ECCV 2020 | 南京大学王利民团队提出BCN:时序动作分割新方法
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:王利民
https://zhuanlan.zhihu.com/p/199403632
本文已由原作者授权,不得擅自二次转载
今天介绍一篇我们NJU-MCG在时序动作分割领域的工作 Boundary-Aware Cascade Networks for Temporal Action Segmentation (BCN),发表于ECCV 2020。本文针对时序动作分割任务中现存的两个主要问题进行了改进:(1) 具有歧义的困难帧分类效果差(尤其是动作边界附近精度较低);(2) 现存方法普遍存在过分割(over-segmentation)问题,从而大幅提升了效果。针对这两个问题,我们分别使用 (1) 区分难易样本的自适应级联网络(Stage Casacde)使得难样本的分类精度(Accuracy)大幅提高;和 (2) 结合动作边界信息的时序正则化方法(Local Barrier Pooling)在显式地减少了过分割的情况的同时不降低分类精度,从而显著提高了F1-score 和 Edit-score。我们将这两种效果互补的方法统一在一个整体框架中,可以通用地改进任何多阶段[1](Multi-Stage)的时序动作分割方法的效果。

论文链接:
http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123700035.pdf
代码链接(ECCV online video ppt也在此链接中):
https://github.com/MCG-NJU/BCN
ECCV Poster Session: Thursday, 27 August - UTC+8 (北京时间) 07:00 - 09:00, 13:00 - 15:00. 欢迎来zoom房间与一作聊天。
1. 任务介绍
简单介绍一下什么是时序动作分割任务:属于视频领域的任务,视频领域常见的任务有动作识别、时序动作检测与分割、时空动作检测、以及一些多模态任务等等。
动作识别 (Action Recognition) : 对每个输入视频进行分类,识别出视频中人物做出的动作。即输入一个视频,得到视频对应的类别。方法主要是Two-Stream和3D Conv两个流派,近期I3D,SlowFast等网络成为主流,常常作为后续任务的特征提取器。
