我用一下午时间标注了十万张没有标签的图片,为老板节约了3W美金
想象一下你的老板给了你 10 万张无标签的图片,并要求你将它们分类为凉鞋、裤子、靴子等等。

现在你有一大堆没有标签的数据,你需要为这些数据打上标签。你该怎么办呢?
这个问题是司空见惯的。许多公司都在数据的大海里遨游,不论是交易数据、物联网传感器产生的海量数据、安全日志,还是图像、语音数据等等,这些都是未标注的数据。
用这么少的标注数据,对于所有企业中的数据科学家来说,建立机器学习模型都是一个单调乏味的过程。
以 Google 的街景数据为例,Gebru 不得不弄清楚如何用很少的带有标签的数据为五千万张图片贴上汽车标签。
在 Facebook,工程师们使用算法来标注 50 万个视频,这个任务使用其他的方法需要花费 16 年的时间。
这篇文章将向您展示如何用一个下午的时间标注数十万张图片。无论是标注图像还是标注传统表格数据(例如,识别网络安全攻击或可能的部件故障),都可以使用同样的方法。
手工标注的方法
对大多数数据科学家来说,如果他们被要求去做某件事,他们首先会想一想有没有其他可以替代的人去做这件事。

但是 10 万张图片可能会让您在 Mechanical Turk 或类似的其他竞争平台上花费至少 30,000 美元。
你的老板期望以较低的代价来做这件事,因为毕竟,他们聘请了你。现在,除了你的工资以外,她没有其他任何的预算(如果你不相信我,请去 pydata)。
你深吸了一口气,想了一下你可以在一个小时内标完 200 张图片。所以这意味着在三个星期内不停地工作,你就可以标完所有的数据!哎呀!
建立一个简单的模型
第一个想法是标记一部分图片,用它们训练一个机器学习模型,然后用来预测剩下的图片的标签。
对于这个练习,我使用的是 Fashion-MNIST 数据集(你也可以用 quickdraw 来制作自己的数据集)。
有十个类别的图像要我们去做识别,下面是它们的样子:

看到这个数据集我很高兴,因为每幅图片都是由 28×28 像素组成的,这意味着它包含 784 个独特的特征/变量。
对于我要写一篇博客文章来说,这些特征很好,但是在现实世界中你是绝对看不到这样的数据集的,它们往往要么窄得多(传统的表格业务问题数据集),要么宽得多(真实图像要大得多,而且由不同的颜色组成)。
我使用最常见的数据科学算法来建立模型,包括:逻辑回归,支持向量机(SVM),随机森林和 Gradient Boosted Machines(GBM) 。
我根据它们在 100、200、500、1000 和 2000 张图片上的标注效果来评测它们的性能。
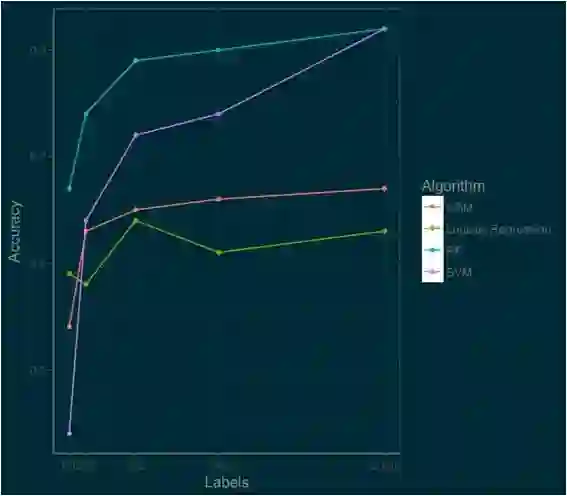
如果你看到这个地方了,那么你应该放慢速度,仔细研究一下这张图。这张图里有很多好东西。
哪个算法最好呢?(如果你是一个数据科学家,你不应该为这个问题而困惑。)问题的答案其实取决于需求环境。
如果你想要快速可靠地开箱即用,你可以选择逻辑回归算法。随机森林算法从开始时就一直遥遥领先,SVM 虽然起点较低,但以极快的速度追赶上来。随着我们的标注数据越来越多,SVM 的性能将超过随机森林。
GBM 工作的很好,但要达到最好的性能还需要做一些额外的工作。这里每种算法的分数都是使用了 R 中已经实现好的库评测出的(e1071,randomForest,gbm,nnet)。
如果我们的 benchmark 是对十个类别的图像分类任务达到 80% 的准确率,那么我们可以通过建立一个包含 1000 个图像的随机森林模型来达到目标。
但是 1000 张图像的标注工作量依旧是很大的,我估计需要 5 个小时。所以让我们想想还有什么可以改进的方法。
Let’s Think About Data
经过短暂思考后,你想起来你经常告诉别人的一句话:数据不是随机的,而是有模式的(The data isn’t random,but has patterns)。利用好这些模式,我们可以更深入地理解我们的数据。
让我们从一个自动编码器(autoencoder,AE)开始。自动编码器是用来压缩你的数据的,就像把汤变成 一个肉汤块一样。自动编码器使用了很时髦的主成分分析(PCA),它们支持非线性变换。
实际上,这意味着我们正在将我们的宽广的数据(784 个特征/变量)减少到 128 个特征。然后我们利用新的压缩后的数据来训练我们的机器学习算法(此例中我们使用 SVM)。
下面的图表显示了用自动编码器(AE_SVM)压缩的数据训练的 SVM 与使用原始数据训练的 SVM 之间的性能差异。

