工程之道:旷视天元框架亚线性显存优化技术解析
机器之心发布
旷视研究院
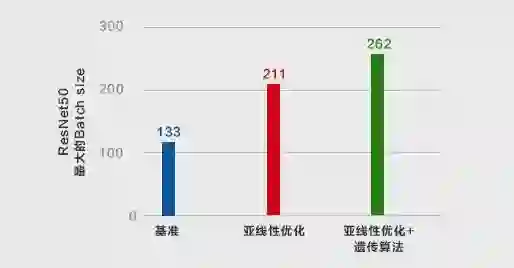
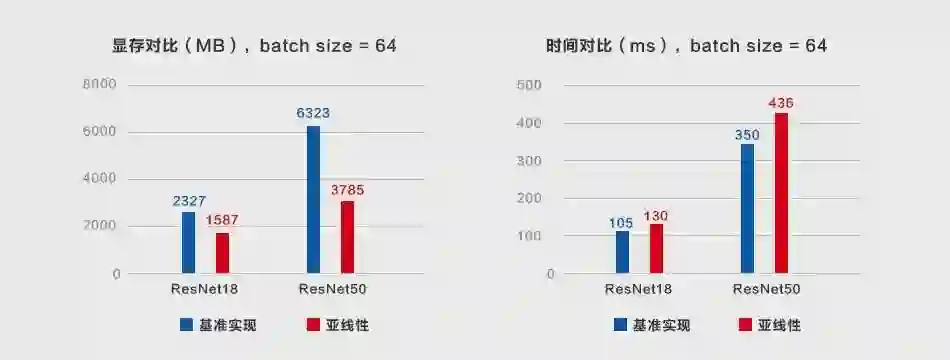
基于梯度检查点的亚线性显存优化方法 [1] 由于较高的计算/显存性价比受到关注。MegEngine 经过工程扩展和优化,发展出一套行之有效的加强版亚线性显存优化技术,既可在计算存储资源受限的条件下,轻松训练更深的模型,又可使用更大 batch size,进一步提升模型性能,稳定 batchwise 算子。使用 MegEngine 训练 ResNet18/ResNet50,显存占用分别最高降低 23%/40%;在更大的 Bert 模型上,降幅更是高达 75%,而额外的计算开销几乎不变。

通过合适的梯度定义,让算子的梯度计算不再依赖于前向计算作为输入,从而 in-place 地完成算子的前向计算,比如 Sigmoid、Relu 等;
在生命周期没有重叠的算子之间共享显存;
通过额外的计算减少显存占用,比如利用梯度检查点重新计算中间结果的亚线性显存优化方法 [1];
通过额外的数据传输减少显存占用,比如把暂时不用的数据从 GPU 交换到 CPU,需要时再从 CPU 交换回来。
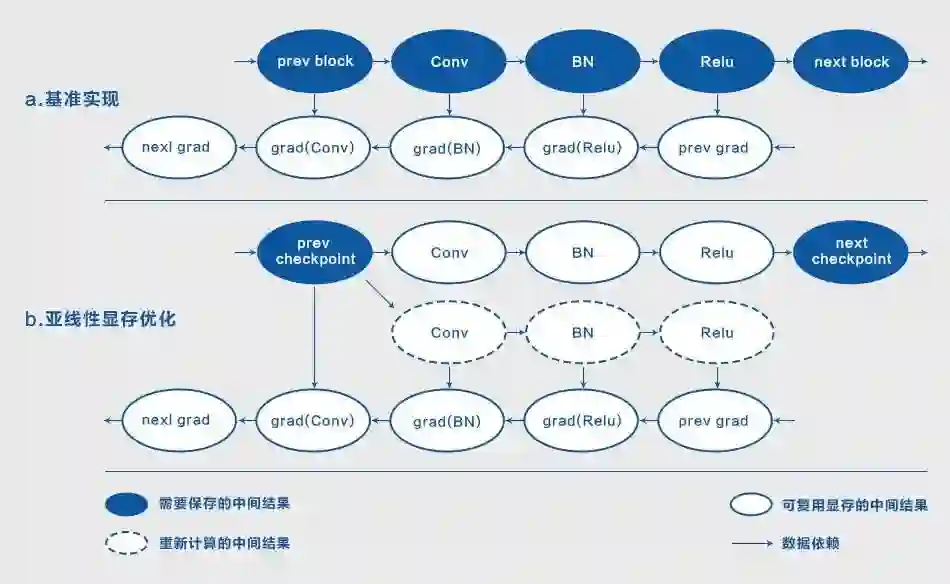
选取神经网络中 k 个检查点,从而把网络分成 k 个 block,需要注意的是,初始输入也作为一个检查点;前向计算过程中只保存检查点处的中间结果;
反向计算梯度的过程中,首先从相应检查点出发,重新计算单个 block 需要的中间结果,然后计算 block 内部各个 block 的梯度;不同 block 的中间结果计算共享显存。
显存占用从 O(n) 变成 O(n/k)+ O(k),O(n/k) 代表计算单个节点需要的显存,O(k) 代表 k 个检查点需要的显存,取 k=sqrt(n),O(n/k)+ O(k)~O(sqrt(n)),可以看到显存占用从线性变成了亚线性;
因为在反向梯度的计算过程中需要从检查点恢复中间结果,整体需要额外执行一次前向计算。

