如何推理一个物体的 Affordance 是机器人相关研究的一个重点关注方向。在具体的 Affordance 中,抓取(grasping)又是格外重要的一个功能。
作为最早提出 Affordance 这一概念的学者,James Gibson 在他的书 [1] 中正式定义了 Affordance:
Affordance 是环境所允许个人能实现的功能(Affordance is what the environment offers the individual)。
不过 Affordance 所最为人知的定义应该是在他几年后出版的书 [2] 中的定义:
Afford 是在字典中存在的一个词,但 Affordance 不是。Affordance 是我个人创造出来的一个词。Affordance 指代环境为动物 / 人类提供的一种功能。我想用这个词来表达环境和动物 / 人类的互补性。
在中文语境下,Affordance 可以大致理解为物体 / 环境的直观功能。虽然语意上比较难以理解,Affordance 却是每个人在日常生活中下意识便会应用的技能。举例来说,当人类看到一个马克杯的时候,他 / 她立刻就能够理解杯子是可以用来盛物体的——不论是咖啡等液体还是固体——并且马克的杯柄可以被抓握。除此之外,假如人类看到茶杯、玻璃杯、酒杯等任何非马克杯的物体,也不会因此而无法推断该物体是否还能够盛物体。人类几乎天然就理解小型物体上的柄可以被抓握和应该从那个角度抓握。人类也可以轻易理解门上的把手是用来推或拉的,挂钩上的钩子是用来挂东西的、家用电器上的按钮是用来按(或者扭)的。设计师在设计产品时也必须将物体的 Affordance (直观功能)和如何引导用户理解物体的 Affordance 纳入考虑中。不信?请移步设计师 Katerina Kamprani 精心设计的「不舒服」的产品一览究竟。
![]()
设计师 Katerina Kamprani 设计的一系列让人感觉「不舒服」的产品,其实就是违反了一个物件应该有的 Affordance(
图源:https://www.theuncomfortable.com)
虽然 Affordance 是人类与生俱来的技能点,机器人却没有这样的「运气」。由于机器人本质上只是在运行人类开发的软件而不能进行真正的推理——至少目前还是这样——机器人对 Affordance 的理解取决于人类在这一领域的研究进展。实际上,机器人领域的研究已经证明了 Affordance 远远不止是只存在于书本中的心理学概念。具体来说,物体的抓取和操纵中,机器人需要通过视觉线索和经验中学习周围环境中物体的 Affordance,包括是否可以操纵物体、如何抓握物体以及学习操作对象以达到特定目标。
不难看出,如何推理一个物体的 Affordance 是相关研究的一个重点关注方向。在具体的 Affordance 中,抓取(grasping)又是格外重要的一个功能。这两点将是本文的讨论重点。
推理(reasoning)Affordance 很好理解,即推断一个物体的 Affordance —— 不论是通过视觉上的线索,还是通过过去的经验知识。机器人需要理解有柄的物体可以抓握,带有凹陷的物体可以盛物品。
推理物体的 Affordance 可以简单分为推理单一物体的 Affordance 和推理多个物体的 Affordance。由于多个物体间可能存在互动 (interaction),Affordance 的推理很容易就会变得非常复杂。本文将集中于单一物体的 Affordance 推理。
![]()
两个物体之间可能有互动(interaction),从而改变了物体的 Affordance。(
图源:https://www.theuncomfortable.com)
具体来说,学习推理单一物体 Affordance 的方法可以分为三类:通过模拟(simulation)、通过视觉特征(visual features)、和通过构建知识图谱(knowledge graph)。
在 [3] 中,Hongtao Wu 和 Gregory S. Chirikjian 利用模拟物体落入容器中的物理过程来对开放式容器——即无盖的容器,杯子、碗、碟等——的容纳性 (containability affordance)进行推理。还是用水杯举例,当机器人面对一个水杯时,需要模拟从水杯上方倾倒物体的结果——物体是会落到桌面上还是会落到水杯内?假如机器人面对的是一个没有杯底的水杯,结果是什么?
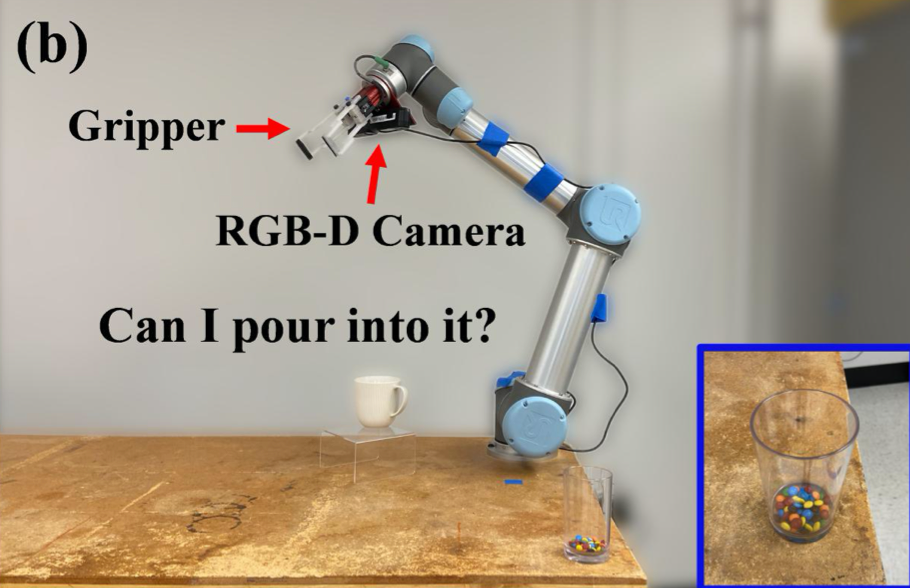
整个实验中,作者使用了一个具有抓握功能的机器手,并在其上安装了 RGB-D 摄像机来对推理对象进行扫描。在 RGB-D 摄像机下有一个透明的平台,被推理的物体将会被放置在其上。具体设置如下图所示。
![]()
实验设计(图源:H. Wu, G. S. Chirikjian. (2020). Can I Pour into It? Robot Imagining Open Containability Affordance of Previously Unseen Objects via Physical Simulations. arXiv:2008.02321.)
