AI 芯片格局最全分析 | 厚势汽车

如果说 2016 年 3 月份 AlphaGo 与李世石的那场人机大战只在科技界和围棋界产生较大影响的话,那么 2017 年 5 月其与排名第一的世界围棋冠军柯洁的对战则将人工智能技术推向了公众视野。阿尔法狗(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能程序,由谷歌(Google)旗下 DeepMind 公司戴密斯·哈萨比斯领衔的团队开发,其主要工作原理是「深度学习」。

其实早在 2012 年,深度学习技术就已经在学术界引起了广泛地讨论。在这一年的 ImageNet 大规模视觉识别挑战赛 ILSVRC 中,采用 5 个卷积层和 3 个全连接层的神经网络结构 AlexNet,取得了 top-5(15.3%)的历史最佳错误率,而第二名的成绩仅为 26.2%。从此以后,就出现了层数更多、结构更为复杂的神经网络结构,如 ResNet、GoogleNet、VGGNet 和 MaskRCNN 等,还有去年比较火的生成式对抗网络 GAN。
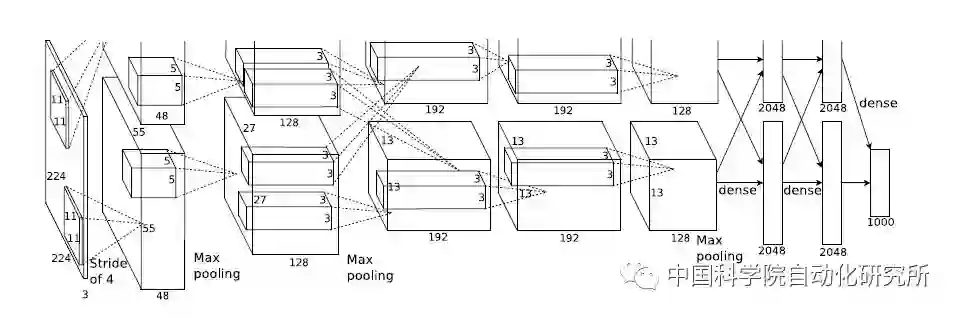
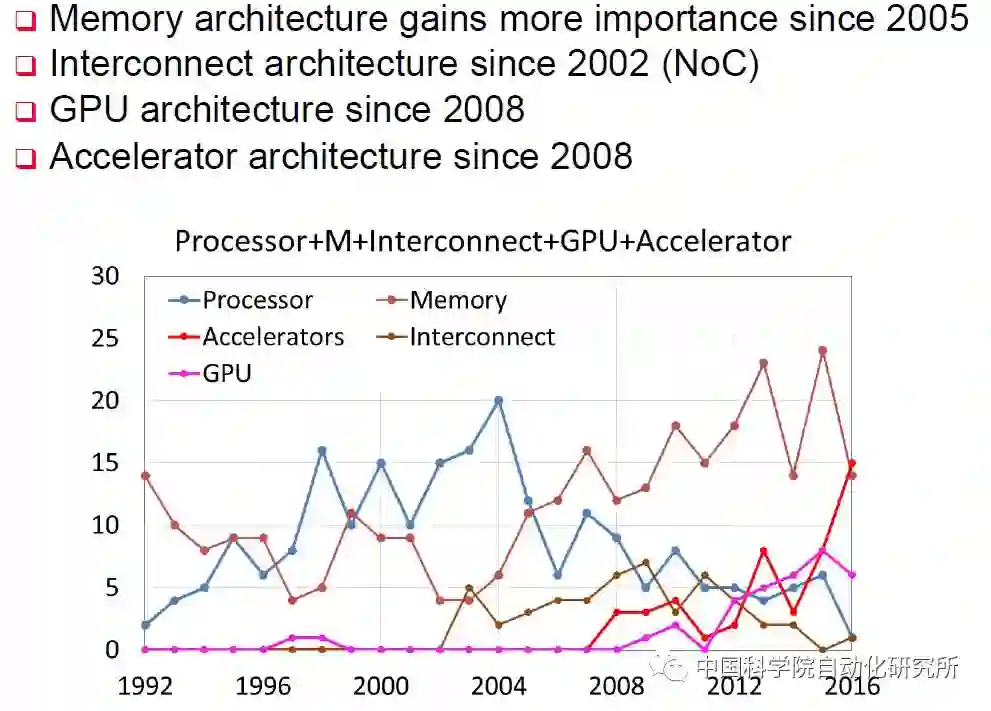
不论是赢得视觉识别挑战赛的 AlexNet,还是击败围棋冠军柯洁的 AlphaGo,它们的实现都离不开现代信息技术的核心——处理器,不论这个处理器是传统的 CPU,还是 GPU,还是新兴的专用加速部件 NNPU(NNPU 是 Neural Network Processing Unit 的简称)。在计算机体系结构国际顶级会议 ISCA2016 上有个关于体系结构 2030 的小型研讨会,名人堂成员 UCSB 的谢源教授就对 1991 年以来在 ISCA 收录的论文进行了总结,专用加速部件相关的论文收录是在 2008 年开始,而在 2016 年达到了顶峰,超过了处理器、存储器以及互联结构等三大传统领域。而在这一年,来自中国科学院计算技术研究所的陈云霁、陈天石研究员课题组提交的《一种神经网络指令集》论文,更是 ISCA2016 最高得分论文。
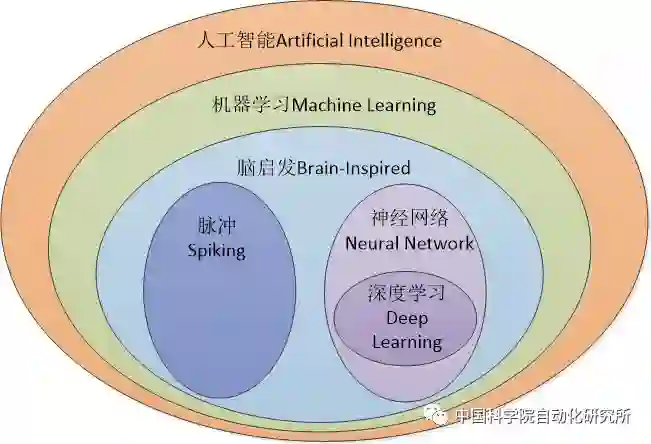
在具体介绍 AI 芯片国内外之前,看到这里有部分读者或许会产生这样的疑惑:这不都是在说神经网络和深度学习吗?那么我觉得有必要对人工智能和神经网络的概念进行阐述,特别是 2017 年工信部发布的《促进新一代人工智能产业发展三年行动计划(2018-2020 年)》中,对发展目标的描述很容易让人觉得人工智能就是神经网络,AI 芯片就是神经网络芯片。
人工智能整体核心基础能力显著增强,智能传感器技术产品实现突破,设计、代工、封测技术达到国际水平,神经网络芯片实现量产并在重点领域实现规模化应用,开源开发平台初步具备支撑产业快速发展的能力。
