Model-Based 两篇paper
概念学习作者的论文
Plan Online, Learn Offline: Efficient Learning and Exploration via Model-Based Control
Kendall Lowrey∗1 Aravind Rajeswaran∗1 Sham Kakade1 Emanuel Todorov1,2 Igor Mordatch3 ∗ Equal contributions 1 University of Washington 2 Roboti LLC 3 OpenAI { klowrey, aravraj } @ cs.washington.edu
Abstract We propose a “plan online and learn offline” framework for the setting where an agent, with an internal model, needs to continually act and learn in the world. Our work builds on the synergistic relationship between local model-based control, global value function learning, and exploration. We study how local trajectory optimization can cope with approximation errors in the value function, and can stabilize and accelerate value function learning. Conversely, we also study how approximate value functions can help reduce the planning horizon and allow for better policies beyond local solutions. Finally, we also demonstrate how trajectory optimization can be used to perform temporally coordinated exploration in conjunction with estimating uncertainty in value function approximation. This exploration is critical for fast and stable learning of the value function. Combining these components enable solutions to complex control tasks, like humanoid locomotion and dexterous in-hand manipulation, in the equivalent of a few minutes of experience in the real world.

https://sites.google.com/view/polo-mpc
https://arxiv.org/pdf/1811.01848.pdf
IMPROVING MODEL-BASED CONTROL AND ACTIVE EXPLORATION WITH RECONSTRUCTION UNCERTAINTY OPTIMIZATION
A PREPRINT
Norman Di Palo∗ Sapienza University of Rome Rome, Italy normandipalo@gmail.com Harri Valpola Curious AI Helsinki, Finland December 11, 2018
ABSTRACT Model-based predictions of future trajectories of a dynamical system often suffer from inaccuracies, forcing model-based control algorithms to re-plan often, thus being computationally expensive, sub-optimal and not reliable. In this work, we propose a model-agnostic method for estimating the uncertainty of a model’s predictions based on reconstruction error, using it in control and exploration. As our experiments show, this uncertainty estimation can be used to improve control performance on a wide variety of environments by choosing predictions of which the model is confident. It can also be used for active learning to explore more efficiently the environment by planning for trajectories with high uncertainty, allowing faster model learning.
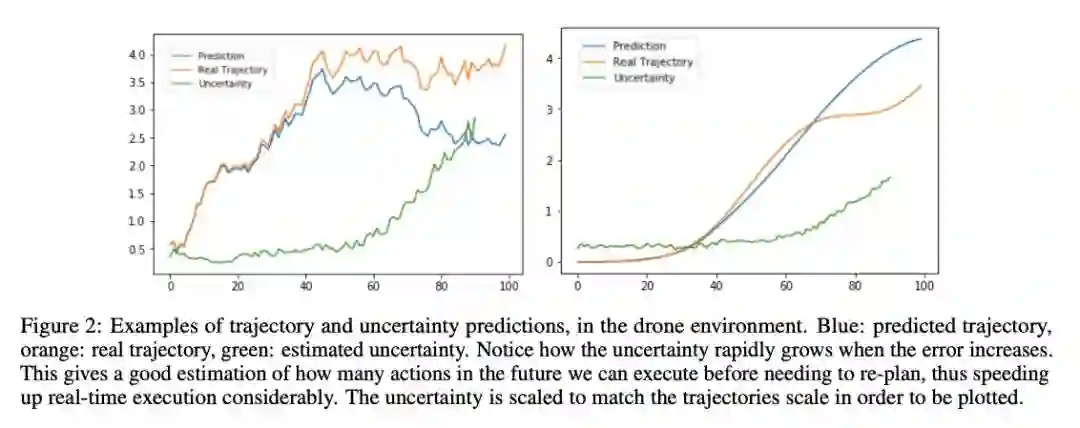
https://arxiv.org/pdf/1812.03955.pdf