时序动作检测 (Temporal Action Detection/Localization) :输入一个未经裁剪的长视频 (untrimmed video),即视频中既包括有动作的前景区间,也包括没有明确语义的背景区间。任务需要检测(或定位,此任务中这两个词等价)出动作开始和结束的区间,并判断区间内动作的类别。即输入未经裁剪的视频序列,得到动作出现的区间和对应的类别。常用数据集为THUMOS14与ActivityNet。
时序动作分割 (Temporal Action Segmentation) :输入一个未经裁剪的长视频 (untrimmed video),相比于时序动作检测来说往往是一些连续动作的场景,例如instructional video。任务需要对每一个视频帧进行分类,类比到语义分割中即为对每一个像素进行分类,但是由于一维区间的特点,计算时序IOU(tIOU)时遇到小段孤立的错误结果会非常敏感。由于同一个视频帧不能具有两个标签,因此与时序动作检测允许检测结果overlap的情况很不一样,导致处理方法与网络结构也很不一样。与时序动作检测用于长视频稀疏动作检测的场景相比,此任务的方法往往适用于一些更加细致(fine-grained)的场景,例如生产线上,教学视频等连续的同一场景不同动作的识别与检测。常用数据集为GTEA,50Salads,Breakfast,Hollywood。
时空动作检测 (spatio-temporal action detection) :相比于时序动作检测略有不同,时空动作检测不仅需要识别动作出现的区间和对应的类别,还要在空间范围内用一个包围框 (bounding box)标记出人物的空间位置。此任务可以关注我们组另一个工作MOC (Actions as Moving Points)。
视频领域中其他多模态任务:有监督信号的任务往往是利用视频图像,音频,音频提取出的文字等模态进行的Visual Question Answering (VQA),Video Caption,Temporal Language Grounding等。无监督信号的任务往往是利用大规模的视频数据集,利用字幕,音频,视频图像等多个模态的pair做自监督预训练任务,从而得到一个很好的视频特征表示网络。自监督预训练任务可以关注我们组另一个工作CPD (arxiv.org/abs/2001.05691)。
2. 研究动机