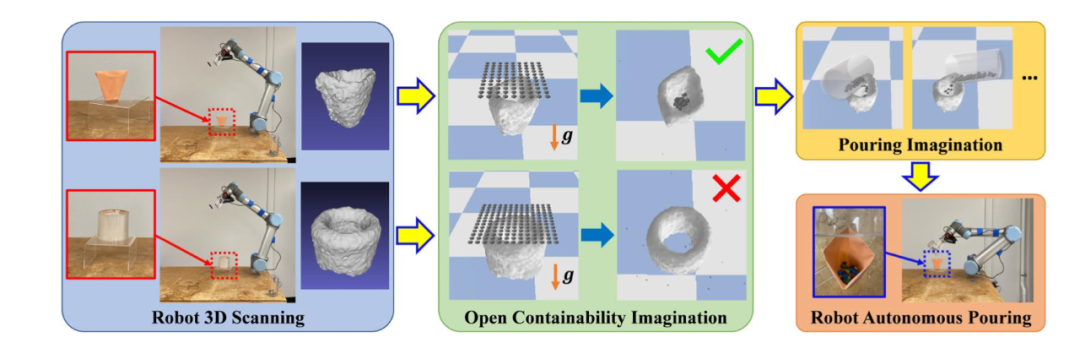
实验过程中,不同的物体会被随机放置在透明平台上,机器手会依次移动到 24 个预先设定好的位置上,利用腕上安装的 RGB-D 摄像机捕获场景的深度图像。接下来作者使用 TSDF Fusion [12] 密集地重建场景。由于平台是透明的,相机的深度传感器不会捕捉到该平台,被建模物体的 3D 重建会比较简单 —— 只要在重建的场景中剪切(crop)即可。生成的 3D 模型会被用于接下来的模拟中,如下图中间所示,算法需要模拟类似于 M&M 豆大小的灰色的小颗粒物体向被推理对象掉落的物理过程,并计算究竟有多少颗粒会进入到该物体内并被容纳以量化一个物体的容纳性,即判断一个物体是否是开放式容器。若模拟结果显示被推理物体内不保有任何颗粒,则该物体不是开放式容器。在下图例子中,算法对纸杯和一卷胶带分别进行了模拟,结果显示只有纸杯是开放式物体。若一个物体被判断为开放式容器,机器手还会再次进行模拟,以推断自己应该倒入的位置和方向,然后将之付诸于行动。
![]()
机器手对纸杯和胶带的容纳性进行推理。(
图源:H. Wu, G. S. Chirikjian. (2020). Can I Pour into It? Robot Imagining Open Containability Affordance of Previously Unseen Objects via Physical Simulations. arXiv:2008.02321.)
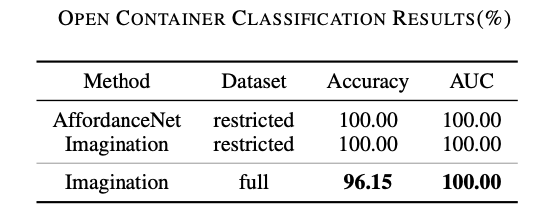
作者利用 11 个物体对整个模拟算法(以 Imagination 代指)进行了校准,然后将其与利用深度学习对 RGB 图像进行学习的 AffordanceNet [11] 进行了比较。测试集包含 51 个物体——23 个开放式容器和 28 个非开放式容器,测试表现用 accuracy 和 AUC (area under curve)进行衡量。下表中可以看出 AffordanceNet 和 作者所提出的模拟方法都在测试集上取得了非常好的表现。Imagination 的准确度稍差,主要是因为对被推理物体的 3D 建模不够准确,从而导致生成的 3D 模型上出现了轻微凹陷,而凹陷部位可以容纳小颗粒物体从而导致了物体被误判为开放式容器。另一些失败的情况则比较模棱两可,如汤匙,这种争议在人类标注者上也存在。另一方面,由于使用了 RGB-D 相机,Imagination 算法可以利用深度信息,这对推理和执行倾倒这个动作是有优势的。作者在之后进行的一些实验也证明了这一点。
![]()
利用模拟来对物体的 Affordance 进行学习的优势主要在于可解释度高、对未知物体的鲁棒性好,难点则在于嵌入式开发中的硬件设施、计算能力、模拟算法的准确性等。比如本文的实验中 (1)被推理物体需要一直处于深度传感器的测量范围内;(2)只能对物体的顶部和侧面进行建模,因为无法机器手无法从被推理物体的下方进行扫描;(3)模拟算法模拟的是离散的刚性颗粒,其他物体——比如水——则具有完全不同的物理特性;(4)Affordance 的推理局限于物体的容纳性,如果想要将该研究延伸到新的 Affordance 如物体的抓握性,则需要完全的不同的模拟算法。
由于人类主要通过视觉线索对物体的 Affordance 进行推理,利用 RGB 照片建模的研究并不少见,比如前文提到的 AffordanceNet。随着深度学习的流行,不少研究会训练卷积神经网络(CNN)来取代传统的特征工程。[4] 就是典型的一例。这篇研究有意思的地方在于作者特意选择了专家演示的视频组成数据集,利用人类理解物体 Affordance 的线索训练模型。如果 [4] 也使用的视频中也有水杯,那么 CNN 就需要对专家演示中将茶水倾倒到水杯中和抓握杯柄将水杯端起来的片段理解水杯的容纳功能和抓握功能。
