原静态资源也会随着node代码一起发布,线上页面保留能访问node端静态资源的能力。模版文件中资源引用调用注入的方法cdnPath,在浏览器端的话该方法不做任何调整,在服务器端如果开发环境不做调整,非开发环境下会根据资源表调整为cdn路径

模版注入方法的文件template.js
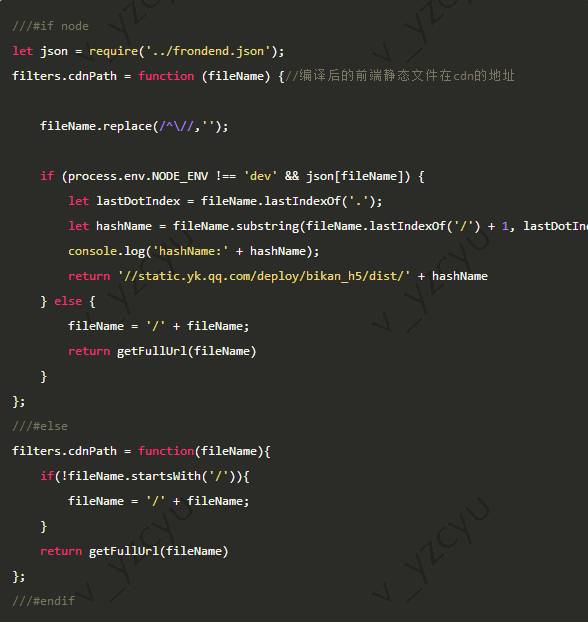
利用ifelse-loader前后端引用同一个模块
node端

浏览器端

最后的效果如图:
开发环境下
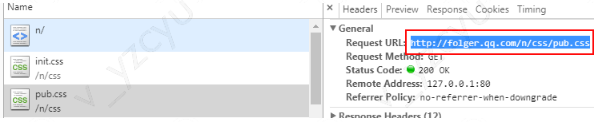
测试环境下

不足
1.前后端代码写在同一份文件中的时候不能使用 import 等node不支持的语法
2.因为let重复定义会报错,可以直接使用var或用let先定义后赋值
3.一定程度上的代码啰嗦和不好看
4.写的时候有点绕
收获
1.搞这么麻烦,肯定是要有收益的,前后端代码除了V层,更多的模块可以复用。减少了文件数,业 务逻辑更清晰。
2.做直出和静态资源放cdn,可以明显感觉到页面打开速度快了很多,以前手机隔一段时间访问页面,会白屏很久甚至打开失败,现在感觉比秒开更快。
3.查阅了不少前端资料,也实践了很多,碰到走不通的地方跳转方向尝试,对前端工程化有了更深入全面的认识。
OVER
嗨
这里是IMWEB
一个想为更多的前端人
享知识
助发展
觅福利
有情怀有情调的公众号
欢迎关注转发
让更多的前端技友一起学习发展~