由于时序动作分割处理的视频是未经修剪的长视频,因此长时序建模(modeling long-term dependency)很重要,此前的模型往往利用 (1) LSTM, (2) Encoder-Decoder (3) Dilated Convolution等方法,通过在时序建模网络中增大感受野来获得较好的效果。不过,由于要求预测结果的时间分辨率与原视频一样高,并且此任务的评价指标对于单帧错误预测很敏感,因此对于模型防止过拟合的能力提出了较高的要求,不可能无限制地通过增加模型能力来提高对于难样本的精度。尤其地,我们通过可视化发现,即使是此前的SOTA方法MS-TCN (arxiv.org/abs/1903.0194) 也存在两种典型的问题:(1) 具有歧义的困难帧,尤其是动作边界附近的那些帧,分类精度较差;(2) 长动作区间内出现的过分割[2](over-segmentation)问题。下面我们分别针对这两种问题进行分析。
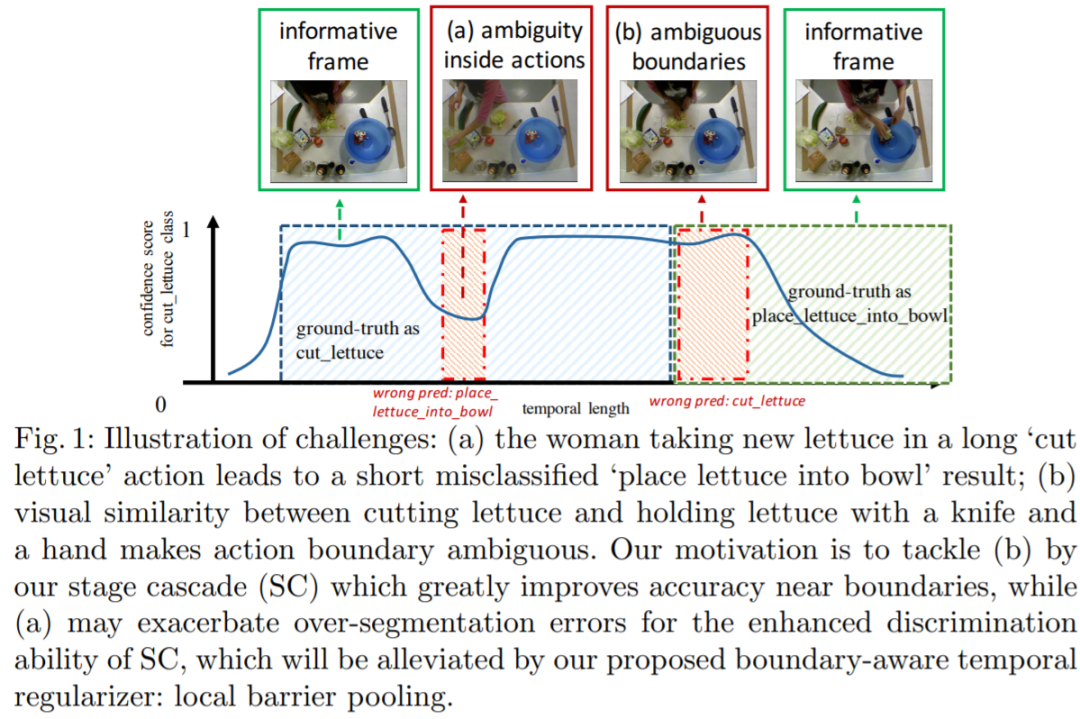
直觉上说,同一个视频中有些帧会比其他帧具有更多的歧义,例如动作边界,视角切换,遮挡等等,简单地提高模型复杂度肯定会倾向于导致过拟合。用一个单一模型去同时处理具有丰富语义信息的简单帧和具有歧义的困难帧会由于训练时这些样本的数据分布不一致和不均衡而导致对于难样本的预测结果较差(低置信度或错误的预测)。因此我们设计了一种动态的建模方法,具体来说是根据样本的难易程度来自适应地采用不同的子网络来处理:浅层子网络处理简单样本,深层子网络处理难样本,通过自适应地调整这些样本对应的loss的权重,以及最终聚合多个子网络生成最终结果时的权重,我们实现了根据难度动态建模的目的,提高了对于难样本的分类精度。
但是由此带来的副作用是,动态建模的能力进一步导致了比baseline更加严重的过分割现象,需要一个更加强有效的时序正则化方法来修正这个结果。与常用的基于相邻结果差值惩罚的loss(类似于机器学习中常用的正则化loss)这个视角不一样,我们希望能够更加有效地直接地解决这个问题,因此我们采用了利用邻域信息进行pooling的思想来改善预测结果的光滑程度。单单利用启发式的average pooling或者gaussian weighted-sum肯定会导致分类精度的下降,或者平滑效果不佳的情况,因此我们在这个任务中第一次引入了时序动作检测中的“动作边界”这样的概念,将子网络预测出来的动作边界作为参数,传入一种我们提出的带参数的pooling方法:Local Barrier Pooling。这些动作边界就像barrier一样,保持边界内部的语义一致,隔离开两个动作之间信息的相互影响,从而极大改善了过分割现象。
3. 具体方法
我们的两个子模块与总体框架图如下:
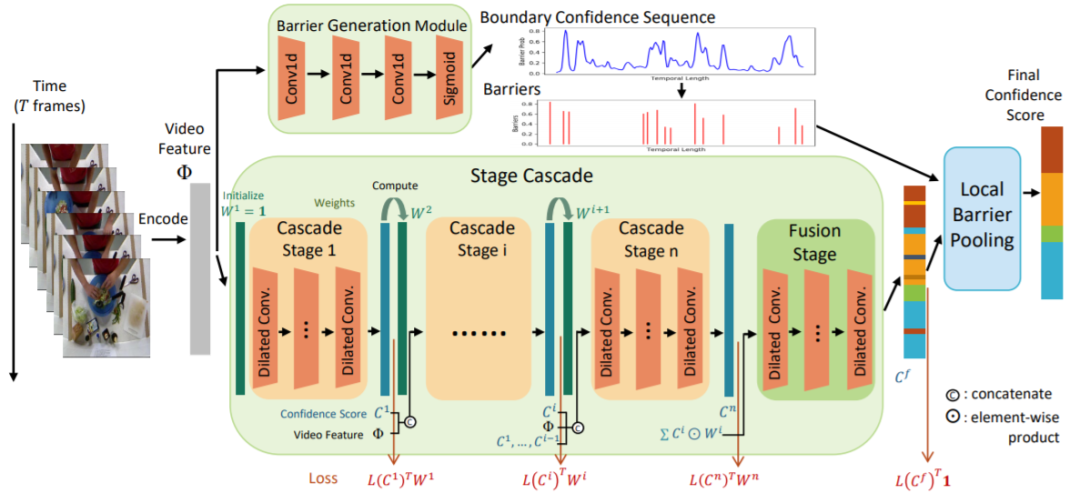
我们的模型处理流程是,对于一个长度为T的输入视频帧序列,首先以每帧为中心,在局部区间提出I3D特征作为此帧的特征,然后对于长度为T的特征序列,将其分别输入到两个分支中。对于Stage Cascade,我们利用n个stage的MS-TCN为backbone,前n-1个stage为用于处理不同难度分布的cascade stage,最后一个stage为融合前面n-1个stage结果的fusion stage。对于n-1个cascade stage,我们首先把第一个stage的权重初始化为全1向量,然后每个stage都根据上一个stage对于每一帧的分类置信度自适应地利用一个权重因子 




得到这样一个权重矩阵以后,我们在权重矩阵的stage number方向聚合多个stage的预测结果,在frame number方向调整每个stage的loss权重分布( 


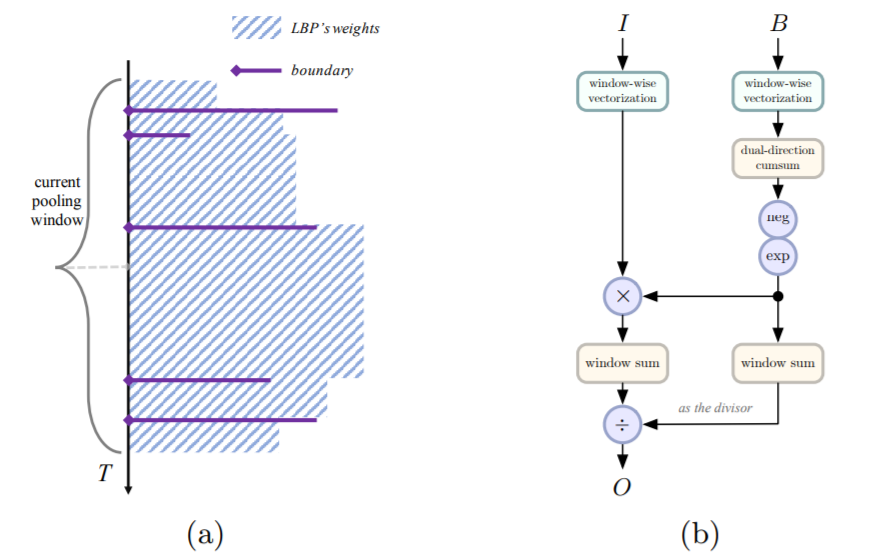
我们的Local Barrier Pooling首先利用Barrier Generation Module (网络结构借鉴BSN中的TEM)预测出动作边界分类置信度,然后通过阈值处理出一些选中的barrier。将这些barrier(未选中置0即可)和Stage Cascade预测出的frame-wise classification confidence输入LBP,我们通过以下的公式进行邻域内的平滑( 


4. 实验
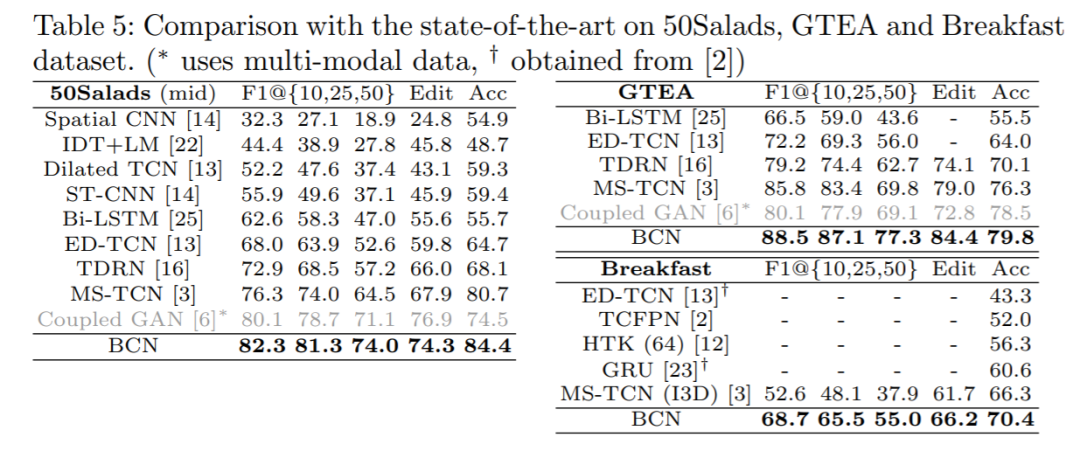
我们的结果在此前的SOTA作为很强的baseline的情况下,依然在GTEA(视频短,规模小),50Salads(视频非常长,规模中等),Breakfast(视频较短,规模大)三个数据集都获得了很大的提升。
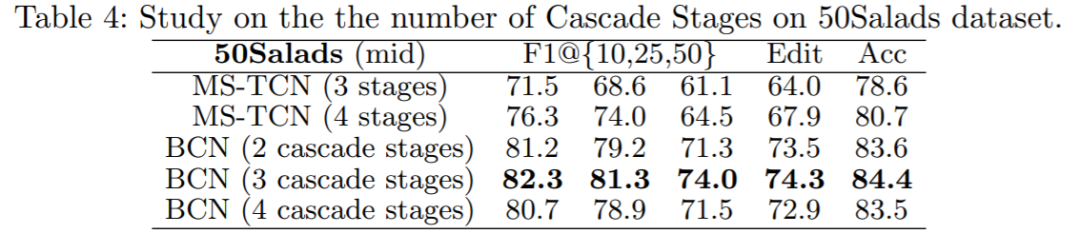
我们的ablation study有以下几个重点:(1)Stage Cascade本身可以提高分类精度(尤其是边界区域,见Fig.4);(2)LBP本身可以普遍提高所有指标,并且明显优于启发式平滑方法;(3)都具有LBP作为公平比较的情况下,Stage Cascade超越了每个stage单独预测权重的传统attention方法;(4)我们的模型即使在更少的stage的情况下也超过了baseline更多stage的最好结果。其他的ablation请参见paper和supplementary materials.
