©作者 | 张北辰
单位 | 中国人民大学高瓴人工智能学院
数学推理能力是人类智能的一项非常重要又富有挑战性的能力。尽管在各类自然语言相关的理解和生成任务等中取得了良好的效果,预训练语言模型可以准确地理解数值含义、数学知识、推理逻辑吗?
最近一段时间,随着大规模预训练语言模型(PLM)的涌现,in-context learning 技术、微调策略的发展,数学推理相关任务指标取得了显著的突破。
本文将从思维链(Chain-of-Thought, CoT)、基于代码标注的微调方法、数学领域 PLM、数值推理、自动定理证明几个主题介绍近期在 NeurIPS、ICLR、EMNLP 上投稿或发表的工作。 受篇幅限制,本文只能介绍近期相关工作中的一小部分。文章图片均来自于原论文。欢迎大家批评指正,相互交流。
思维链的研究与改进
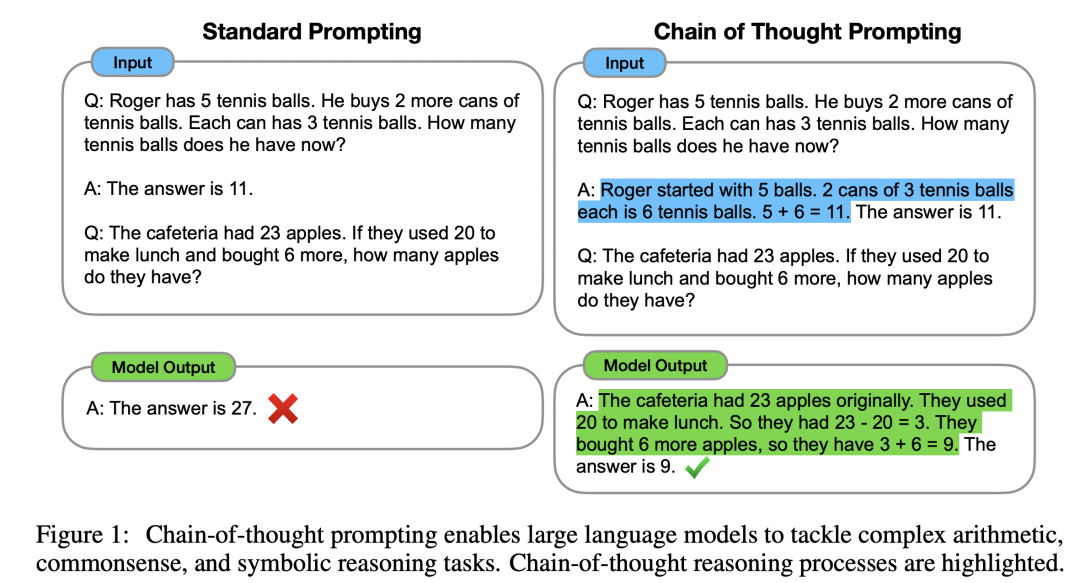
大规模语言模型的突出优势之一在于可以通过示例(demonstration)自由设定模型的生成形式,从而避免了昂贵的数据形式标注和微调过程。今年年初,Wei 等人提出了 Chain-of-Thought prompt 策略,利用示例提示模型以一步步显式生成思维链的方式来回答推理相关的问题。
这种 prompt 策略提升了大规模预训练语言模型(GPT-3、PaLM 等等)进行复杂推理的能力,在 GSM8k 这类有挑战的数学应用题求解任务中取得了非常显著的性能提升。随后有大量的工作基于 CoT 进行探究或改进。本文选择了一小部分最近公开的工作进行介绍。
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
收录情况:
论文链接:
https://arxiv.org/abs/2209.14610
文章构建了一种半结构化的数学应用题数据集,同时提出了一种自动选取 Chain-of-Thought 示例的方法。