专家演示的视频来自互联网上充斥着的大量的产品评论视频 (product review videos),其中很多视频中会有一名「专家」——比如产品评论者——通过对产品对象的一系列操作来详细演示产品功能。除了为消费者们拔草种草外,这些视频还为作者提供了新思路——用这些视频组成能够为机器人提供有关 affordance 以及人们如何与产品交互的大规模、高质量数据。
![]()
产品评论视频中往往有一名「专家」在对产品进行演示(图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
这种方法虽然从逻辑上看非常可行,但却面临两个挑战:第一,这些视频中的产品和机器人要面对的产品在外观上可能有非常大的差异,如何保证机器人学到的 affordance 对产品外观是稳健的;第二,在视频中「专家」和产品的交互并不频繁,比如在上图例子中几乎只有第三帧中「专家」有对产品进行操作,还是在有大量的背景信息下进行的,机器人需要在其中辨别并学习真正有用的信息。
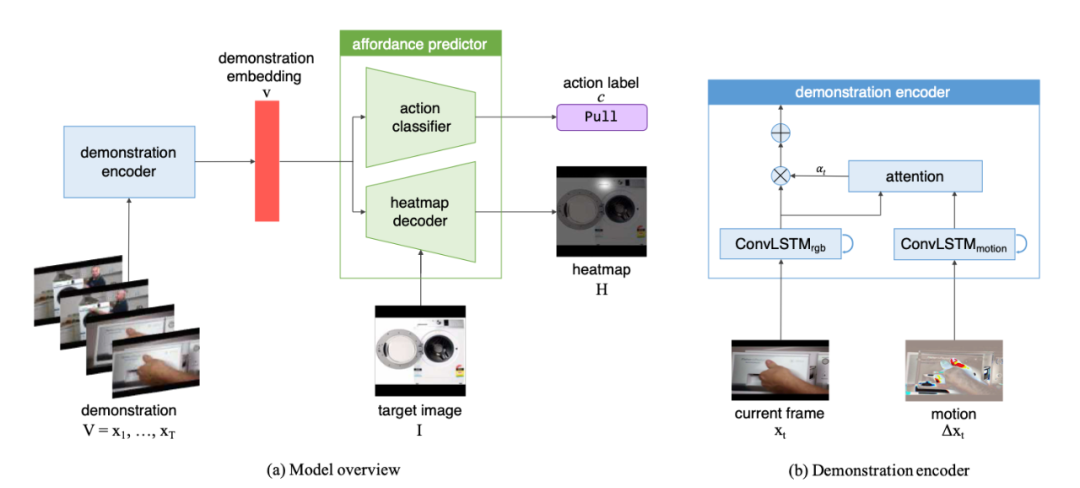
作者提出的解决办法是将模型(Demo2Vec)分解为演示编码器(Demonstration encoder)和 affordance 预测器(affordance prediction),演示编码器负责将演示视频通过「演示嵌入」(demonstration embedding) 总结为了人类动作和被推理物体外观的低维向量,这里的需要解决的问题主要是如何提取关于人与物体交互的有用视觉提示,如前文提到的,这种交互在视频中比较稀疏 (「sparse」), 且存在许多其他无关物体。作者提出用卷积 LSTM 网络(ConvLSTM)和 soft-attention 来组成演示编码器。卷积 LSTM 网络使用两组信息作为输入,一组是视频帧,即正常的 RGB 图像,另一组则是当前的视频帧和前一帧的差值(∆x_t = x_t -x_{t-1})用以捕捉两帧之间的动态变化, 从而捕捉手部动作的变化讯息。
接下来,卷积 LSTM 网络的两组输出(RGB 特征和动态特征)将会被输入到 soft attention 模块中,最终得到的注意力权重会与 RGB 特征相乘,并对所有帧求和,从而生成 demonstration embedding。利用 demonstration embedding,affordance 预测器 (predictor)将知识转移到目标图像上预测被推理物体的交互区域和动作标签。
![]()
(a)模型概述。Demo2Vec 模型由一个演示编码器和一个 affordance 预测器组成。(b)演示编码器。演示编码器将输入的演示视频嵌入到低维向量,输入图像包括 RGB 图像和 运动图像 (motion modality),然后用 soft attention 将两部分信息融合起来。affordance 预测器然后利用嵌入向量来预测目标图像中展示的物体的 affordance 和热力图(heat map)。(图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
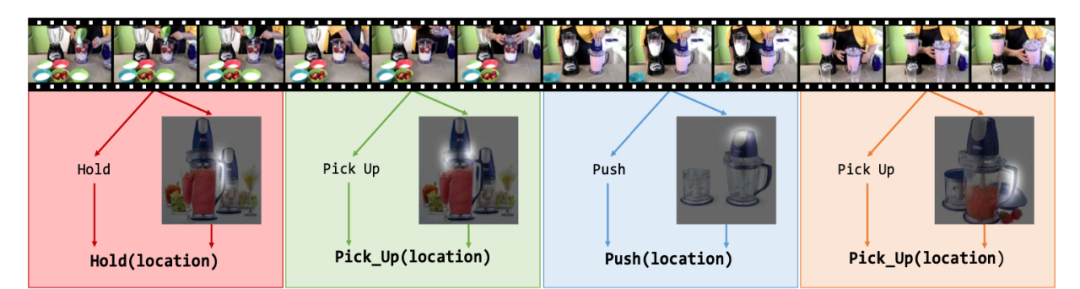
训练后的模型在面对同一个演示视频的不同时段,根据演示者的不同操作会对同一个物体推理出不同的 affordance。在下图给出的例子中,演示者在制作奶昔,并依次涉及到了四个 affordance:拿住(hold)、拿起(pick up)、推(push)、拿起(pick up)。该视频被分为 4 个短片(由不同颜色表示),模型能够正确的根据演示理解 affordance 并且识别每个 affordance 对应的部位。这和人类的表现更相似,能够让机器人更自然一些。
![]()
不同的演示可以令模型对同一物体推理出不同的 affordance(图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
