Kaggle:纽约的士旅程数据简要分析

作者:colacola,R语言中文社区专栏作者。知乎专栏:https://www.zhihu.com/people/colacola-40/posts
前言
本文数据来自于kaggle一个还在进行中的playground级别竞赛,公众号后台回复“的士”下载数据集。
选用train.csv中145万余条的数据记录进行相关数据分析的基础练习,使用工具为R。
参考该项目下Kernels中一些大神的思路方法,我会在这里分享代码和一些图表展示。
总述
先看看官方给出的这145万余条数据的字段信息描述:
id - a unique identifier for each trip
vendor_id - a code indicating the provider associated with the trip record
pickup_datetime - date and time when the meter was engaged
dropoff_datetime - date and time when the meter was disengaged
passenger_count - the number of passengers in the vehicle (driver entered value)
pickup_longitude - the longitude where the meter was engaged
pickup_latitude - the latitude where the meter was engaged
dropoff_longitude - the longitude where the meter was disengaged
dropoff_latitude - the latitude where the meter was disengaged
store_and_fwd_flag - This flag indicates whether the trip record was held in vehicle memory before sending to the vendor because the vehicle did not have a connection to the server - Y=store and forward; N=not a store and forward trip
trip_duration - duration of the trip in seconds
一共11个字段,其中包括上下车时间、上下车经纬度、旅程时长、乘客人数、数据记录发送类别(储存发送还是直接发送)、数据提供者的id编号
正文
#用到的包
library(dplyr)
library(lubridate)
library(data.table)
library(geosphere)
library(ggplot2)
library(gridExtra)第一部分:数据的基本概况和处理
#1.数据读取
train <-tbl_df(fread("train.csv"))由于数据量较大,使用fread函数进行读取,并转化为tbl对象类型
#2.数据的基本情况
class(train)
glimpse(train)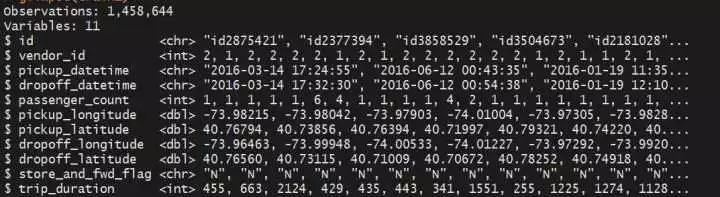
summary(train)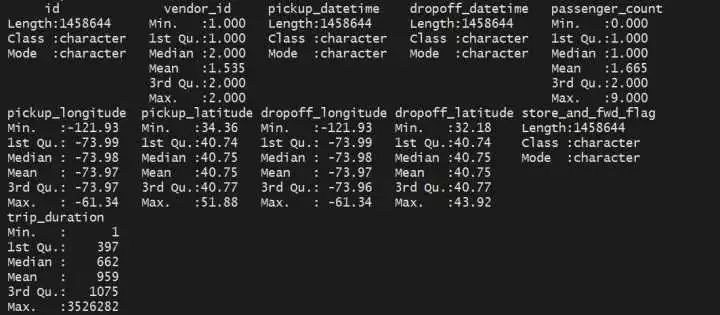
(1)上下车时间为chr类型,需转化为时间类型
(2)vendor_id有可能不是1就是2,是不是可以把这个字段理解为出租车公司的编号(公司1、公司2)
(3)旅程时长最长的为3526282秒,我的天,将近41天??
(4)乘客数目的中位数为1,平均数为1.665,可以先推测一下,是不是单人打车的情况最多见?
