ICASSP 2018 | 阿里巴巴Oral论文:用于语音合成的深度前馈序列记忆网络
阿里巴巴语音交互智能团队
机器之心发布
作者:毕梦霄/Mengxiao Bi,卢恒/Heng Lu,张仕良/Shiliang Zhang,雷鸣/Ming Lei,鄢志杰/Zhijie Yan
语音领域的顶会 ICASSP 2018 将于 4 月 15-20 日在加拿大阿尔伯塔卡尔加里市举行。据机器之心了解,国内科技巨头阿里巴巴语音交互智能团队有 5 篇论文被此大会接收。本文介绍了其中一篇 oral 论文《Deep Feed-Forward Sequential Memory Network for Speech Synthesis》。
论文标题:Deep Feed-Forward Sequential Memory Network for Speech Synthesis

论文地址:https://arxiv.org/pdf/1802.09194.pdf
摘要
我们提出了一种基于深度前馈序列记忆网络的语音合成系统。该系统在达到与基于双向长短时记忆单元的语音合成系统一致的主观听感的同时,模型大小只有后者的四分之一,且合成速度是后者的四倍,非常适合于对内存占用和计算效率非常敏感的端上产品环境。
研究背景
语音合成系统主要分为两类,拼接合成系统和参数合成系统。其中参数合成系统在引入了神经网络作为模型之后,合成质量和自然度都获得了长足的进步。另一方面,物联网设备(例如智能音箱和智能电视)的大量普及也对在设备上部署的参数合成系统提出了计算资源的限制和实时率的要求。本工作引入的深度前馈序列记忆网络可以在保持合成质量的同时,有效降低计算量,提高合成速度。
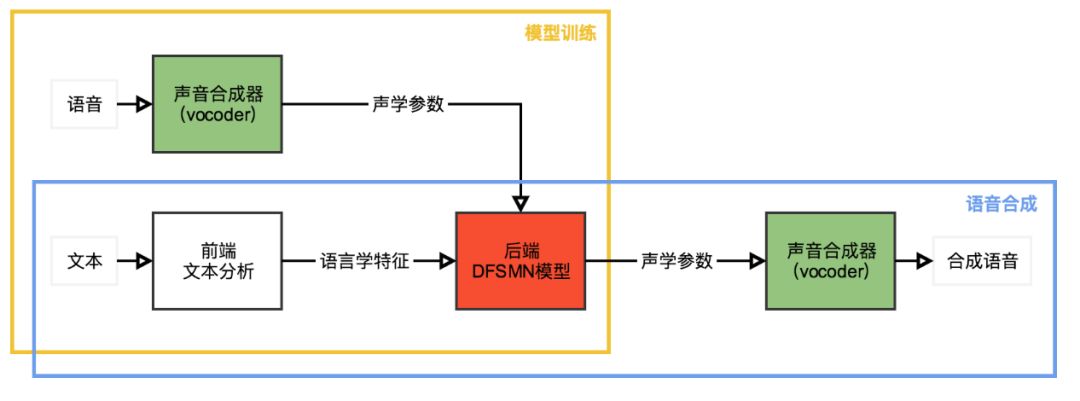
我们使用基于双向长短时记忆单元(BLSTM)的统计参数语音合成系统作为基线系统。与其他现代统计参数语音合成系统相似,我们提出的基于深度前馈序列记忆网络(DFSMN)的统计参数语音合成系统也是由 3 个主要部分组成,声音合成器(vocoder),前端模块和后端模块,如上图所示。我们使用开源工具 WORLD 作为我们的声音合成器,用来在模型训练时从原始语音波形中提取频谱信息、基频的对数、频带周期特征(BAP)和清浊音标记,也用来在语音合成时完成从声学参数到实际声音的转换。前端模块用来对输入的文本进行正则化和词法分析,我们把这些语言学特征编码后作为神经网络训练的输入。后端模块用来建立从输入的语言学特征到声学参数的映射,在我们的系统中,我们使用 DFSMN 作为后端模块。
