不用恐惧AI的高速发展,论击败阿法狗(零)最简单的方法

作者:刘锋 计算机博士,互联网进化论作者
10月19日凌晨,在国际学术期刊《自然》(Nature)上发表的一篇研究论文中,谷歌下属公司Deepmind报告新版程序AlphaGo Zero:从空白状态学起,在无任何人类输入的条件下,它能够迅速自学围棋,并以100:0的战绩击败“前辈”。
团队称,AlphaGo Zero的水平已经超过之前所有版本的AlphaGo。在对阵曾赢下韩国棋手李世石那版AlphaGo时,AlphaGo Zero取得了100:0的压倒性战绩。DeepMind团队将关于AlphaGo Zero的相关研究以论文的形式,刊发在了10月18日的《自然》杂志上。
10月19日很多阿尔法狗的新闻。标题写着不依赖于人类的任何知识或者完全自通,但实际情况是阿法狗(零)在开始运行时,是需要程序员输入人类制定的围棋规则,阿法狗(零)依然依赖于人类设定的规则,而这其实是人类最为强大的知识。
阿法狗(零)的进展的确是人工智能领域伟大的进展,但这种伟大并不应该让人类自惭形秽,反而是衬托出人类的伟大。因为人类可以自主的进化,拥有发现规则,制定规则,使用规则,判断规则价值使之有利于种群的进化,这四点中,阿法狗(零)只做3中的一小部分,从宏观上说,AI离人类的距离,如同人类离“上帝”的距离一样
彻底战胜阿法狗(零)的方法有很多,最简单的方法是“把围棋的胜负规则定为谁占的空多,谁输,如果没有程序员帮助阿尔法狗调整,它会永远输下去,除非一次闪电导致的BUG,就像在机器猫故事里,让机器猫最早活过来的那种闪电”。
如同我们在论文"人工智能智商评测与智能等级“中探讨的那样:
关于AlphaGo是否具备创新创造性问题,我们认为它依然是依托人工支持的大数据训练形成的策略模型,同时在比赛中结合比赛对手的落点数据,根据其内部的运算规则,来不断形成自己的落点数据,这些落点数据最终形成比赛数据集合。AlphaGo根据围棋规则与对手的比赛数据集合进行计算和比较,判断输赢,整个过程完全在人类设定的规则下运行,无法体现其自身的创造性,如图4所示。
即使AlphaGo形成的落点数据集合很可能是人类历史上没有出现过的,也不能说明AlphaGo具备了独立的创新创造功能。例如,我们用计算机程序实现下述过程:从1万到100万的自然数中随机选取两个数进行相乘,记录相乘结果,重复此过程361次,即使得出的自然数集合很大,并且可能是人类历史上没有出现过的,我们也不能认定该计算机程序具有创新创造性。
如果AlphaGo在没有人类协助更改程序的情况下,能够自动理解比赛规则的任意变化,并主动更改内部设置,自动改变自己的训练模型,用于实战比赛,战胜对手,那么在这种情况下,我们才可能认为AlphaGo具备创新性。但从人工智能的发展过程看,AlphaGo还完全无法实现这一点。即使在很远的未来,也很难实现。正如一位专家的那样,更优秀的AlphaGo也是人类更优秀的一把刀。
如果说AlphaGo战胜了人类,倒不如是这个公式的成立:
程序员 + AlphaGo > 顶级围棋选手
以下两篇文章为阿尔法狗相关报道和技术分析
