![]()
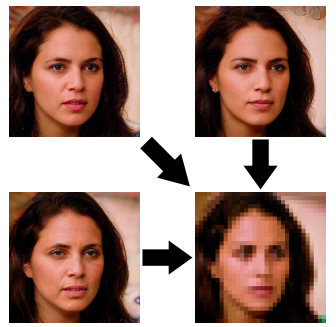
近期一篇关于图像超分辨率的论文引起了不小的争论,一切都起源于以下这张图片:
针对这张图,Yann LeCun在推特上发表了这么一句话:“当数据有偏见时,机器学习系统就变得有偏见。这个人脸上采样系统让每个人看起来都像白人,因为网络是在FlickFaceHQ数据集上预训练的,而这个数据集主要包含白人图像。”
这为LeCun招来了不少的批评,很多网友认为LeCun在提出狭隘甚至错误的观点误导人们,并纷纷提出了自己的质疑。LeCun对这些质疑一一回应,但仍得不到理解。最后LeCun不得不一条一条地解释自己的观点,才缓和了这场争论的气氛。
争论的焦点在于:AI产生偏见的原因是否只是数据集导致?算法本身的缺陷能不能成为原因?
1、只要是在有偏见数据上进行基准测试,那么这样的偏见也会反映在机器学习系统的归纳偏置上。
用有偏见的基准推进机器学习并要求工程师简单地“使用无偏见的数据重新训练模型”是没有用的。
2、我们不都知道机器学习算法带有数据偏见以外的归纳偏置吗?
3、当数据带有偏见时,机器学习系统就是有偏见的。但某些机器学习系统的偏见不是由于数据,并且构建100%无偏见的数据集在实际上是不可能的。并且我们发现很多时候,假如数据带有少量的偏见,系统会将其放大,并变得更加有偏见。
4、在完整的美国人数据集上训练:当你使用L2损失,大多数人都像白人;当你使用L1损失,大多数人都像黑人。别再觉得偏见和算法无关了。
5、承认这个结论要求极大地缩小算法的定义范围。你忽略了表征的选择、损失函数的选择、训练方法的选择以及超参数等等。
6、确实,这是个需要证明的大胆断言。AI学习过程应该是架构、数据、训练算法、损失函数等等的相互作用。
对于这些评论,LeCun澄清道,他只是认为,在大多数现代机器学习系统中,数据是主要的偏见来源。
在7年前,大多数机器学习系统使用手工特征,这是偏见的主要来源。但是现在,人们开始使用深度学习架构,很大程度上减少了源于特征选择和架构设计的偏见。所以我才认为现在数据是主要的偏见来源。我不是在讨论机器学习理论性质上的归纳偏置(这是独立于数据的)。我所讨论的是现在在机器学习系统中经常见到的偏见,这些偏见可能源于特征或数据。但如果特征是用深度学习学到的,那么偏见不应该主要存在于数据吗?”
另外,相比损失函数的选择,通过在训练过程中均衡样本的类别频率来修正这种偏见会远远更加高效。
但是也有学者认为算法和数据之间并没有清晰的分界线,均衡样本的类别频率也是一种算法的选择。偏见并非单纯来源于数据,也可能取决于研究人员本身。
对于也可能取决于“研究人员”本身这一观点,LeCun回应道:
当然。但是在logistic 回归、全连接网络或卷积网络之间进行选择,并不会导致系统固有地偏向某些类型的人。当手动设计特征时,就会引入偏见。而且,数据显然是可以有偏见的。
![]()
到了这一步,争论各方似乎都不太清楚对方在表达什么了。于是最后,LeCun在一系列的推文中清楚地表达了自己的观点:
我没有说“仅当数据有偏见时机器学习系统才有偏见”。
我只是表达了对PULSE这篇论文的看法。
机器学习系统中导致社会偏见的原因很多(这里不谈论更一般的归纳偏置):
1.如何收集数据和格式化
2.特征设计
3.模型的架构
4.目标函数
5.部署方式
当使用没有手工特征的原始输入时(如现代深度学习系统中常见的那样),特征设计引起的偏差的重要性要小得多。
如果使用别人的预训练模型作为特征提取器,特征将包含该系统的偏见。
也就是说,LeCun并非不同意质疑他的专家们的观点,只是他当时发表的观点建立在特定的条件下,而没有表述清楚。
最开始那张引起争议的图片来源于提出PULSE这一模型的论文。具体而言是有人用作者在论文中开源的代码进行了模型推理:用奥巴马的打码图像进行了试验,结果发现奥巴马被还原成了白人。
论文地址:https://arxiv.org/pdf/2003.03808.pdf
还原成白人这个结果实际上并不奇怪,因为PULSE就是建立在StyleGAN的基础上实现的,而StyleGAN所用的数据集是FFHQ,这个数据集里包含了90%以上的白人人脸。
PULSE的特点在于,可以将多个不同但相似的人脸图像聚合为同一个低分辨率图像。
论文作者之一、北卡罗来纳州达勒姆市杜克大学计算机科学教授Cynthia Rudin说:“我们已经证明人们无法从模糊的图像中进行人脸识别,因为可能性非常多。因此,缩放和增强不可能超过某个阈值水平。”
Rudin说:“过去,许多算法都试图从低分辨率恢复高分辨率图像。” 这可能是错误的方法,原始图像实际上是信息稀疏的。因此,奥巴马的打码图像还原后也不一定是奥巴马,我们会坚持认为那张图像的原型必然是奥巴马,也是由于记忆先验导致的偏见。
当然这也不能否认该模型确实存在偏见,当把模型在其他非白人面孔上进行实验时,也会出现相似的结果:
也就是说,PULSE提供的不是错误的答案,也不是故意的,但提供了有偏见的答案。
斯坦福大学研究生:社区研究者应理性争论,发言需谨慎
来自斯坦福大学的一名研究生深度关注了这次事件,并在Gradient上写下了他对此次事件的感悟。他思考的不仅仅是关于“AI偏见来源”的学术性问题,还有关于社区研究者该如何发表言论以及争论的问题。他表达的思考和观点有以下六点:
第一,除了简单的源代码之外,交互式演示很有用,因为这可以使人们轻松地与模型进行交互并指出模型存在的问题。
简单直观的演示可以引发高效的传播效应,就像成为这次事件的那张图片,基本一看就知道发生了什么事。
第二,发现了用于解决应用AI研究中的潜在偏见的最佳实践,“model card”的想法很有意义。
作为对质疑的回应,PULSE这篇论文的作者就在原文的第6节加入了对模型偏见的讨论,并在附录中加入了一张“model card”,其中写道,相比于 CelebA HQ(基于公众人物(名人)的人脸数据集),FairFace或许是评估模型时的更好选择。
第三,数据可能是机器学习系统中偏见的来源,但不是唯一的来源,此类系统可能造成的危害可能不仅仅源于有缺陷的数据集。
这是众多专家在质疑LeCun论点时提出的,同时也是LeCun在最后澄清的观点,LeCun大概也想不到自己表述不严谨的几句话会引起这么大的反响。
第四,重要的是,能够对复杂的主题进行理性的讨论。在这样的讨论中,回应专家对有关话题的批评时,注意不要情绪化。
第五,人工智能研究人员的行动有助于为学术界以外的人们设定AI使用的规范。因此,他们应该注意应该使用哪些数据集来测试其模型。并且当使用有缺陷的数据集时,他们仍可以在研究中采取具体措施以最大程度地减少这样做造成的危害。
第六,解决一个复杂的主题时,请谨记自己的措辞和信息,尤其是该领域的领导者,其声明会被很多人阅读。模棱两可的陈述可能导致人们错误地得出结论,而不是加深了解。
LeCun作为深度学习的领军者,发表的言论有很大的影响力,必须严谨自己的措辞。
https://thegradient.pub/pulse-lessons/
https://spectrum.ieee.org/tech-talk/computing/software/making-blurry-faces-photorealistic-goes-only-so-far
对于整件事情的始末,一位 Youtube 博主还专门制作了一个讲解视频供大家参考,大家可点击阅读原文观看视频。
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiangbaoshang@yanxishe.com