文本数据如何向量化展开
点击蓝字关注这个神奇的公众号~
因为最近每晚都忙于看球,所以挺长时间没有更新,今天更新一个大家比较关注的问题,就是文本类数据如何向量化展开。
一
背景
首先介绍下文本向量化展开的用途,对语文本数据常见的应用场景大致有以下两个个方面:
提取关键信息:包含关键词、关键句、摘要句等
文本分类:将文本按照某种特征维度,利用分类器进行分类,如情感分析
无论是要解决以上两个场景中的哪一种,其实对于机器学习算法而言,首先要做的都是文本向量化,也就是将字符串文字展开成可以向量表示的方式,这样才可以通过算法做分类。下面就通过一些真实的案例给大家演示下,如何做文本向量化,以及向量化方法之间的区别。
二
数据集准备
数据集采用的是我非常欣赏的一位摄影师在参观完特列季亚科夫画廊后的画评,大家如果对摄影感兴趣的话,强烈推荐她的公众号"青影三弄"
数据如下图:

三
具体方法
具体词向量展开的方法有很多,我们分别来介绍:
1.按照词频展开
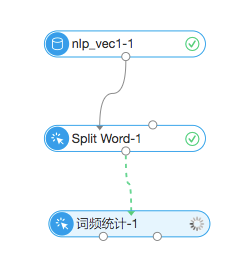
按照词频的方式展开是最基础的词向量展开方法。具体操作方式是先分词,然后统计每一句每个词出现的个数。
具体流程图:
结果图:
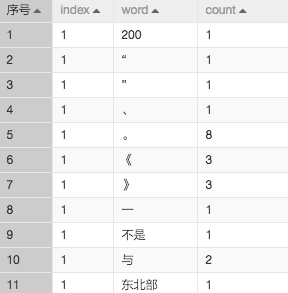
词频统计展示的是每个词在每句话中出现的个数。如果是做语句分类的场景,构建数据的时候,矩阵每一列代表一个词,每一行代表一个句子,每一个数据代表着每个词在这句话中出现的个数。
优点:这种词展开方式容易理解和实现,是文本分类中的常见用法。特别是当文本间语意内容差距较为明显的时候,可以用这种方法快速分类
缺点:缺少训练样本句子间的差异比较,对于差异化细微的语句分析有比较差的效果
2.TF-IDF
TF-IDF也是词向量展开的常用方法,其实相比于按照词频方法展开,TF-IDF更多的考虑了语句间词频的差异。比如,某一些助词“的”、“地”、“得”,虽然在每句话中出现的频率都很高,但是其实是没有实际意义的。如果有一个词X,在某一句话A中出现了非常多次,在其它话中出现的很少,那么X就是A这句话的关键词。更多的分析找出X这样的词,有助于我们更好地实现句子的分类,这就是TF-IDF的作用。
具体流程图:
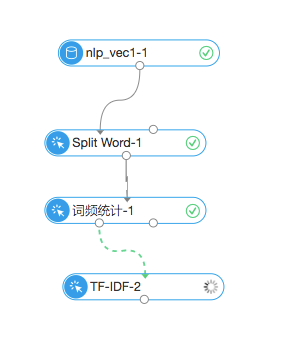
结果图:

TF-IDF展示的是每个词对于这句话的tf-idf值,这个值越大,表示这个词对于这句话的语意影响越大。如果是作为语句分类的场景,那么每句话每个词的tf-idf值都可以当成特征。
优点:更多地考虑了每个词对于每个句的影响
缺点:缺少词与词之间的关系特征
3.Word2Vec
word2vec也是常用的方式,它可以更多地表示词和词的之间的关系。比如有一句话是:
几个囚犯凑在铁栅窗前,欣赏着窗外的自由生活:孩子掉下的面包屑引来了一群欢乐的鸽子
用word2vec计算之后,可以表示出每个词的向量,这个向量会代表这个词的实际含义。比如“囚犯”和“孩子”都是人,“面包”是一种物品。那么在词向量距离里,表示囚犯“和“孩子”语音更近:
(“囚犯”-“孩子”)<(“囚犯”-“面包”)
具体流程图:
结果图:
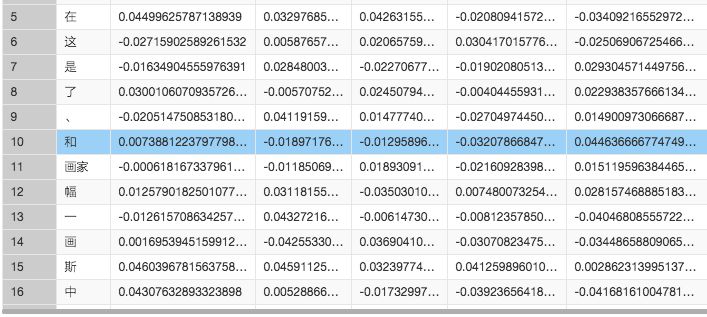
每句话的最关键的词的词向量,就可以代表这句话的语意。在语意分类的场景下,通常可以使用这种方式去构建训练集。
优点:考虑了词与词之间的含义的关联
缺点:缺少每个词与整体每句话主题之间的联系
4.LDA
LDA是基于贝叶斯理论的主题模型,可以通过LDA计算出训练样本中每个词对应每句话主题的概率,并且可以向量表示。(具体实现方式可以在网上找下,这里不多说)。
流程图:
结果图:
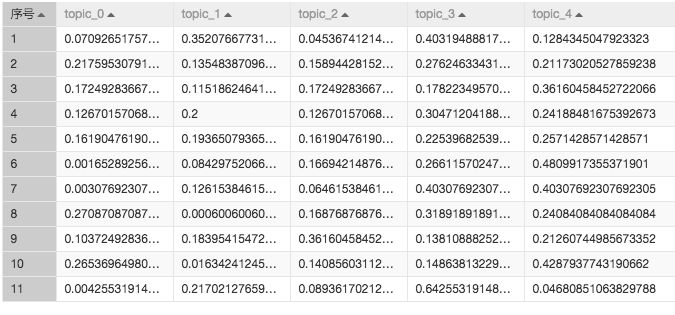
优点:可以快速的将句子展开成主题概率模型,也就是可以把每个句子通过一堆词表示
缺点:缺少词与词上下文位置的关系描述。词语出现在前后不同的位置对于语意有很大的影响,比如下面两句话“我美不?”和“我不美。”就有天差地别的语意区别。这种问题可以根据ngram来解。
四
总结
今天具体介绍了四种词向量的展开方式。这些方法都可以应用到语句分类前的词向量展开数据建模中,具体要用哪种方法,其实是根据用户自己的场景而定。要多考虑语句中关键词的影响就可以考虑TF-IDF,如果想多考虑多个主题词的影响,就可以用LDA。最稳妥的方式就是把TF-IDF、LDA、Word2vec这些方法的结果都作为特征建模,然后代入算法,如果是逻辑回归算法做分类,会自动权衡各个特征的影响大小,生成模型。这也是业内主流的文本分类方法。


