一份数据支持多种应用场景 CarbonData融合数据存储方案技术揭秘丨活动报名
Apache CarbonData 是由华为发起并开源的一种高性能数据存储格式,通过新的融合数据存储方案,以一份数据同时支持多种应用场景,解决了当前业界因分析场景需求各异而导致的存储冗余等问题。同时,CarbonData 通过多级索引、字典编码、列存等特性提升 IO 扫描和计算性能,实现百亿数据级秒级响应,它的出现为大数据低延时查询提供了一种新的思路和方向。
为帮助关注 CarbonData 的开发者深入了解该技术,我们发起了一场关于 Apache CarbonData+Spark 的技术交流会,并邀请了来自美国 Databricks、华为、上汽集团的行业顶尖专家,希望通过 Spark SQL 使用场景、Spark 2.2 核心特性 CBO 介绍、CarbonData 应用实践 +2.0 新技术规划等主题内容的分享,让 CarbonData 的使用变得更加简单。
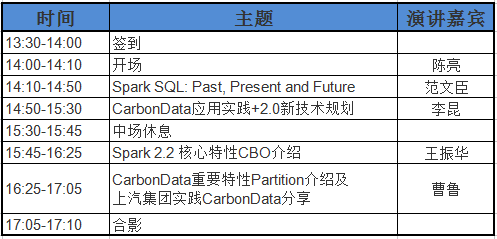
活动时间:2017 年 9 月 2 日 13:30-17:10
活动地点:上海车享大楼 (一层会议厅)
活动费用:限额免费
讲师简介:范文臣,来自美国 Databricks 公司,Apache Spark PMC member,Spark SQL 开发团队成员。2013 年从浙江大学毕业后,一直在进行分布式系统相关的工作。2014 年开始接触 Spark,并成为最活跃的代码贡献者之一。2015 年正式加入 Databricks,成为 Databricks 中国分部(筹建中)的第一名员工,主要负责开源社区方面的工作,例如:审查其他社区成员提交的 PR,主导 Spark SQL 一些主要功能的设计和研发,定期审计项目代码质量等。

议题摘要:Spark SQL 作为 Spark 的基础框架,已经有了广泛的用户基础,并且经历了一段漫长的开发历史。本次议题将会带领大家回顾一下 Spark SQL 的演进历史,以及目前的现状,和未来的一些展望,帮助大家更好的理解 Spark SQL 的一些设计决策以及使用场景。
讲师简介:李昆,Apache CarbonData committer,华为技术有限公司大数据软件架构师。2004 年加入华为,长期从事电信协议、业务智能化、数据可视化、用户行为分析等系统研究和开发工作。近年致力于大数据技术研究,参与 Hadoop、Spark、Alluxio 等开源社区,2016 年作为 CarbonData PMC 成员参与 Apache CarbonData 项目孵化,寻求大数据与一站式分析平台的创新机会点。

议题摘要:Apache CarbonData 是一种新的高性能数据存储,针对当前大数据领域分析场景需求各异而导致的存储冗余问题,CarbonData 提供了一种新的融合数据存储方案,以一份数据同时支持大数据分析的多种应用场景(如:“任意维度组合的数据查询分析、快速扫描、详单查询、数据更新删除等”),并通过多级索引、字典编码、列存等特性提升了 I/O 扫描和计算性能,实现百亿数据级秒级响应。
CarbonData 开源后,受到全球大数据技术爱好者高度关注;截止到目前为止,全球已有 100+ 开发者参与了代码贡献,有 10+ 家企业上线生产系统。本次演讲主要介绍 CarbonData 应用实践以及 2.0 新技术规划,帮助大家更好地应用 CarbonData 技术。
讲师简介:王振华,现任华为公司研究工程师,Apache Spark 核心 Contributor, CBO 主要开发者,致力于构建高性能大数据查询分析平台。在此之前,博士毕业于浙江大学计算机科学与技术学院,研究方向涉及空间数据库、信息检索、数据挖掘。

议题摘要:在 Spark SQL 的 Catalyst 优化器中,许多基于规则的优化技术已经实现,但优化器本身仍然有很大的改进空间。例如,没有关于数据分布的详细列统计信息,因此难以精确地估计过滤(filter)、连接(join)等数据库操作符的输出大小和基数 (cardinality)。由于不准确的估计,它经常导致优化器产生次优的查询执行计划。
在 Spark 2.2 中,在 Spark SQL 引擎内添加了一个基于成本的优化器框架,此框架计算每个数据库操作符的基数和输出大小。通过可靠的统计和精确的估算,能够在这些领域做出好的决定:选择散列连接(hash join)操作的正确构建端(build side),选择正确的连接算法(如 broadcast hash join 与 shuffled hash join),调整连接的顺序等等。在这次演讲中,将展示 Spark SQL 的新的基于成本的优化器框架及其对 TPC-DS 查询的性能影响。
讲师简介:曹鲁, Apache CarbonData 核心 Contributor, partition 主要开发者,现任上汽集团数据业务部大数据平台开发经理。目前主要专注于大数据平台架构,数据存储、压缩、索引以及实时流数据处理等领域的研究及应用。曾负责某金融行业公司 ETL、BI 系统开发,某互联网电商公司的数据仓库容量管理、性能调优等。热衷开源技术研究,Apache CarbonData 社区贡献者。

议题摘要:CarbonData 的 partition 特性将在 Apache CarbonData 1.2.0 版本里正式发布,此特性将显著提升大数据查询性能。上汽集团大数据将 CarbonData 作为平台基础组件,以应对迅猛增长的数据量,本议题将分享上汽集团在 CarbonData 项目的实践和测试数据。
扫描下方图片二维码 或者点击 阅读原文,填写报名信息并提交,我们的工作人员审核后将向您发送确认参会短信。无论你是 Apache CarbonData 忠实粉丝和拥趸者,或着在 CarbonData 的使用上有任何的疑问和想法,我们的技术专家都在现场等你!