GAN能合成2k高清图了!还能手动改细节 | 论文+代码,英伟达出品
夏乙 安妮 编译整理
量子位 出品 | 公众号 QbitAI
输入一张语义地图——

就能为你还原整个世界。

输入一张亲妈都认不出来的语义标注图——

为你合成一张真实的人脸。

聪明的你可能已经发现,这个名为pix2pixHD的神奇算法,可以用条件生成式对抗网络(conditional GAN),将一张语义标注的图像还原成现实世界的样子。pix2pixHD合成的图像分辨率可高达2048x1024,和CRN、pix2pix等其他图像合成工具相比可以发现,pix2pixHD的效果显然领先了好几条街!

△ pix2pixHD与pix2pix、CRN对比图
有趣的是,连李飞飞高徒、现特斯拉人工智能与自动驾驶视觉部门主管Andrej Karpathy也在Twitter上大呼“非常鹅妹子嘤!”
到底是怎么一回事?上车,我们前去看看论文。
效果惊人
有一个官方演示视频——
pix2pixHD具有通过语义标注的图像还原到现实世界的能力,并且还能根据需要轻松修改和搭配图像。在视频中可以看到,你可以一键更换车辆的颜色和型号,改变街道的类型,甚至还可以移除图像内景物甚至增加图像中的树木。
一张语义地图背后,是丰富的现实世界。
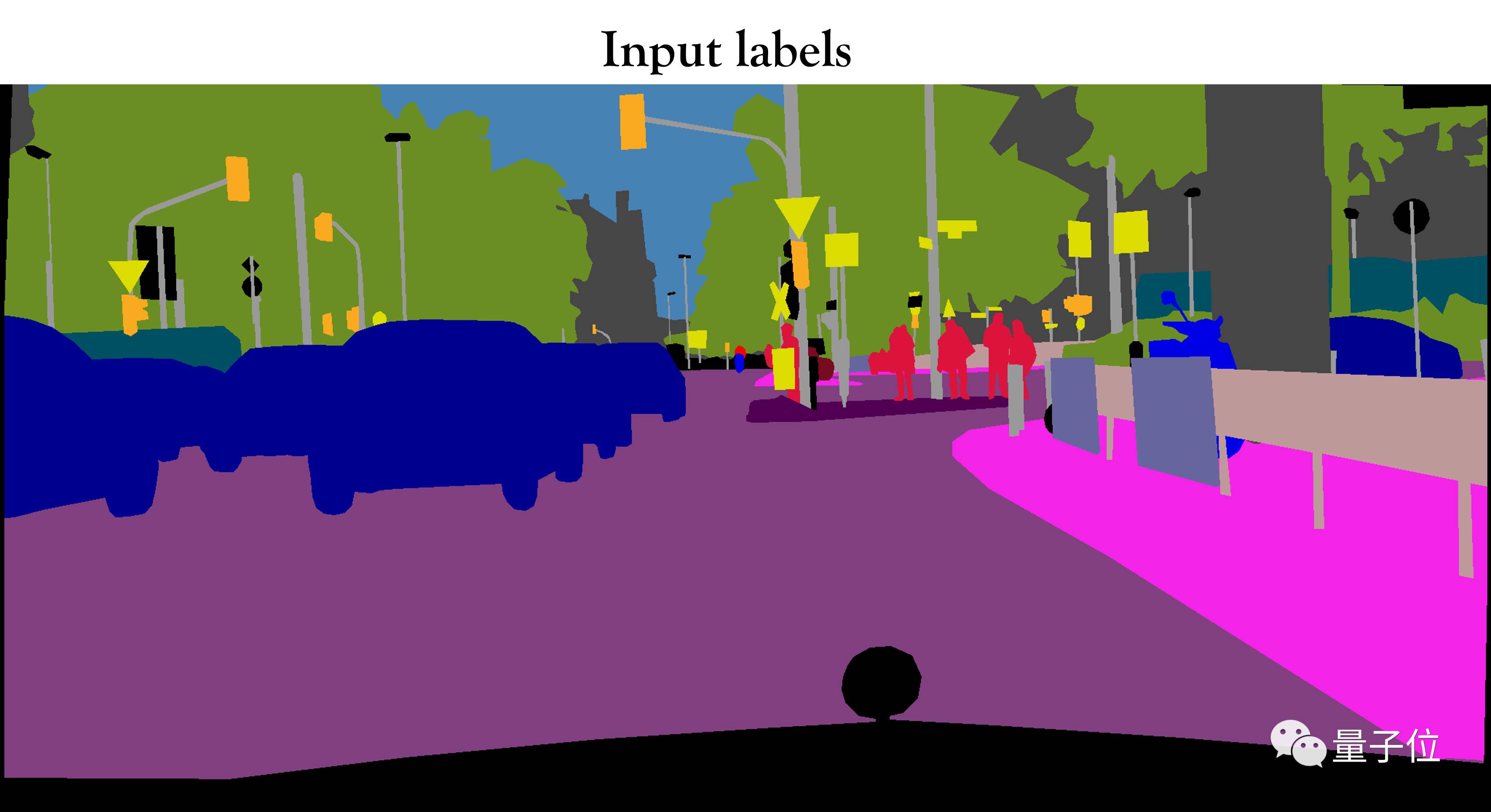

△ 输出的不同合成场景
pix2pixHD不仅可以将街景语义图转化为真实图像,还能合成人脸。
和街景类似,根据语义标注的人脸图像,我们可以选择组合人物的眼睛、眉毛和胡须等五官特征,还能在标注图上调整五官的大小。


无论是在街景中增加和减少物体,还是改变人脸的五官,都是通过一个可编辑的界面完成的。这个界面神似众多穿衣搭配的Falsh小游戏的界面,实现了“一键换车”和“一键换眼”,长胡子、改肤色,也都是点一下鼠标的事。
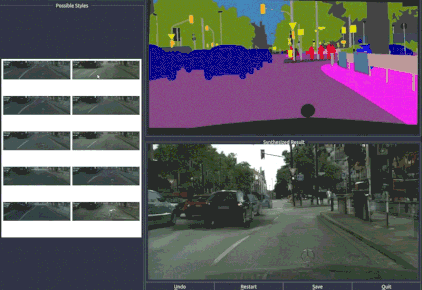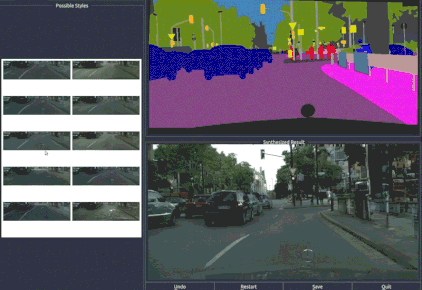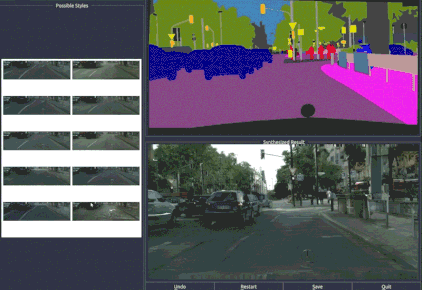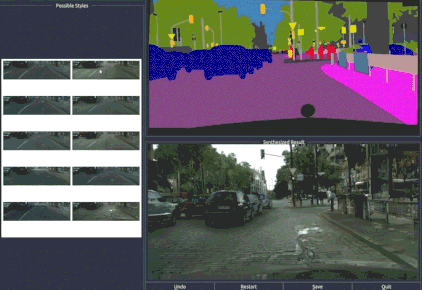
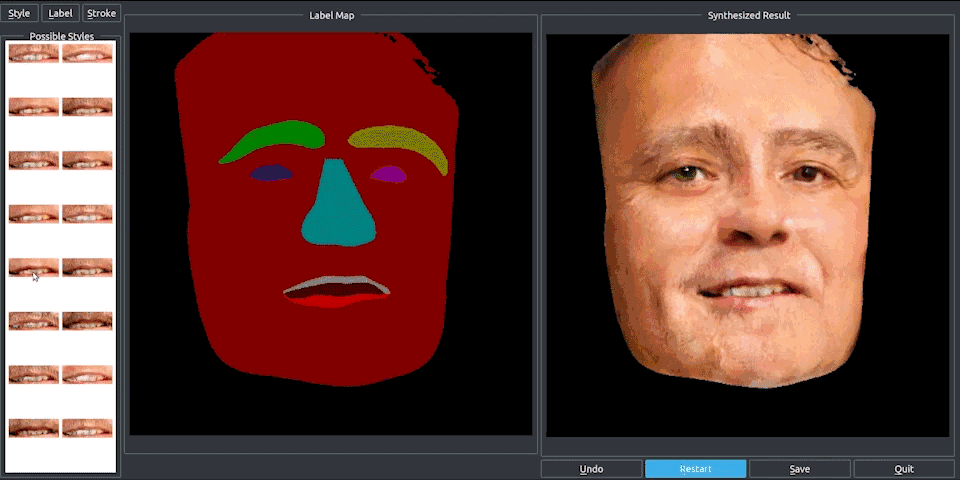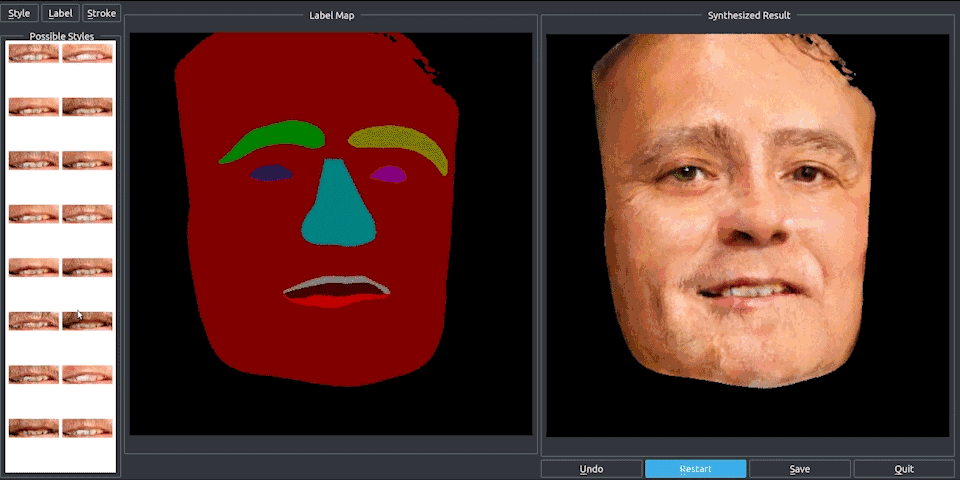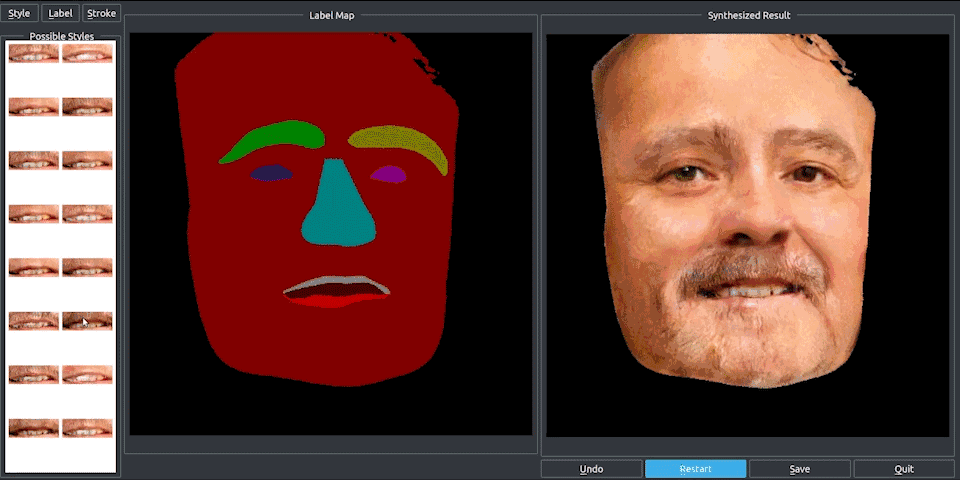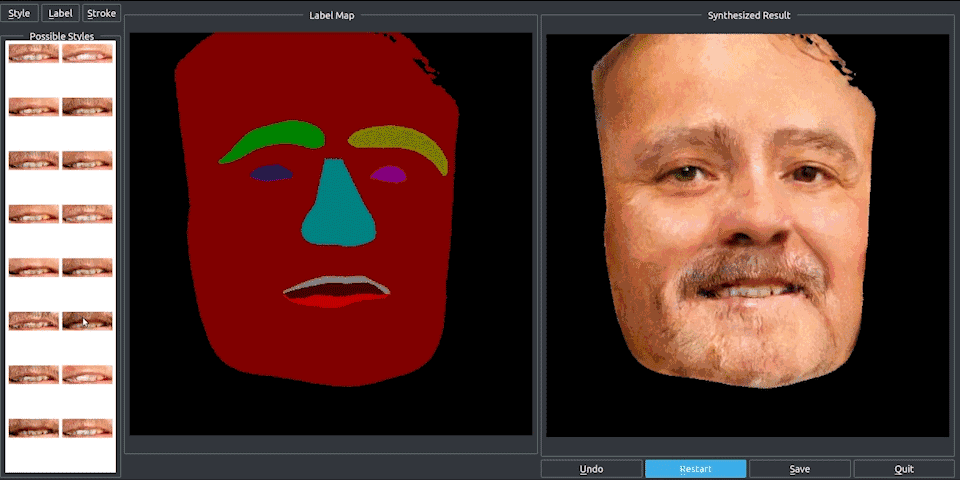
只能搞定256×256的pix2pix,怎么就变成这个“鹅妹子嘤”pix2pixHD呢?我们来看看技术细节。
网络架构
要生成高分辨率图片,直接用pix2pix的架构是肯定不行的。作者们在论文中说,他们试过了,训练不稳定,生成图片的质量也不如人意。
还是得在它的基础上,进行改造。
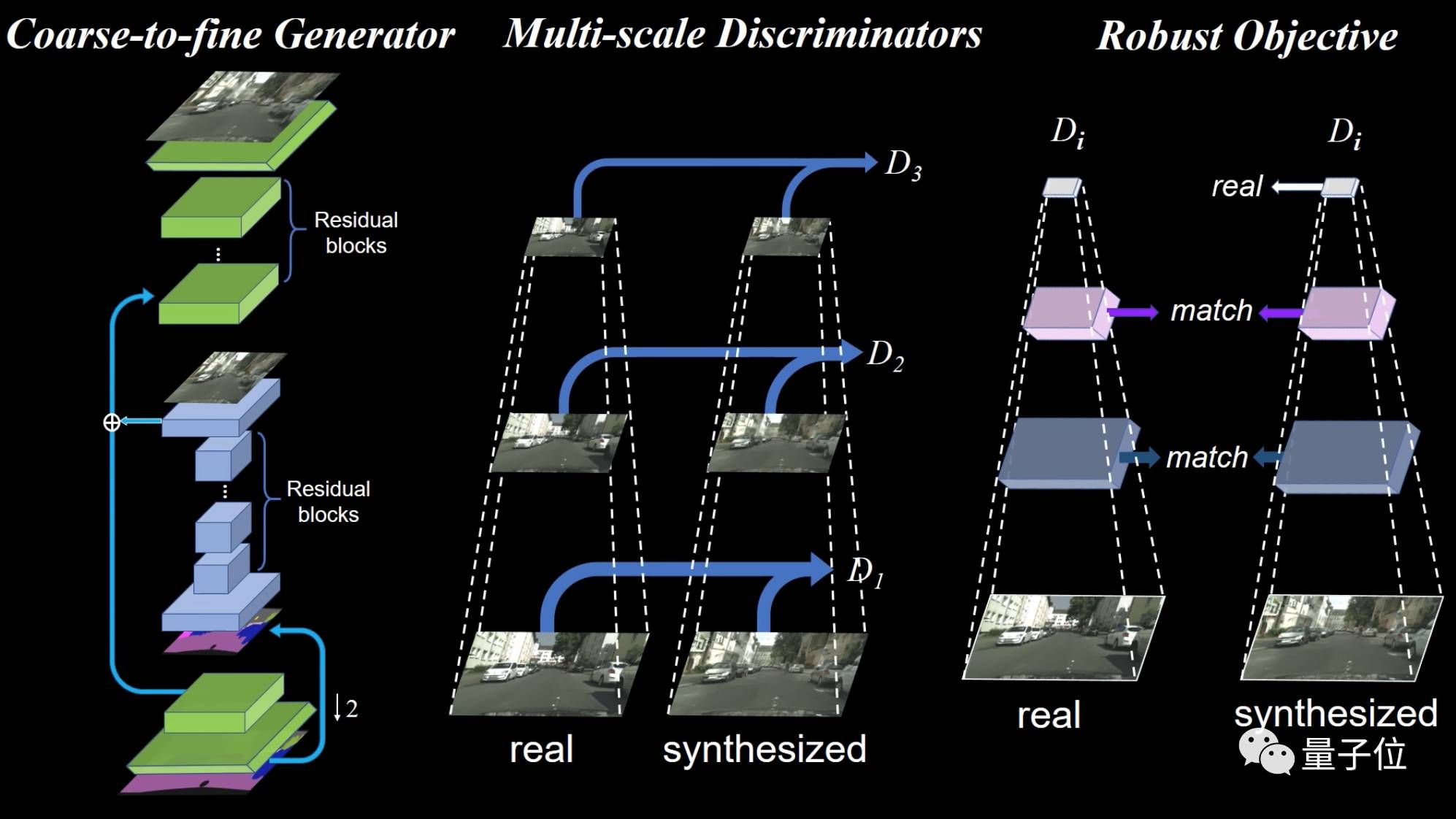
于是,他们在pix2pix的基础上,增加了一个“从糙到精生成器(coarse-to-