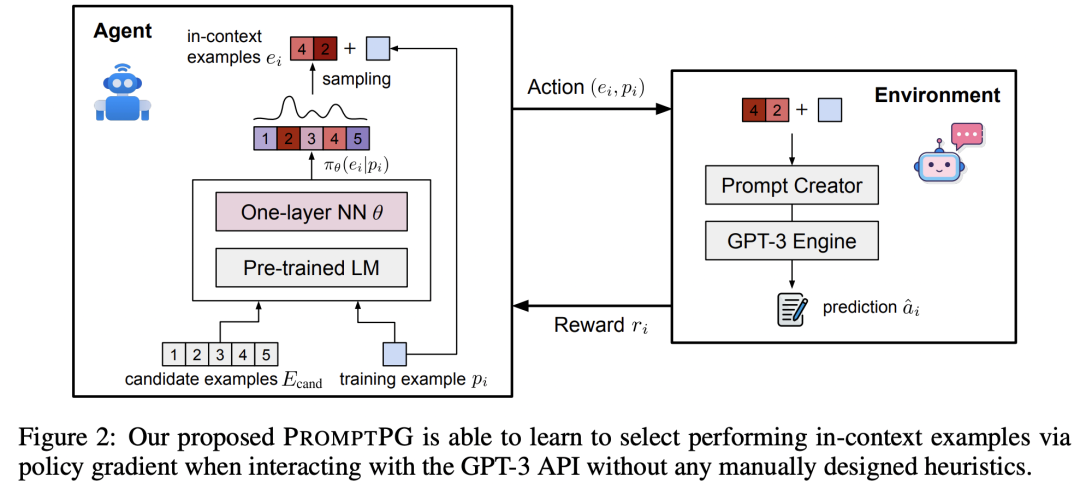
一方面,本文在纯文本数学应用题求解的基础上进行扩展,提出了半结构化的数学应用题数据集 TabMWP。该数据集的每个样本包含一段表格上下文和问题,其中表格上下文可能是图像、半结构化文本或者表格。
另一方面,Chain-of-Thought 的示例通常是人工选取或随机选取,可能会导致 PLM 的性能不稳定。为了解决这个问题,本文提出通过策略梯度来从训练集中选取示例的方法,用于选择适合当前问题的示例。
1.2 自动构建示例
Automatic Chain of Thought Prompting in Large Language Models
收录情况:
论文链接:
http://arxiv.org/abs/2210.03493
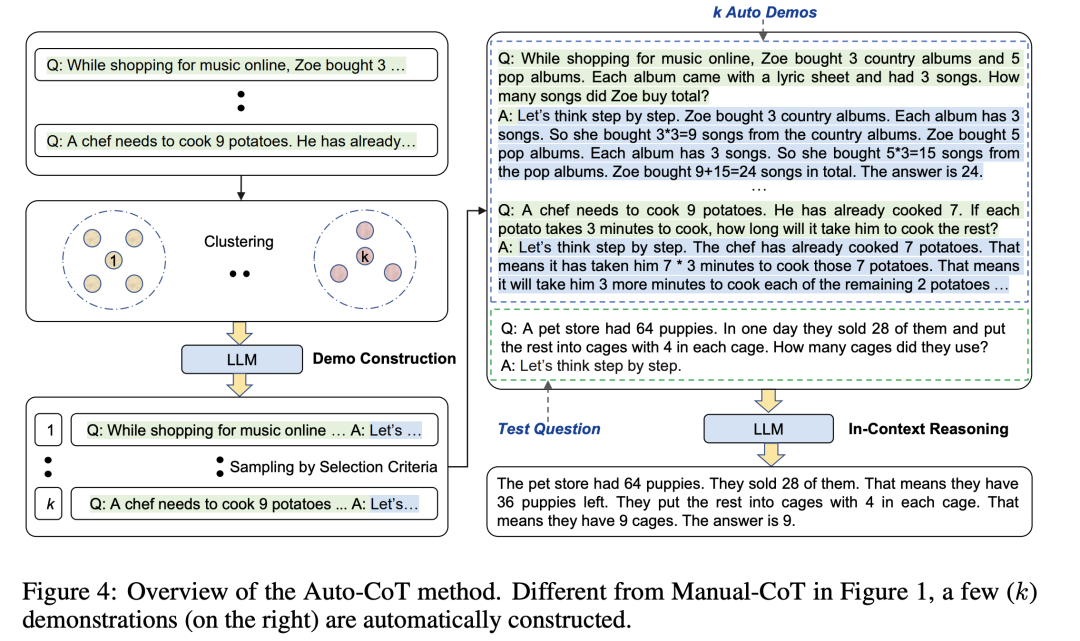
与上文的动机类似,本文也希望解决人工标注示例带来的性能不稳定问题。与上文从现有标注中选择示例的思路不同,本文考虑利用 Zero-Shot Chain-of-Thought (Zero-Shot CoT)自动构建示例,但主要的挑战在于模型自动生成的示例可能存在错误。
为了探究 Zero-Shot CoT 生成的示例对结果的影响,文章首先进行了详尽的预实验,发现基于相似问题生成示例会损害模型的性能。作者认为相似示例中的错误更容易传播到待求解的问题中。
基于以上预实验的错误经验,作者提出了一种基于多样性的自动化构建示例方法。首先对问题集进行聚类,选取每个簇中的代表问题作为示例,并利用 Zero-Shot CoT 示例对应的推理路径,最终进行带示例的 CoT 得到最终的结果。实验表明,示例中的少数错误情况并不会损害最终的推理效果。
1.3 减少思维链中的假阳性
Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning
收录情况:
论文链接:
https://arxiv.org/abs/2205.09712
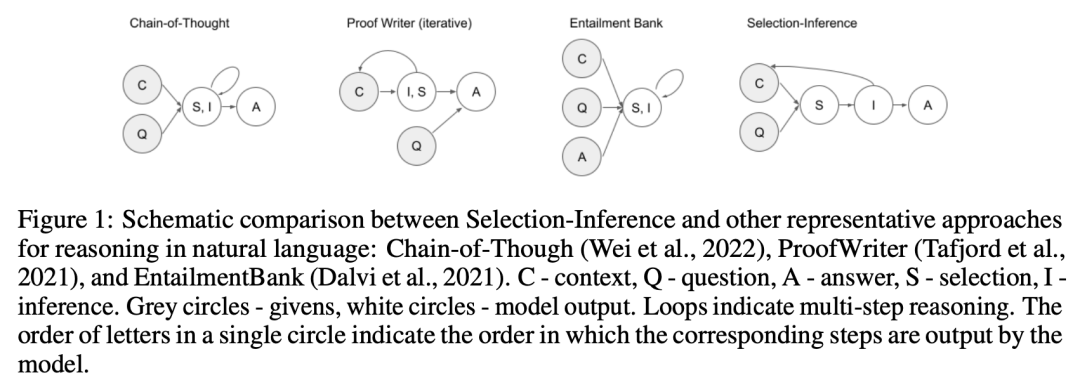
Chain-of-Thought 虽然可以显式展示模型的推理过程,但存在推理过程错误、答案正确的假阳性情况。本文对 Chain-of-Thought 的多步推理过程进行细化,将逻辑推理过程分解为两个模块:Selection 和 Inference。为了限制模型的推理过程,Inference 阶段只能参考 Selection 模块选取的上下文信息进行新事实的生成。Selection 模块中,选取的内容通过预训练语言模型对上下文进行打分比较确定,从而避免了语言模型自行编造选取的证据。
对于自然语言描述的数学问题,我们通常考虑用自然语言解答作为标注来训练模型,但自然语言解答的过程正确性很难评估,也可能存在跳步、指代不明的现象。最近有一些工作考虑将代码等形式语言作为解答形式,这样可以在清晰地表达解题逻辑的同时验证过程的正确性,并考虑进一步利用正确性反馈作为额外的监督信号进行训练。
Lila: A Unified Benchmark for Mathematical Reasoning
收录情况:
论文链接:
https://arxiv.org/abs/2210.17517
已有研究认为 Chain-of-Thought 是一种涌现能力(emergent ability),即只有足够大的预训练语言模型(>10B)才能够有体现的能力。那么相对较小的 PLM 如何提高数学推理能力呢?参数不够,数据来凑。
本文提出了包含 23 个任务的数学推理 benchmark Lila。对现有的数据集进行组合,并标注 Python 程序作为计算过程。作者基于这些数据进行多任务学习微调,得到了数学领域语言模型 Bhaskara。实验表明,多任务学习可以取得比单任务学习更好的效果,并且使用 2.7B 模型进行微调可以在部分任务中达到与 175B 模型进行少样本学习相近的效果。
