特斯拉Dojo超算架构细节首次公开!为自动驾驶「操碎了芯」

新智元报道
新智元报道
【新智元导读】在刚刚举办的硅谷芯片技术研讨会Hot Chips 34会议上,备受关注的特斯拉Dojo超算指令集结构细节史上首次被公开。
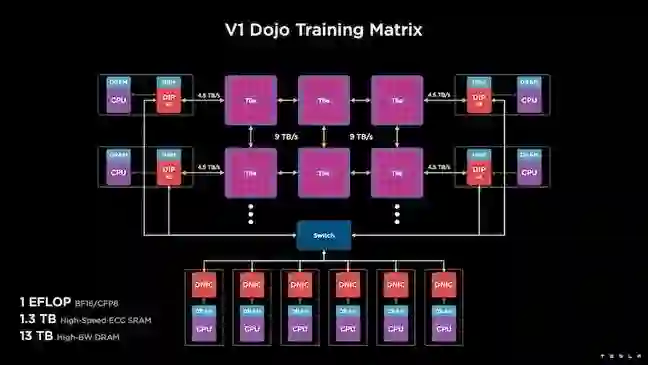
数据中心「三明治」



软件
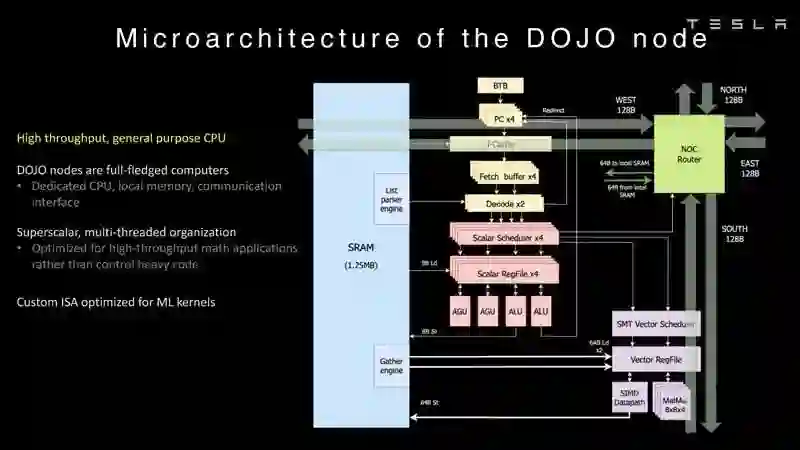
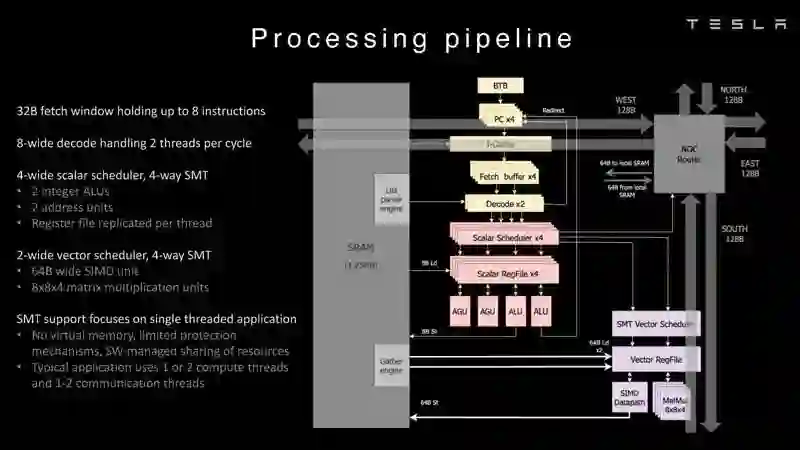
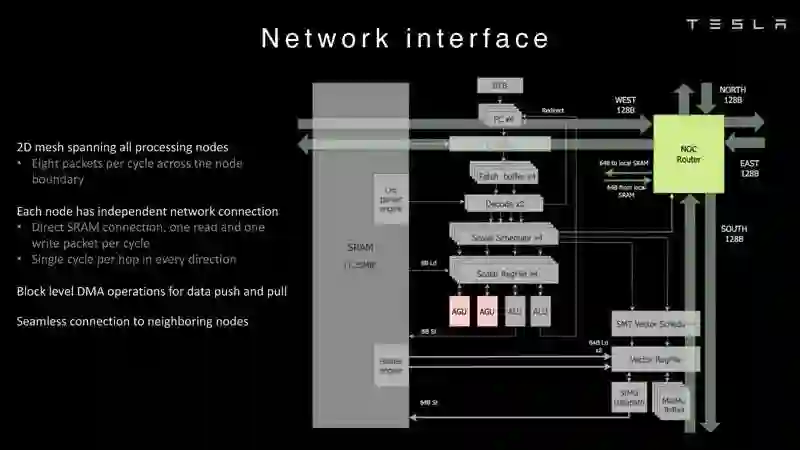
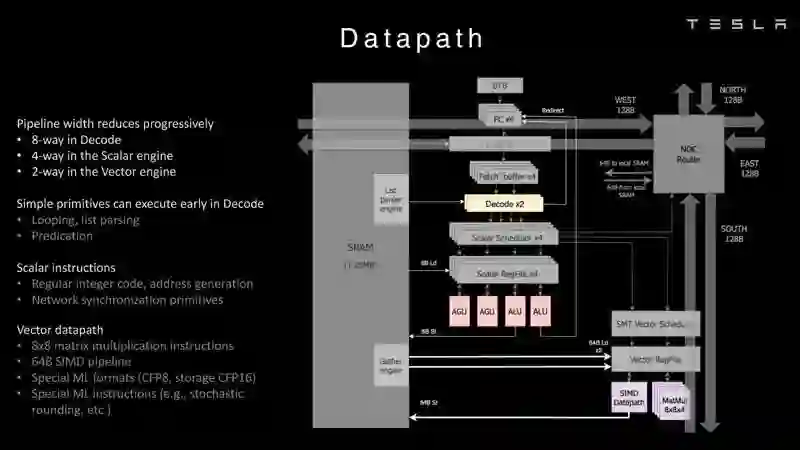
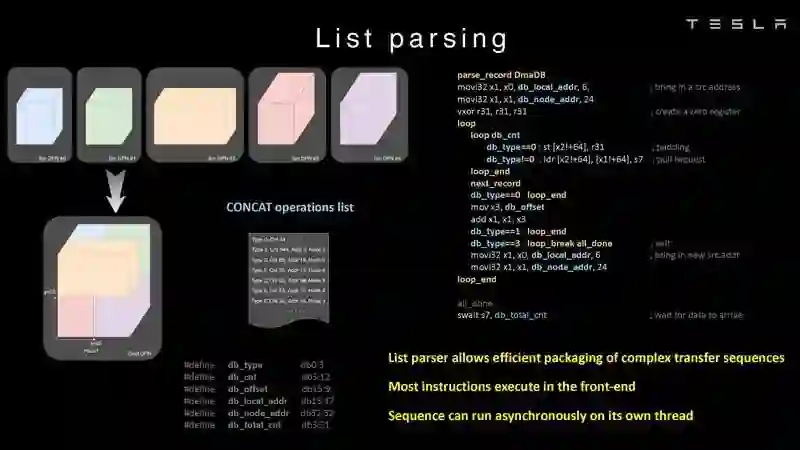