其实则不然。人工智能是一个很老很老的概念,而神经网络只不过是人工智能范畴的一个子集。早在 1956 年,被誉为「人工智能之父」的图灵奖得主约翰·麦卡锡就这样定义人工智能:创造智能机器的科学与工程。而在 1959 年,Arthur Samuel 给出了人工智能的一个子领域机器学习的定义,即「计算机有能力去学习,而不是通过预先准确实现的代码」,这也是目前公认的对机器学习最早最准确的定义。而我们日常所熟知的神经网络、深度学习等都属于机器学习的范畴,都是受大脑机理启发而发展得来的。另外一个比较重要的研究领域就是脉冲神经网络,国内具有代表的单位和企业是清华大学类脑计算研究中心和上海西井科技等。
好了,现在终于可以介绍 AI 芯片国内外的发展现状了,当然这些都是我个人的一点观察和愚见,管窥之见权当抛砖引玉。
国外:技术寡头,优势明显
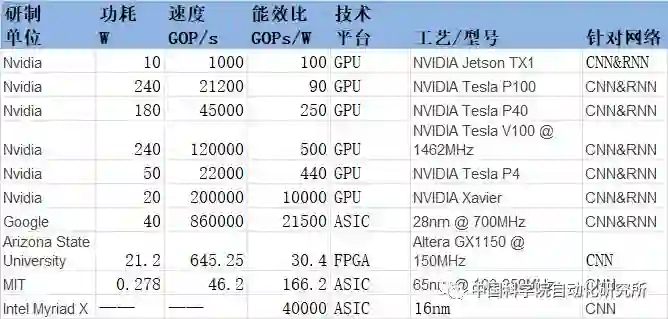
由于具有得天独厚的技术和应用优势,英伟达和谷歌几乎占据了人工智能处理领域 80% 的市场份额,而且在谷歌宣布其 Cloud TPU 开放服务和英伟达推出自动驾驶处理器 Xavier之后,这一份额占比在 2018 年有望进一步扩大。其他厂商,如英特尔、特斯拉、ARM、IBM 以及 Cadence 等,也在人工智能处理器领域占有一席之地。
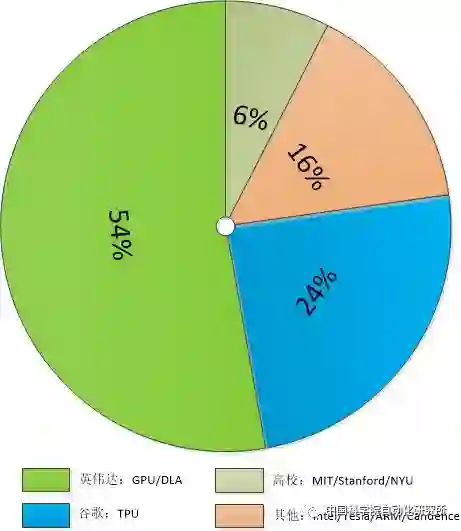
当然,上述这些公司的专注领域却不尽相同。比如英伟达主要专注于 GPU 和无人驾驶领域,而谷歌则主要针对云端市场,英特尔则主要面向计算机视觉,Cadence 则以提供加速神经网络计算相关 IP 为主。如果说前述这些公司还主要偏向处理器设计等硬件领域,那么 ARM 公司则主要偏向软件,致力于针对机器学习和人工智能提供高效算法库。
独占鳌头——英伟达
在人工智能领域,英伟达可以说是目前涉及面最广、市场份额最大的公司,旗下产品线遍布自动驾驶汽车、高性能计算、机器人、医疗保健、云计算、游戏视频等众多领域。其针对自动驾驶汽车领域的全新人工智能超级计算机 Xavier,用 NVIDIA 首席执行官黄仁勋的话来说就是「这是我所知道的 SoC 领域非常了不起的尝试,我们长期以来一直致力于开发芯片。」

Xavier 是一款完整的片上系统 (SoC),集成了被称为 Volta 的全新 GPU 架构、定制 8 核 CPU 架构以及新的计算机视觉加速器。该处理器提供 20 TOPS(万亿次运算/秒)的高性能,而功耗仅为 20 瓦。单个 Xavier 人工智能处理器包含 70 亿个晶体管,采用最前沿的 16nm FinFET 加工技术进行制造,能够取代目前配置了两个移动 SoC 和两个独立 GPU 的 DRIVE PX 2,而功耗仅仅是它的一小部分。
而在 2018 年拉斯维加斯 CES 展会上,NVIDIA 又推出了三款基于 Xavier 的人工智能处理器,包括一款专注于将增强现实(AR)技术应用于汽车的产品、一款进一步简化车内人工智能助手构建和部署的 DRIVE IX 和一款对其现有自主出租车大脑——Pegasus 的修改,进一步扩大自己的优势。
产学研的集大成者——谷歌