fine generator)”、一个多尺度鉴别器架构和一个健壮的对抗学习目标函数。
从糙到精生成器
生成器包含G1和G2两个子网络,G1是全局生成网络,G2是局部增强网络。两个子网络结合起来使用,结构如下图所示:
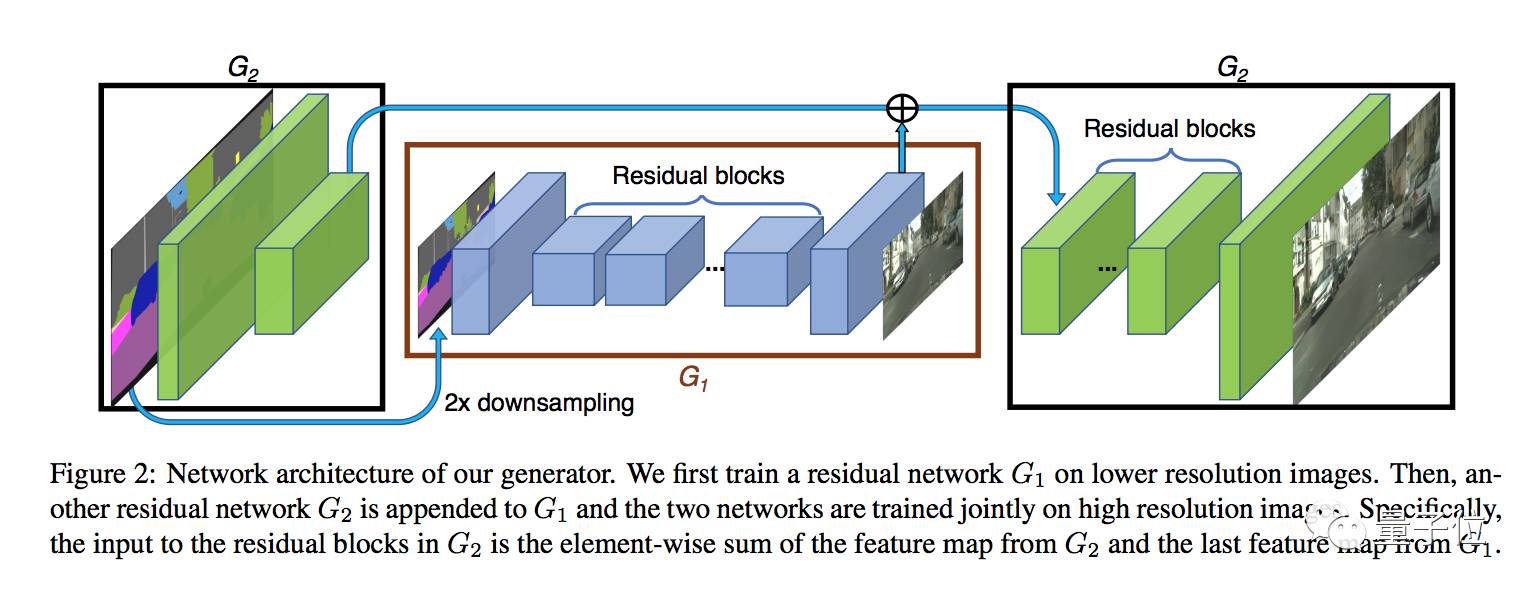
其中G1计算的分辨率是1024×512,而G2将输出图像的分辨率扩大到4倍,也就是横向纵向分别乘以2,2048×1024。如果想生成分辨率更高的图片,可以再加一个同样的局部增强网络,输出4096×2048的图。
在训练这个生成器时,先训练全局生成器,然后训练局部增强器,然后整体微调所有网络的参数。
多尺度鉴别器
高分辨率图片不仅生成起来难,让计算机鉴别真假也难。
要鉴别高分辨率图像是真实的还是合成的,就需要一个感受野很大的鉴别器,也就是说,要么用很深的网络,要么用很大的卷积核。这两种方法都会增加网络容量,导致容易过拟合,训练时也都会占用更多内存。
跟生成器抢内存?不行不行。于是这篇论文的作者们提出了一种新思路:多尺度鉴别器,也就是用3个鉴别器,来鉴别不同分辨率图片的真假。