但是,不可避免地,当演示视频中出现许多杂物或其他和被推理物体十分相似的物体时,模型很容易受到误导。如下图所示,演示人站在摄像机前占据了大部分画面,并且遮挡了被推理物体,此时模型错误的将物体的 Affordance 预测为 Hold(如图中红色方框所示), 而实际上应该是 Rotate(如图中绿色方框所示)。
![]()
当演示人遮挡了被推理物体时推理结果会出错(图源:K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018) Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.)
此外,每次对物体的 affordance 进行判断时,演示视频是必不可少的。而人类只需要对演示视频观看几次就能够直接对未知物体进行推理。从这一点看利用模拟(simulation)的 [3] 的泛化能力要更好一点。但利用视觉线索仍然是最接近人类推理 Affordance 的方法之一。算力方面,根据模型的不同——比如 [5] 直接用 RGB-D 图像 3D 建模——有可能对计算能力有很高的要求。
通过构建知识图谱(knowledge graph)
可以看出,利用视觉信息 + CNN 的方法主要是试图模拟人类学习 Affordance 的过程,但是由于 CNN 是黑箱模型,训练出来的模型可解释性差。除此之外,绝大多数训练好的 CNN 本质上仍是一个分类器,因而其能够推理的 Affordance 也局限于训练数据所包含的 Affordance。使用构建知识库的方法则不一样,由于物品的各项特征都被单独标记了出来用于最后的推理,模型在可解释性方面更有优势,使用基于知识的表示形式便于对学习范围进行扩展。如果利用知识图谱对水杯的 Affordance 进行学习,得到的规则可能是「有柄的物体可以被抓握,有开口并且有底的物体可以容纳」。
[6] 利用图像和其他元数据源中获取物品的各种信息,然后使用马尔可夫逻辑网络(MLN)学习知识图谱。在对未知物品进行推理时只依赖于已习得的知识库而无需训练单独的分类器,包括 zero-shot affordance prediction。
作者通过从图像以及诸如 Amazon 和 eBay 之类的在线文本源中提取信息来抽取物品的属性和 Affordance, 然后从中学习知识图谱。每一个物品都有三类属性:视觉属性(Visual attributes)、物理属性(Physical attributes)和分类属性(Categorical attributes)。视觉属性对应于从视觉感知中获得的信息,包括物品的形状和材质等;物理属性包括物体的重量和大小;分类属性则反映物体所属于的更抽象的类别,比如动物、机器、器械、电器等等。
相应地,每个物品也有三类标签:Affordance 标签、人体姿势(Human poses)和人与物品的相对位置(Human-object relative locations)。后两者分别用于描述人体的姿势和人与物品交互过程中人与物体之间的空间关系。
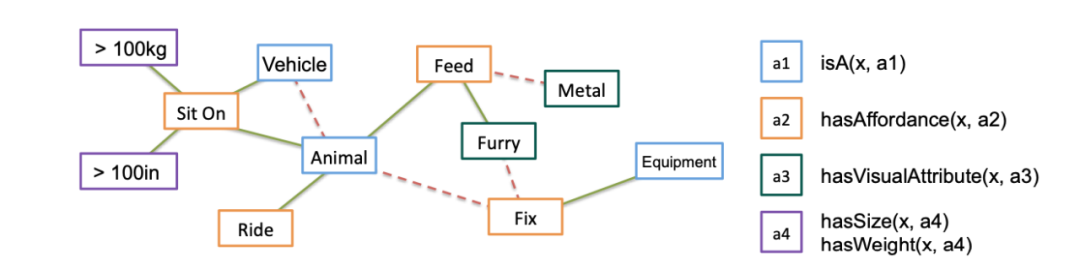
在数据收集好之后,就可以利用马尔可夫逻辑网络(MLN)从中学习关系即通用规则的权重来构建知识图谱。下图可视化了作者所构建的知识图谱的一部分。在下图中,每个节点包含了某一类属性或标签,连接两个节点的线段则代表两个节点之间的逻辑公式——比如既是 vehicle 又是 animal,MLN 需要学习相应的权重,其中正权重表示两者可能同时出现,由绿色实线表示,负权重表示两者是负相关的,由红色虚线表示。在本例中 vehicle 和 animal 是由红色虚线连接的,即两者不大可能出现在同一物体上。
![]()
构造的 KB 的图形化显示。 (图源:Zhu, Y., Fathi, A., & Fei-Fei, L. (2014). Reasoning about Object Affordances in a Knowledge Base Representation. ECCV.)