阿尔法狗再进化:自学3天,就100:0碾压李世石版旧狗
来源:澎湃新闻 责任编辑:王心馨
伦敦当地时间10月18日18:00(北京时间19日01:00),AlphaGo再次登上世界顶级科学杂志——《自然》。
一年多前,AlphaGo便是2016年1月28日当期的封面文章,Deepmind公司发表重磅论文,介绍了这个击败欧洲围棋冠军樊麾的人工智能程序。
今年5月,以3:0的比分赢下中国棋手柯洁后,AlphaGo宣布退役,但DeepMind公司并没有停下研究的脚步。伦敦当地时间10月18日,DeepMind团队公布了最强版AlphaGo ,代号AlphaGo Zero。它的独门秘籍,是“自学成才”。而且,是从一张白纸开始,零基础学习,在短短3天内,成为顶级高手。
团队称,AlphaGo Zero的水平已经超过之前所有版本的AlphaGo。在对阵曾赢下韩国棋手李世石那版AlphaGo时,AlphaGo Zero取得了100:0的压倒性战绩。
DeepMind团队将关于AlphaGo Zero的相关研究以论文的形式,刊发在了10月18日的《自然》杂志上。
“AlphaGo在两年内达到的成绩令人震惊。现在,AlphaGo Zero是我们最强版本,它提升了很多。Zero提高了计算效率,并且没有使用到任何人类围棋数据,”AlphaGo之父、DeepMind联合创始人兼CEO 戴密斯·哈萨比斯(Demis Hassabis)说,“最终,我们想要利用它的算法突破,去帮助解决各种紧迫的现实世界问题,如蛋白质折叠或设计新材料。如果我们通过AlphaGo,可以在这些问题上取得进展,那么它就有潜力推动人们理解生命,并以积极的方式影响我们的生活。”
不再受人类知识限制,只用4个TPU
AlphaGo此前的版本,结合了数百万人类围棋专家的棋谱,以及强化学习的监督学习进行了自我训练。
在战胜人类围棋职业高手之前,它经过了好几个月的训练,依靠的是多台机器和48个TPU(谷歌专为加速深层神经网络运算能力而研发的芯片)。
AlphaGo Zero的能力则在这个基础上有了质的提升。最大的区别是,它不再需要人类数据。也就是说,它一开始就没有接触过人类棋谱。研发团队只是让它自由随意地在棋盘上下棋,然后进行自我博弈。值得一提的是,AlphaGo Zero还非常“低碳”,只用到了一台机器和4个TPU,极大地节省了资源。
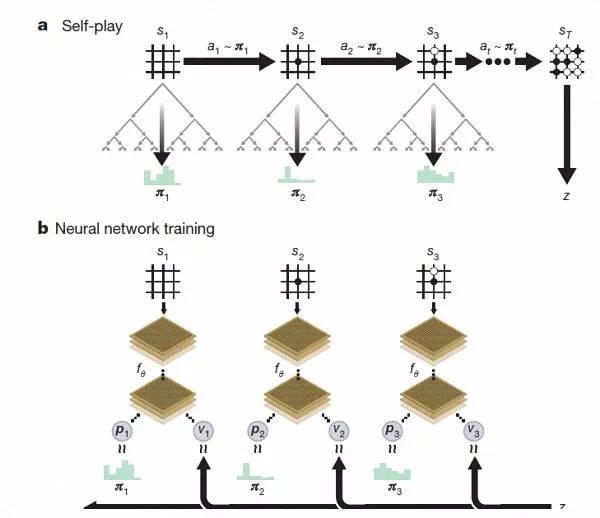
AlphaGo Zero强化学习下的自我对弈。
经过几天的训练,AlphaGo Zero完成了近5百万盘的自我博弈后,已经可以超越人类,并击败了此前所有版本的AlphaGo。DeepMind团队在官方博客上称,Zero用更新后的神经网络和搜索算法重组,随着训练地加深,系统的表现一点一点地在进步。自我博弈的成绩也越来越好,同时,神经网络也变得更准确。
AlphaGo Zero习得知识的过程
“这些技术细节强于此前版本的原因是,我们不再受到人类知识的限制,它可以向围棋领域里最高的选手——AlphaGo自身学习。” AlphaGo团队负责人大卫·席尔瓦(Dave Sliver)说。