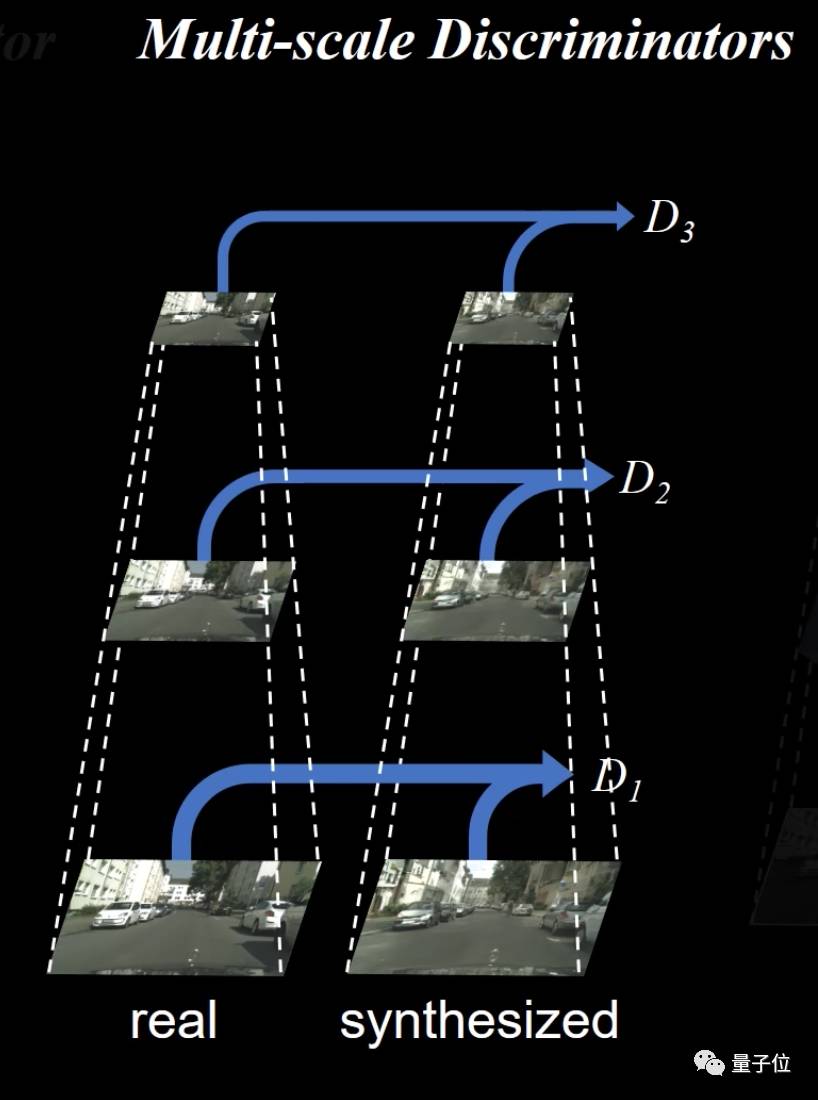
如上图所示,这三个鉴别器D1、D2和D3有着相同的网络结构,但是在不同尺寸的图像上进行训练。通过对高分辨率图像进行两次降低采样,生成3种大小的图像,然后训练鉴别器D1、D2和D3分别来辨别这3种尺寸图像的真假。
最粗糙尺度上的鉴别器感受野最大,负责让图像全局和谐,最精细尺度的鉴别器负责引导生成器生成出精致的细节。
改良损失函数
在Conditional GAN的目标函数LGAN(G, D)
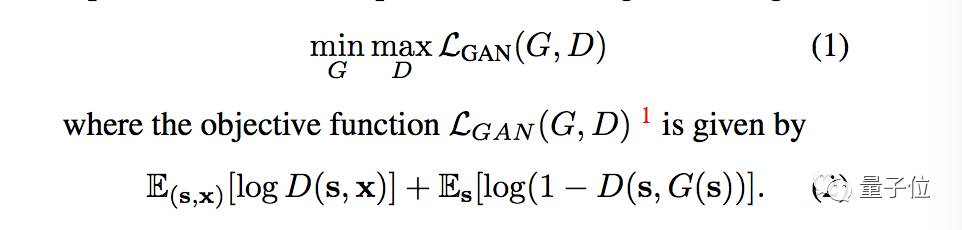
的基础上,pix2pixHD又基于鉴别器引入了一个特征匹配损失,生成器训练之后所生成的各种尺寸图像越来越自然,损失在也随之稳定。
将鉴别器Dk第i层的特征提取器表示为D(i)k,特征匹配损失函数可以表示如下:
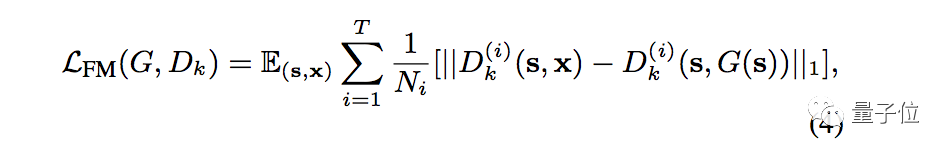
完整的目标函数如下,包含GAN损失和特征匹配损失:
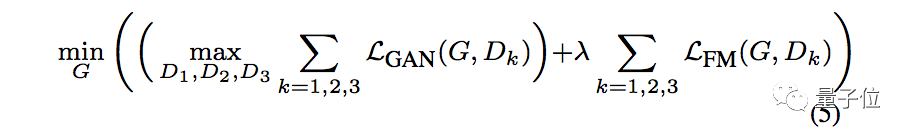
从语义标记图到合成图像
图像生成经常用到语义标记图(semantic lable maps),不过本文作者们认为,实例图(instance map)里最重要信息,并没有包含在语义标记图中。
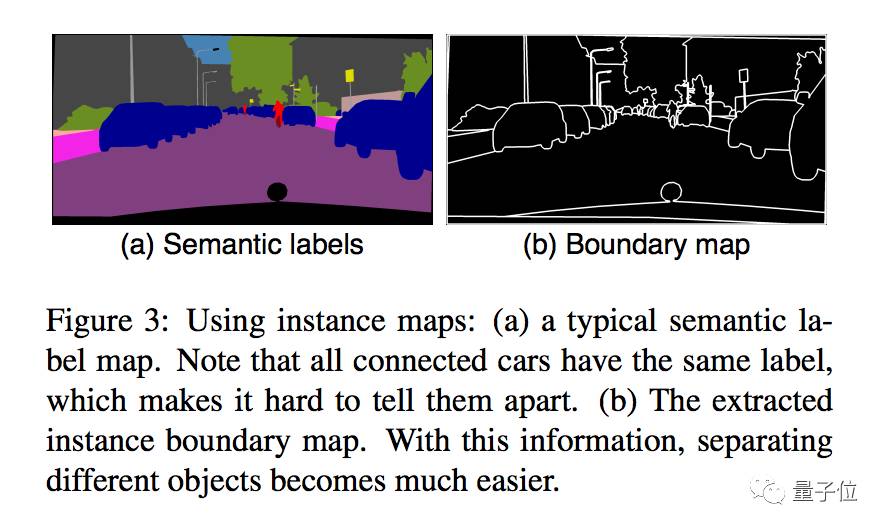
比如说上图a里,所有汽车连成一体,无法分开,这就需要先计算出如上图b所示的实例边界图(instance boundary map)。
用了实例边界图,生成的图像就不会出现下图a中两辆汽车细节不清楚的情况了。

解决了语义标记图自身的缺陷之后,还有一个问题:我们前面所说的图上每个物体都能单独控制,是怎样实现的呢?
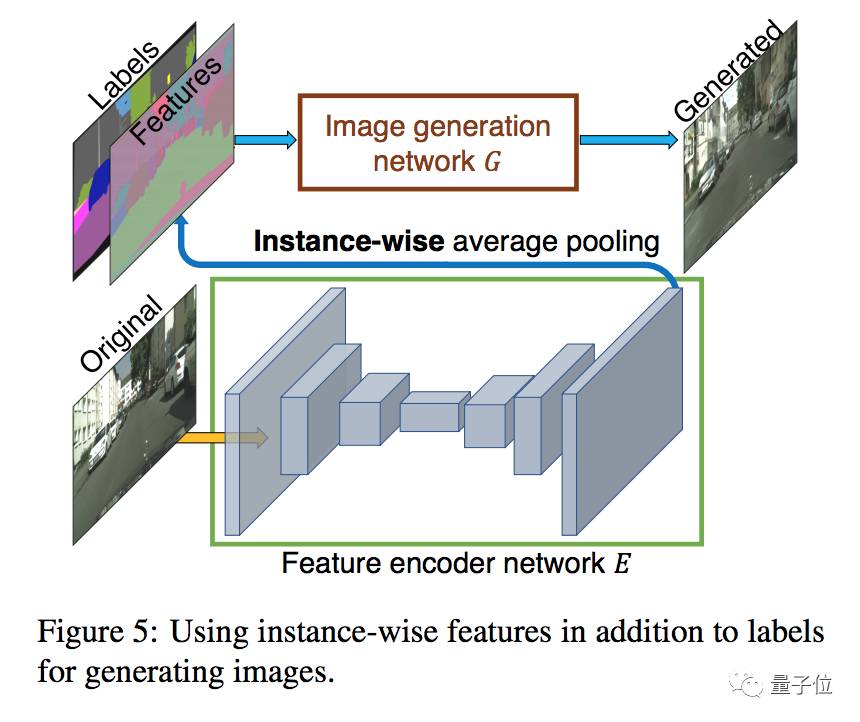
在pix2pixHD中,作者们为了生成低维特征,训练了一个编码网络E来寻找和图中每个实例的真实目标相对应的低维向量。另外,还使用了一个标准的编码器-解码器组成的编码架构。