通过将信息压缩到 128 个特征,我们实际上能够改善底端 SVM 算法的性能。
在 100 个标签上,准确率从 44% 上升到 59%;在 1000 个标签上,自动编码器仍然可以起作用,我们看到准确率从 74% 提高到 78%。
所以我们离目标更近了一步,我们只需要更进一步地思考可以利用的数据的分布和模式。
Thinking Deeper About Your Data
我们的数据是图像,而我们知道,自 2012 年以来,图像处理的利器是卷积神经网络(CNN)。
使用 CNN 有好几种方法,可以从一个预训练的网络或简单的模型来预处理图像。
这篇文章中,我参照 Kingma 等人的一篇论文,使用卷积变分自动编码器(Convolutional Variational Autoencoder)来实现目标。
因此,我们来建立一个卷积变分自动编码器(CVAE)。这里的技术相比之前有两层“飞跃”。
首先,“变分”(variational)是指自动编码器将信息压缩成概率分布。其次是增加了卷积神经网络作为编码器。
这里使用了一点深度学习的技术,但我要强调的是我们的重点不是为了卖弄最新的最潮的技术,而是如何恰当地去解决问题。
为了编码我的 CVAE,我使用了 examples over at RStudio’s Keras Page 这个列表中的示例 CVAE。
像之前的自动编码器一样,我们设计了潜在的空间来将数据减少到 128 个特征。然后,我们使用这些新的数据来训练 SVM 模型。
以下是 CVAE_SVM 与在原始数据上训练的 SVM 和 Random Forest 的性能比较图。
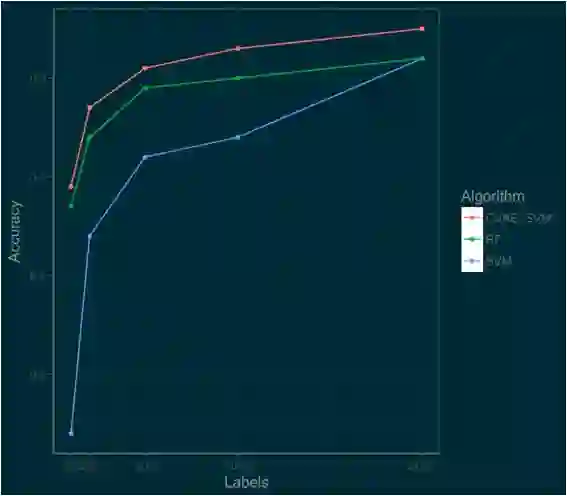
哇!新模型更加准确。只用 500 个标签,我们就可以达到 80% 以上的准确率。
通过使用这些技术,我们获得了更好的性能,并且只需要更少的标注图像。在高端,这种方法也可以比 Random Forest 或 SVM 模型做得更好。
Next Steps
通过对自动编码器使用一些非常简单的半监督技术,就可以快速准确地标注数据。但是重点并不是使用深度学习编码器!
相反,我希望你理解了这里的方法后,从很简单的方法开始尝试,然后逐渐尝试更复杂的解决方案。
不要沉迷于使用那些最新的技术—实际的数据科学并不是使用 arXiv 中的最新方法。
这种半监督学习的方法一定可以给你带来启发。这篇文章相当于半监督学习中的逻辑回归算法。
如果你想进一步深入半监督学习和领域适应性(Domain Adaptation)相关的内容,请参考 BrianKeng 的 great walkthrough of using variational autoencoders。
他的工作超出了我们在这里所说的,或者 Curious AI 的工作 ,他们的工作使用深度学习来改进半监督学习,并且开放了代码。
最后,我希望你至少要明白的一点是,不要认为你所有的数据都要贴上标签。
作者:Rajiv Shah,张盛强翻译
简介:Rajiv Shah 是 DataRobot 的数据科学家、Caterpillar 和 StateFarm 的数据科学团队的一员。他喜欢数据科学,并且愿意花时间指导数据科学家,喜欢对事件发表看法,并且以写博客文章为乐趣。他拥有伊利诺伊大学香槟分校的博士学位。
编辑:陶家龙、孙淑娟
投稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com

精彩文章推荐:




