学界 | 大白话解释模型产生过拟合的原因
AI科技评论按:本文原作者忆臻,原载于作者的知乎专栏。
今天郭江师兄在实验室讲解了全体机器学习会第一章的知识,大家讨论了一下过拟合的知识,这里我根据自己的理解,整理了一下原因,力求同最通俗的语言来描述,可能不是太严谨,但是总体思想能保证正确!
一、过拟合的概念?
首先我们来解释一下过拟合的概念?
过拟合就是训练出来的模型在训练集上表现很好,但是在测试集上表现较差的一种现象!下图给出例子:
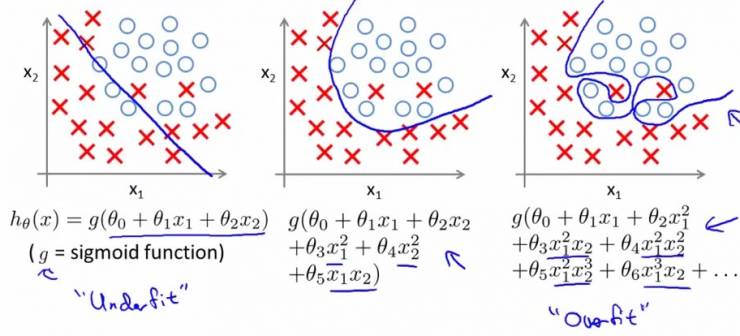
我们将上图第三个模型解释为出现了过拟合现象,过度的拟合了训练数据,而没有考虑到泛化能力。在训练集上的准确率和在开发集上的准确率画在一个图上如下:
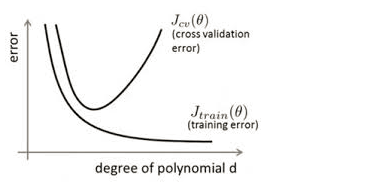
从图中我们能够看出,模型在训练集上表现很好,但是在交叉验证集上表现先好后差。这也正是过拟合的特征!
二、模型出现过拟合现象的原因
发生过拟合的主要原因可以有以下三点:
(1)数据有噪声
(2)训练数据不足,有限的训练数据
(3)训练模型过度导致模型非常复杂
下面我将分别解释这三种情况(这里按自己的理解解释,欢迎大家交流):
(1)数据有噪声
为什么数据有噪声,就可能导致模型出现过拟合现象呢?
所有的机器学习过程都是一个 search 假设空间的过程!我们是在模型参数空间搜索一组参数,使得我们的损失函数最小,也就是不断的接近我们的真实假设模型,而真实模型只有知道了所有的数据分布,才能得到。
往往我们的模型是在训练数据有限的情况下,找出使损失函数最小的最优模型,然后将该模型泛化于所有数据的其它部分。这是机器学习的本质!
那好,假设我们的总体数据如下图所示:
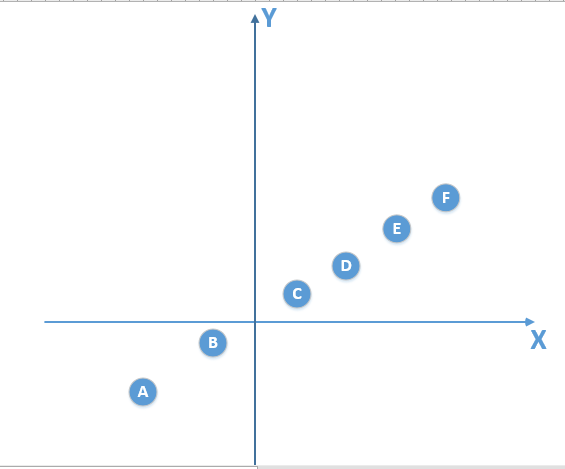
(我这里就假设总体数据分布满足一个线性模型 y = kx+b, 现实中肯定不会这么简单,数据量也不会这么少,至少也是多少亿级别,但是不影响解释。反正总体数据满足模型 y)
此时我们得到的部分数据,还有噪声的话,如图所示:
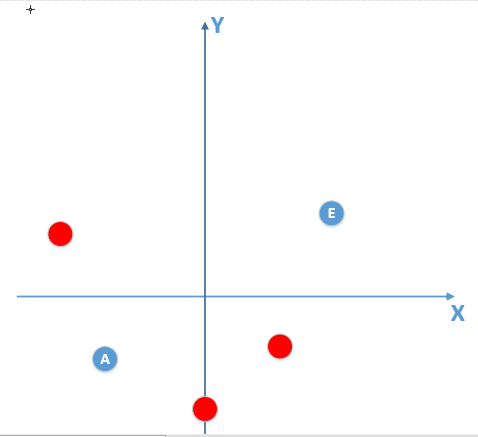
(红色数据点为噪声)
那么由上面训练数据点训练出来的模型肯定不是线性模型(总体数据分布下满足的标准模型),比如训练出来的模型如下:
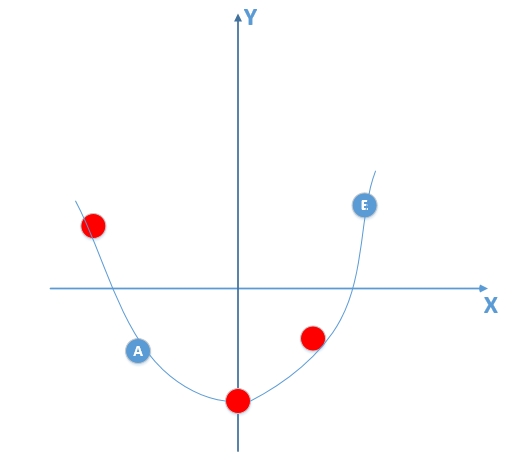
那么我拿着这个有噪声训练的模型,在训练集合上通过不断训练,可以做到损失函数值为 0,但是拿着这个模型,到真实总体数据分布中(满足线性模型)去泛化,效果会非常差,因为你拿着一个非线性模型去预测线性模型的真实分布,显而易得效果是非常差的,也就产生了过拟合现象!