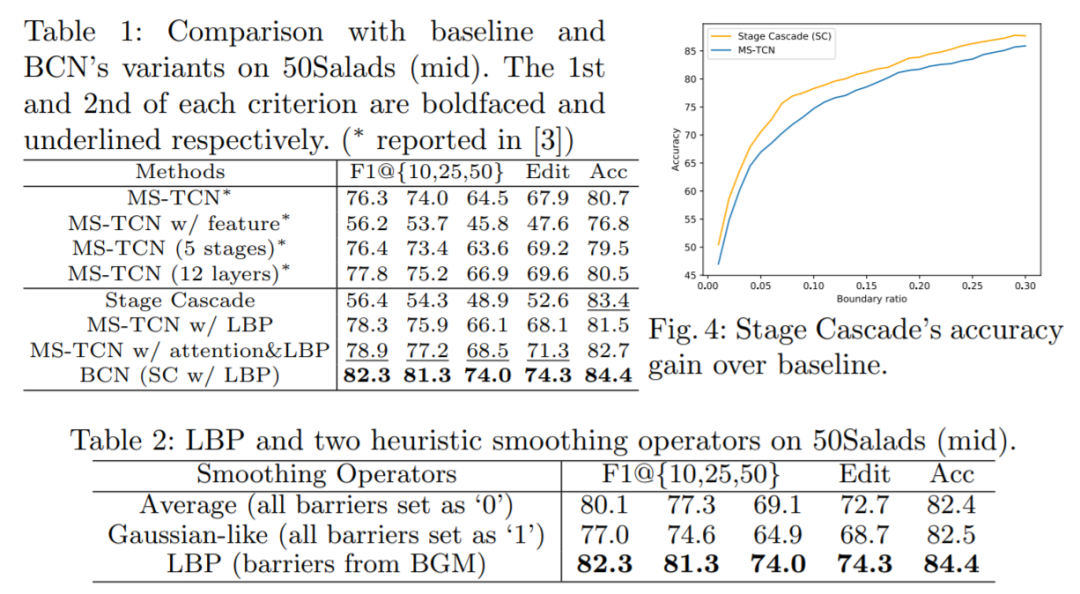
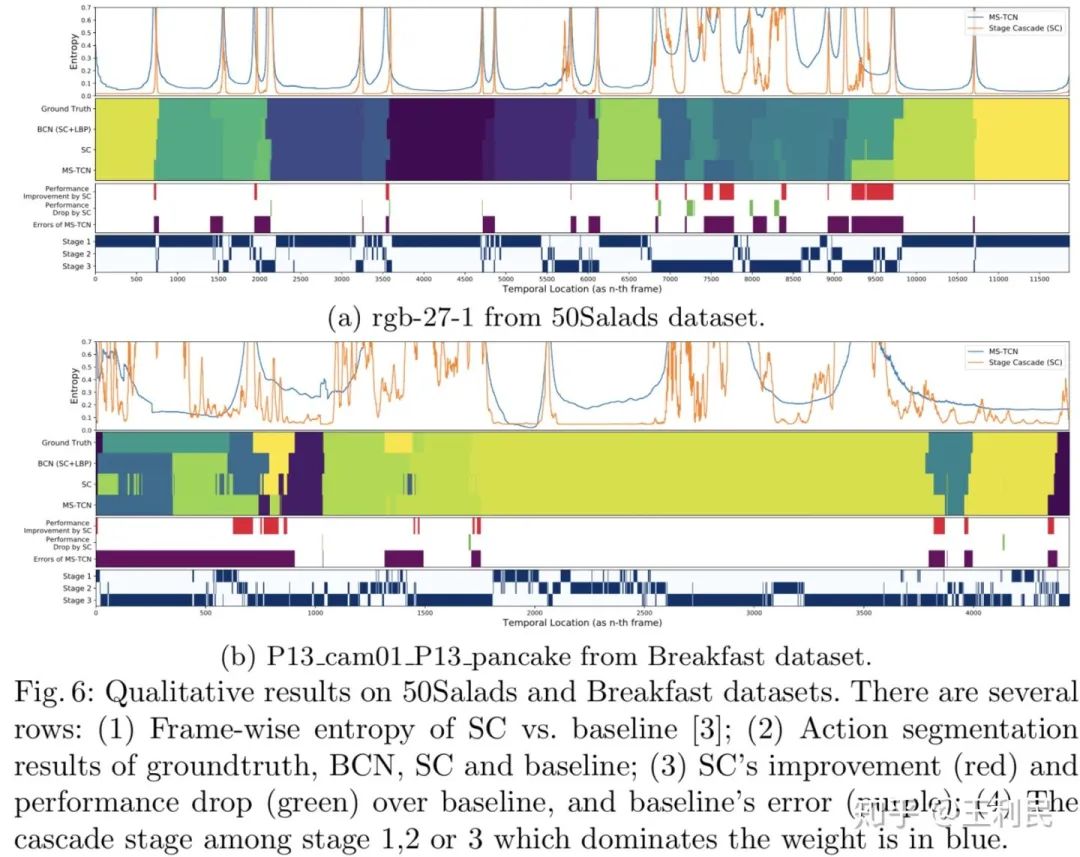
最后是可视化结果,值得关注的是我们的Stage Cascade在绝大部分区域的frame-wise entropy(通过这一帧的多分类置信度计算而得)都低于baseline,说明我们对于难样本的分类置信度是更好的。通过最后一行的stage assignment(有颜色的表示该stage权重最大)也能看出模型的最终表现是符合我们的分析与预期的。
参考
^此处的多阶段概念并非目标检测中的多阶段的意思,指的是多个可以输出分割结果的子网络,这种多个网络中间层输出分割结果的网络结构常见于语义分割和时序动作分割中。
^过分割问题即在单一动作的长区间内分类出一些错误的短区间或单帧预测结果,会极大影响最终指标。
下载
论文PDF已打包好,在CVer公众号后台回复:BCN,即可下载访问
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2300+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!