深度前馈序列记忆网络
紧凑前馈序列记忆网络(cFSMN)作为标准的前馈序列记忆网络(FSMN)的改进版本,在网络结构中引入了低秩矩阵分解,这种改进简化了 FSMN,减少了模型的参数量,并加速了模型的训练和预测过程。
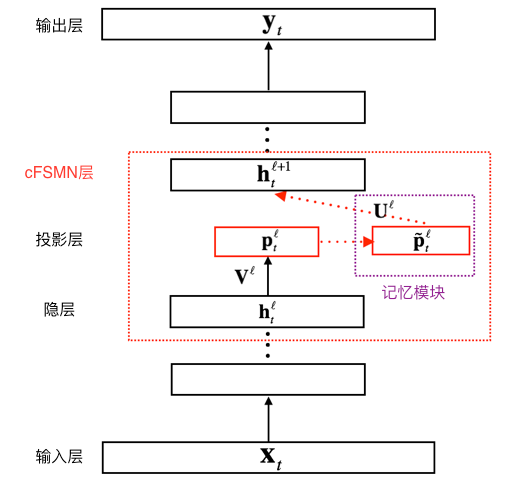
上图给出了 cFSMN 的结构的图示。对于神经网络的每一个 cFSMN 层,计算过程可表示成以下步骤①经过一个线性映射,把上一层的输出映射到一个低维向量②记忆模块执行计算,计算当前帧之前和之后的若干帧和当前帧的低维向量的逐维加权和③把该加权和再经过一个仿射变换和一个非线性函数,得到当前层的输出。三个步骤可依次表示成如下公式。
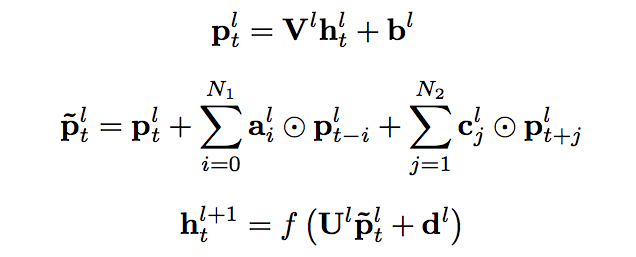
与循环神经网络(RNNs,包括 BLSTM)类似,通过调整记忆模块的阶数,cFSMN 有能力捕捉序列的长程信息。另一方面,cFSMN 可以直接通过反向传播算法(BP)进行训练,与必须使用沿时间反向传播算法(BPTT)进行训练的 RNNs 相比,训练 cFSMN 速度更快,且较不容易受到梯度消失的影响。
对 cFSMN 进一步改进,我们得到了深度前馈序列记忆网络(DFSMN)。DFSMN 利用了在各类深度神经网络中被广泛使用的跳跃连接(skip-connections)技术,使得执行反向传播算法的时候,梯度可以绕过非线性变换,即使堆叠了更多 DFSMN 层,网络也能快速且正确地收敛。对于 DFSMN 模型,增加深度的好处有两个方面。一方面,更深的网络一般来说具有更强的表征能力,另一方面,增加深度可以间接地增大 DFSMN 模型预测当前帧的输出时可以利用的上下文长度,这在直观上非常有利于捕捉序列的长程信息。具体来说,我们把跳跃连接添加到了相邻两层的记忆模块之间,如下面公式所示。由于 DFSMN 各层的记忆模块的维数相同,跳跃连接可由恒等变换实现。
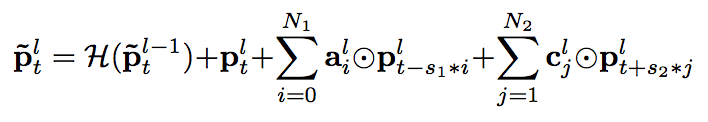