在执行推理时,模型首先根据提供的图像抽取物体的视觉属性,然后推测其物理和分类属性。利用这些属性模型可以在习得的知识图谱中对物体的 Affordance 进行查询。下图给出了 zero-shot affordance prediction 的例子。
![]()
zero shot affordance prediction 的推理过程。给定一个未知对象的图像,模型通过 hierarchical model 估算对象属性。这些属性可作为知识图谱查询的线索,从而对 Affordance 进行预测,并估计人体姿势和人体的相对位置。(图源:Zhu, Y., Fathi, A., & Fei-Fei, L. (2014). Reasoning about Object Affordances in a Knowledge Base Representation. ECCV.)
由于推理是运用多个线索综合完成的,模型的稳健性较好,不容易出现缺少某一个属性的信息就推理失败的情况。灵活性也好,可以比较容易的对模型进行扩展。不便之处则在于模型的质量很大程度上依靠于知识图谱的质量,而后者又依靠于数据集的质量。如果数据集中有很强的偏置(bias),比如红色的物体刚好都可以被抓握,所生成的模型表现也会受到影响。
当然,许多研究会将上述的方法混合起来,比如 [9] 和 [10] 就使用了 CNN 抽取特征用于构建知识图谱。
抓握(grasping)是人类生活最常用到的动作之一,而机器人的任务就是根据已经学习过的物体推断未知物体的 grasping affordance,即一个物体是否能被抓握。抓握和推理任务在一定程度上有重合。在机器人领域内,有很多研究会将推断物体是否能被抓握和识别物体具体能够被抓握的位置放在一个学习任务中。另一方面,抓握也可以分为学习 simple-task affordance 和 task-specific affordance。本文的重点会更偏向于推理未知物体能否被抓握,借用 zero-shot learning 的概念——在上文中的知识图谱中也有简要提到——这一领域也被叫做 zero-shot (grasp) affordance。这也算是推理抓握功能的难点之一,其他难点还包括实时推理、数据收集等。
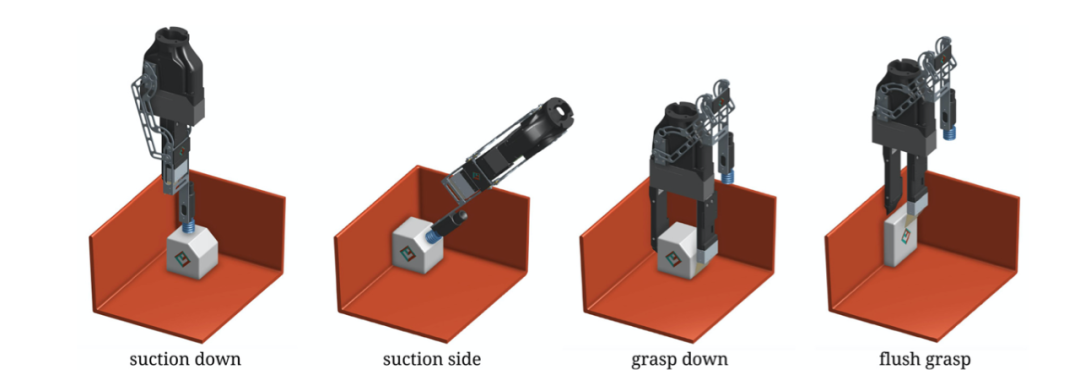
早期的一些研究会利用本地特征抽取器(local feature extractors )来学习一个物体是否能被抓握,如 [7]。虽然随着深度学习的流行手工设计的特征已经不再吃香,这篇文章还是在一定程度上解决了如何面对未知物体的问题:只寻找物体上是否有具有已知能够抓握的部位。[8] 则使用了神经网络来判断一个物体可能的 Affordance,包括正面吸取(suction down)、侧面吸取(suction side)、抓握(grasp down)和齐平抓握(flush grasp)。四种 Affordance 如下图所示,抓握和齐平抓握的区别主要是后者具有在目标对象和墙壁之间滑动一根手指的附加行为。
![]()
神经网络需要学习的四种 Affordance(图源:Zeng, A., Song, S., Yu, K.-T., Donlon, E., Hogan, F. R., Bauza, M., Ma, D., Taylor, O., Liu, M., Romo, E., Fazeli, N., Alet, F., Chavan Dafle, N., Holladay, R., Morona, I., Nair, P. Q., Green, D., Taylor, I., Liu, W., … Rodriguez, A. (2019). Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. The International Journal of Robotics Research.)