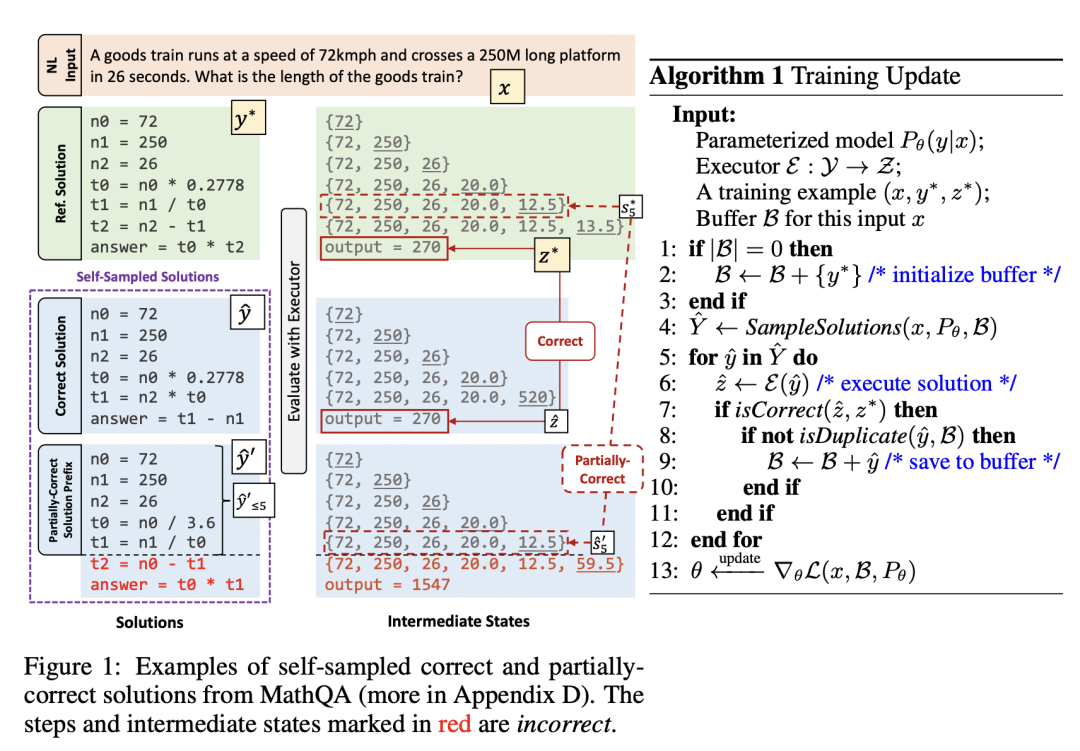
Learning Math Reasoning from Self-Sampled Correct and Partially-Correct Solutions
收录情况:
论文链接:
https://openreview.net/forum?id=4D4TSJE6-K
现有的数学题数据集往往对于每条样本只有一条参考解析,这可能会导致模型的泛化能力较差。本文提出让模型从自己生成的正确代码样例与部分正确代码样例进行学习。
在进行自采样、过滤、去重后,完全正确的样例可以直接作为训练数据,基于多目标学习进行训练。文中使用了三种不同的多目标学习损失函数:
除了完全正确的解答,部分正确的解答也值得利用,而关键问题在于如何筛选部分正确样例。本文的判断标准是当前解答的中间状态是否出现在完全生确或者部分正确的解答中。这部分部分正确的解析也可以通过上述训练目标进行学习。
数学领域预训练语言模型
Solving Quantitative Reasoning Problems with Language Models
收录情况:
论文链接:
https://arxiv.org/abs/2206.14858
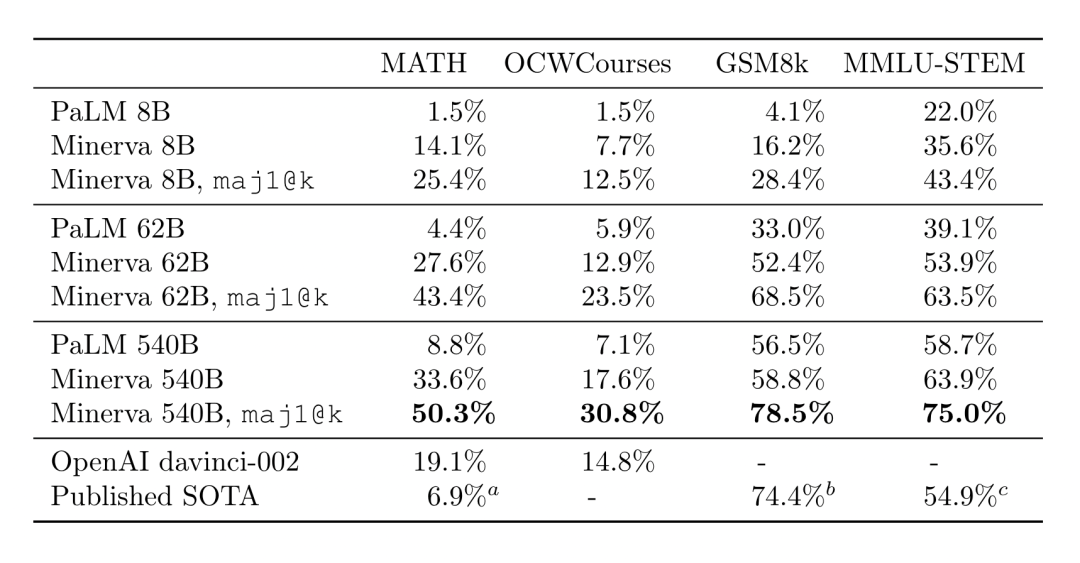
大规模语言模型虽然在自然语言相关任务上取得突破性进展,但是仍然在定量推理相关的任务中存在提升空间,本文提出了一个在自然语言语料和数学领域语料上继续预训练的大规模PLM Minerva(8B、62B、540B)。作者首先收集了 17B tokens 的数学网页、21B 的 arXiv 论文和超过 100B 的自然语言语料,基于 PaLM 进行继续预训练。
