CVPR 2020 | 中科大提出AANet:高效立体匹配的适应聚合网络
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文作者:Spade
https://zhuanlan.zhihu.com/p/142291358
本文已由原作者授权,不得擅自二次转载

CVPR2020接受的工作,AANet: Adaptive Aggregation Network for Efficient Stereo Matching。
论文:https://arxiv.org/abs/2004.09548
代码:https://github.com/haofeixu/aanet
本文目标是为了替代聚合部分中比较消耗显存且费时的3D卷积,但提出的2个创新点,分别用于解决边缘区域和弱纹理区域,感觉更适合作为提升模型表现的方法。
这篇论文提出的两个创新点也是应用在立体匹配算法流程中的代价聚合部分。一个是尺度内的聚合,用于针对边缘区域;另一个是交叉尺度(尺度间)的聚合,用于针对弱纹理区域。
尺度内聚合:
代价聚合从形式上来讲,是对领域内所有点代价的一个加权平均:
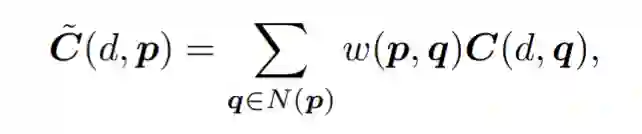
但对于处在边缘区域的点,邻域内的点可能是一些不关联的点。如下图(b)中,对于黄色的点,它属于前景,因此邻域内的背景点(左下角绿色)在视差上与其没什么关系;红色点属于背景,那么邻域内的前景点(左上角绿色)在视差上与其没什么关系。
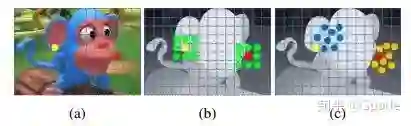
因此,在代价聚合时,我们希望邻域点尽量是和自己视差接近的点。因此,对于常规的邻域点,本文额外学一个偏移量,使得邻域内的点都是在视差上比较接近的点。
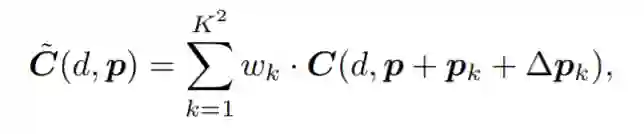

此外,在代价聚合中学到的卷积核,是在全图应用的。为了获得一个内容变化的聚合权重,对于每个领域点,额外学一个掩模 
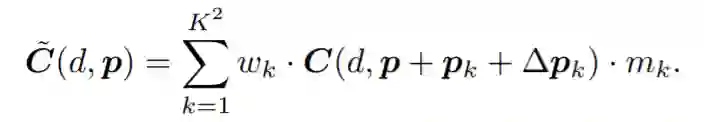
这两个量,
尺度间聚合:
一种处理弱纹理区域的想法是在较大尺度上进行操作,因此,本文在多尺度上聚合,同时每个尺度会考虑其他尺度的信息。
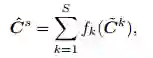
