pytorch的余弦退火学习率
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要10分钟
跟随小博主,每天进步一丢丢


地址:https://www.zhihu.com/people/lim0-34
编辑:人工智能前沿讲习
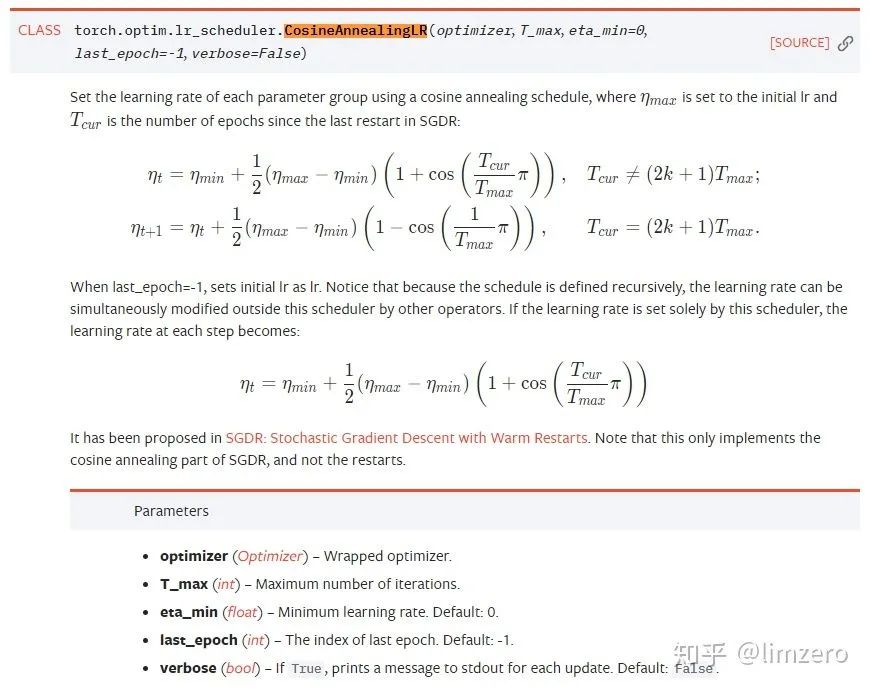

CosineAnnealingLR
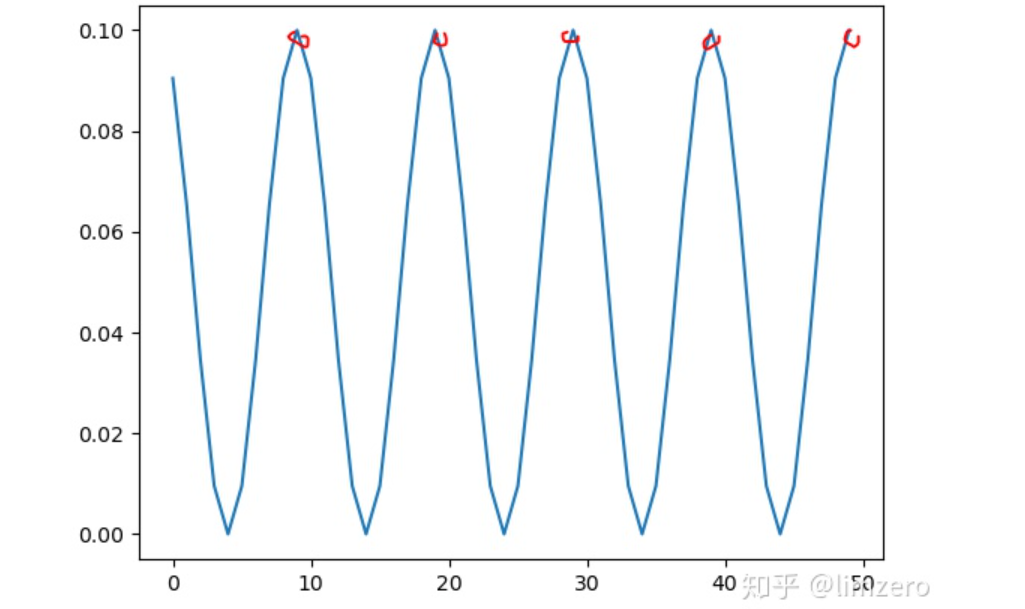
CosineAnnealingWarmRestarts
-
T_0:学习率第一次回到初始值的epoch位置 -
T_mult:这个控制了学习率变化的速度 -
如果T_mult=1,则学习率在T_0,2T_0,3T_0,....,i*T_0,....处回到最大值(初始学习率) -
5,10,15,20,25,.......处回到最大值 -
如果T_mult>1,则学习率在T_0,(1+T_mult)T_0,(1+T_mult+T_mult**2)T_0,.....,(1+T_mult+T_mult2+...+T_0i)*T0,处回到最大值 -
5,15,35,75,155,.......处回到最大值
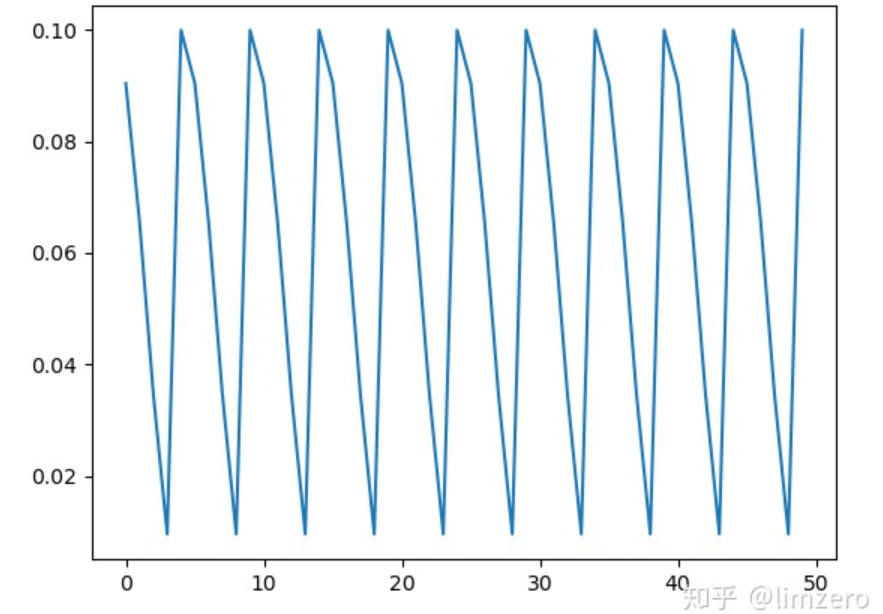
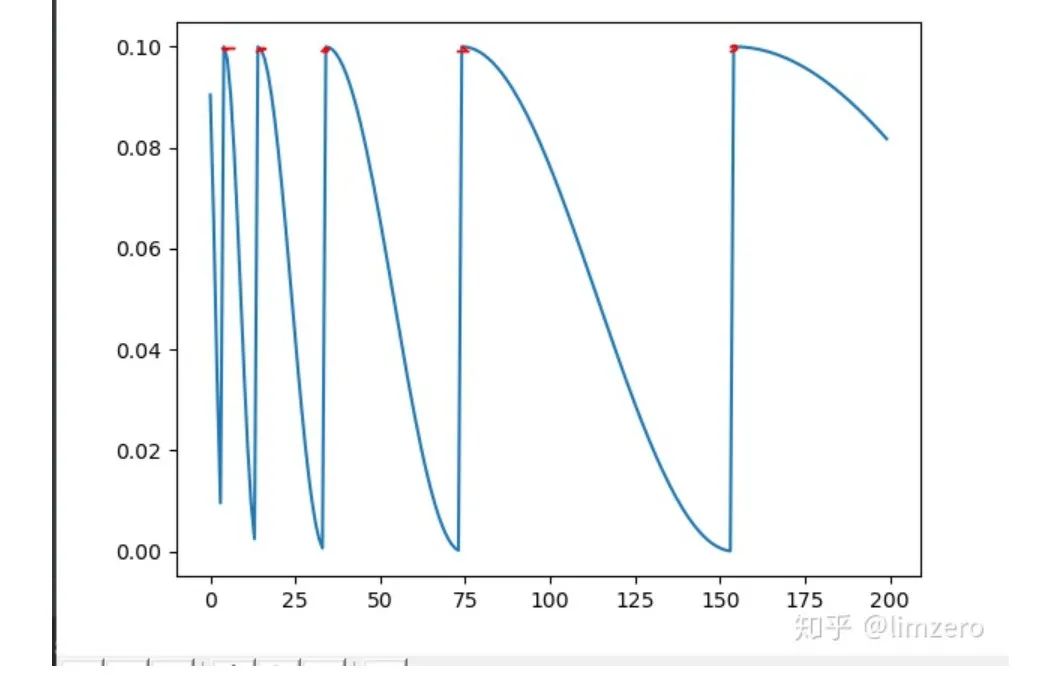
所以可以看到,在调节参数的时候,一定要根据自己总的epoch合理的设置参数,不然很可能达不到预期的效果,经过我自己的试验发现,如果是用那种等间隔的退火策略(CosineAnnealingLR和Tmult=1的CosineAnnealingWarmRestarts),验证准确率总是会在学习率的最低点达到一个很好的效果,而随着学习率回升,验证精度会有所下降.所以为了能最终得到一个更好的收敛点,设置T_mult>1是很有必要的,这样到了训练后期,学习率不会再有一个回升的过程,而且一直下降直到训练结束。