(2)训练数据不足,有限的训练数据
当我们训练数据不足的时候,即使得到的训练数据没有噪声,训练出来的模型也可能产生过拟合现象,解释如下:
假设我们的总体数据分布如下:
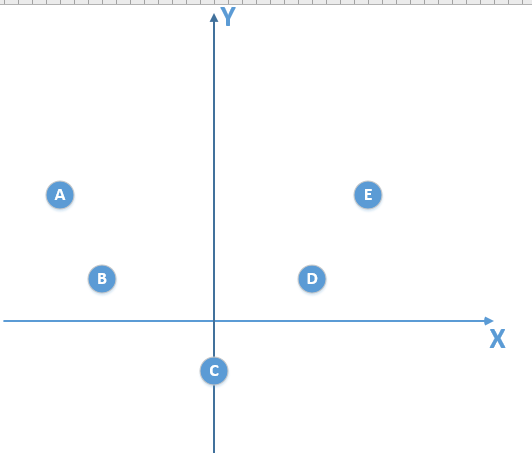
(为了容易理解,假设我们的总体数据分布满足的模型是一个二次函数模型)
我们得到的训练数据由于是有限的,比如是下面这个:

(我只得到了 A,B 两个训练数据)
那么由这个训练数据,我得到的模型是一个线性模型,通过训练较多的次数,我可以得到在训练数据使得损失函数为 0 的线性模型,拿这个模型我去泛化真实的总体分布数据(实际上是满足二次函数模型),很显然,泛化能力是非常差的,也就出现了过拟合现象!
(3)训练模型过度导致模型非常复杂
训练模型过度导致模型非常复杂,也会导致过拟合现象!这点和第一点俩点原因结合起来其实非常好理解,当我们在训练数据训练的时候,如果训练过度,导致完全拟合了训练数据的话,得到的模型不一定是可靠的。
比如说,在有噪声的训练数据中,我们要是训练过度,会让模型学习到噪声的特征,无疑是会造成在没有噪声的真实测试集上准确率下降!
好了,到这里本文要讲的内容已经讲完了,我根据自己的理解,试图通俗的讲解产生过拟合的原因,希望能够让更多的人有一个直观的理解~ 真心希望对大家有帮助,欢迎大家指错交流~
报名 |【2017 AI 最佳雇主】榜单
在人工智能爆发初期的时代背景下,雷锋网联合旗下人工智能频道AI科技评论,携手 环球科学 和 BOSS 直聘,重磅推出【2017 AI 最佳雇主】榜单。
从“公司概况”、“创新能力”、“员工福利”三个维度切入,依据 20 多项评分标准,做到公平、公正、公开,全面评估和推动中国人工智能企业发展。
本次【2017 AI 最佳雇主】榜单活动主要经历三个重要时段:
2017.4.11-6.1 报名阶段
2017.6.1-7.1 评选阶段
2017.7.7 颁奖晚宴
最终榜单名单由雷锋网、AI科技评论、《环球科学》、BOSS 直聘以及 AI 学术大咖组成的评审团共同选出,并于7月份举行的 CCF-GAIR 2017大会期间公布。报名期间欢迎大家踊跃自荐或推荐心目中的最佳 AI 企业公司。
报名方式
如果您有意参加我们的评选活动,可以点击【阅读原文】,进入企业报名通道。提交相关审核材料之后,我们的工作人员会第一时间与您取得联系。
【2017 AI 最佳雇主】榜单与您一起,领跑人工智能时代。

AI科技评论招聘季全新启动!
很多读者在思考,“我和AI科技评论的距离在哪里?”答案就是:一封求职信。
AI科技评论自创立以来,围绕学界和业界鳌头,一直为读者提供专业的AI学界、业界、开发者内容报道。我们与学术界一流专家保持密切联系,获得第一手学术进展;我们深入巨头公司AI实验室,洞悉最新产业变化;我们覆盖A类国际学术会议,发现和推动学术界和产业界的不断融合。
而你只要加入我们,就可以一起来记录这个风起云涌的人工智能时代!
如果你有下面任何两项,请投简历给我们:
*英语好,看论文毫无压力
*理工科或新闻相关专业优先,好钻研
*对人工智能有一定的兴趣或了解
* 态度好,学习能力强
简历投递:
深圳:lizongren@leiphone.com