如果你只是知道谷歌的 AlphaGo、无人驾驶和 TPU 等这些人工智能相关的产品,那么你还应该知道这些产品背后的技术大牛们:谷歌传奇芯片工程师 Jeff Dean、谷歌云计算团队首席科学家、斯坦福大学 AI 实验室主管李飞飞、Alphabet 董事长 John Hennessy 和谷歌杰出工程师 David Patterson。
时至今日,摩尔定律遇到了技术和经济上的双重瓶颈,处理器性能的增长速度越来越慢,然而社会对于计算能力的需求增速却并未减缓,甚至在移动应用、大数据、人工智能等新的应用兴起后,对于计算能力、计算功耗和计算成本等提出了新的要求。与完全依赖于通用 CPU 及其编程模型的传统软件编写模式不同,异构计算的整个系统包含了多种基于特定领域架构(Domain-Specific Architecture,DSA)设计的处理单元,每一个 DSA 处理单元都有负责的独特领域并针对该领域做优化,当计算机系统遇到相关计算时便由相应的 DSA 处理器去负责。而谷歌就是异构计算的践行者,TPU 就是异构计算在人工智能应用的一个很好例子。

2017 年发布的第二代 TPU 芯片,不仅加深了人工智能在学习和推理方面的能力,而且谷歌是认真地要将它推向市场。根据谷歌的内部测试,第二代芯片针对机器学习的训练速度能比现在市场上的图形芯片(GPU)节省一半时间;第二代 TPU 包括了四个芯片,每秒可处理 180 万亿次浮点运算;如果将 64 个 TPU 组合到一起,升级为所谓的 TPU Pods,则可提供大约 11500 万亿次浮点运算能力。
计算机视觉领域的搅局者——英特尔
英特尔作为世界上最大的计算机芯片制造商,近年来一直在寻求计算机以外的市场,其中人工智能芯片争夺成为英特尔的核心战略之一。为了加强在人工智能芯片领域的实力,不仅以 167 亿美元收购 FPGA 生产商 Altera 公司,还以 153 亿美元收购自动驾驶技术公司 Mobileye,以及机器视觉公司 Movidius 和为自动驾驶汽车芯片提供安全工具的公司 Yogitech,背后凸显这家在 PC 时代处于核心位置的巨头面向未来的积极转型。

Myriad X 就是英特尔子公司 Movidius 在 2017 年推出的视觉处理器(VPU,vision processing unit),这是一款低功耗的系统芯片(SoC),用于在基于视觉的设备上加速深度学习和人工智能——如无人机、智能相机和 VR / AR 头盔。
Myriad X 是全球第一个配备专用神经网络计算引擎的片上系统芯片(SoC),用于加速设备端的深度学习推理计算。该神经网络计算引擎是芯片上集成的硬件模块,专为高速、低功耗且不牺牲精确度地运行基于深度学习的神经网络而设计,让设备能够实时地看到、理解和响应周围环境。引入该神经计算引擎之后,Myriad X 架构能够为基于深度学习的神经网络推理提供 1TOPS 的计算性能。
执「能效比」之牛耳——学术界
除了工业界和厂商在人工智能领域不断推出新产品之外,学术界也在持续推进人工智能芯片新技术的发展。