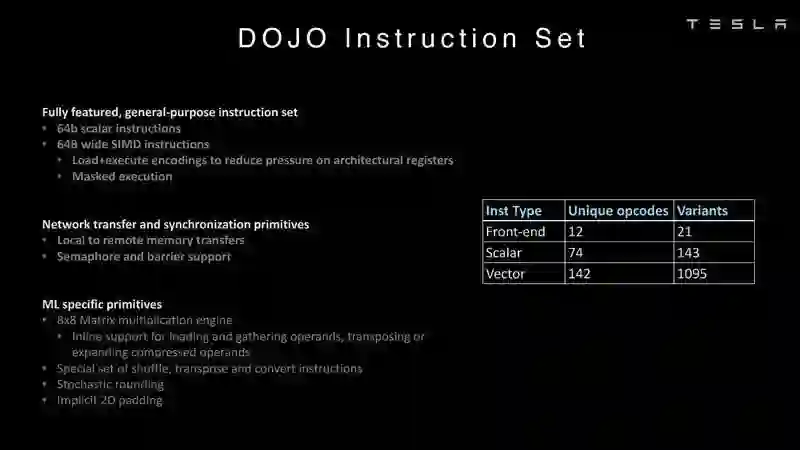
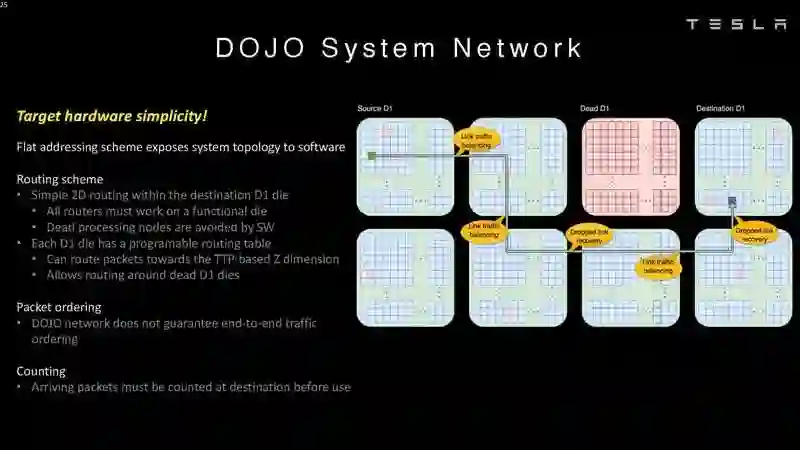
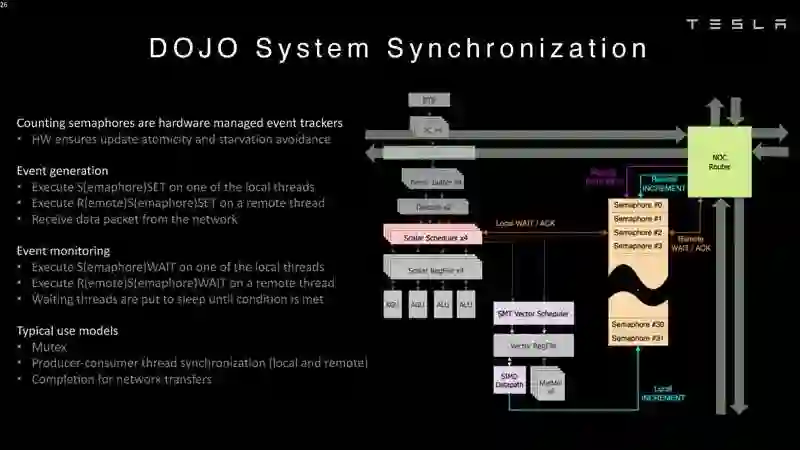
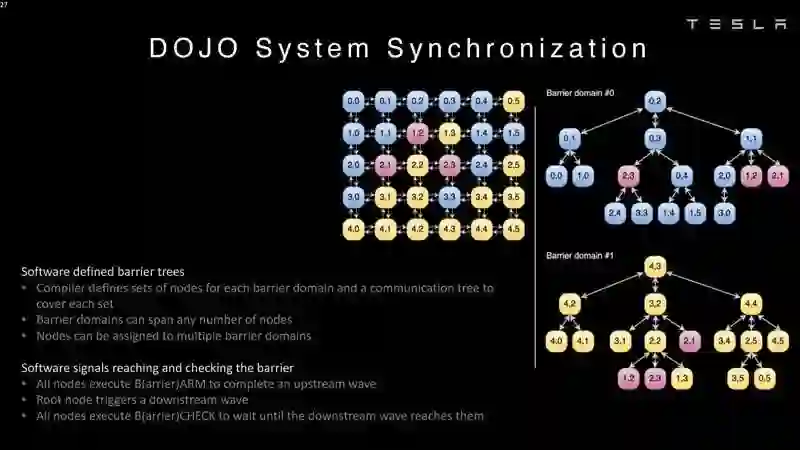
Dojo架构一览