在高中数学竞赛数据集 MATH、数学应用题数据集 GSM8k 等数据集中取得了非常显著的进步。其中 MATH 数据集是难度非常大,涉及丰富数学领域知识和多步推理的数据集,Minerva 在 MATH 上的强大表现说明了领域大规模 PLM 出色的推理能力和领域知识记忆能力。
ELASTIC: Numerical Reasoning with Adaptive Symbolic Compiler
收录情况:
论文链接:
https://arxiv.org/abs/2210.10105
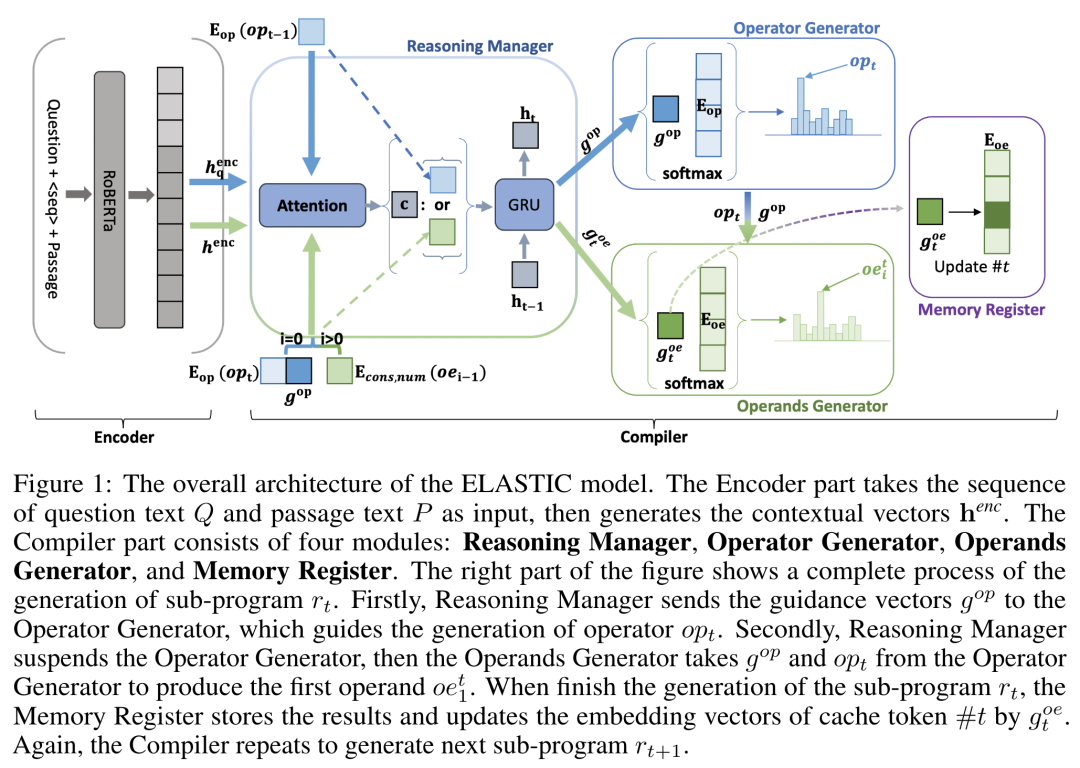
已有的数值推理阅读理解相关工作没有解耦操作符和操作数的生成,没有考虑到操作符的多样性以及操作数的动态数量,这导致模型很难生成复杂的程序。本文的核心贡献是将操作符和操作树的生成分开。
ELASTIC 模型包含文本编码器和由 4 个模块组成的解码器。对于解码器,Reasoning Manager 将编码器表示和上轮的操作符、操作数表示结合,生成引导输出;Operator Generator 和 Operands Generator 分别生成本轮操作符和操作数,Memory Register 用于存储子程序结果操作数的中间状态,用于参与未来操作数的计算。
实验表明,由于保存了中间状态,Memory Register 的存在能够让模型在长跨度的程序步骤中利用很早之前的中间结果。同时,由于操作数和操作符生成被解耦,该模型在长程序生成中更不容易受到级联错误的影响。
Inversely Eliciting Numerical Reasoning in Language Models via Solving Linear Systems
收录情况:
论文链接:
https://arxiv.org/abs/2210.05075
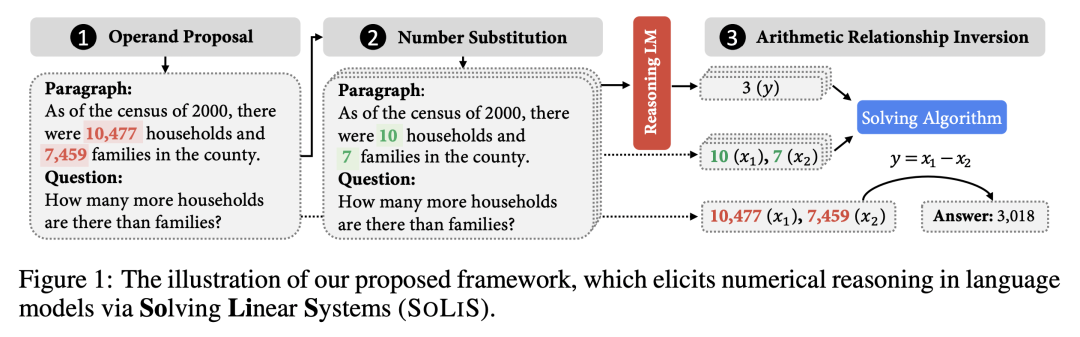
