【EMNLP2020】Cross-Thought句子表示预训练
 !
!
阅读大概需7分钟 ![]()
跟随小博主,每天进步一丢丢 ![]()


论文

来源:EMNLP2020
原文链接:aclweb.org/anthology/20
来自:学习NLP的皮皮虾
Introduction
将句子嵌入到向量空间,在许多NLP任务上都需要用到。相较于词向量,使用句子编码的好处是这些编码后的表示可以在句子层级重用,因而能大大提升推理速度。譬如对于QA任务,对于候选段落可以将其预先缓存,然后就只需要和query的embedding进行匹配即可。
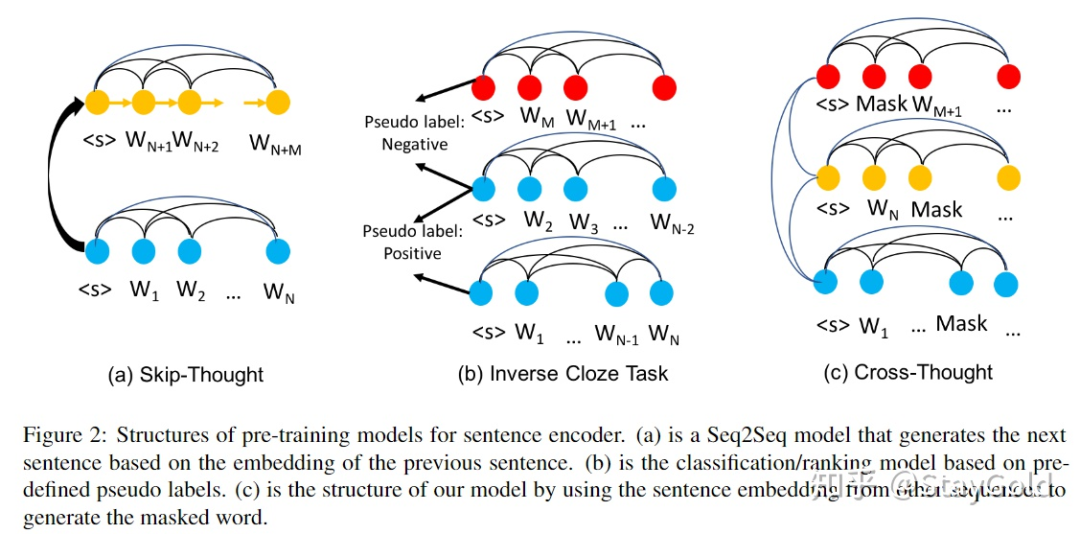
目前有一系列预训练句子编码器的方法,例如:
Skip-thought使用句子表示来生成下个句子,如上图(a);
Inverse Cloze Task要求给定句子,预测其上下文的句子(类似NSP任务),如上图(b);如之前工作证明的那样,该预训练任务较弱,往往难以学到非常细粒度的、带有充分语义信息的句子表示。
目前主流的语言模型预训练任务,如language model、masked language model、sequence generation,都难以直接应用于句子表示预训练。因为它们都采用序列的第一个特殊符号(如:[CLS])作为句子的表示,但是上述预训练任务的目标都没有损失直接作用在这个特殊符号上,这样就导致在这个特殊符号上学出来的句子表示很难包含充分的信息。
另一个限制在于,主流的masked language model都作用在非常长的序列上(比如512),使得模型在恢复被mask的token时,可以直接获取到周边句子的信息(因为在512的跨度上,多个句子都被分割到同一个样本上了,导致不同句子的token之间具有直接的信息交互)。作者认为,这对于学习有效的上下文token表示很有用,但对于学习句子表示则效率较低,因为信息不会主动聚集到[CLS]符号上。
本文提出了Cross-Thought,如上图(c)所示。它将输入文本切分成许多短句,使得恢复某个短句中被mask掉token的信息较难出现在同一个短句中,而不得不依赖于其上下文其它短句的信息:

如上图所示,最后一个短句中被mask掉的“United States”和“George Washington”必须从第一个短句中获得信息才能恢复。本文提出的方法不再是对于所有句子的所有token做attention,而是要求模型从上下文的句子表示中,选取最相关的句子表示用于恢复被mask的token。
Model
预训练数据处理
由于本文提出的预训练目标是让模型利用上下文的句子信息用来恢复该句子中被mask的token,因此预训练数据的构建方式和传统的预训练模型有所区别。
在传统的预训练模型训练中,语料通常按照最大长度(512)切分,然后将所有切分后的样本随机shuffle。但本文的做法是:
将语料切分成更短的短句
不进行shuffle
这样做使得:
切分后的短句有较大可能不具有恢复mask token的必要信息,而需要从上下文信息中去获取该信息;
不进行shuffle使得预训练短句之间具有上下文依赖关系,而不是像传统预训练任务那样,每个序列被视为是单独的一条样本。
Pre-training
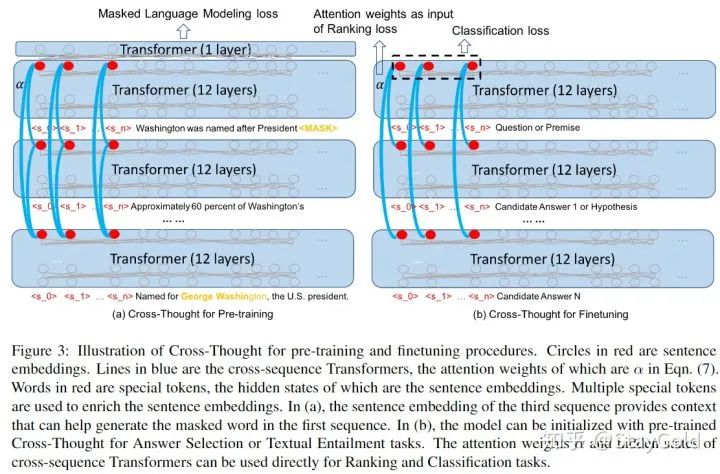
 条连续的序列组成:
条连续的序列组成:
 。类似BERT,本文也使用特殊符号的表示作为句子表示。为了获取更丰富的句子表示,本文不再是添加单个特殊符号,而是添加
。类似BERT,本文也使用特殊符号的表示作为句子表示。为了获取更丰富的句子表示,本文不再是添加单个特殊符号,而是添加
 个,即上图中的<s_0>到<s_n>。
个,即上图中的<s_0>到<s_n>。