#3.看看有没有缺失值####
sum(is.na(train))
这简直是个福音,没有缺失值的数据集是多么的可爱
#4.把上下车时间、出租车公司的ID、乘客数改一下字段类型
train <- train %>%
mutate(pickup_datetime = ymd_hms(pickup_datetime),
dropoff_datetime = ymd_hms(dropoff_datetime),
vendor_id = factor(vendor_id),
passenger_count = factor(passenger_count))#5.trip_duration和上下车时间计算出来的数据是否一致
train %>%
mutate(check = abs(int_length(interval(pickup_datetime,dropoff_datetime))
- trip_duration) == 0) %>%
select(check,pickup_datetime,dropoff_datetime,trip_duration) %>%
group_by(check) %>%
count()
#6.添加一些字段
#(1)从上车时间可以提取出星期几、月份、时段,添加这三个字段
train <- train %>%
mutate(weekday = wday(pickup_datetime,label = TRUE),
month = month(pickup_datetime,label = TRUE),
hour = hour(pickup_datetime))#(2)从上下车经纬度可以整合出两点之间的距离(km),除去路程时长,可以得出速度,添加这两个字段
pickuplocation <- train %>%
select(pickup_longitude,pickup_latitude)
dropofflocation <- train %>%
select(dropoff_longitude,dropoff_latitude)#距离,单位为km
train <- train %>%
mutate(distance = distHaversine(pickuplocation,dropofflocation)/1000)
#速度,单位km/h
train <- train %>%
mutate(speed = distance/trip_duration*3600)