为了确保每个实例内部的特征都协调,作者们在编码器的输出上添加了一个实例级平均池化层,来计算实例的平均特征。然后这个将这个平均特征广播到实例中的所有像素位置上,如下图所示:
广为流传的pix2pix
这个pix2pixHD,从名字到架构,都可以说是pix2pix的升级版。
这篇新论文主要来自英伟达,不过混入了一位加州大学伯克利分校的作者Jun-Yan Zhu,清华CMU伯克利系列学霸、猫奴、也是pix2pix的二作。
他所在的实验室,在图像合成和风格迁移领域贡献了大量论文,还非常良心地都开源了代码。
其中,pix2pix更是流传甚广。比如说不少广为人知的线稿变照片demo,都是基于他们的pix2pix,其中最知名&好玩的,大概要数随手就能画只猫的edges2cats。
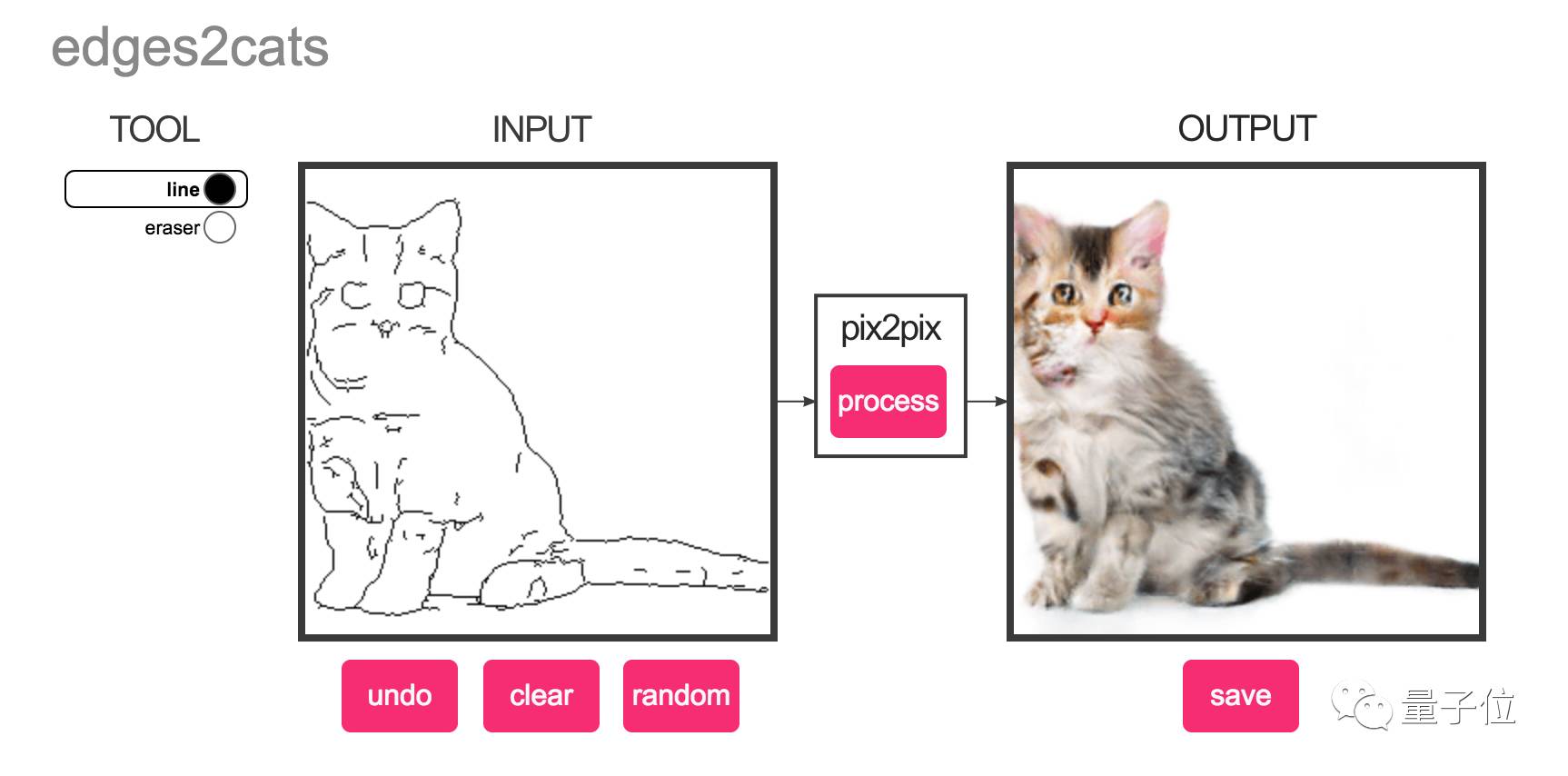
画猫的demo大受欢迎,以至于后来被网友们玩出了各种各样的新高度,量子位之前整理的灵魂画师合辑,就收集了其中不少“杰作”。
同样基于pix2pix,画鞋画包画房子的都有,这里有一系列demo,都可以上手试一试:https://affinelayer.com/pixsrv/index.html
如今,有了高清版的pix2pixHD,同样开源了代码,不知道又要玩出什么新花样了。
(☆▽☆)期待~
相关链接
pix2pixHD
主页:https://tcwang0509.github.io/pix2pixHD/
代码:https://github.com/NVIDIA/pix2pixHD
论文:https://arxiv.org/abs/1711.11585
pix2pix
主页:https://phillipi.github.io/pix2pix/
Jun-Yan Zhu
主页:http://people.eecs.berkeley.edu/~junyanz/
— 完 —
活动报名

加入社群
量子位AI社群11群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