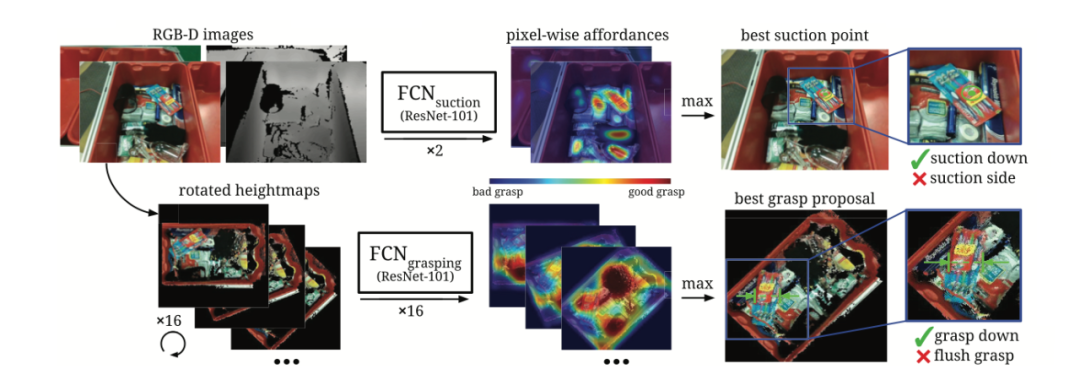
在训练过程中,作者使用到两个全卷积残差网络(FCN) —— ResNet101 —— 中分别判断物体的吸取和抓握的 Affordance。为判断物体是否能够被吸取,下图中上排的 FCN 使用多视角 RGB-D 图像作为输入,然后对每个像素的 吸取 Affordance 进行预测,预测值越接近 1,则代表该部位越容易被吸取。随后,模型需要将所有视角的的预测汇集到 3D 点云(3D point cloud)上。
图中下排的 FCN 则负责抓握 Affordance 的推理。作者假设一个物体可抓握与否取决于该物体是否有可抓握区域,并且可抓握区域可以从物体具备的几何形状和外观推断,即 [7] 的思想。首先,RGB-D 图像将被合并到场景的正交 RGB-D 高度图(orthographic RGB-D heightmap)中,来生成场景的高度图。图中的每个像素代表垂直方向——即重力方向——上的 2mm*2mm 的空间。FCN 需要对图中的每个像素的抓握 Affordance 进行判断(0-1 的概率),由于作者假设机器手的位置是与生成的高度图在垂直方向上平行的,生成的 Affordance heatmap 可以直接用于机器手在该方向上抓握该物体某一个部位的可能性。通过将高度旋转 16 次到不同的角度,并用 FCN 对其进行预测,则可以得出在不同方向上对该物体抓握的可能性,即预测结果直接包含了 16 种不同的自上而下的抓取角度的概率图。
在后处理(post-processing)时,根据最佳抓握点在生成的 3D 点云中的位置,算法会计算机器手两根手指的最佳宽度。同时,如果最佳抓握点过于靠近墙壁,算法会推荐执行齐平抓握,否则执行一般的抓握。
![]()
作者所提出的神经网络训练流程(图源:Zeng, A., Song, S., Yu, K.-T., Donlon, E., Hogan, F. R., Bauza, M., Ma, D., Taylor, O., Liu, M., Romo, E., Fazeli, N., Alet, F., Chavan Dafle, N., Holladay, R., Morona, I., Nair, P. Q., Green, D., Taylor, I., Liu, W., … Rodriguez, A. (2019). Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. The International Journal of Robotics Research.)
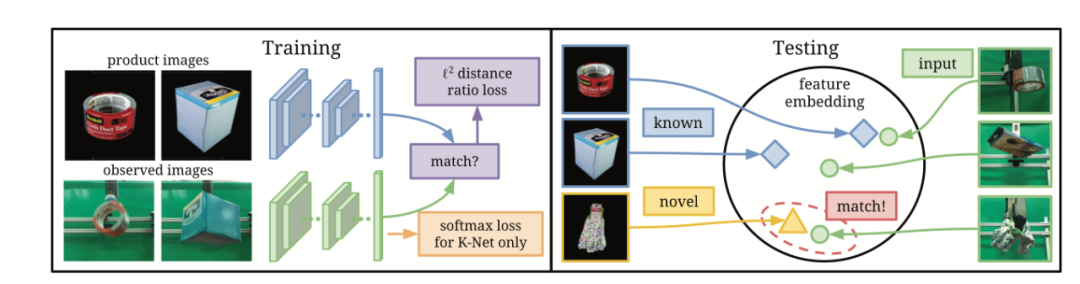
由于在进行推理时,训练好的神经网络有可能遇到未知的物体,作者提出了跨领域图像匹配(cross-domain image matching)模型来通过通过检索一组产品图像中的最佳匹配来解决此识别问题。该模型由两组 ConvNet (two-stream ConvNet)组成,一个用来对已知的图像计算 2048 维特征,另一个则为用于检索的图像——即未知物品的图像——计算 2048 维特征。在训练时作者从已知的物体中提供一系列匹配和不匹配的图像对来提供平衡的正例和反例,然后用 Triplet Loss 作为损失函数。这样可以有效地优化网络,从而最大程度地减小匹配对特征之间的 l2 距离,同时拉开不匹配对特征之间的 l2 距离。在测试过程中,已知对象和未知对象的图像都被映射到公共特征空间上,模型通过将观察到的图像映射到相同的特征空间并找到可能性最高的匹配来识别它们。本质上[8] 是把未知物体的推理简化成了搜索任务。
![]()
未知物体的识别框架(图源:Zeng, A., Song, S., Yu, K.-T., Donlon, E., Hogan, F. R., Bauza, M., Ma, D., Taylor, O., Liu, M., Romo, E., Fazeli, N., Alet, F., Chavan Dafle, N., Holladay, R., Morona, I., Nair, P. Q., Green, D., Taylor, I., Liu, W., … Rodriguez, A. (2019). Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. The International Journal of Robotics Research.)