比利时鲁汶大学的 Bert Moons 等在 2017 年顶级会议 IEEE ISSCC 上面提出了能效比高达 10.0TOPs/W 的针对卷积神经网络加速的芯片 ENVISION,该芯片采用 28nm FD-SOI 技术。该芯片包括一个 16 位的 RISC 处理器核,1D-SIMD 处理单元进行 ReLU 和 Pooling 操作,2D-SIMD MAC 阵列处理卷积层和全连接层的操作,还有 128KB 的片上存储器。
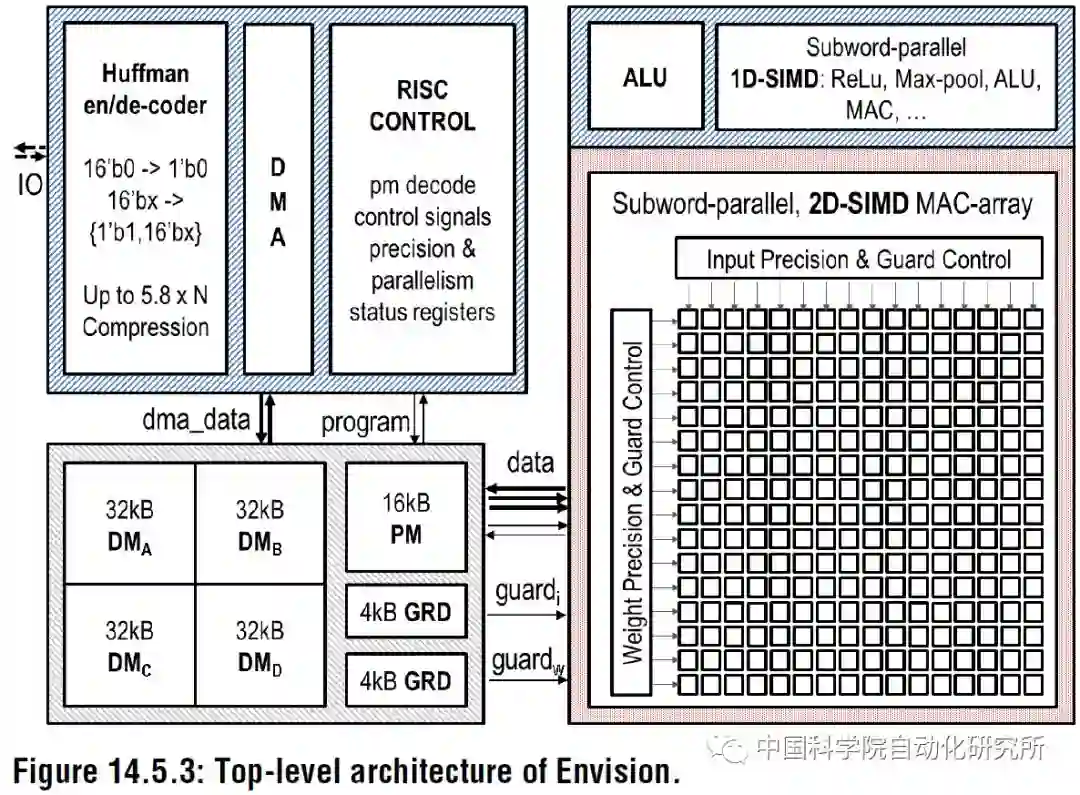
韩国科学技术院 KAIST 的 Dongjoo Shin 等人在 ISSCC2017 上提出了一个针对 CNN 和 RNN 结构可配置的加速器单元 DNPU,除了包含一个 RISC 核之外,还包括了一个针对卷积层操作的计算阵列 CP 和一个针对全连接层 RNN-LSTM 操作的计算阵列 FRP,相比于鲁汶大学的 Envision,DNPU 支持 CNN 和 RNN 结构,能效比高达 8.1TOPS/W。该芯片采用了 65nm CMOS 工艺。
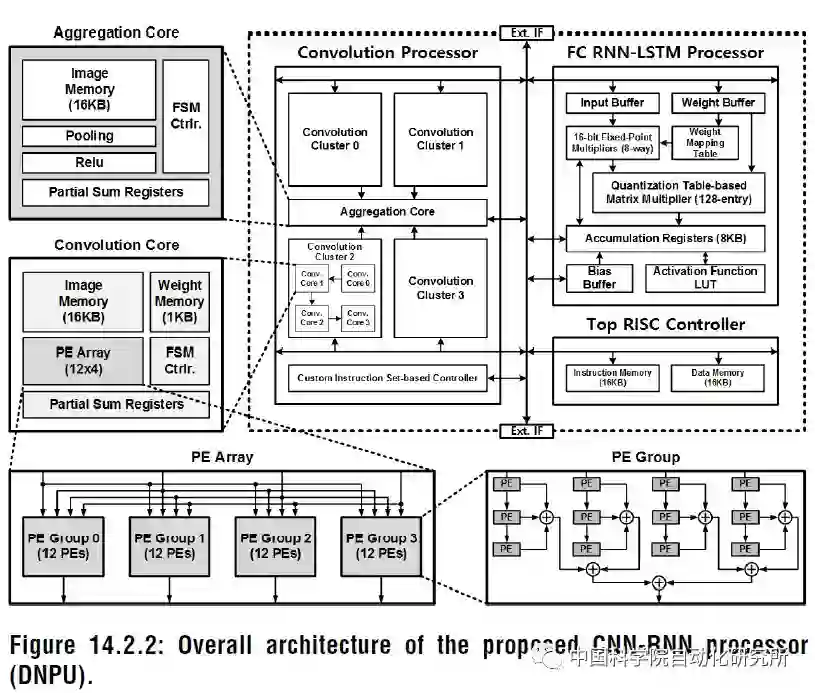
相比较于鲁汶大学和韩国科学技术院都针对神经网络推理部分的计算操作来说,普渡大学的 Venkataramani S 等人在计算机体系结构顶级会议 ISCA2017 上提出了针对大规模神经网络训练的人工智能处理器 SCALLDEEP。
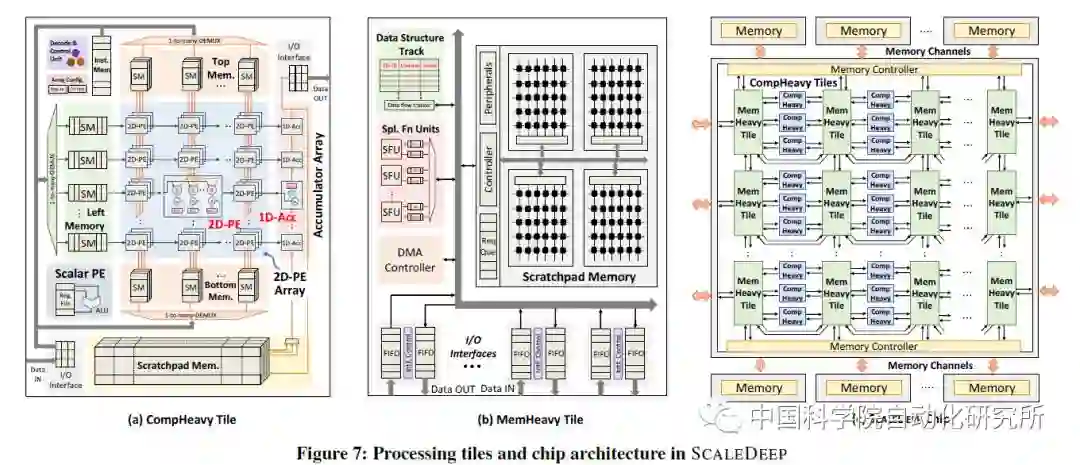
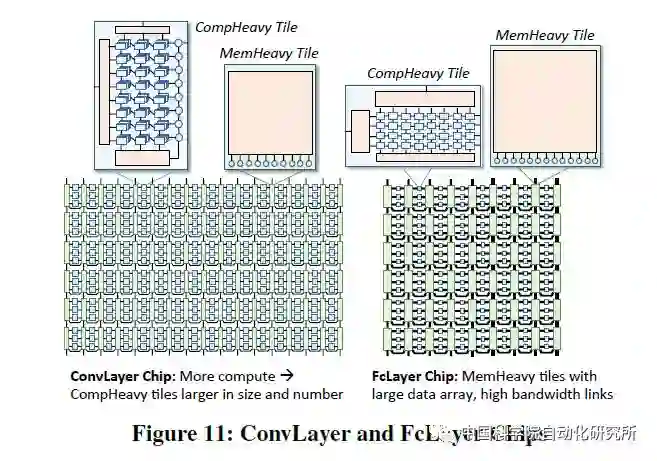
该论文针对深度神经网络的训练部分进行针对性优化,提出了一个可扩展服务器架构,且深入分析了深度神经网络中卷积层,采样层,全连接层等在计算密集度和访存密集度方面的不同,设计了两种处理器 core 架构,计算密集型的任务放在了 comHeavy 核中,包含大量的 2D 乘法器和累加器部件,而对于访存密集型任务则放在了 memHeavy 核中,包含大量 SPM 存储器和 tracker 同步单元,既可以作为存储单元使用,又可以进行计算操作,包括 ReLU,tanh 等。而一个 SCALEDEEP Chip 则可以有不同配置下的两类处理器核组成,然后再组成计算簇。
论文中所用的处理平台包括 7032 个处理器 tile。论文作者针对深度神经网络设计了编译器,完成网络映射和代码生成,同时设计了设计空间探索的模拟器平台,可以进行性能和功耗的评估,性能则得益于时钟精确级的模拟器,功耗评估则从 DC 中提取模块的网表级的参数模型。该芯片仅采用了 Intel 14 nm 工艺进行了综合和性能评估,峰值能效比高达 485.7 GOPS/W。
国内:百家争鸣,各自为政
可以说,国内各个单位在人工智能处理器领域的发展和应用与国外相比依然存在很大的差距。由于我国特殊的环境和市场,国内人工智能处理器的发展呈现出百花齐放、百家争鸣的态势,这些单位的应用领域遍布股票交易、金融、商品推荐、安防、早教机器人以及无人驾驶等众多领域,催生了大量的人工智能芯片创业公司,如地平线、深鉴科技、中科寒武纪等。尽管如此,国内起步较早的中科寒武纪却并未如国外大厂一样形成市场规模,与其他厂商一样,存在着各自为政的散裂发展现状。