我们可以认为 DFSMN 是一种非常灵活的模型。当输入序列很短,或者对预测延时要求较高的时候,可以使用较小的记忆模块阶数,在这种情况下只有当前帧附近帧的信息被用来预测当前帧的输出。而如果输入序列很长,或者在预测延时不是那么重要的场景中,可以使用较大的记忆模块阶数,那么序列的长程信息就能被有效利用和建模,从而有利于提高模型的性能。
除了阶数之外,我们为 DFSMN 的记忆模块增加了另一个超参数,步长(stride),用来表示记忆模块提取过去或未来帧的信息时,跳过多少相邻的帧。这是有依据的,因为与语音识别任务相比,语音合成任务相邻帧之间的重合部分甚至更多。
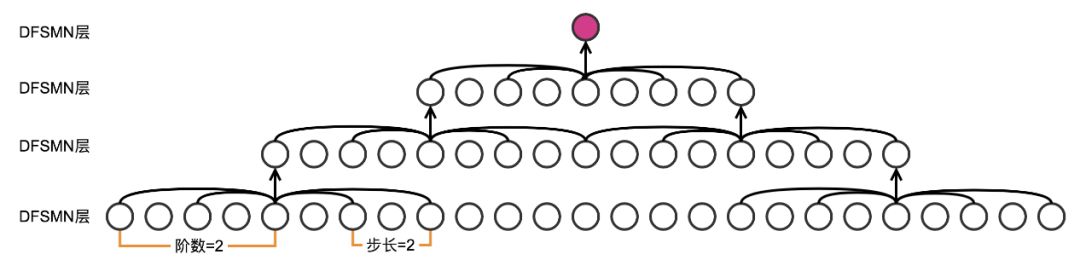
上文已经提到,除了直接增加各层的记忆模块的阶数之外,增加模型的深度也能间接增加预测当前帧的输出时模型可以利用的上下文的长度,上图给出了一个例子。
实验
在实验阶段,我们使用的是一个由男性朗读的中文小说数据集。我们把数据集划分成两部分,其中训练集包括 38600 句朗读(大约为 83 小时),验证集包括 1400 句朗读(大约为 3 小时)。所有的语音数据采样率都为 16k 赫兹,每帧帧长为 25 毫秒,帧移为 5 毫秒。我们使用 WORLD 声音合成器逐帧提取声学参数,包括 60 维梅尔倒谱系数,3 维基频的对数,11 维 BAP 特征以及 1 维清浊音标记。我们使用上述四组特征作为神经网络训练的四个目标,进行多目标训练。前端模块提取出的语言学特征,共计 754 维,作为神经网络训练的输入。
我们对比的基线系统是基于一个强大的 BLSTM 模型,该模型由底层的 1 个全连接层和上层的 3 个 BLSTM 层组成,其中全连接层包含 2048 个单元,BLSTM 层包含 2048 个记忆单元。该模型通过沿时间反向传播算法(BPTT)训练,而我们的 DFSMN 模型通过标准的反向传播算法(BP)训练。包括基线系统在内,我们的模型均通过逐块模型更新过滤算法(BMUF)在 2 块 GPU 上训练。我们使用多目标帧级别均方误差(MSE)作为训练目标。
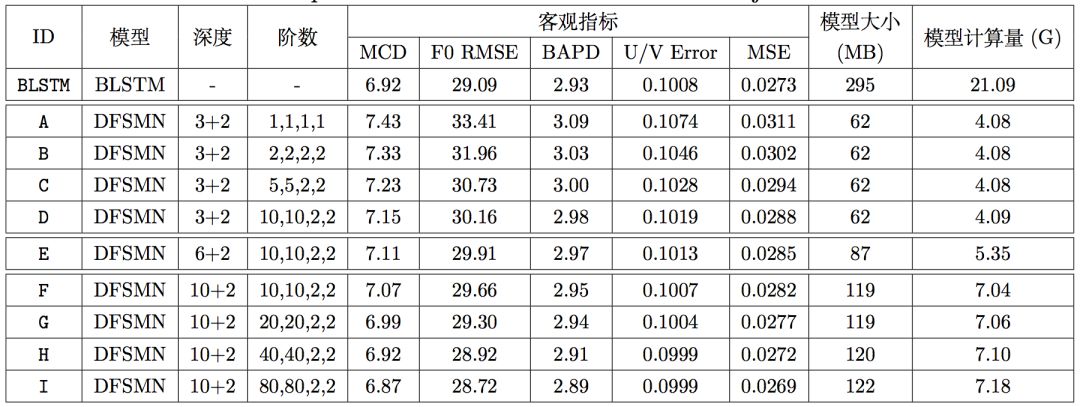
