学界 | ACL 2017 最佳长论文,带你创造一门优雅的新语言
AI科技评论按:在昨天结束的ACL 2017大会的正会上,分别公布了今年的终身成就奖和五篇最佳论文奖。本篇文章中 AI 科技评论将带你一块儿来解读其中的最佳长论文「Probabilistic Typology: Deep Generative Models of Vowel Inventories」

在了解这篇文章之前,首先需要了解一些语言类型学的知识。根据语言类型学的研究,发现任何一种人类语言都有元音,例如英语中的[i], [u], [æ]等,把所有语言中的这些元音收集起来(目前收集的大概有600多个独立的元音)就构成了一个元音集合。这些元音通常情况下可以用其音频的前两个共振峰 (F1, F2)来表示,这样就构成了一个2维的元音空间。在这个空间中,每一个元音都可以用一个向量f(F1,F2)来表示。
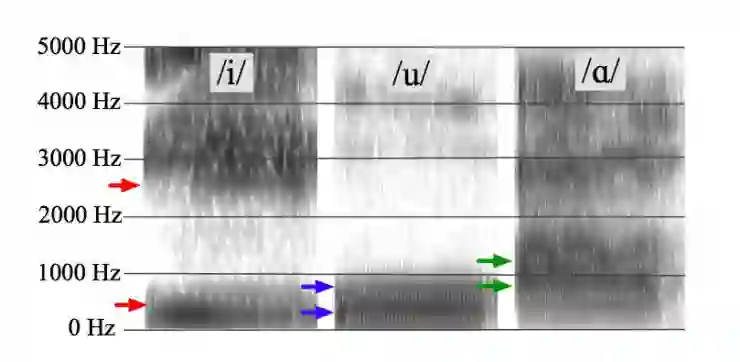
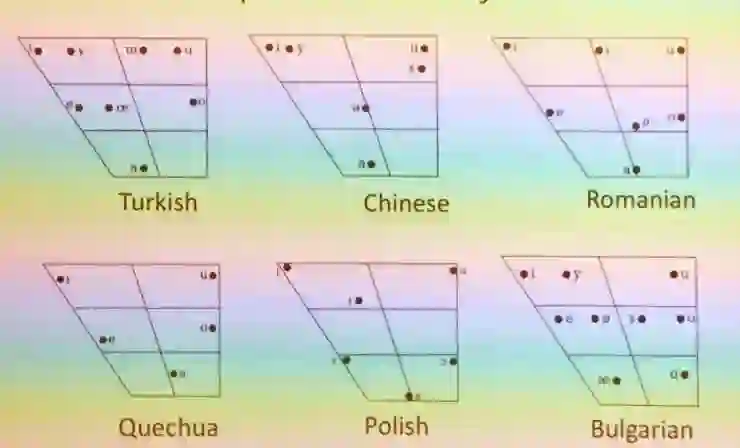
在语言类型学中对于元音有两个基本的定律:
其一,在一门语言中元音的音位必须相对较为分散,这样才能让听者能够很容易地辨别出它们,也即分散性。
其二,在所有语言中,并不是所有的元音都会出现,有些元音出现的频次较高,而有些则只在个别语言中出现或不出现,即聚焦性。
本篇论文即想要通过神经网络学习方法来对元音空间构建一个可训练的生成概率型分布方法,从而来研究语言类型学中的元音的分散性和聚焦性问题。
那么具体如何来研究呢?其实很简单,就是选定一种概率评分方法。作者考察了三种评分方法,分别为伯努利点过程(BPP)、马科夫点过程(MPP)和特征值点过程(DPP)。
其中第一种方法(伯努利点过程 )只是元音概率的乘积,所以只考虑了元音的聚焦性,而没有考虑元音之间的分散程度。其公式为
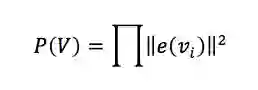
第二种评分方法中,元音概率和前一种方法一致,但是同时考虑了元音之间的聚合程度,这种方法就弥补了前一种方法分散性的问题。其公式为
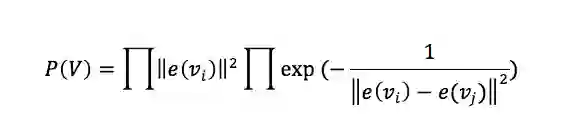
第三种评分方法,基本的考虑就是把两个元音向量乘积所得作为其评分标准。整体来考虑的话就是所有元音向量乘积构成的矩阵(称为Gram矩阵)的行列式构成其评分标准。其公式为
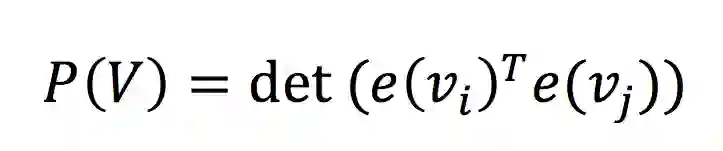
但是其中的向量e(vi)如何获得呢?在此之前人们通常是用人工的方法,通过一种音频能量最优解之类的方法来获得。而作者此处选择了神经网络训练的方法。首先,作者选用国际音标中的53个音标作为学习训练的数据集。然后分别选用三种神经网络嵌入学习方法——神经嵌入(u)、可解释神经嵌入(i)、基于原型嵌入(p)。我们以神经嵌入为例,文章中选用下面这个公式来获得前馈神经网络
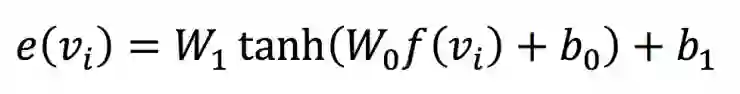
其中的f(vi)为元音向量,其他几个参数向量都将是通过学习训练获得,而e(vi)就是神经嵌入学习的结果。

通过嵌入学习方法获得的元音空间流形则能够更好地反映每个元音的概率型。将嵌入学习的结果e(vi)代入到前面的评分标准中,即可以评价每一个元音的聚焦性和每一种语言中元音的分散性。
其试验结果如下图所示(第一行中数值越小越好,下面百分比则是越大越好),其中u代表没有使用可解释的神经嵌入,i表示可解释神经嵌入,p表示基于原型的神经嵌入。
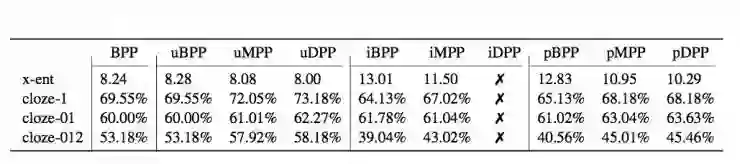
在这篇文章之前,学者们研究元音的这两个问题(分散性和聚焦性)通常是基于能量最优化的方法,即认为元音的前两个音频能量差越小聚焦性就越大,不过这种方法没法同时考虑分散性问题。而这篇文章通过概率打分可以轻而易举地同时分析这两个问题。
另外,为什么大部分语言包含的元音个数在5-7个之间呢?这也是传统人工方法所不能解决的,而在这里通过竞争的方法可以挑选出所有潜在较优(概率较大)的元音集。
当然,这篇文章中只使用了53种语言的元音作为数据集,而地球上目前有7105种语言,文章中的结果可能并不代表人类语言中元音的基本规律。不过没关系,只要有数据,按照同样的范式做再做一遍就好了。
同样的,这种使用神经网络训练来生成概率的方法不是只能使用在人类语言中元音问题上的,它更具有普适性,我们可以用同样的思路来研究语言中的辅音、词性、句式等等。或许,这篇文章将是我们用人工智能方法来研究、优化甚至创造语言的新起点。

我们知道在《权利的游戏》中东方大陆草原上有一个战斗民族多斯拉克,他们说着我们谁都听不懂的多斯拉克语。这种语言在《权利的游戏》播出之前是从来没有在地球上出现过。它是由当时年仅28岁的语言学家大卫·彼得森所创立。也许以后某一天,我们使用人工智能可以创造出更优雅的新语言。
AI 科技评论编译
论文地址: http://www.aclweb.org/anthology/P/P17/P17-1109.pdf
———————— 给爱学习的你的福利 ————————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

——————————————————————————