除了新兴创业公司,国内研究机构如北京大学、清华大学、中国科学院等在人工智能处理器领域都有深入研究;而其他公司如百度和比特大陆等,2017 年也有一些成果发布。
全球 AI 芯片界首个独角兽——寒武纪
2017 年 8 月,国内 AI 芯片初创公司寒武纪宣布已经完成 1 亿美元 A 轮融资,战略投资方可谓阵容豪华,阿里巴巴、联想、科大讯飞等企业均参与投资。而其公司也成为全球 AI 芯片界首个独角兽,受到国内外市场广泛关注。
寒武纪科技主要负责研发生产 AI 芯片,公司最主要的产品为 2016 年发布的寒武纪 1A 处理器(Cambricon-1A),是一款可以深度学习的神经网络专用处理器,面向智能手机、无人机、安防监控、可穿戴设备以及智能驾驶等各类终端设备,在运行主流智能算法时性能功耗比全面超越传统处理器。目前已经研发出 1A、1H 等多种型号。与此同时,寒武纪也推出了面向开发者的寒武纪人工智能软件平台 Cambricon NeuWare,包含开发、调试和调优三大部分。
软硬件协同发展的典范——深鉴科技
深鉴科技的联合创始人韩松在不同场合曾多次提及软硬件协同设计对人工智能处理器的重要性,而其在 FPGA 领域顶级会议 FPGA2017 最佳论文 ESE 硬件架构就是最好的证明。该项工作聚焦于使用 LSTM 进行语音识别的场景,结合深度压缩(Deep Compression)、专用编译器以及 ESE 专用处理器架构,在中端的 FPGA 上即可取得比 Pascal Titan X GPU 高 3 倍的性能,并将功耗降低 3.5 倍。
在 2017 年 10 月的时候,深鉴科技推出了六款 AI 产品,分别是人脸检测识别模组、人脸分析解决方案、视频结构化解决方案、ARISTOTLE 架构平台,深度学习 SDK DNNDK、双目深度视觉套件。而在人工智能芯片方面,公布了最新的芯片计划,由深鉴科技自主研发的芯片「听涛」、「观海」将于 2018 年第三季度面市,该芯片采用台积电 28nm 工艺,亚里士多德架构,峰值性能 3.7 TOPS/W。
对标谷歌 TPU——比特大陆算丰
作为比特币独角兽的比特大陆,在 2015 年开始涉足人工智能领域,其在 2017 年发布的面向 AI 应用的张量处理器算丰 Sophon BM1680,是继谷歌 TPU 之后,全球又一款专门用于张量计算加速的专用芯片(ASIC),适用于 CNN / RNN / DNN 的训练和推理。

BM1680 单芯片能够提供 2TFlops 单精度加速计算能力,芯片由 64 NPU 构成,特殊设计的 NPU 调度引擎(Scheduling Engine)可以提供强大的数据吞吐能力,将数据输入到神经元核心(Neuron Processor Cores)。BM1680 采用改进型脉动阵列结构。2018 年比特大陆将发布第 2 代算丰 AI 芯片 BM1682,计算力将有大幅提升。
百家争鸣——百度、地平线及其他
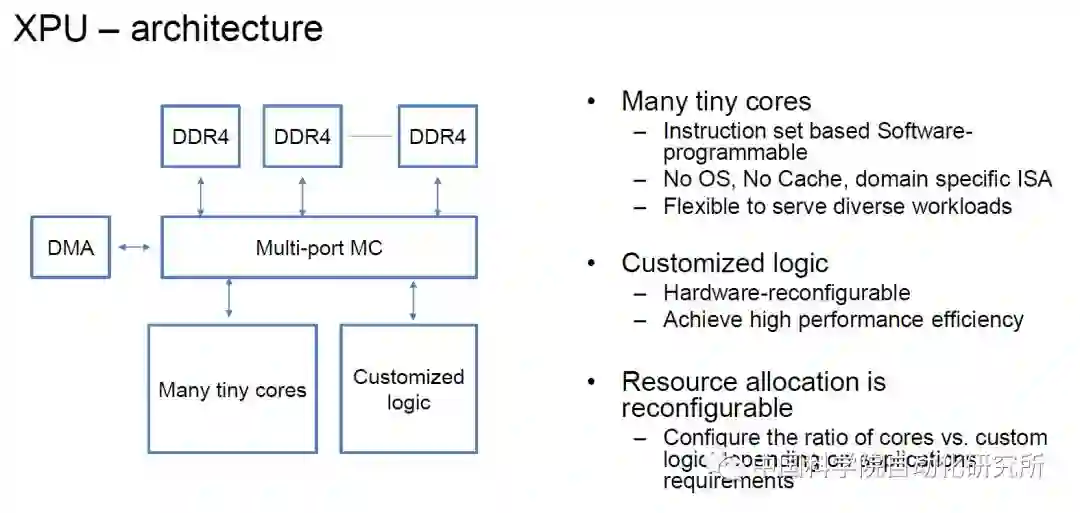