所有的 DFSMN 模型均由底层的若干 DFSMN 层和上的 2 个全连接层组成,每个 DFSMN 层包含 2048 个结点和 512 个投影结点,而每个全连接层包含 2048 个结点。在上图中,第三列表示该模型由几层 DFSMN 层和几层全连接层组成,第四列表示该模型 DFSMN 层的记忆模块的阶数和步长。由于这是 FSMN 这一类模型首次应用在语音合成任务中,因此我们的实验从一个深度浅且阶数小的模型,即模型 A 开始(注意只有模型 A 的步长为 1,因为我们发现步长为 2 始终稍好于步长为 1 的相应模型)。从系统 A 到系统 D,我们在固定 DFSMN 层数为 3 的同时逐渐增加阶数。从系统 D 到系统 F,我们在固定阶数和步长为 10,10,2,2 的同时逐渐增加层数。从系统 F 到系统 I,我们固定 DFSMN 层数为 10 并再次逐渐增加阶数。在上述一系列实验中,随着 DFSMN 模型深度和阶数的增加,客观指标逐渐降低(越低越好),这一趋势非常明显,且系统 H 的客观指标超过了 BLSTM 基线。
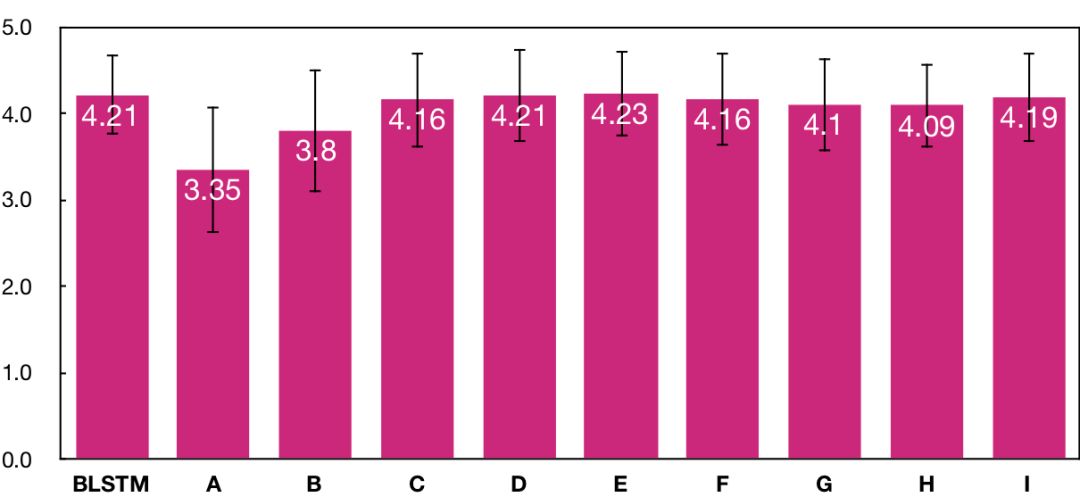
另一方面,我们也做了平均主观得分(MOS)测试(越高越好),测试结果如上图所示。主观测试是通过付费众包平台,由 40 个母语为中文的测试人员完成的。在主观测试中,每个系统生成了 20 句集外合成语音,每句合成语音由 10 个不同的测试人员独立评价。在平均主观得分的测试结果表明,从系统 A 到系统 E,主观听感自然度逐渐提高,且系统 E 达到了与 BLSTM 基线系统一致的水平。但是,尽管后续系统客观指标持续提高,主观指标只是在系统 E 得分的上下波动,没有进一步提高。
结论
根据上述主客观测试,我们得到的结论是,历史和未来信息各捕捉 120 帧(600 毫秒)是语音合成声学模型建模所需要的上下文长度的上限,更多的上下文信息对合成结果没有直接帮助。与 BLSTM 基线系统相比,我们提出的 DFSMN 系统可以在获得与基线系统一致的主观听感的同时,模型大小只有基线系统的 1/4,预测速度则是基线系统的 4 倍,这使得该系统非常适合于对内存占用和计算效率要求很高的端上产品环境,例如在各类物联网设备上部署。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