import torchfrom torch.optim.lr_scheduler import CosineAnnealingLR,CosineAnnealingWarmRestarts,StepLRimport torch.nn as nnfrom torchvision.models import resnet18import matplotlib.pyplot as plt#model=resnet18(pretrained=False)optimizer = torch.optim.SGD(model.parameters(), lr=0.1)mode='cosineAnnWarm'if mode=='cosineAnn': scheduler = CosineAnnealingLR(optimizer, T_max=5, eta_min=0)elif mode=='cosineAnnWarm': scheduler = CosineAnnealingWarmRestarts(optimizer,T_0=5,T_mult=1) ''' 以T_0=5, T_mult=1为例: T_0:学习率第一次回到初始值的epoch位置. T_mult:这个控制了学习率回升的速度 - 如果T_mult=1,则学习率在T_0,2*T_0,3*T_0,....,i*T_0,....处回到最大值(初始学习率) - 5,10,15,20,25,.......处回到最大值 - 如果T_mult>1,则学习率在T_0,(1+T_mult)*T_0,(1+T_mult+T_mult**2)*T_0,.....,(1+T_mult+T_mult**2+...+T_0**i)*T0,处回到最大值 - 5,15,35,75,155,.......处回到最大值 example: T_0=5, T_mult=1 '''plt.figure()max_epoch=50iters=200cur_lr_list = []for epoch in range(max_epoch): for batch in range(iters): ''' 