在 2017 年的 HotChips 大会上,百度发布了 XPU,这是一款 256 核、基于 FPGA 的云计算加速芯片,用于百度的人工智能、数据分析、云计算以及无人驾驶业务。在会上,百度研究员欧阳剑表示,百度设计的芯片架构突出多样性,着重于计算密集型、基于规则的任务,同时确保效率、性能和灵活性的最大化。
欧阳剑表示:「FPGA 是高效的,可以专注于特定计算任务,但缺乏可编程能力。传统 CPU 擅长通用计算任务,尤其是基于规则的计算任务,同时非常灵活。GPU 瞄准了并行计算,因此有很强大的性能。XPU 则关注计算密集型、基于规则的多样化计算任务,希望提高效率和性能,并带来类似 CPU 的灵活性。」
在 2018 年百度披露更多关于 XPU 的相关信息。
2017 年 12 月底,人工智能初创企业地平线发布了中国首款全球领先的嵌入式人工智能芯片——面向智能驾驶的征程(Journey)1.0 处理器和面向智能摄像头的旭日(Sunrise)1.0 处理器,还有针对智能驾驶、智能城市和智能商业三大应用场景的人工智能解决方案。「旭日 1.0」和「征程 1.0」是完全由地平线自主研发的人工智能芯片,具有全球领先的性能。
为了解决应用场景中的问题,地平线将算法与芯片做了强耦合,用算法来定义芯片,提升芯片的效率,在高性能的情况下可以保证它的低功耗、低成本。具体芯片参数尚无公开数据。

除了百度和地平线,国内研究机构如中国科学院、北京大学和清华大学也有人工智能处理器相关的成果发布。
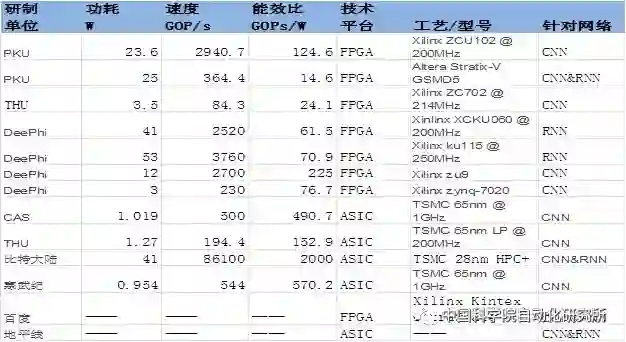
北京大学联合商汤科技等提出一种基于 FPGA 的快速 Winograd 算法,可以大幅降低算法复杂度,改善 FPGA 上的 CNN 性能。论文中的实验使用当前最优的多种 CNN 架构(如 AlexNet 和 VGG16),从而实现了 FPGA 加速之下的最优性能和能耗。在 Xilinx ZCU102 平台上达到了卷积层平均处理速度 1006.4 GOP/s,整体 AlexNet 处理速度 854.6 GOP/s,卷积层平均处理速度 3044.7 GOP/s,整体 VGG16 的处理速度 2940.7 GOP/s。
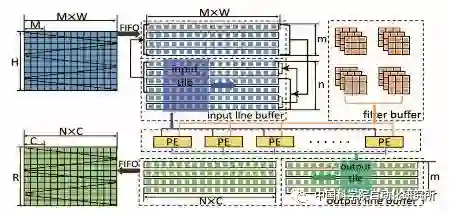
中国科学院计算机体系结构国家重点实验室在顶级会议 HPCA2017 上提出了一种基于数据流的神经网络处理器架构,以便适应特征图、神经元和突触等不同层级的并行计算,为了实现这一目标,该团队对单个处理单元 PE 进行重新设计,使得操作数可以直接通过横向或纵向的总线从片上存储器获取,而非传统 PE 只能从上至下或从左至右由相邻单元获取。该芯片采用了 TMSC 65nm 工艺,峰值性能为 490.7 GOPs/W。
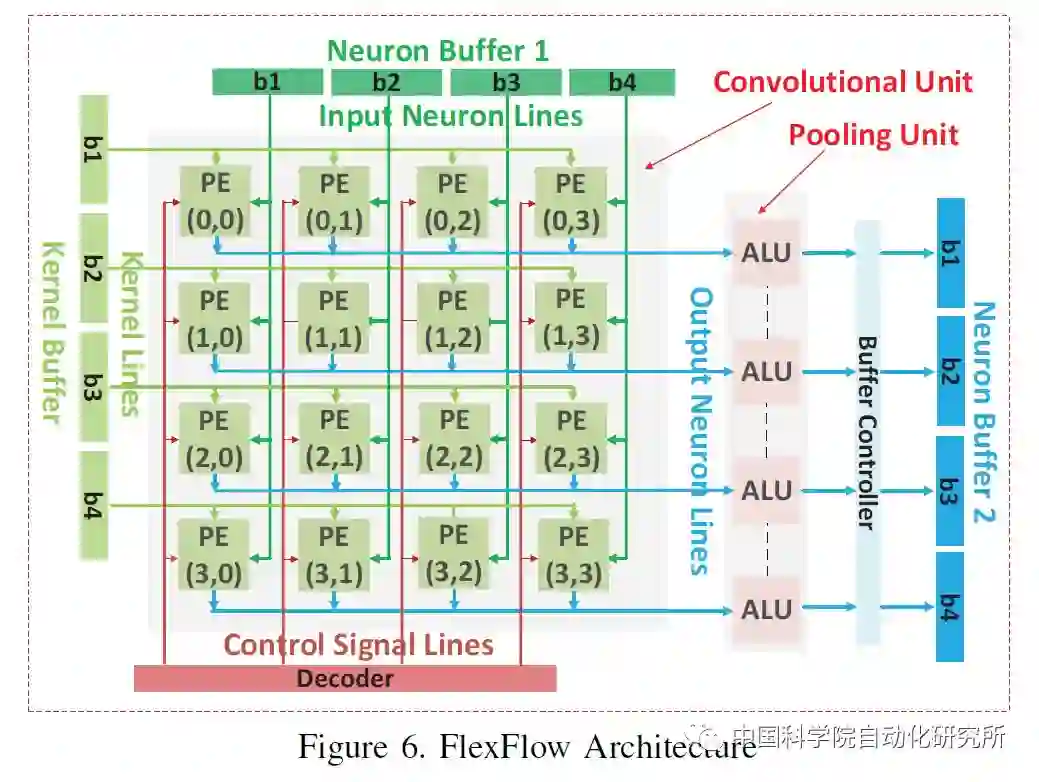