第二部分 数据可视化展示(单字段)
经过第一部分对原始数据简单的了解及处理,进行相对应的数据可视化展示,先单独看看各个字段的数据情况:
(1)观测vendor_id的情况
p1 <- train %>%
ggplot(aes(vendor_id,fill = vendor_id)) +
geom_bar() +
theme(legend.position = "null")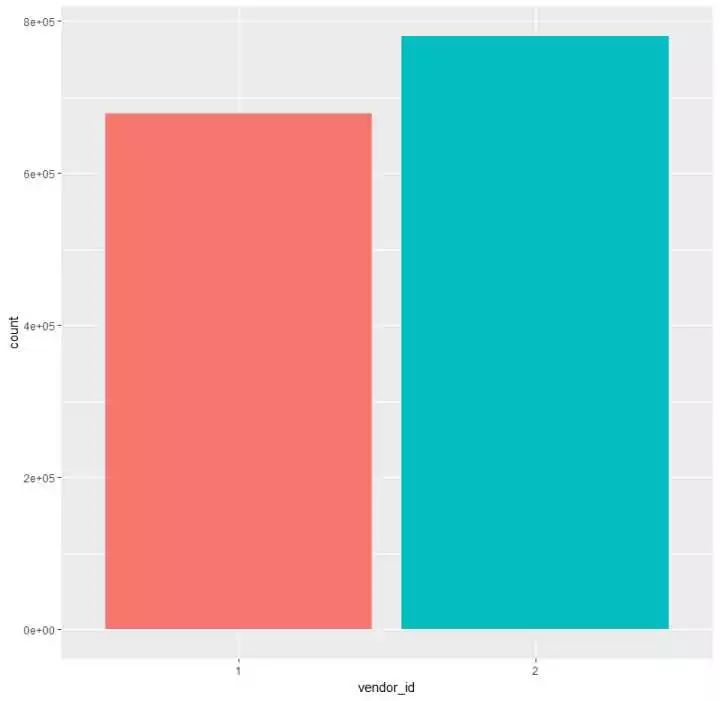
发现和之前的假设相同,只有两种情况,且vendor_id为2的情况比vendor_id为1的情况多了10W条左右
(2)#观测上车、下车时间的分布情况;组合对比一下
p2 <- train %>%
ggplot(aes(pickup_datetime)) +
geom_histogram(bins = 250,fill="orange")
p3 <- train %>%
ggplot(aes(dropoff_datetime)) +
geom_histogram(bins = 250,fill="skyblue")
p23 <- grid.arrange(p2,p3,nrow =2)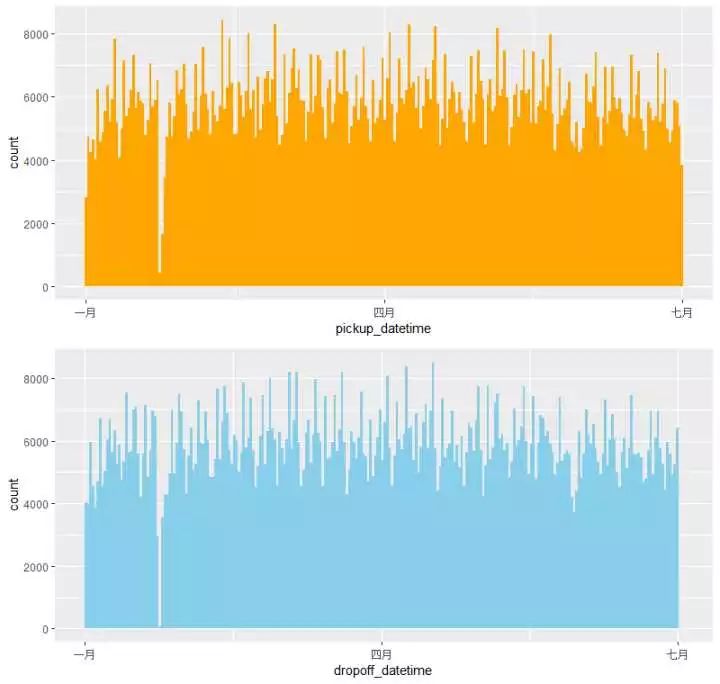
发现:
(1)所有的打的记录都在1-6月份
(2)大体上看去整个分布还是比较均匀的,但是在1月底2月初之间出现了一个很明显的回落趋势,来放大这个区间看看情况:
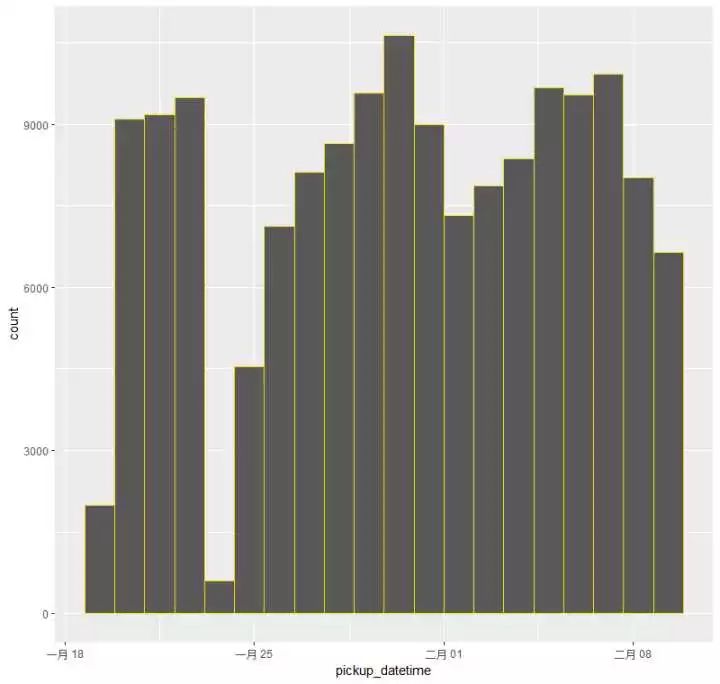
是那几天出租车涨价?还是类似于停电一小时的活动,呼吁不打的活动?还是天灾人祸?
google一下,答案是暴!风!雪!


(3)看看乘客数量的一个分布
p4 <- train%>%
ggplot(aes(passenger_count,fill = passenger_count)) +
geom_bar() +theme(legend.position = "null") +
scale_y_sqrt()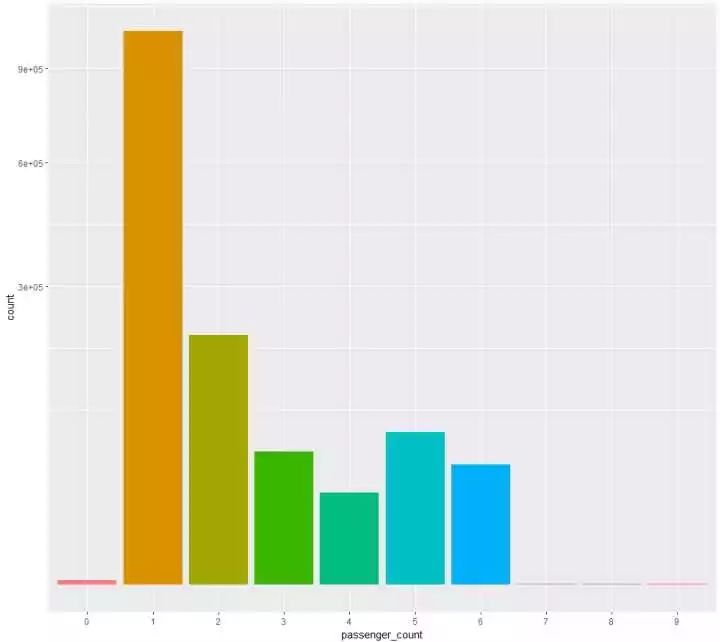
(1)单人打车的情况最多,在145万多条的记录中,有100W+是单人打车的情况
(2)出现了乘客为0的打的记录
(3)原来美国出租车还可以坐四个以上的乘客,而且5、6名乘客情况还不少,中国的的士有可以坐4个以上乘客的吗?
(4)看看记录是否第一时间发送服务器的情况分布
p5 <- train %>%
ggplot(aes(store_and_fwd_flag,fill = store_and_fwd_flag)) +
geom_bar() +theme(legend.position = "null") + scale_y_log10()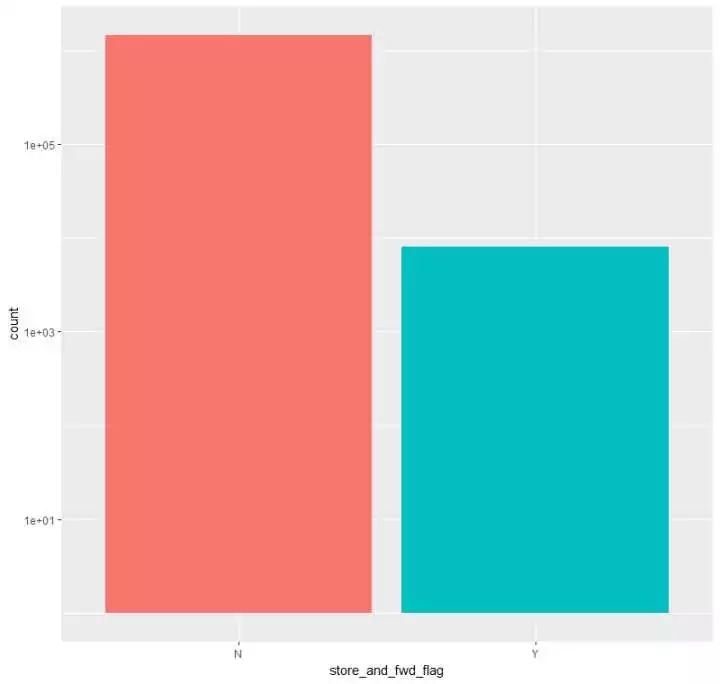
(5)看看旅行时长的分布
p6 <- train %>%
ggplot(aes(trip_duration)) +
geom_histogram(bins = 10000,fill="red") + coord_cartesian(x=c(1,6000))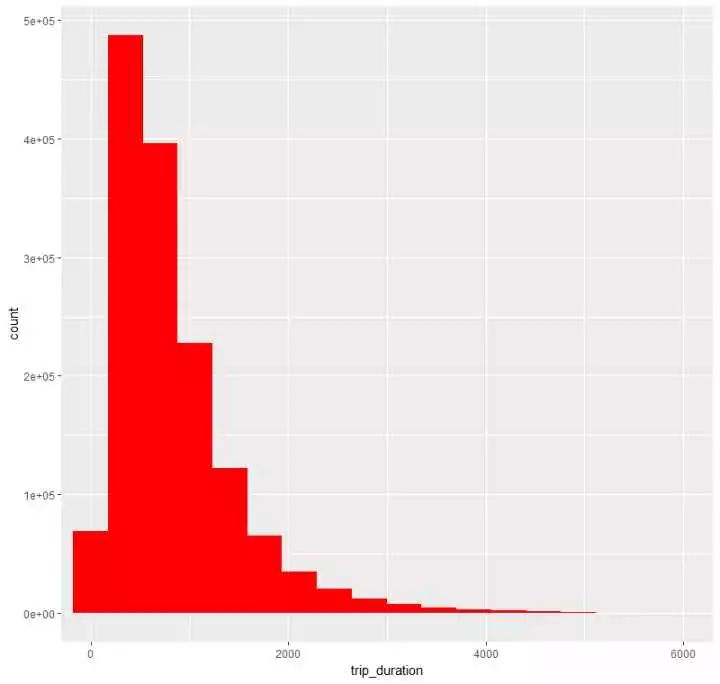
看出,主要的时长还是集中在1000秒左右,即15分钟这样,当然还有一些时间非常短或则特别长的情况发生
(6)接下来按时间分布来观测下打车情况,哪个时段打车多?星期几出租车最忙?
