【专栏】极限元语音算法专家刘斌:基于深度学习的语音生成问题
基于深度学习的语音生成问题
作者:刘斌
来源:机器之心专栏
深度学习在 2006 年崭露头角后,近几年取得了快速发展,在学术界和工业界均呈现出指数级增长的趋势;伴随着这项技术的不断成熟,深度学习在智能语音领域率先发力,取得一系列成功的应用。本文将重点分享近年来深度学习在语音生成问题中的新方法,围绕语音合成和语音增强两个典型问题展开介绍。
一、深度学习在语音合成中的应用
语音合成主要采用波形拼接合成和统计参数合成两种方式。波形拼接语音合成需要有足够的高质量发音人录音才能够合成高质量的语音,它在工业界中得到了广泛使用。统计参数语音合成虽然整体合成质量略低,但是在发音人语料规模有限的条件下,优势更为明显。在上一期我们重点介绍了深度学习在统计参数语音合成中的应用,本期将和大家分享基于波形拼接的语音合成系统,围绕 Siri 近期推出的语音合成系统展开介绍,它是一种混合语音合成系统,选音方法类似于传统的波形拼接方法,它利用参数合成方法来指导选音,本质上是一种波形拼接语音合成系统。
单元选择是波形拼接语音合成系统的基本难题,需要在没有明显错误的条件下将合适的基元组合在一起。语音合成系统通常分为前端和后端两个部分,前端模块对于提高语音合成系统的表现力起到非常重要的作用。前端模块将包含数字、缩写等在内的原始文本正则化,并对各个词预测读音,解析来自文本的句法、节奏、重音等信息。因此,前端模块高度依赖于语言学信息。后端通过语言学特征预测声学参数,模型的输入是数值化的语言学特征。模型的输出是声学特征,例如频谱、基频、时长等。在合成阶段,利用训练好的统计模型把输入文本特征映射到声学特征,然后用来指导选音。在选音过程中需要重点考虑以下两个准则:(1)候选基元和目标基元的特征必须接近;(2)相邻两个基元的边界处必须自然过渡。可以通过计算目标代价和拼接代价评估这两个准则;然后通过维特比算法计算最优路径确定最终的候选基元;最后通过波形相似重叠相加算法找出最佳拼接时刻,因此生成平滑且连续合成语音。