清华大学微纳电子系魏少军等 2017 年的 VLSI 国际研讨会上提出了基于可重构多模态混合的神经计算芯片 Thinker。Thinker 芯片基于该团队长期积累的可重构计算芯片技术,采用可重构架构和电路技术,突破了神经网络计算和访存的瓶颈,实现了高能效多模态混合神经网络计算。Thinker 芯片具有高能效的突出优点,其能量效率相比目前在深度学习中广泛使用的 GPU 提升了三个数量级。Thinker 芯片支持电路级编程和重构,是一个通用的神经网络计算平台,可广泛应用于机器人、无人机、智能汽车、智慧家居、安防监控和消费电子等领域。该芯片采用了 TSMC 65nm 工艺,片上存储为 348KB,峰值性能为 5.09TOPS/W。

新架构新技术——忆阻器
2017 年清华大学微电子所钱鹤、吴华强课题组在《自然通讯》(Nature Communications)在线发表了题为「运用电子突触进行人脸分类」(「Face Classification using Electronic Synapses」)的研究成果,将氧化物忆阻器的集成规模提高了一个数量级,首次实现了基于 1024 个氧化物忆阻器阵列的类脑计算。该成果在最基本的单个忆阻器上实现了存储和计算的融合,采用完全不同于传统「冯·诺依曼架构」的体系,可以使芯片功耗降低到原千分之一以下。忆阻器被认为是最具潜力的电子突触器件,通过在器件两端施加电压,可以灵活地改变其阻值状态,从而实现突触的可塑性。此外,忆阻器还具有尺寸小、操作功耗低、可大规模集成等优势。因此,基于忆阻器所搭建的类脑计算硬件系统具有功耗低和速度快的优势,成为国际研究热点。

在神经形态处理器方面,最为著名的就是 IBM 在 2014 年推出的 TrueNorth 芯片,该芯片包括 4096 个核心和 540 万个晶体管,功耗 70mW,模拟了一百万个神经元和 2.56 亿个突触。而在 2017 年,英特尔也推出一款能模拟大脑工作的自主学习芯片 Loihi,Loihi 由 128 个计算核心构成,每个核心集成了 1024 个人工神经元,整个芯片拥有超过个 13 万个神经元与 1.3 亿个突触连接,与人脑超过 800 亿个神经元相比,简直是小巫见大巫,Loihi 的运算规模仅比虾脑复杂一点点而已。英特尔认为该芯片适用于无人机与汽车自动驾驶,红绿灯自适应路面交通状况,用摄像头寻找失踪人口等任务。

而在神经形态芯片研究领域,清华大学类脑计算研究中心施路平等在 2015 年就推出了首款类脑芯片—「天机芯」,该芯片世界首次将人工神经网络(Artificial Neural Networks, ANNs)和脉冲神经网络(Spiking Neural Networks,SNNs)进行异构融合,同时兼顾技术成熟并被广泛应用的深度学习模型与未来具有巨大前景的计算神经科学模型,可用于诸如图像处理、语音识别、目标跟踪等多种应用开发。在类脑「自行」车演示平台上,集成 32 个天机一号芯片,实现了面向视觉目标探测、感知、目标追踪、自适应姿态控制等任务的跨模态类脑信息处理实验。据悉,基于 TSMC 28nm 工艺的第二代天机芯片也即将推出,性能将会得到极大提升。

从 ISSCC2018 看人工智能芯片发展趋势