#看看每天打的数量的分布\趋势
p7<- train %>%
group_by(weekday) %>%
count() %>%
ggplot(aes(weekday,n,group=1)) +
geom_line(size=1.5,color="lightblue") +
geom_point(size=1.5,shape =17)#看看每月打的数量的分布\趋势
p8<- train %>%
group_by(month) %>%
count() %>%
ggplot(aes(month,n,group=1)) +
geom_line(size=2,color="lightblue") +
geom_point(size=2,shape =17)#看看每个时段打的数量的分布\趋势
p9<- train %>%
mutate(hour= hour(pickup_datetime)) %>%
group_by(hour) %>%
count() %>%
ggplot(aes(hour,n)) +
geom_line(size=2,color = "lightblue") +
geom_point(size=2,shape=17)
p789 <- grid.arrange(p7,p8,p9,ncol=1)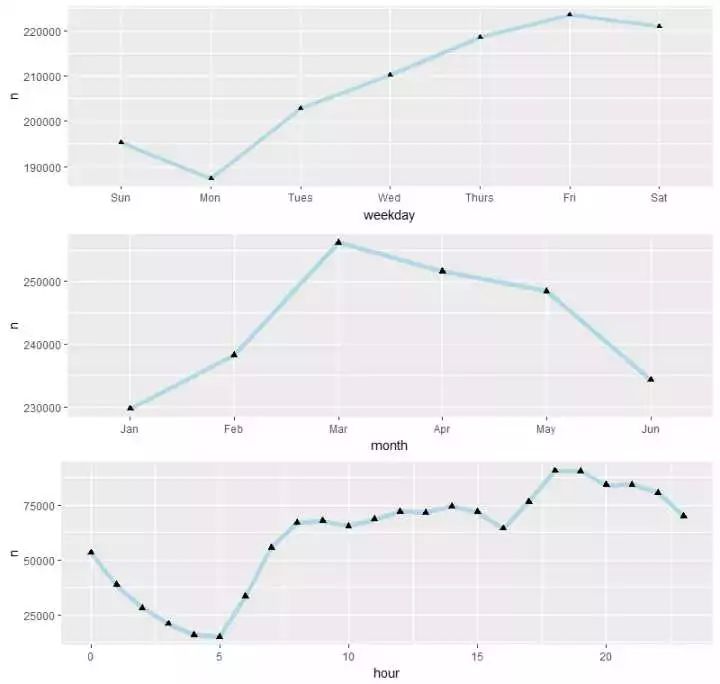
(1)NYC的出租车最忙的时间集中在周五、周六
(2)3-5月份打的的人最多,和旅游旺季有一定关系吗?
(3)对于每天而言,还是符合我们的日常认识的,0-5点打车的人越来越少,到了晚上,嗯,call a taxi ,get high!