这里scheduler.step(epoch + batch / iters)的理解如下,如果是一个epoch结束后再.step 那么一个epoch内所有batch使用的都是同一个学习率,为了使得不同batch也使用不同的学习率 则可以在这里进行.step ''' #scheduler.step(epoch + batch / iters) optimizer.step() scheduler.step() cur_lr=optimizer.param_groups[-1]['lr'] cur_lr_list.append(cur_lr) print('cur_lr:',cur_lr)x_list = list(range(len(cur_lr_list)))plt.plot(x_list, cur_lr_list)plt.show()
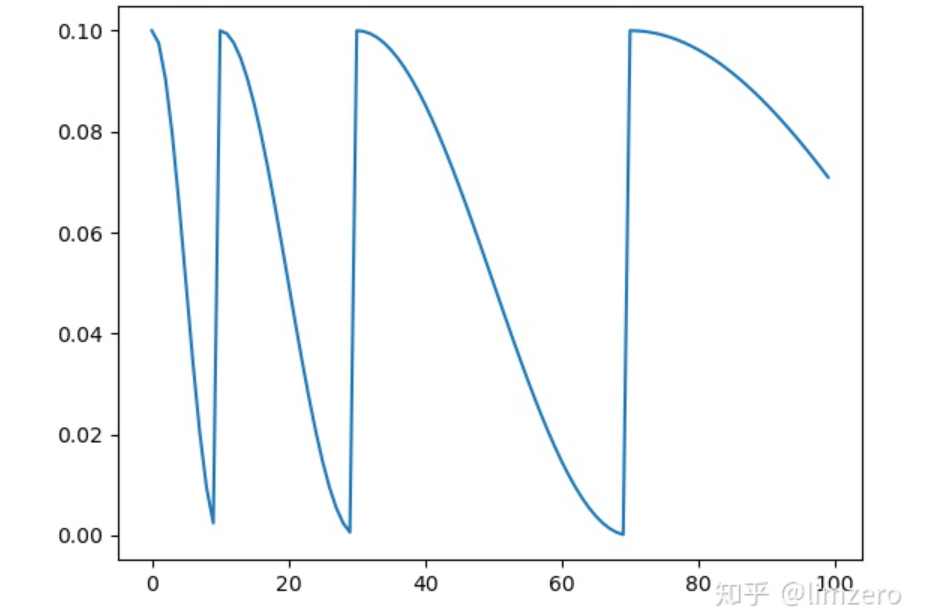
import torchfrom torch.optim.lr_scheduler import CosineAnnealingLR,CosineAnnealingWarmRestarts,StepLRimport torch.nn as nnfrom torchvision.models import resnet18import matplotlib.pyplot as plt#model=resnet18(pretrained=False)optimizer = torch.optim.SGD(model.parameters(), lr=0.1)mode='cosineAnnWarm'if mode=='cosineAnn':scheduler = CosineAnnealingLR(optimizer, T_max=5, eta_min=0)elif mode=='cosineAnnWarm':scheduler = CosineAnnealingWarmRestarts(optimizer,T_0=2,T_mult=2)'''以T_0=5, T_mult=1为例:T_0:学习率第一次回到初始值的epoch位置.T_mult:这个控制了学习率回升的速度- 如果T_mult=1,则学习率在T_0,2*T_0,3*T_0,....,i*T_0,....处回到最大值(初始学习率)- 5,10,15,20,25,.......处回到最大值- 如果T_mult>1,则学习率在T_0,(1+T_mult)*T_0,(1+T_mult+T_mult**2)*T_0,.....,(1+T_mult+T_mult**2+...+T_0**i)*T0,处回到最大值- 5,15,35,75,155,.......处回到最大值example:T_0=5, T_mult=1'''plt.figure()max_epoch=20iters=5cur_lr_list = []for epoch in range(max_epoch):print('epoch_{}'.format(epoch))for batch in range(iters):scheduler.step(epoch + batch / iters)optimizer.step()#scheduler.step()cur_lr=optimizer.param_groups[-1]['lr']cur_lr_list.append(cur_lr)print('cur_lr:',cur_lr)print('epoch_{}_end'.format(epoch))x_list = list(range(len(cur_lr_list)))plt.plot(x_list, cur_lr_list)plt.show()
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

登录查看更多
相关内容

专知会员服务
148+阅读 · 2019年12月28日
Arxiv
0+阅读 · 2021年1月27日



相关VIP内容
专知会员服务
148+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月27日