 为
个追加的特殊符号的embedding;
为
个追加的特殊符号的embedding;
 为第
为第
 条短句的上下文word embedding,其中
条短句的上下文word embedding,其中
 为序列长度,
为序列长度,
 为embedding维度。
为embedding维度。
 为Transformer的所有隐层状态,
为Transformer的所有隐层状态,
 为所有特殊符号的hidden states,它们将作为最终的句子
的表示。
为所有特殊符号的hidden states,它们将作为最终的句子
的表示。


 为
为
 的第
的第
 行,即第
个特殊符号对应的句子表示;
行,即第
个特殊符号对应的句子表示;
 为所有句子在第
个特殊符号上句子表示的拼接;
为所有句子在第
个特殊符号上句子表示的拼接;
 为Cross-sequence Transformer的输出,相当于对句子表示进行了额外的上下文建模。
为Cross-sequence Transformer的输出,相当于对句子表示进行了额外的上下文建模。



 和
和
 分别为可训练向量;
分别为可训练向量;
 为注意力权重,可以直接用于下游任务(例如QA答案选择)。
为注意力权重,可以直接用于下游任务(例如QA答案选择)。
 来恢复masked token:
来恢复masked token:

 为Cross-Transformer输出的第
句子中,对应第
个特殊符号的隐状态;
为Cross-Transformer输出的第
句子中,对应第
个特殊符号的隐状态;
 是公式1中,对应非特殊符号的句子隐层向量;
是公式1中,对应非特殊符号的句子隐层向量;
 将被用来恢复masked token:
将被用来恢复masked token:

 是生成第
个短句中,第
是生成第
个短句中,第
 个masked token的概率。
个masked token的概率。
Finetuning
 ,该任务要求从一个候选集
,该任务要求从一个候选集
 中选取答案。基于公式7中的attention分数,可以直接构造finetune的目标:
中选取答案。基于公式7中的attention分数,可以直接构造finetune的目标:

 表示query
和所有其它候选答案的匹配概率分布。注意到模型包含多个Cross-sequence Transformer,分别作用在
个特殊符号上,同时每一个Cross-sequence Transformer包含多个head,因此这里的注意力权重选取其平均值即可。
和
表示query
和所有其它候选答案的匹配概率分布。注意到模型包含多个Cross-sequence Transformer,分别作用在
个特殊符号上,同时每一个Cross-sequence Transformer包含多个head,因此这里的注意力权重选取其平均值即可。
和
 ,使用公式4中的融合后的表示,作为分类依据如下:
,使用公式4中的融合后的表示,作为分类依据如下:

 为拼接
个特殊符号对应隐层状态的结果,
为拼接
个特殊符号对应隐层状态的结果,
 为最终用于分类的表示。
为最终用于分类的表示。
Experiments
数据集
MNLI:textual entailment(句子对分类任务)
SNLI:textual entailment
QQP:语义匹配任务
Quasar-T:阅读理解(选择候选段落)
HotpotQA(选择候选段落)
实验结果
主实验:
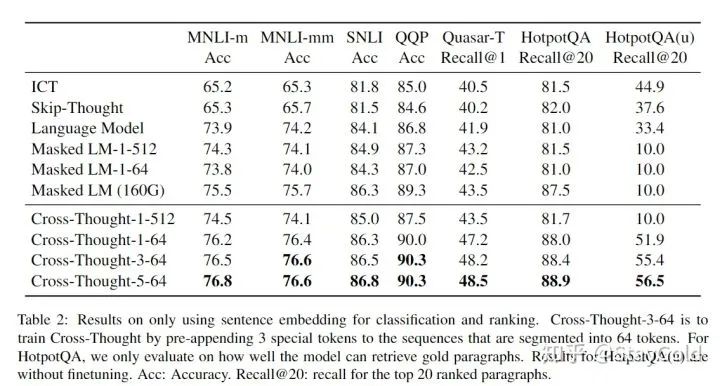
“-5-64”表示,按照64个词切分,同时追加5个特殊token。
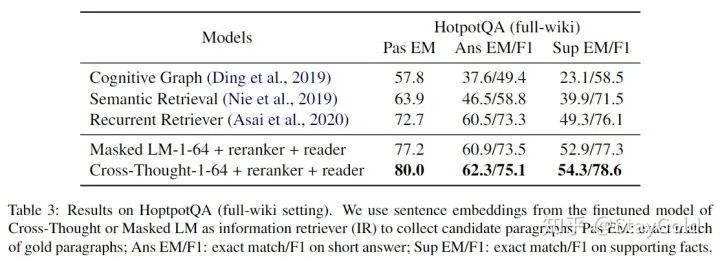
HotpotQA实验对比:
Conclusion
本文提出了Cross-Thought,一种创新的训练句子表示的自监督任务,使得模型利用上下文句子的表示用来恢复当前句子中被mask的token。实验结果显示Cross-Thought在短序列上预训练的有效性,进一步在下游任务上finetune的结果显示超出了许多baseline。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!