from megengine.jit import trace, SublinearMemoryConfigconfig = SublinearMemoryConfig()@trace(symbolic=True, sublinear_memory_config=config)def train_func(data, label, *, net, optimizer):...
import osfrom multiprocessing import Processdef train_resnet_demo(batch_size, enable_sublinear, genetic_nr_iter=0):import megengine as mgeimport megengine.functional as Fimport megengine.hub as hubimport megengine.optimizer as optimfrom megengine.jit import trace, SublinearMemoryConfigimport numpy as npprint("Run with batch_size={}, enable_sublinear={}, genetic_nr_iter={}".format(batch_size, enable_sublinear, genetic_nr_iter))# 使用GPU运行这个例子assert mge.is_cuda_available(), "Please run with GPU"try:# 我们从 megengine hub 中加载一个 resnet50 模型。resnet = hub.load("megengine/models", "resnet50")optimizer = optim.SGD(resnet.parameters(), lr=0.1,)config = Noneif enable_sublinear:config = SublinearMemoryConfig(genetic_nr_iter=genetic_nr_iter)@trace(symbolic=True, sublinear_memory_config=config)def train_func(data, label, *, net, optimizer):pred = net(data)loss = F.cross_entropy_with_softmax(pred, label)optimizer.backward(loss)resnet.train()for i in range(10):batch_data = np.random.randn(batch_size, 3, 224, 224).astype(np.float32)batch_label = np.random.randint(1000, size=(batch_size,)).astype(np.int32)optimizer.zero_grad()train_func(batch_data, batch_label, net=resnet, optimizer=optimizer)optimizer.step()except:print("Failed")returnprint("Sucess")# 以下示例结果在2080Ti GPU运行得到,显存容量为 11 GB# 不使用亚线性内存优化,允许的batch_size最大为 100 左右p = Process(target=train_resnet_demo, args=(100, False))p.start()p.join()# 报错显存不足p = Process(target=train_resnet_demo, args=(200, False))p.start()p.join()# 使用亚线性内存优化,允许的batch_size最大为 200 左右p = Process(target=train_resnet_demo, args=(200, True, 20))p.start()p.join()
MegEngine GitHub:https://github.com/MegEngine
MegEngine 官网:https://megengine.org.cn
MegEngine ModelHub:https://megengine.org.cn/model-hub/
登录查看更多
相关内容

Arxiv
9+阅读 · 2019年10月12日
Arxiv
4+阅读 · 2018年1月11日


相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2019年10月12日
Arxiv
4+阅读 · 2018年1月11日