Siri 的 TTS 系统的目标是训练一个基于深度学习的统一模型,该模型能自动准确地预测数据库中单元的目标成本和拼接成本。因此该方法使用深度混合密度模型来预测特征值的分布。这种网络结构结合了常规的深度神经网络和高斯混合模型的优势,即通过 DNN 对输入和输出之间的复杂关系进行建模,并且以概率分布作为输出。系统使用了基于 MDN 统一的目标和拼接模型,该模型能预测语音目标特征(谱、基频、时长)和拼接成本分布,并引导基元的搜索。对于元音,有时语音特征相对稳定,而有些时候变化又非常迅速,针对这一问题,模型需要能够根据这种变化性对参数作出调整,因此在模型中使用嵌入方差解决这一问题。系统在运行速度、内存使用上具有一定优势,使用快速预选机制、单元剪枝和计算并行化优化了它的性能,可以在移动设备上运行。
二、深度学习在语音增强中的应用
通过语音增强可以有效抑制各种干扰信号,增强目标语音信号;有效的语音增强算法一方面可以提高语音可懂度和话音质量,另一方面有助于提高语音识别和声纹识别的鲁棒性。经典的语音增强方法包括谱减法、维纳滤波法、最小均方误差法,上述方法基于一些数学假设,在真实环境下难以有效抑制非平稳噪声的干扰。基于盲分离的非负矩阵分解方法也得到了一定关注,但是这类方法计算复杂度相对较高;近年来,基于深度学习的语音增强方法得到了越来越多的关注,接下来重点介绍几种典型的基于深度学习的语音增强方法。
1. 预测幅值谱信息
这类方法通过深层神经网络模型建立带噪语音和干净语音谱参数之间的映射关系,模型的输入是带噪语音的幅值谱相关特征,模型的输出是干净语音的幅值谱相关特征,通过深层神经网络强大的非线性建模能力重构安静语音的幅值谱相关特征;神经网络模型结构可以是 DNN/BLSTM-RNN/CNN 等;相比于谱减、最小均方误差、维纳滤波等传统方法,这类方法可以更为有效的利用上下文相关信息,对于处理非平稳噪声具有明显的优势。
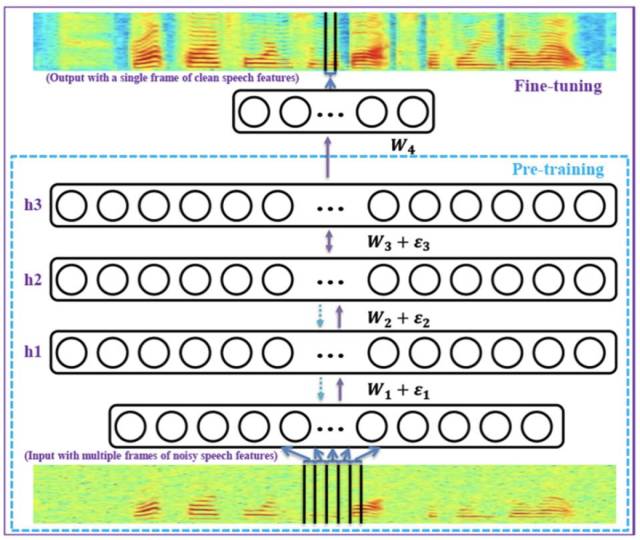
2. 预测屏蔽值信息
采用这类方法建模时模型的输入可以是听觉域相关特征,模型的输出是二值型屏蔽值或浮点型屏蔽值,最常用的听觉域特征是 Gamma 滤波器相关特征,这种方法根据听觉感知特性将音频信号分成不同子带提取特征参数;对于二值型屏蔽值,如果某个时频单元能量是语音主导,则保留该时频单元能量,如果某个时频单元能量是噪声主导,则将该时频单元能量置零;采用这种方法的优势是,共振峰位置处的能量得到了很好的保留,而相邻共振峰之间波谷处的能量虽然失真误差较大,但是人耳对这类失真并不敏感;因此通过这种方法增强后的语音具有较高的可懂度;浮点值屏蔽是在二值型屏蔽基础上进一步改进,目标函数反映了对各个时频单元的抑制程度,进一步提高增强后语音的话音质量和可懂度。