具体的 
模型:
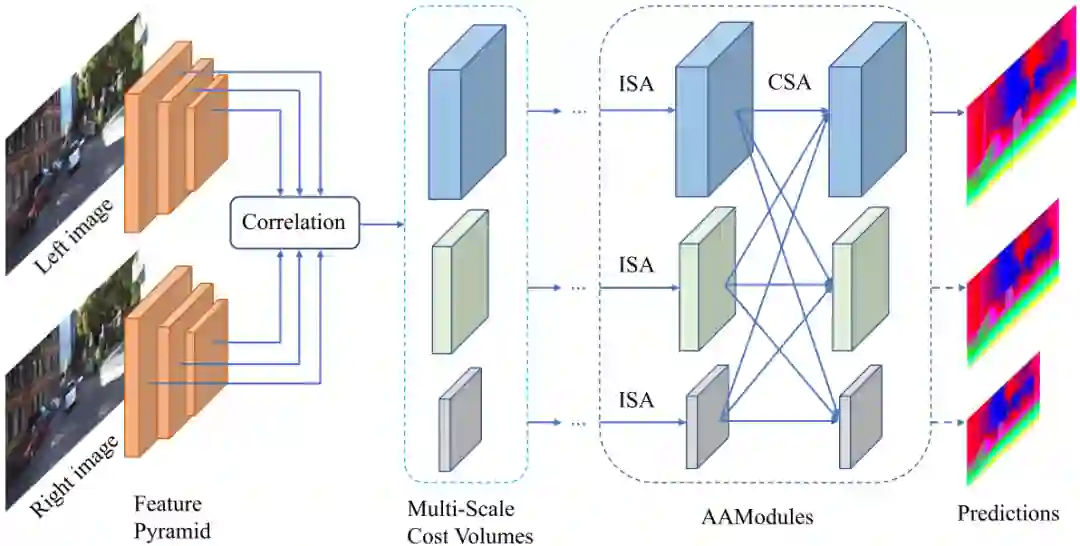
采用特征相关得到多尺度的代价体(每个3维)。然后就是尺度内聚合(ISA)和交叉尺度聚合(CSA),二者组成了本文的适应性聚合模块AAModule。堆叠多个AAModule即完成了本文的代价聚合。最终输出3个较低分辨率的视差图,采用StereoDRNet中的调优方法提升到图像分辨率。
另:本文虽然使用特征相关得到的代价体,但最终聚合得到的仍是一个 
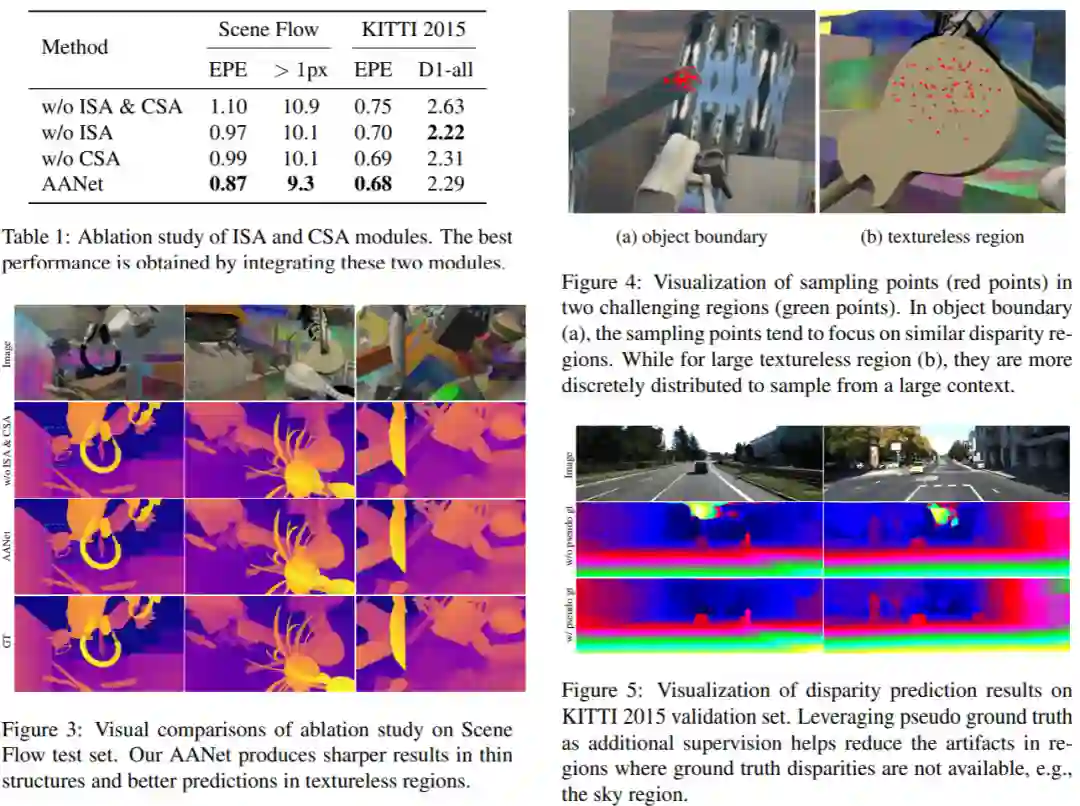
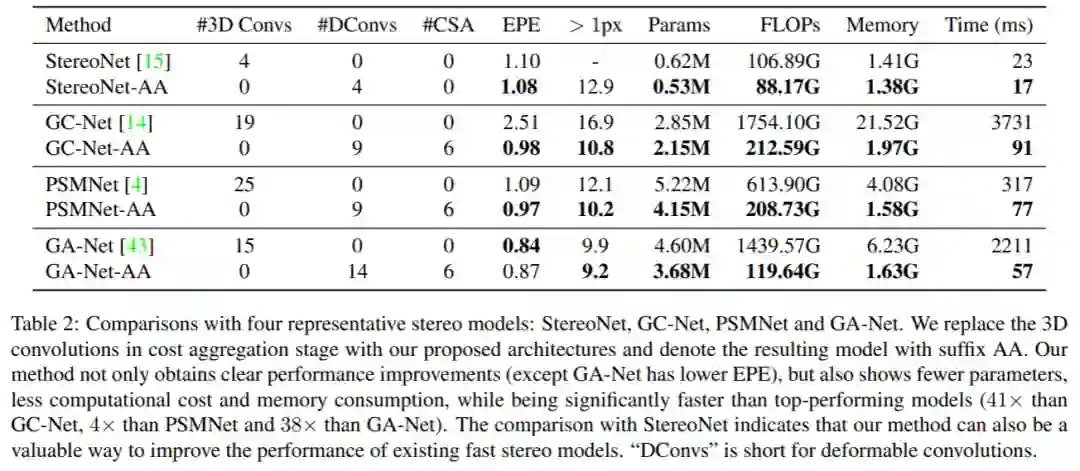
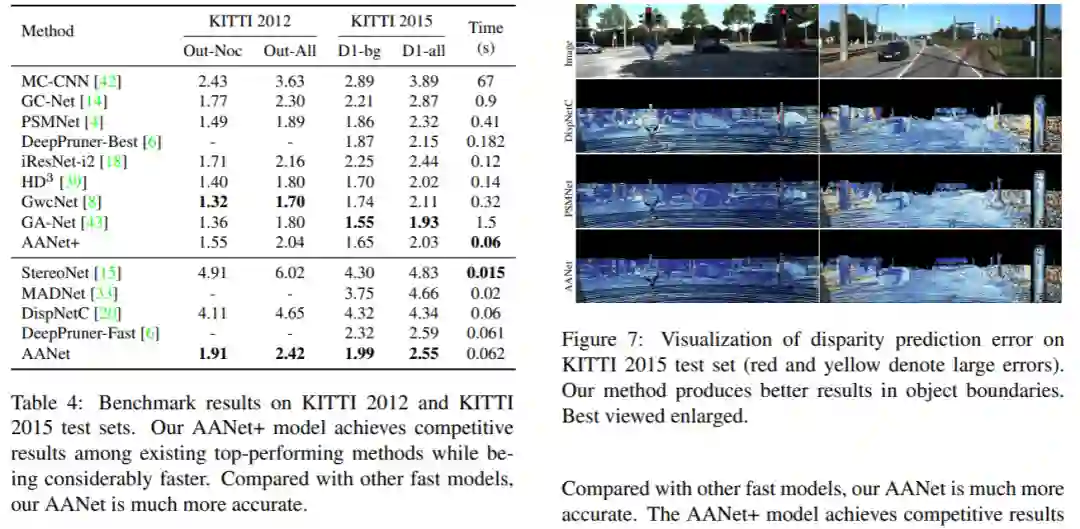
实验结果
论文下载
在CVer公众号后台回复:AANet,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1900+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!


