CV中的Attention机制:简单而有效的CBAM模块

极市导读
1. 什么是注意力机制?
-
通道注意力机制:对通道生成掩码mask,进行打分,代表是senet, Channel Attention Module -
空间注意力机制:对空间进行掩码的生成,进行打分,代表是Spatial Attention Module -
混合域注意力机制:同时对通道注意力和空间注意力进行评价打分,代表的有BAM, CBAM
2. CBAM模块的实现
2.1 通道注意力机制
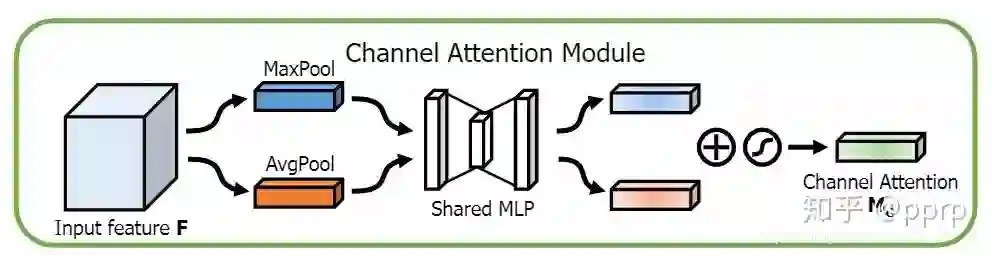
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
2.2 空间注意力机制
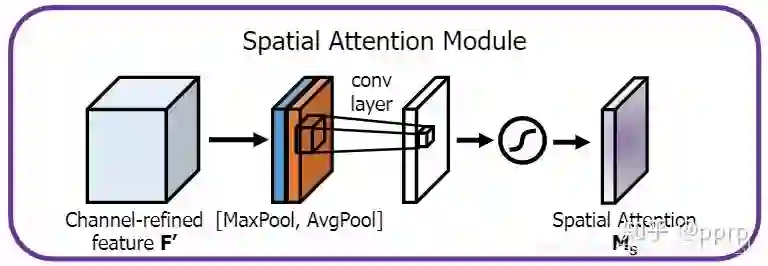
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)
2.3 Convolutional bottleneck attention module
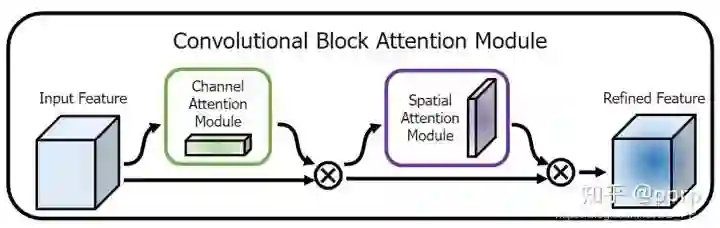
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # 广播机制
out = self.sa(out) * out # 广播机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class cbam(nn.Module):
def __init__(self, planes):
self.ca = ChannelAttention(planes)# planes是feature map的通道个数
self.sa = SpatialAttention()
def forward(self, x):
x = self.ca(out) * x # 广播机制
x = self.sa(out) * x # 广播机制
3. 在什么情况下可以使用?
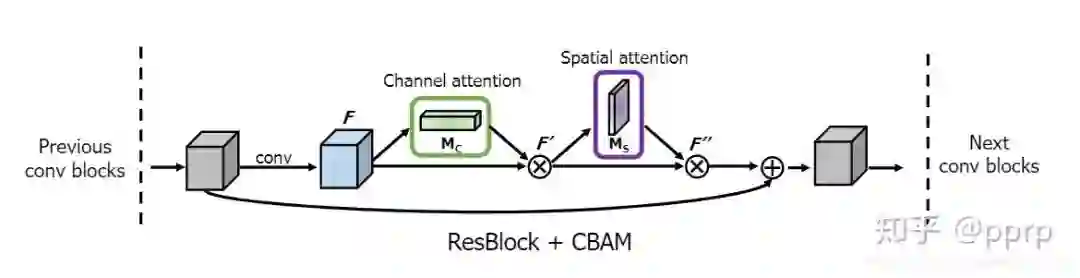
-
如何更有效地计算channel attention?
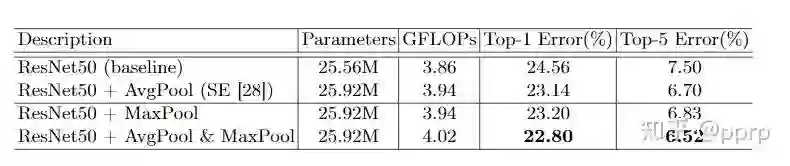
-
如何更有效地计算spatial attention?
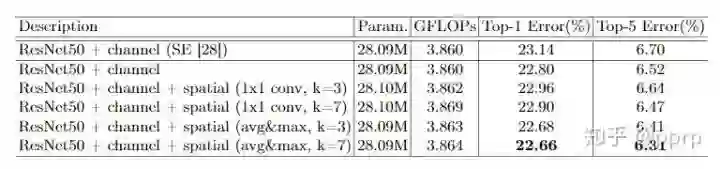
-
如何组织这两个部分?
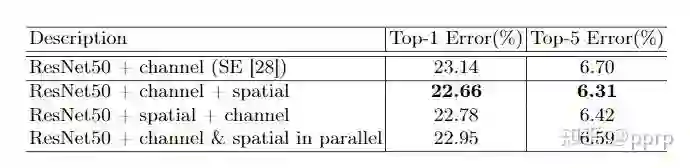

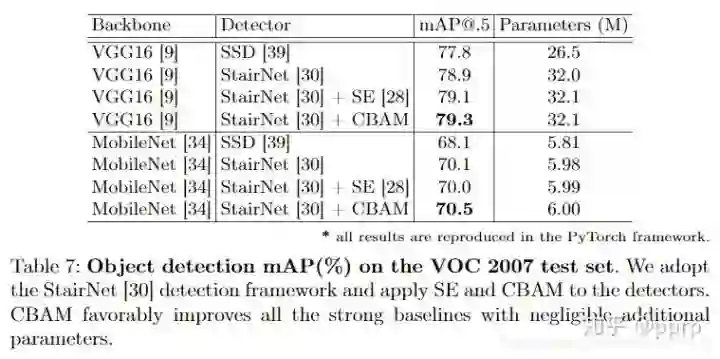
4. 参考
推荐阅读



登录查看更多
相关内容

Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。


相关VIP内容
相关资讯
相关论文