目前的预训练语言模型不能很好地理解大范围的数值,但对常见和简单的数值有一定的理解能力。本文巧妙地避开语言模型的弱项,提出利用简单数字作为 anchor 来探查语言模型中的隐式算术表达式,然后通过后处理来在已有表达式框架上执行复杂数字的计算。
具体来说,本文将复杂的数字(例如 10,477)替换为简单数字(10)作为 anchor 来简化输入,然后让模型预测结果。重复多次上述操作就可以得到多个不同的结果。随后考虑根据 anchor 数字和结果来得到隐含的表达式。作者考虑了基于分析、基于搜索和基于启发式的三种算法来推测表达式,从而规避了 PLM 对大范围数值理解的弱项。
涉及自然语言的自动定理证明
自动定理证明是数学研究和教育的重要组成部分,现有的相关工作通常是基于形式语言,这类工作的优势是可以有效地结合自动定理证明器进行验证和反馈,但问题在于形式语言的语料相对较少。近期有一类工作考虑在该领域结合自然语言信息,利用强大的预训练语言模型和大规模自然语言语料进一步提升自动定理证明的性能。进一步,学者们考虑打出“自然语言问题->自然语言解析->形式语言解析->形式验证环境“的组合拳,形成从自然语言到过程正确性反馈的闭环。
NaturalProver: Grounded Mathematical Proof Generation with Language Models
收录情况:
论文链接:
http://arxiv.org/abs/2205.12910
本文提出了一种文本生成模型,用于解决基于自然语言的数学证明问题。作者考虑了两类任务,一类是给定定理从头生成完整证明(full proof generation),一类是在部分 gold 证明步骤的基础上生成下一步证明(next-step suggestion)。
训练时,模型联合学习两个任务:基于定理、参考定理标题生成定理,以及基于参考定理标题生成参考定理内容。测试时考虑通过模型检索参考定理或直接提供 gold 定理两种设定。
为了避免语言模型随意生成错误的参考定理,作者还提出了一种分步受限解码策略,鼓励模型在生成证明时提到参考定理。