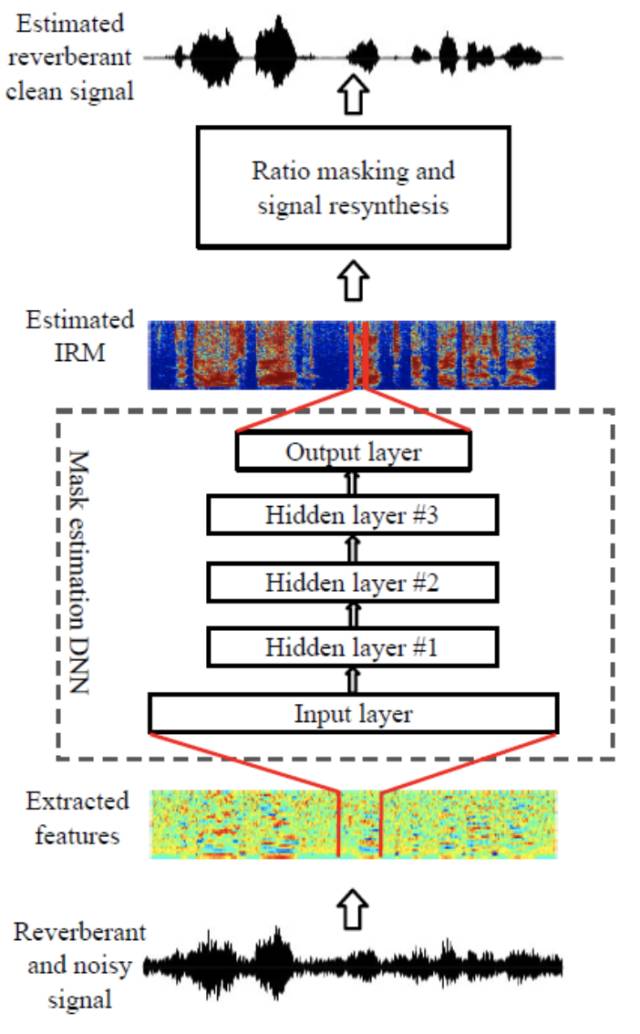
3. 预测复数谱信息
目前主流的语音增强方法更多的关注于对幅值谱相关特征的增强而保留原始语音的相位谱,随着信噪比的降低相位谱失真对听感的影响明显增强,在低信噪比条件下,有效的相位重构方法可以有助于提高语音可懂度;一种典型的相位重构方法是利用基音周期线索对浊音段的相位进行有效修复,但是这类方法无法有效估计清音段的相位信息;复数神经网络模型可以对复数值进行非线性变换,而语音帧的复数谱能够同时包含幅值谱信息和相位谱信息,可以通过复数神经网络建立带噪语音复数谱和干净语音复数谱的映射关系,实现同时对幅值信息和相位信息的增强。
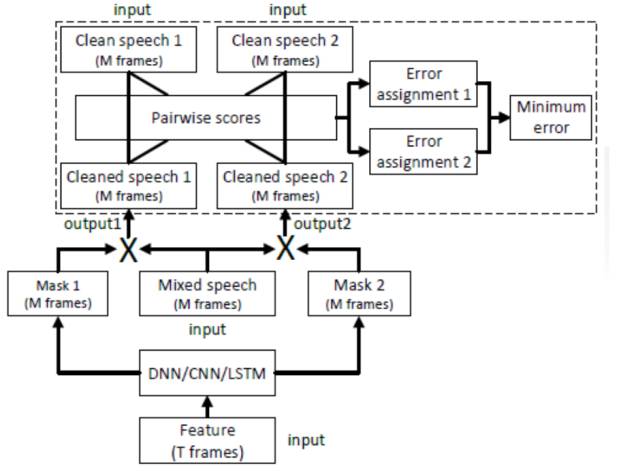
4. PIT 说话人分离
通过说话人分离技术可以将混叠语音中不同的说话人信息有效分离出来,已有的基于深度学习的说话人分离模型受限于说话人,只能分离出特定说话人的声音;采用具有置换不变性的训练方法得到的说话人分离模型不再受限于特定说话人;这种方法通过自动寻找分离出的信号和标注的声源之间的最佳匹配来优化语音增强目标函数;模型的输入是混叠语音的谱参数特征,模型的输出包含多个任务,每个任务对应一个说话人;在训练过程中,对于训练集中一个样本内,每个任务固定对应某个说话人;可以采用 BLSTM-RNN 模型结构建模。
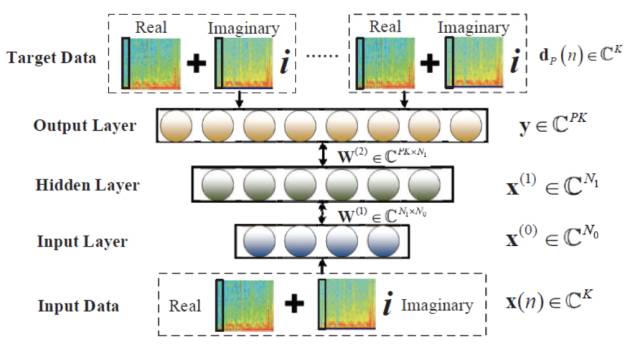
5. DeepClustering 说话人分离
基于深度聚类的说话人分离方法是另一种说话人无关的分离模型,这种方法通过把混叠语音中的每个时频单元结合它的上下文信息映射到一个新的空间,并在这个空间上进行聚类,使得在这一空间中属于同一说话人的时频单元距离较小可以聚类到一起;将时频单元映射到新的空间跟词矢量抽取的思想有些类似,可以通过 k 均值聚类的方法对时频单元分组,然后计算二值型屏蔽值分离出不同说话人的语音,也可以通过模糊聚类的方法描述不同的时频单元,然后计算浮点型屏蔽值后分离混叠语音。基于深层聚类的方法和基于 PIT 的方法有着各自的优势,为了更有效的解决问题,可能需要将两种方法有效的结合。