(7)看看路程距离\速度的分布,组合
p10 <- train %>%
ggplot(aes(distance)) +
geom_histogram(bins = 4000,fill="red") +coord_cartesian(x=c(0,30))
p11 <- train %>%
ggplot(aes(speed)) +
geom_histogram(bins = 3000,fill="orange") +coord_cartesian(x=c(0,100))
p1011 <- grid.arrange(p10,p11,ncol=1)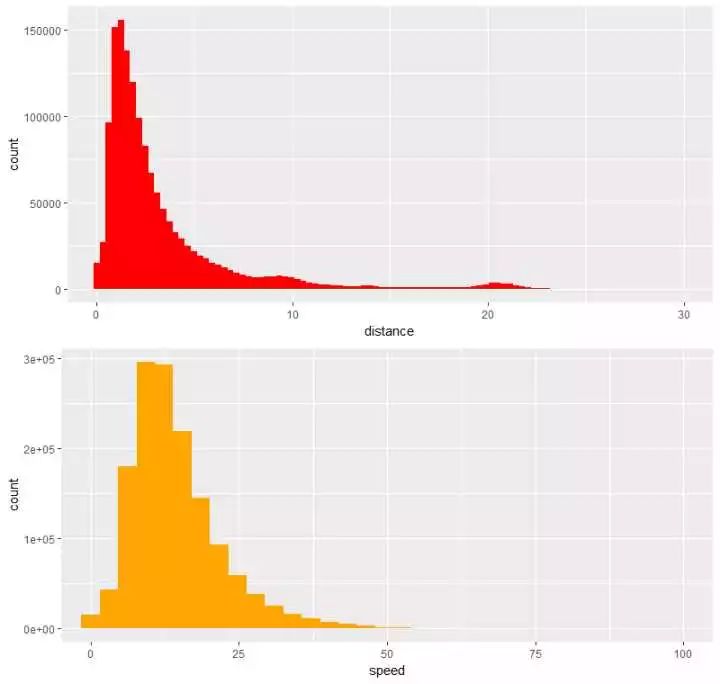
发现:
(1)主要的路程距离集中在1-3公里这个范围内
(2)行驶的速度集中在13-15km/h,我的天!这么堵?
第三部分 数据可视化展示(组合字段)
接下来,试着组合一些字段进行可视化的展示,看看还能得出什么信息
(1)看一下7个weekday不同时段的打车情况、6个月每个时段的打车情况,组合一下
p12 <-train %>%
group_by(weekday,hour) %>%
count() %>%
ggplot(aes(hour,n,color=weekday)) +
geom_line(size=2) +
scale_color_brewer(palette = "Set1")
p13 <- train %>%
group_by(month,hour) %>%
count() %>%
ggplot(aes(hour,n,color=month)) +
geom_line(size=2) +
scale_color_brewer(palette = "Set2")
p1213 <- grid.arrange(p12,p13,nrow=2)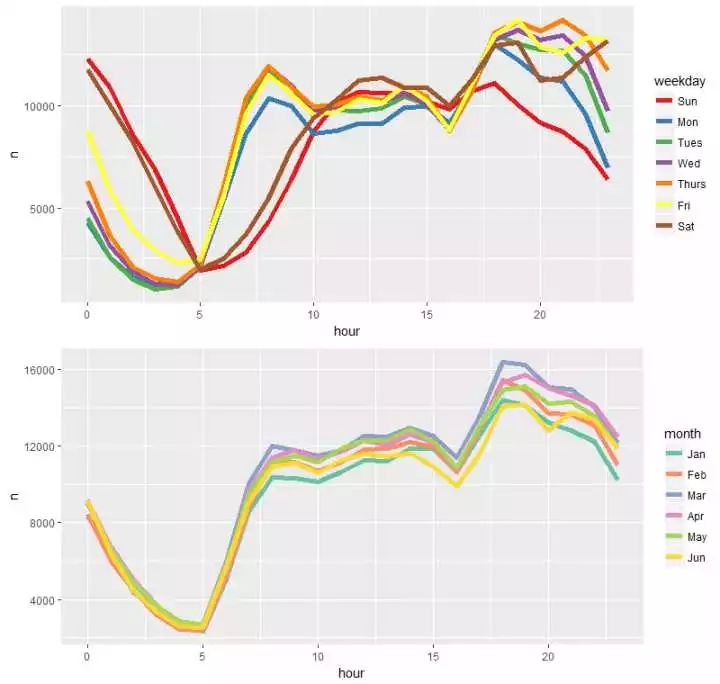
(1)周六、周日凌晨,打车的情况会比其他工作日多不少,而周日深夜时段打车的数量是一周7天中最少的,收收心,第二天上班?
(2)正常工作日,早上打的的数量明显要比周末来的多,符合出行规律
(3)第二张图,除了看出3月份打车情况比其它月份来的多,除此并没有其它大的区别
(2)按乘客数目分组,看看旅行时长的分布
p14<- train %>%
ggplot(aes(passenger_count,trip_duration,color=passenger_count)) +
geom_boxplot() +
scale_y_log10() +
theme(legend.position = "null")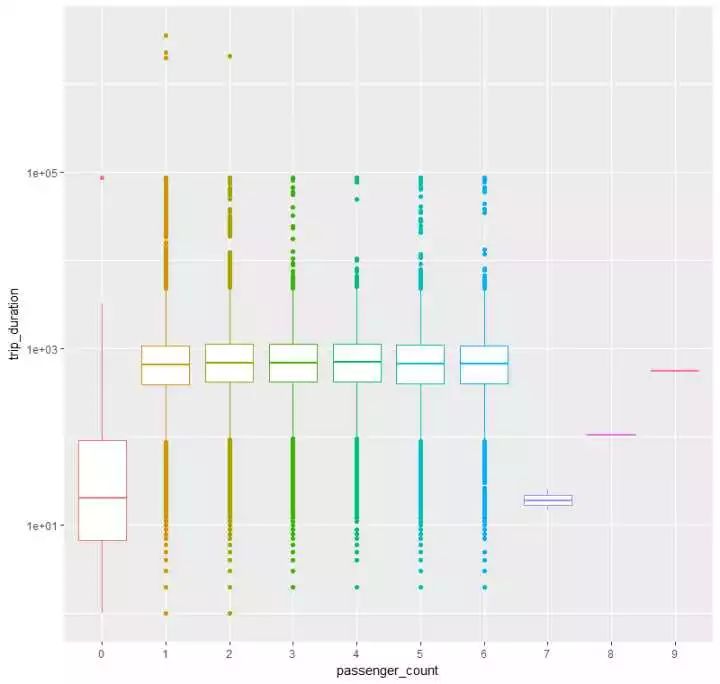
除去数据量很小的0、7、8、9几个类别外,
好像,并看不出什么...看来并不会因为乘客数量的多少而影响时长
(3)看看是否第一时间储存记录和vendor_id的关系
p14 <- train %>%
ggplot(aes(vendor_id,fill=store_and_fwd_flag)) +
geom_bar(position = "dodge")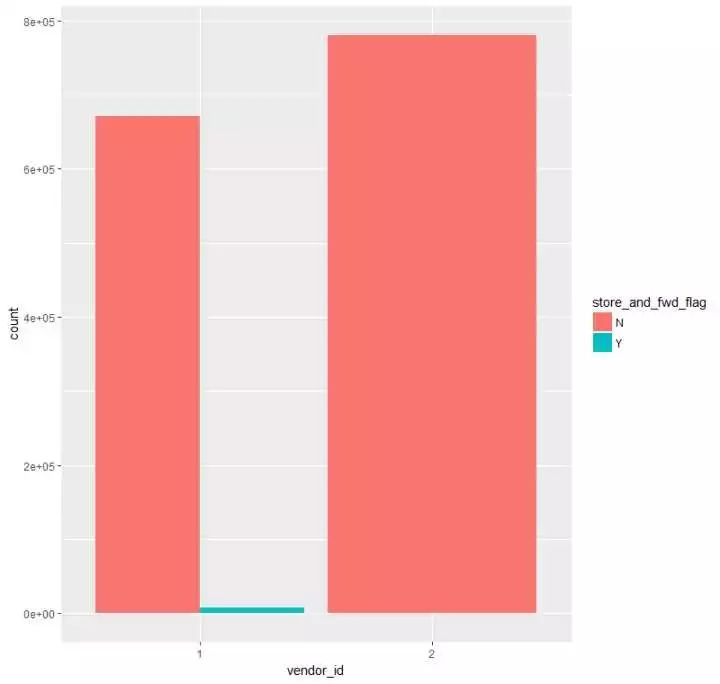
总述
这是在kaggle上学习后的第一篇实践输出,也参考了不少其它大神的代码和思路,主要是对R中dplyr、lubirdate、ggplot2包实战使用进行练习记录。
深深感觉到自己的缺陷与不足,不能进行更深入系统的数据分析。
希望认识更多学习数据分析的朋友,欢迎留言,感谢点赞。
最后,路漫漫其修远兮,平常心!

公众号后台回复关键字即可学习
回复 R R语言快速入门免费视频
回复 统计 统计方法及其在R中的实现
回复 用户画像 民生银行客户画像搭建与应用
回复 大数据 大数据系列免费视频教程
回复 可视化 利用R语言做数据可视化
回复 数据挖掘 数据挖掘算法原理解释与应用
回复 机器学习 R&Python机器学习入门