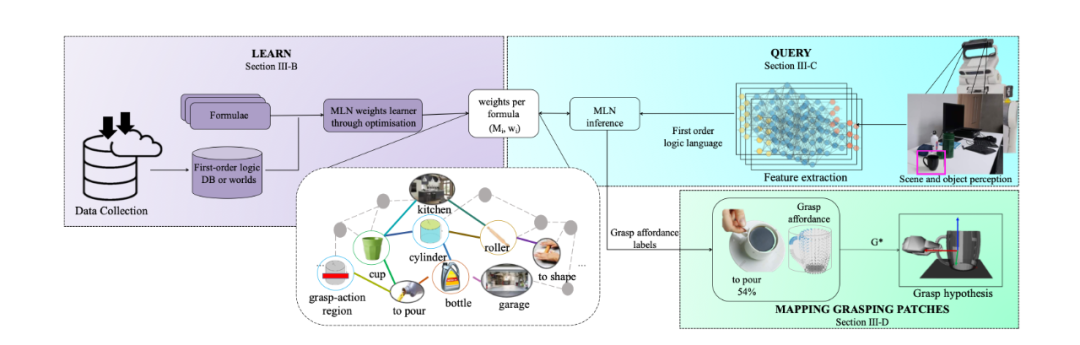
[9] 和 [6] 有一定相似度,但 [9] 中的 CNN 是为了构建知识图谱然后用 MLN 进行学习而服务的。其提出的模型如下图所示,在学习阶段(紫色方框)根据已经给出的一系列物体属性、抓握功能 以及依次创造出的规则(rules),作者使用 MLN 来学习物品的属性、位置和抓握功能之间的语意关系。学习完成后得到白色方框内所示例的知识图谱。在推理阶段(蓝色方框),作者使用预训练卷积神经网络(CNN)从被推理的 RGB 图像中提取被推理物品的属性,即形状、纹理、材料、位置等。为了从训练好的知识图谱中查询具体的抓握功能,作者使用吉布斯抽样(Gibbs sampling),在计算量允许的情况下遍历尽可能多的可能性来生成后验样本。
![]()
[9]中的抓握功能推理框架,由学习(learn),查询(query)和映射(mapping)组成。学习的模型(由白色矩形标注)使用彩色线段对节点之间的关系进行编码(
图源:Ardón P., Pairet È. , Petrick R. P. A. , Ramamoorthy S. and Lohan K. S. (2019). Learning Grasp Affordance Reasoning Through Semantic Relations. IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4571-4578.)
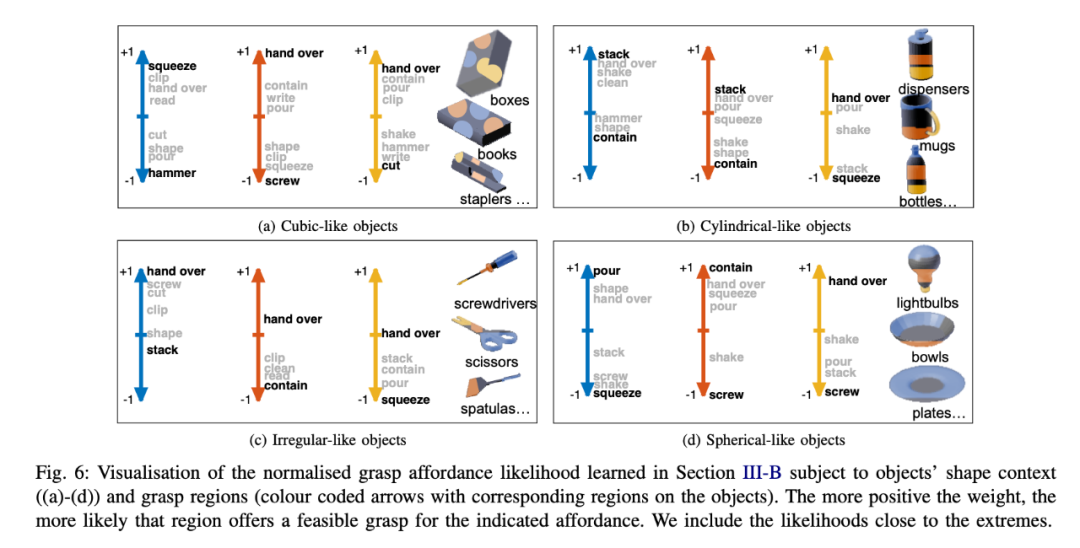
相对于 [6], [9] 专注于解决抓握功能的推理,同时对其进行了很多细分。在此之后, [9] 将一组细分后的掌握功能与一个物体相关联。下图描绘了在不同室内场景中,不同形状的物体可能对应的抓握功能。三个箭头按照颜色代表物体上不同位置更可能或更不可能拥有的抓握功能。所有的可能性都已经经过了归一化处理,在(+1,-1)内分布,数值越高,则代表可能性越大。
有趣的是,可以看到,在不同的抓握功能中,与性状最无关的功能是移交(hand over)。而其他功能,如盛纳(contain)则与物体的形状关联度很大。开放式容器更有可能具有盛纳功能而其他形状如螺丝刀等则最不可能具有盛纳功能。
![]()
对物体的形状和抓握功能之间的可能性进行可视化(图源:Ardón P., Pairet È. , Petrick R. P. A. , Ramamoorthy S. and Lohan K. S. (2019). Learning Grasp Affordance Reasoning Through Semantic Relations. IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4571-4578.)