6. 基于对抗网络的语音增强
在深度学习生成模型方面的最新突破是生成对抗网络,GAN 在计算机视觉领域生成逼真图像上取得巨大成功,可以生成像素级、复杂分布的图像。GAN 还没有广泛应用于语音生成问题。本文介绍一种基于对抗网络的语音增强方法。这种方法提供了一种快速增强处理方法,不需要因果关系,没有 RNN 中类似的递归操作;直接处理原始音频的端到端方法,不需要手工提取特征,无需对原始数据做明显假设;从不同说话者和不同类型噪声中学习,并将它们结合在一起形成相同的共享参数,使得系统简单且泛化能力较强。
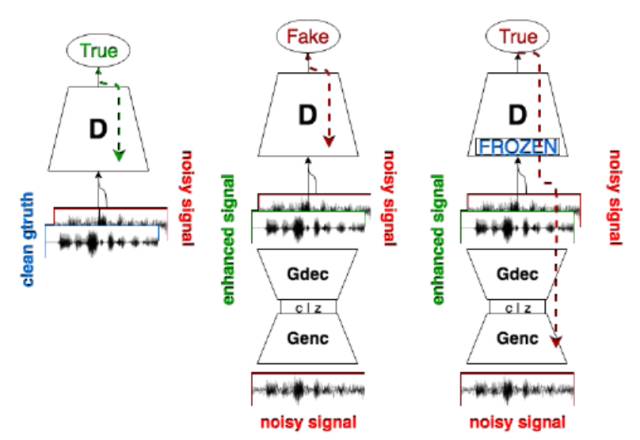
语音增强问题是由输入含噪信号得到增强信号,这种方法通过语音增强 GAN 实现,其中生成网络用于增强。它的输入是含噪语音信号和潜在表征信号,输出是增强后的信号。将生成器设计为全部是卷积层(没有全连接层),这么做可以减少训练参数从而缩短了训练时间。生成网络的一个重要特点是端到端结构,直接处理原始语音信号,避免了通过中间变换提取声学特征。在训练过程中,鉴别器负责向生成器发送输入数据中真伪信息,使得生成器可以将其输出波形朝着真实的分布微调,从而消除干扰信号。
三、总结
本文围绕着近年来深度学习在语音合成和语音增强问题中的新方法展开介绍,虽然语音合成和语音增强需要解决的问题不同,但是在建模方法上有很多相通之处,可以相互借鉴。深度学习方法在语音转换、语音带宽扩展等领域也有着广泛的应用,感兴趣的读者可以关注这一领域最新的研究成果。虽然深度学习的快速发展推动了智能语音产品的落地,但是仍有些问题不能依赖于深度学习方法彻底解决,例如提高合成语音的表现力、提高增强后语音的可懂度,需要在对输入输出特征的物理含义深入理解的基础上,有效的表征信息,选择合适的方法进行建模。
刘斌:中科院自动化所博士,极限元资深智能语音算法专家,中科院-极限元智能交互联合实验室核心技术人员,在国际顶级会议上发表多篇文章,获得多项关于语音及音频领域的专利,具有丰富的工程经验,擅长语音信号处理和深度学习,提供有效的技术解决方案。
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【分析】图像分类、目标检测、图像分割、图像生成……一文「计算机视觉」全分析