据大卫·席尔瓦介绍,AlphaGo Zero使用新的强化学习方法,让自己变成了老师。系统一开始甚至并不知道什么是围棋,只是从单一神经网络开始,通过神经网络强大的搜索算法,进行了自我对弈。
随着自我博弈的增加,神经网络逐渐调整,提升预测下一步的能力,最终赢得比赛。更为厉害的是,随着训练的深入,DeepMind团队发现,AlphaGo Zero还独立发现了游戏规则,并走出了新策略,为围棋这项古老游戏带来了新的见解。
除了上述的区别之外,AlphaGo Zero还在3个方面与此前版本有明显差别。
AlphaGo-Zero的训练时间轴
首先,AlphaGo Zero仅用棋盘上的黑白子作为输入,而前代则包括了小部分人工设计的特征输入。
其次,AlphaGo Zero仅用了单一的神经网络。在此前的版本中,AlphaGo用到了“策略网络”来选择下一步棋的走法,以及使用“价值网络”来预测每一步棋后的赢家。而在新的版本中,这两个神经网络合二为一,从而让它能得到更高效的训练和评估。
第三,AlphaGo Zero并不使用快速、随机的走子方法。在此前的版本中,AlphaGo用的是快速走子方法,来预测哪个玩家会从当前的局面中赢得比赛。相反,新版本依靠地是其高质量的神经网络来评估下棋的局势。
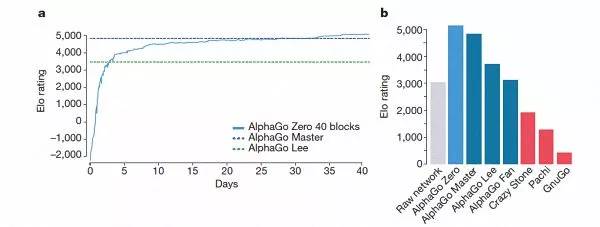
AlphaGo几个版本的排名情况。
据哈萨比斯和席尔瓦介绍,以上这些不同帮助新版AlphaGo在系统上有了提升,而算法的改变让系统变得更强更有效。
经过短短3天的自我训练,AlphaGo Zero就强势打败了此前战胜李世石的旧版AlphaGo,战绩是100:0的。经过40天的自我训练,AlphaGo Zero又打败了AlphaGo Master版本。“Master”曾击败过世界顶尖的围棋选手,甚至包括世界排名第一的柯洁。
对于希望利用人工智能推动人类社会进步为使命的DeepMind来说,围棋并不是AlphaGo的终极奥义,他们的目标始终是要利用AlphaGo打造通用的、探索宇宙的终极工具。AlphaGo Zero的提升,让DeepMind看到了利用人工智能技术改变人类命运的突破。他们目前正积极与英国医疗机构和电力能源部门合作,提高看病效率和能源效率。
AlphaGo Zero 没有告诉你的秘密

作者:屏芯科技CTO陈利人
AlphaGo 确实很厉害,尤其是最新发表的 AlphaGo Zero,完全不用人类棋手的棋谱,从零开始学起,大概学习21天就能完胜柯洁,学习40天就能完胜之前的任何AlphaGo版本。
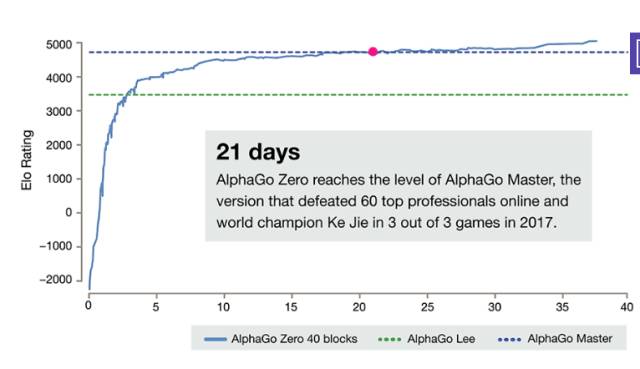
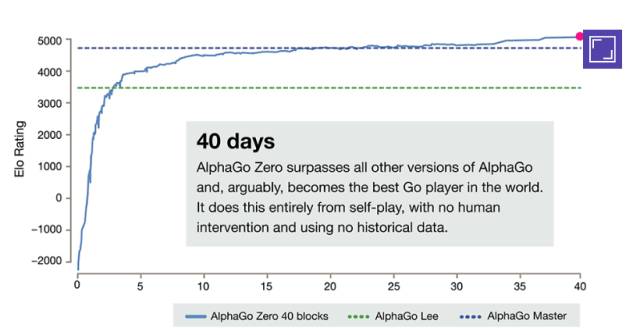
AlphaGo Zero除了使用围棋规则,完全摈弃了人类棋手的知识和棋谱,利用强化学习和深度学习模型,左右手互搏的自学习,获得功力。它高强度的使用了搜索(模拟),蒙特卡罗树搜索(MCTS),但它没有告诉你,这个树搜索实际上是在产生标注数据。
为什么?
