组合在线学习:实时反馈玩转组合优化
编者按:人们每天都在面临取舍,如何能够做出机会成本最低且收益最为理想的选择,这让很多选择恐惧症们陷入无限纠结的境地。
看似无比困难的权衡问题,如今组合在线学习就能帮你“算出”最优解,轻松破解传统组合优化问题。本文中,我们邀请到微软亚洲研究院资深研究员陈卫为大家多面解读组合在线学习的奥妙之处。
什么是组合在线学习?大家都曾有过这样的经历,在我们刷微博或是阅读新闻的时候,经常会看到一些自动推荐的内容,这些信息可以根据你对推送的点击情况以及阅读时间等来调整以后的推送选择。再比如,手机导航往往会在你输入地点时推荐一条最合适的路线,当你按照推荐走的时候,手机导航也会收集这次行程的信息,哪里比较堵,哪里很顺畅,从而可以调整系统今后的推荐。
有人会提出质疑:这不就是推荐系统吗?是的,但是传统的推荐系统只能离线学习用户和对象的各种特征,作出尽量合适的推荐,是一个相对静态的系统。而我们这里强调的是在线学习(online learning),即迅速利用在线反馈,不断迭代调整推荐策略,从而尽快提高学习效果和整体收益。而组合在线学习(combinatorial online learning)的组合性则体现在学习的输出上,它不是一个简单结果,而是一个组合对象。比如上述情形中,手机导航输出的路线其实是若干路段的组合或者包括不同交通工具换乘的组合,而手机助手的推荐也是不同消息渠道的组合。
传统的推荐系统通过与组合在线学习相结合,就可以通过即时反馈调整策略达到更好的推荐效果。而组合在线学习应用范围远不止推荐系统,任何传统的组合优化问题,只要问题的输入有不确定性,需要通过在线反馈逐步学习的,都可以应用组合在线学习方法。组合在线学习也是当前大热的强化学习(reinforcement learning)的一个组成部分,而组合在线学习的强大理论支持也会给强化学习提供很好的理论指导。所以组合在线学习就是下面图示所表达的组合优化和在线学习不断交互迭代更新的反馈环路。
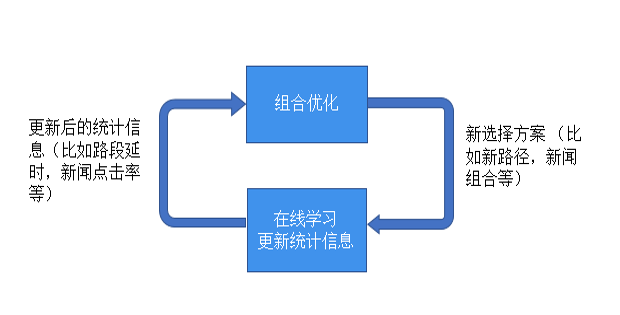