在刚刚结束的计算机体系结构顶级会议 ISSCC2018,「Digital Systems: Digital Architectures and Systems」分论坛主席 Byeong-Gyu Nam 对人工智能芯片,特别是深度学习芯片的发展趋势做了概括。深度学习依然今年大会最为热门的话题。相比较于去年大多数论文都在讨论卷积神经网络的实现问题,今年则更加关注两个问题:其一,如果更高效地实现卷积神经网络,特别是针对手持终端等设备;其二,则是关于全连接的非卷积神经网络,如 RNN 和 LSTM 等。
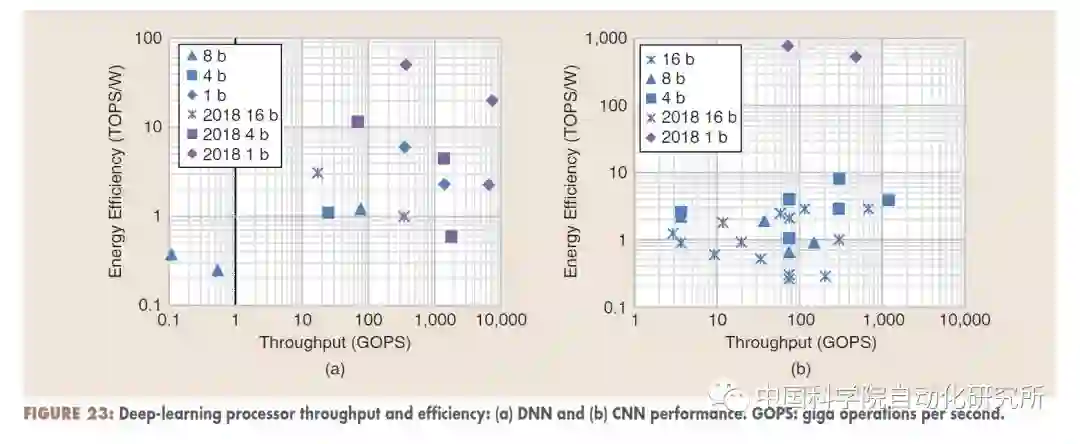
同时,为了获得更高的能效比,越来越多的研究者把精力放在了低精度神经网络的设计和实现,如 1bit 的神经网络。这些新型技术,使得深度学习加速器的能效比从去年的几十 TOPS/W 提升到了今年的上百 TOPS/W。有些研究者也对数字+模拟的混合信号处理实现方案进行了研究。对数据存取具有较高要求的全连接网络,有些研究者则借助 3-D 封装技术来获得更好的性能。
总结
对国产人工智能芯片的一点愚见
正如前文所述,在人工智能芯片领域,国外芯片巨头占据了绝大部分市场份额,不论是在人才聚集还是公司合并等方面,都具有绝对的领先优势。而国内人工智能初创公司则又呈现百家争鸣、各自为政的纷乱局面;特别是每个初创企业的人工智能芯片都具有自己独特的体系结构和软件开发套件,既无法融入英伟达和谷歌建立的生态圈,又不具备与之抗衡的实力。
国产人工智能芯片的发展,一如早年间国产通用处理器和操作系统的发展,过份地追求完全独立、自主可控的怪圈,势必会如众多国产芯片一样逐渐退出历史舞台。借助于 X86 的完整生态,短短一年之内,兆芯推出的国产自主可控 x86 处理器,以及联想基于兆芯 CPU 设计生产的国产计算机、服务器就获得全国各地党政办公人员的高度认可,并在党政军办公、信息化等国家重点系统和工程中已获批量应用。
当然,投身于 X86 的生态圈对于通用桌面处理器和高端服务器芯片来说无可厚非,毕竟创造一个如 Wintel 一样的生态链已绝非易事,我们也不可能遇见第二个乔布斯和苹果公司。而在全新的人工智能芯片领域,对众多国产芯片厂商来说,还有很大的发展空间,针对神经网络加速器最重要的就是找到一个具有广阔前景的应用领域,如华为海思麒麟处理器之于中科寒武纪的 NPU;否则还是需要融入一个合适的生态圈。另外,目前大多数国产人工智能处理器都针对于神经网络计算进行加速,而能够提供单芯片解决方案的很少;微控制器领域的发展,ARM 的 Cortex-A 系列和 Cortex-M 系列占据主角,但是新兴的开源指令集架构 RISC-V 也不容小觑,完全值得众多国产芯片厂商关注。
文章来源:中国科学院自动化研究所
责任编辑:柒柒
-END-
文章精选
企业家
智能驾驶
新能源汽车
项目和评论
这些大神从Google出走,创办了五家(命运各异的)无人车公司
厚
势
汽
车
为您对接资本和产业
新能源汽车 自动驾驶 车联网
联系邮箱
bp@ihoushi.com

点击阅读原文,查看文章「新一代信息通信技术影响下的智能网联汽车数据资源发展分析」