因为围棋下到一定程度,最极端的情况是,大家都无子可下的时候,是能通过规则计算胜负的,也就是说,模拟(搜索)到一定程度,就能产生一个输或赢的棋局数据。正是由于这一点,围棋是能够在没有人类棋手的知识(用来减少搜索空间和加速搜索进程)的情况下,使用非监督学习来学习的。机器的计算速度很快,能够在极短的时间内模拟大量的有胜负的棋局,并且从中学习。
很多的游戏也具有类似的能够模拟(搜索)产生最后能用规则判别胜负的样本,所以它们无需人类的知识,确实能从零学习。
但是,像语音识别,图像识别,自然语音理解,等等,领域,就缺乏用简单规则就能判别的样本,它们需要大量的人工标注,然后才能监督或是半监督学习。
就像给你一段不知地球上哪个角落的一句方言说的语音,鬼知道讲的是什么,除了有很多之前专家标注的样本。或是给你一块甲骨文,你能知道写的是什么吗,如果没有很多专家考证研究了多年的结果。
有人可能会质疑,机器翻译,自动问答,不是可以吗?别忘了,这些系统是充分利用了人类有史以来积累的大量的人类翻译的双语语料,或是人类的问答句对。没有它们,这是不可能的任务。
明白了这个可用简单规则判别结果的先决条件,知道AlphaGo Zero 确实算法和工程很牛逼,但是不要被误导了,任何东西(人工智能)都可以无需人类知识或是领域数据就可以从零学习的。然后就觉得人工智能是万能的。
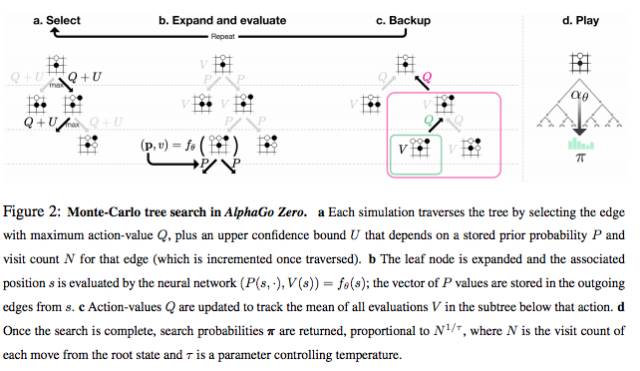
从AlphaGo Zero的论文中,描述的Self-Play和Neural Network Training,我们看到最终状态St是需要根据围棋规则来计算胜者z的,实际上,用模拟(搜索)产生了一个(或是几个)训练样本(棋局)。
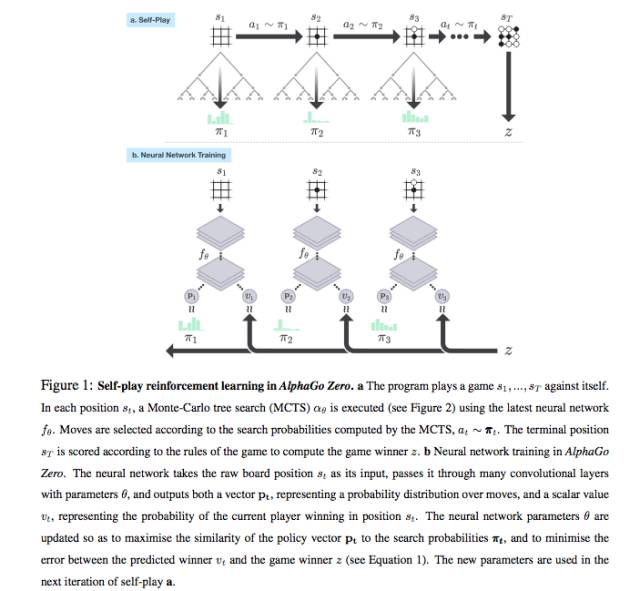
AlphaGo Zero中的模特卡罗树搜索(MTCS)。