最新对象检测YOLOv4来了!
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
YOLO对象检测模型自问世以来受到计算机视觉开发者的追捧、应用广发,已经陆续发出了三个版本分别是YOLOv1~YOLOv3,现在YOLOv4也出炉了,精度与速度全面超越YOLOv3版本,废话不多说了,有图为证:
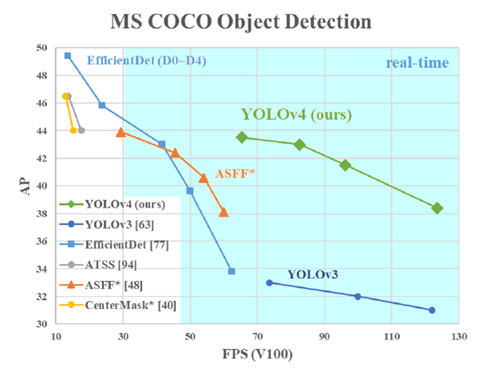
精度跟FPS分别比YOLOv3版本提升10%与12%。常见的对象检测模型分为二阶段与一阶段,图示如下:
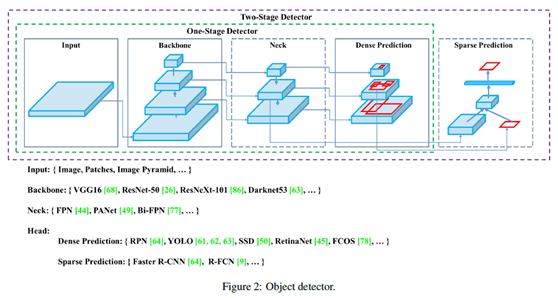
YOLOv4改进

作者的改进主要是基于以下几点:
1.可以使用1080Ti或者2080Ti训练一个超级快与高精度的对象检测器
2.在训练时使用BOF(Bag-of-Freebies)与BOS(Bag-of-Specials)模型优化技巧
3.优化模型本身,更加有效率的可以实现单GPU训练方式
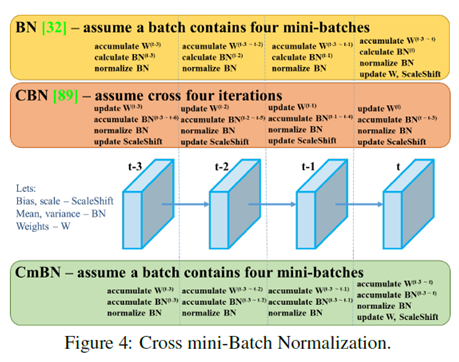
其中BOS与BOF的选择改进

选择了ReLU6作为激活函数、DropBlock作为正则化方法、因为模型只是在一个GPU上训练,所以跨GPU的归一化方法不用考虑了。
此外作者还加入下面一些提高方法:
Mosaic数据增强、自我对抗训练
优化超参数
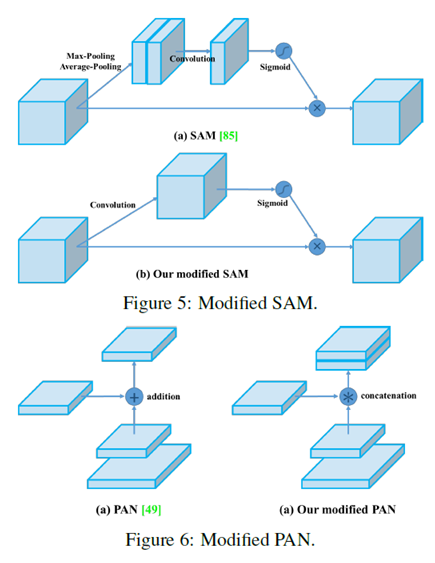
采用修改之后的SAM、PAN、CmBN
其中马赛克数据增强是一种新的数据增强方法,它是有四张训练数据组合而成,如下图所示:

总结:
最终的YOLOv4网络组成如下:
- BackBone CSPDarknet53
- Neck: SPP,PAN
- Head: YOLOv3

训练阶段各种数据增强的方法:

效果对比

论文地址
https://arxiv.org/pdf/1902.04103v2.pdf
代码
https://github.com/pjreddie/darknet
交流群
欢迎加入公众号读者群一起和同行交流,目前覆盖SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群,请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

好赞!看完分享一下啦~