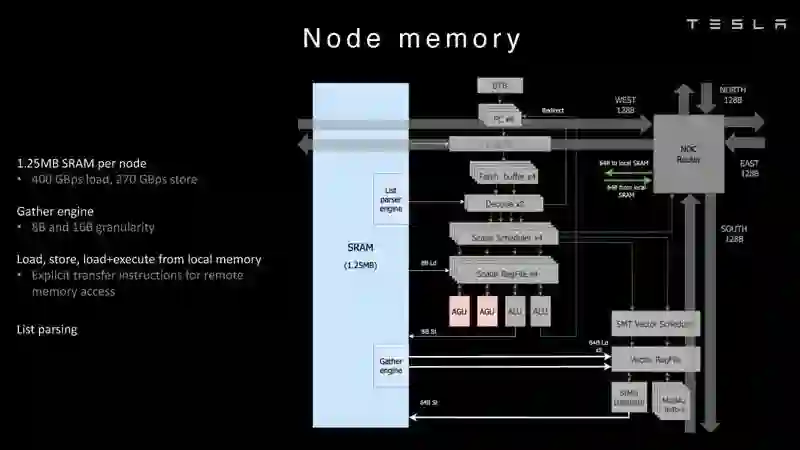
节点内存









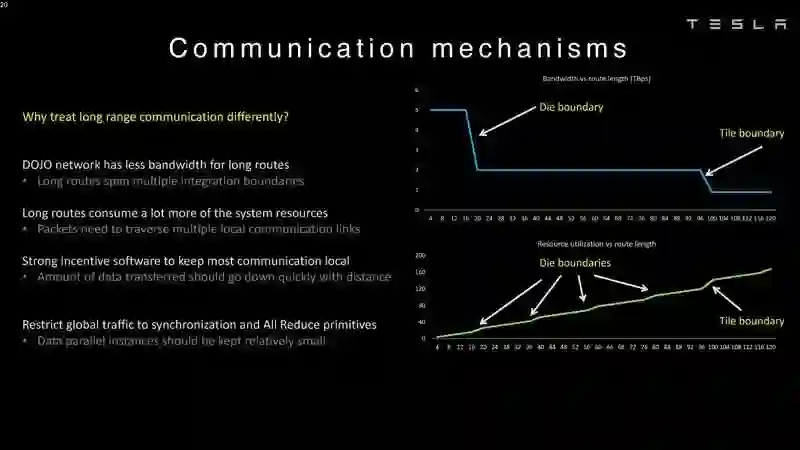

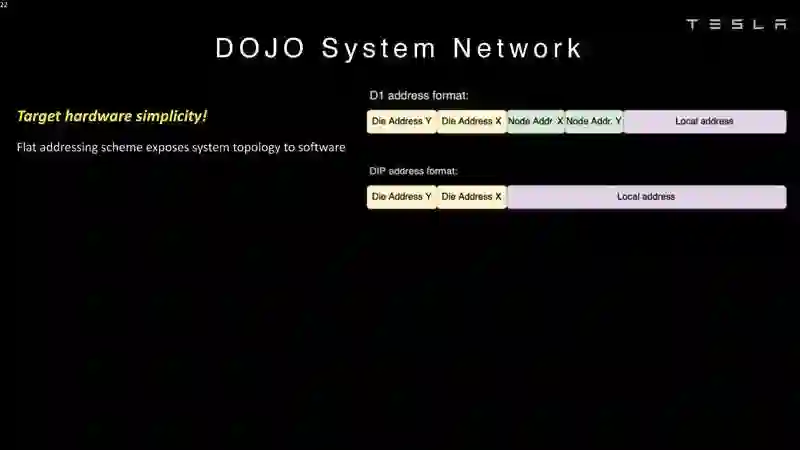
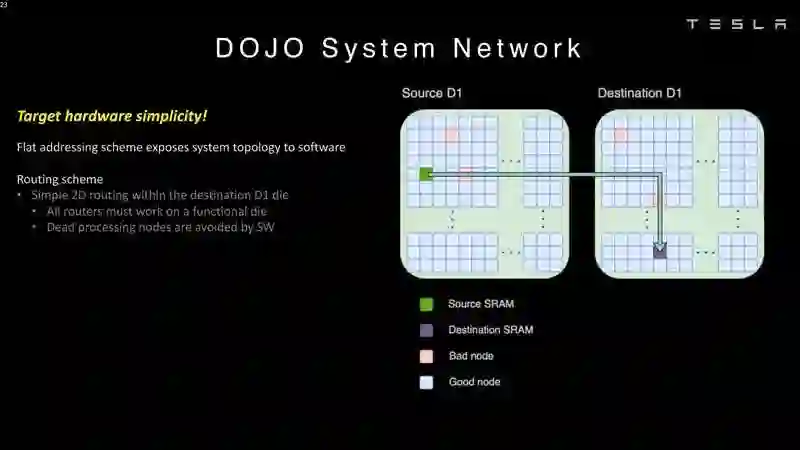
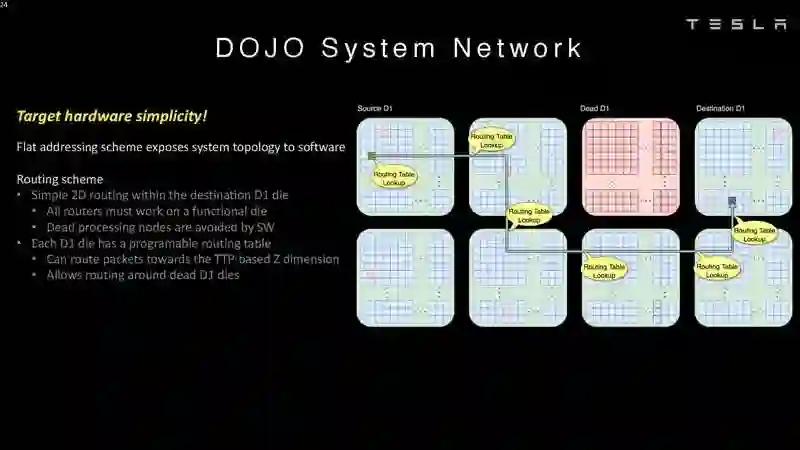



登录查看更多
相关内容

Arxiv
22+阅读 · 2021年12月22日



相关VIP内容
相关资讯
相关论文
Arxiv
22+阅读 · 2021年12月22日