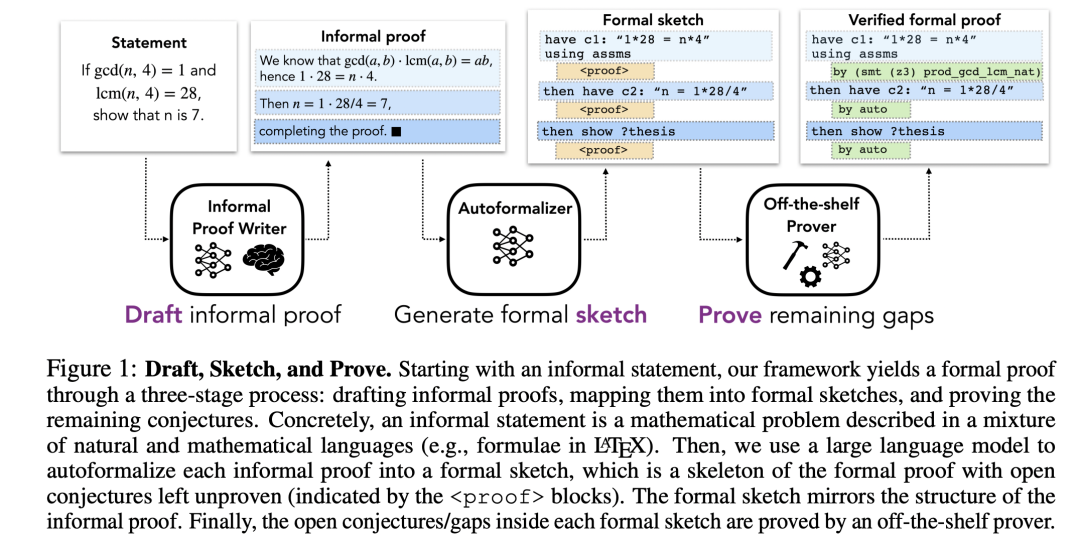
4.2 Draft, Sketch, and Prove
Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs
收录情况:
论文链接:
http://arxiv.org/abs/2210.12283
本文着眼于将现有自动定理证明器与自然语言语料相结合,提出了一种从自然语言-形式语言-自动定理证明的框架。首先将自然语言证明映射到形式语言证明草稿,然后利用草稿直接引导自动定理证明器搜索简单子问题。
对于自然语言描述的问题,本文分别考虑了让人标注自然语言解答或让 Minerva 模型生成自然语言解答。自然语言解答映射为形式语言的难点在于,自然语言通常会省略一些平凡细节,但这些细节对于规范的形式语言而言是必要的。因此考虑生成关注高阶信息的形式语言草图。考虑到缺乏自然语言到形式语言的平行语料,本文采用 in-context learning 的方式提示模型生成形式化草稿。最后,采用现有的自动定理证明器搜索草稿中缺失的部分,这样可以有效验证解答的正确性。
从今天讨论的几个主题中,我们可以大概看到数学推理能力研究的几个趋势。
首先,大模型结合 in-context learning 展现出了非常强大的推理能力,未来还会有很多工作聚焦于提示工程;
其次,形式语言和自然语言相互交织的工作越来越多。一方面,对于形式语言形式的自动定理证明任务,一些工作考虑利用自然语言的大规模语料和模型来提升性能;另一方面,对于自然语言形式的数学题求解,形式语言能够很清晰地表达解析的过程逻辑,也可以通过执行来验证和反馈正确性。
在非常短的时间内,数学推理相关的任务取得了令人瞩目的进展,相信在不久的将来,我们又会看到 PLM 在数学领域的进一步突破。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编