在线学习的核心:权衡探索和守成
要介绍组合在线学习,我们先要介绍一类更简单也更经典的问题,叫做多臂老虎机(multi-armed bandit或MAB)问题。赌场的老虎机有一个绰号叫单臂强盗(single-armed bandit),因为它即使只有一只胳膊,也会把你的钱拿走。而多臂老虎机(或多臂强盗)就从这个绰号引申而来。假设你进入一个赌场,面对一排老虎机(所以有多个臂),由于不同老虎机的期望收益和期望损失不同,你采取什么老虎机选择策略来保证你的总收益最高呢?这就是经典的多臂老虎机问题。
这个经典问题集中体现了在线学习及更宽泛的强化学习中一个核心的权衡问题:我们是应该探索(exploration)去尝试新的可能性,还是应该守成(exploitation),坚持目前已知的最好选择?在多臂老虎机问题中,探索意味着去玩还没玩过的老虎机,但这有可能使你花太多时间和金钱在收益不好的机器上;而守成意味着只玩目前为止给你收益最好的机器,但这又可能使你失去找到更好机器的机会。而类似抉择在日常生活中随处可见:去一个餐厅,你是不是也纠结于是点熟悉的菜品,还是点个新菜?去一个地方,是走熟知的老路还是选一条新路?而探索和守成的权衡就是在线学习的核心。
多臂老虎机的提出和研究最早可以追述到上世纪三十年代,其研究模型和方法已有很多。想进一步了解其技术细节的读者可参考综述[1]。其中一类重要的模型是随机多臂老虎机,即环境给予的反馈遵从某种随机但未知的分布,在线学习的过程就是要学出这个未知分布中的某些参数,而且要保证整个学习过程的整体收益尽量高。这其中最有名的一个方法是UCB(Upper Confidence Bound)方法,能够通过严格的理论论证说明UCB可达到接近理论最优的整体收益。
组合在线学习:组合优化和在线学习的无缝对接
介绍了多臂老虎机问题,我们现在终于可以介绍组合在线学习,更具体的是组合多臂老虎机(CMAB)问题了。在组合多臂老虎机问题中,你一次拉动的不是一个臂,而是多个臂组成的集合,我们称之为超臂(super arm),原来的每个臂我们称之为基准臂(base arm),以示区别。拉完这个超臂后,超臂所包含的每个基准臂会给你一个反馈,而这个超臂整体也给你带来某种复合的收益。
以前面的手机导航作为一个例子。城市中的每一个路段可以被看成是一个老虎机(一个基准臂),而你一次选择的并不是一个路段,而是从出发点到终点的一条路线,会包括很多路段,整个这个路线就是一个的超臂。当你实际走这条路线时,每一个路段都会给你反馈,就是该路段的拥堵时间(注意这个拥堵时间是随机的,不是每次都一样,而平均拥堵时间就是你需要学习的),而你的整体收益就是整个路线的拥堵时间(在这个例子里拥堵越短越好,所以用整体损失表达更贴切些)。这就是组合多臂老虎机问题。很多组合推荐,组合选择优化问题都可以用多臂老虎机来表达。
那么如何解决组合多臂老虎机的问题呢?你可能首先想到的就是把每一个超臂看成是经典多臂老虎机问题中的一个臂。但是超臂是多个基准臂的组合,而这样组合的数目会大大超过问题本身的规模——组合问题中经典的组合爆炸现象,因此传统的方法并不适用。所以在线学习不能在超臂这个层次进行,而需要在基准臂层次上进行,并需要与离线组合优化巧妙地结合。我们在ICML2013的论文[2]中给出了组合多臂老虎机的一般框架和基于UCB方法的CUCB算法。CUCB算法将组合优化和在线学习无缝对接实现了前面图示中的反馈回路。较之前的涉及组合多臂老虎机的研究,我们的模型适用范围更广,尤其是我们通过给出收益函数的两个一般条件,能够涵盖非线性的收益函数,这是第一个能解决非线性多臂老虎机问题的方案。我们的工作,包括之后我们和他人的后续工作,都强调对在线学习部分和离线优化部分的模块化处理和无缝对接。也即我们将离线优化部分作为一个黑盒子神谕(oracle),这部分可以由具有相关领域知识的专家来完成。而一旦离线优化问题可以精确解决或近似解决,我们就可以把这个离线算法当作黑盒子拿过来和我们在线学习方法相结合,达到有严格理论保证的组合在线学习效果。这使得我们的方法可以适用于一大批已经有离线优化算法的组合在线学习问题,比如最短路径、最小生成树、最大匹配、最大覆盖等问题的在线学习版本,而不需要对每个问题单独再设计在线学习算法。
在论文[2]的期刊版本[6]中,我们进一步将组合多臂老虎机模型扩展为允许有随机被触发臂的模型。这一模型可以被用于在线序列推荐、社交网络病毒式营销等场景中,因为在这些场景中前面动作的反馈可能会触发更多的反馈。然而在[6]的理论结果中,我们包含了一个和触发概率有关的项,而这个项在序列推荐和病毒营销场景中都会过大,造成在线学习效果不好。在今年刚被录取的NIPS论文[9]中,我们彻底解决了这个问题:一方面我们论证了序列推荐和病毒营销等满足某种特定条件的问题都不会有这个不好的项,另一方面我们指出在更一般的组合多臂老虎机中这个项又是不可避免的。这是目前研究可触发臂的组合多臂老虎机中最好的一般结果。
除此之外,我们还在与组合多臂老虎机相关的方面做了若干工作,比如如何在反馈受限情况下达到好的学习效果[3];如何解决先探索再找到最佳方案的组合探索问题[4];当离线优化基于贪心算法时,如果更好地将离线贪心算法和在线学习相结合[5];如何在有上下文的场景中解决组合序列推荐问题[7];以及当超臂的期望收益取决于每个基准臂的随机分布而不仅是每个基准臂的分布均值时,如何同样有效地进行组合在线学习[8]。
总之,组合在线学习将离线组合优化和在线学习有机地结合起来。由于组合优化的普遍存在和在线即时反馈机制的日益完善,将优化和反馈不断迭代结合的组合在线学习势必会找到更多的应用,而组合在线学习坚实的理论根基会对其实际应用起到很好的指导作用。这个方向有很多的理论和实践问题需要进一步研究,我们也希望在这个方向继续做出新的贡献。
[1] Sébastien Bubeck and Nicolò Cesa-Bianchi. Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems.
[2] Wei Chen, Yajun Wang, and Yang Wang. Combinatorial Multi-Armed Bandit: GeneralFramework, Results and Applications.
[3] Tian Lin, Bruno Abrahao, Robert Kleinberg, John C.S. Lui, and Wei Chen. Combinatorial Partial Monitoring Game with Linear Feedback and its Applications.
[4] Shouyuan Chen, Tian Lin, Irwin King, Michael R. Lyu, and Wei Chen. Combinatorial Pure Exploration of Multi-ArmedBandits.
[5] Tian Lin, Jian Li, and Wei Chen. Stochastic Online Greedy Learning with Semi-bandit Feedbacks.
[6] Wei Chen, Yajun Wang, Yang Yuan, and Qinshi Wang. Combinatorial Multi-Armed Bandit and Its Extension to Probabilistically Triggered Arms.
[7] Shuai Li, Baoxiang Wang, Shengyu Zhang, and Wei Chen. Contextual Combinatorial Cascading Bandits.
[8] Wei Chen, Wei Hu, Fu Li, Jian Li, YuLiu, and Pinyan Lu. Combinatorial Multi-Armed Bandit with General Reward Functions.
[9] Qinshi Wang, and Wei Chen. Improving Regret Bounds for Combinatorial Semi-Bandits with Probabilistically Triggered Arms and Its Applications.

陈卫,微软亚洲研究院资深研究员,清华大学交叉信息学院兼职教授,中科院计算所客座研究员。主要研究方向包括社交和信息网络、在线机器学习、网络博弈论和经济学、分布式计算、容错和可靠系统等。他在社交网络和在线学习方面的基础性研究得到广泛关注,这方面的论文他引逾4000次。陈卫是中国计算机协会第一届大数据专家委员会成员和《大数据》期刊的编委,也是多个顶级学术会议(KDD、WWW、WSDM、SIGMOD、NIPS等)的程序委员会成员,并有一本关于信息和影响力传播的专著。
你也许还想看:

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。