不难看出,Affordance 的研究重点之一是发展机器人的泛化能力。正如人类能够对形状明显不同但 Affordance 相同的物体——比如玻璃杯 vs 葡萄酒杯——成功进行推理,同时还不会混淆形状相同但 Affordance 不同的物体,比如杯子和蜡烛。我们离人类的水平目前还有一段距离,但得益于深度学习的发展,Affordance 的推理也取得了很多突破。特别是 CNN 结合知识图谱的路线,已经提供不少非常有希望的结果。
但另一方面,硬件仍然是这个领域内的一个挑战。相较于普通的视觉任务(vision task),深度信息对于 Affordance 的学习至关重要。想象一下上文中两个杯子交缠的例子,若没有深度信息模型就无法正确推理。虽然这个例子比较极端,但当机器人需要和真实世界——一个有很多静止和非静止物体的世界——进行交互时,深度信息绝对是必不可少的。此外,如果模型不能被部署在云端上,算力也是对目前机器人身上的硬件的一个挑战。使用模拟或者使用神经网络,这两个方法对算力的要求都比较高,并且很多研究在推理并定位了 Affordance 还需要将结果投射到 3D 模型上,又进一步加大了硬件算力方面的挑战。
总的来说,笔者对机器人这一领域的发展充满信心,期待能够尽快看到更多研究上的突破落实到实际生产中。也许在不远的将来,我们就能在海底捞看到机器人服务员为你端茶倒水、为你表演扯面了呢 :-)
[1] J. J. Gibson (1966). The Senses Considered as Perceptual Systems. Allen and Unwin, London.
[2] J. J. Gibson (1975). 'Affordances and behavior'. In E. S. Reed & R. Jones (eds.), Reasons for Realism: Selected Essays of James J. Gibson, pp. 410-411. Lawrence Erlbaum, Hillsdale, NJ, 1 edn.
[3] H. Wu, G. S. Chirikjian. (2020). Can I Pour into It? Robot Imagining Open Containability Affordance of Previously Unseen Objects via Physical Simulations. arXiv:2008.02321.
[4] K. Fang, T. Wu, D. Yang, S. Savarese and J. J. Lim. (2018). Demo2Vec: Reasoning Object Affordances from Online Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition.
[5] Y. Zhu, C. Jiang, Y. Zhao, D. Terzopoulos, and S.-C. Zhu.(2016). Inferring forces and learning human utilities from videos. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3823–3833.
[6] Zhu, Y., Fathi, A., & Fei-Fei, L. (2014). Reasoning about Object Affordances in a Knowledge Base Representation. ECCV.
[7] Montesano L. and Lopes M. (2009).,Learning grasping affordances from local visual descriptors. 2009 IEEE 8th International Conference on Development and Learning
[8] Zeng, A., Song, S., Yu, K.-T., Donlon, E., Hogan, F. R., Bauza, M., Ma, D., Taylor, O., Liu, M., Romo, E., Fazeli, N., Alet, F., Chavan Dafle, N., Holladay, R., Morona, I., Nair, P. Q., Green, D., Taylor, I., Liu, W., … Rodriguez, A. (2019). Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. The International Journal of Robotics Research.
[9] Ardón P., Pairet È. , Petrick R. P. A. , Ramamoorthy S. and Lohan K. S. (2019). Learning Grasp Affordance Reasoning Through Semantic Relations. IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4571-4578.
[10] Ardón P., Pairet È., Petrick R., Ramamoorthy S., Lohan K. (2019) Reasoning on Grasp-Action Affordances. Towards Autonomous Robotic Systems. TAROS 2019. Lecture Notes in Computer Science, vol 11649.
[11] Do, T.-T., Anh N., and Ian R. (2018). Affordancenet: An end-to-end deep learning approach for object affordance detection. 2018 IEEE international conference on robotics and automation (ICRA).
[12] B. Curless and M. Levoy. (1996) A volumetric method for building complex models from range images. Proceedings of the 23rd annual conference on Computer graphics and interactive techniques, pp. 303–312.
本文作者为
Yuanyuan Li。
几次转行,本科国际贸易,研究生转向统计,毕业后留在比利时,从事农用机械研发工作,主要负责图像处理,实现计算机视觉算法的落地。
欣赏一切简单、优雅但有效的
算法,试图在深度学习的簇拥者和怀疑者之间找到一个平衡。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。