NIPS论文遭受全面质疑:论证过程普遍不完整,又何谈对错?
栗 发自 凹非寺
量子位 报道 | 公众号 QbitAI
现在的机器学习论文,到底是不是经过有效论证的研究成果?
伦敦大学学院 (UCL) 的研究人员,分析了NIPS 2017的中选论文,得出的结果令人失望。
△ 连对错也不配谈?
一大问题就是基线 (Baseline) 严重缺失:
121篇参与评估的论文里,只有55%和现有最前沿算法 (State-of-the-Art) 做了对比;而与没有输入信息、没有经过训练的随机猜测进行了比较的,更是只有9%。
除此之外,NIPS论文的论证中,也大量存在其他问题,比如不标注置信区间。这些问题都会关系到,算法的有效性能不能被证实。
那么,就来仔细观察一下这份评估报告:
几乎全军覆没
研究人员从679篇NIPS 2017论文中,按照下面的标准筛选出了121篇接受评估:
提出了监督/半监督模型的研究,或者把预训练和监督/半监督模型结合在一起的研究。

三个维度
然后,团队确定了评估标准三大项:
一是实验:有没有用真实数据或者合成数据 (Synthetic Data) 去测试算法,最理想是两者兼有。
二是基线:有没有现有最前沿 (State-of-the-Art) 基线,或者随机猜测 (Uninformed) 的基线。
如果缺少前者,就不能得出超越现有算法的结论;缺少后者,就不能说明算法比随机猜测的表现更好。
三是量化对比 (Quantitative Comparison) :比如从有没有置信区间 (CI) 这一点上,评估对比是否正式 (下图为详细标准) 。
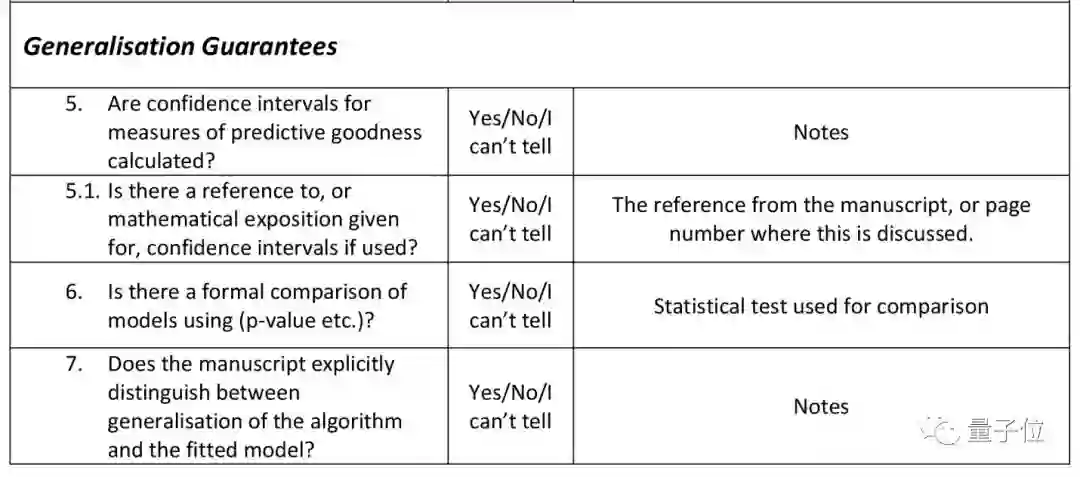
正式对比中,要标明置信区间,或者要有频率论假设检验 (Frequentist Hypothesis Test) 。并且,需要说明是怎样得出的。
如果不经过这些步骤,就不能证明,差异不是由随机波动 (Random Fluctuation) 造成的。

幸存者无几
先看数据,有99%的论文使用了真实数据来测试,有29%用到了合成数据。
基线方面,有91%的论文没有用到随机猜测 (Uninformed) 基线,有55%用了现有最先进 (State-of-the-Art) 算法作为基线。
而关于算法之间的量化对比是否正式,32%的论文标明了置信区间,但同时解释了置信区间如何计算的寥寥无几,被评判为“正式对比”的只有3%。
这样看来,几乎是全盘否定。

该如何解决呢?
研究人员为测试结果总结了一句话:完整的论证过程,在NIPS论文里是罕见的。
团队说,虽然用一届NIPS的发表论文,来概括ML/AI领域所有学术文献的情况,并不是一个非常全面的方法;
但是,NIPS/NeurIPS是领域内的顶会,把这里发表的论文视为高质量研究成果,作为研究样本,也属合理。

如果,机器学习领域的论文普遍存在论证不完整的问题,要怎么解决呢?
理论上不难,研究人员应该在论文里,表明使用某个方法、使用某种基线的理由,写清现有最先进 (State-of-the-Art) 的方法是什么,用合适的量化方法来体现研究的重要性。
可是,实际操作中还会遇到困难:
团队在论文里写到,ML/AI领域,环境比较特殊。众所周知,这个领域的论文发表和审核机制,会鼓励那些宏大的论调,而那些审慎的论点很容易被忽略。
如果机制不改变,这样的状况也很难发生明显的变化。

不过,研究人员也提出,用户 (End Users) 可能会促进情况的改善:
行业和政府部门的决策者,可以向上游领域施加压力,比如从财政上打击那些论证不够有效的研究成果。
论文传送门:
https://arxiv.org/pdf/1812.07519.pdf
— 完 —
年度评选报名

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !


