双十一疯狂剁手,你知道阿里是如何跟踪用户兴趣演化的吗?
机器之心发布
作者:Guorui Zhou、Na Mou、Ying Fan、Qi Pi、Weijie Bian、Chang Zhou、Xiaoqiang Zhu、Kun Gai
双十一,昨晚你是不是在疯狂剁手?在阿里这篇 AAAI 2019 论文中,研究人员提出了深度兴趣进化网络(DIEN)跟踪用户兴趣演化,带来了可观的商业价值。

论文地址:https://arxiv.org/pdf/1809.03672.pdf
在展示广告领域,CPC (cost per click) 是最常见的计费方式之一。这种计费方式下广告主会为每一次点击付费,同时系统需要预估每次展现广告的点击率来决定展示哪一个广告。点击率预估模型的性能不仅会影响平台的收入同时也会关系到用户的体验,因此点击率预估是非常核心的一项任务。展示广告场景下,点击率预估模型的目标是预估给定广告、场景、用户的情况下该用户会点击该广告的概率,即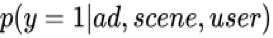
进年来随着深度学习的发展,点击率预估模型也逐渐从传统的 LR、FM、MLR[1] 等模型迁移到深度模型如 Wide&Deep[2]、DeepFM[3] 等。Wide&Deep、DeepFM 等模型都可以看做是一种 Embedding&MLP 的范式,先通过 embedding 将输入的特征 ID 等高维的 one-hot 向量投影到一个低维稠密的 embedding 空间最后 concat 成一个向量表达,再通过几层多层感知机来根据输入的向量表达预测点击率。这些模型更多是面向了通用的问题采用了普适的设计。但是在电商场景下,会更多的关注用户个性化需求同时也有更多的数据能更好的去理解用户,类似 Wide&Deep、DeepFM 的模型就会显得缺乏对应用场景的理解。
之前我们的工作深度兴趣网络 DIN[4] (Deep Interest Net) 提出在电商场景下,用户同时会存在多种多样的兴趣,同时用户在面对一个具体商品的时候只有部分和此商品相关的兴趣会影响用户的行为(点击 or 不点击等等)。DIN 提出了一个兴趣激活的模块,用于根据被预测的商品 candidate C 激活其相关的历史行为从而表达用户和此商品 C 相关的部分兴趣。相比以往的模型需要用一个固定的向量表达用户所有的兴趣,DIN 用一个根据不同被预测商品变化的向量来表达用户相关的兴趣,这样的设计降低了模型表达用户兴趣的难度。
然而 DIN 也有其不足。首先,DIN 的设计中直接将一个具体的用户行为(如点击一个具体的商品)当做了用户的兴趣。用户的兴趣其实是一个更为抽象的概念,而某个历史的行为只是抽象的兴趣一个具体的体现。比如用户购买了某款连衣裙,其背后可能是因为触发了用户对颜色、品牌、风格、当季相关的隐藏兴趣,而用户的兴趣并不仅仅局限于这一款具体的商品。因此我们设计了一个兴趣提取模块用于从用户具体的行为中抽取出每一个行为背后用户隐藏的兴趣。
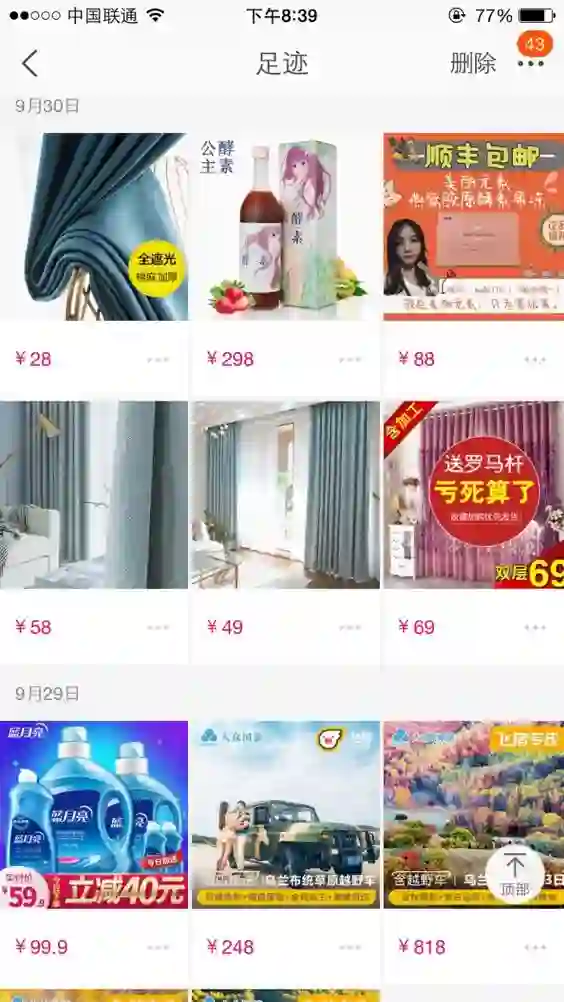
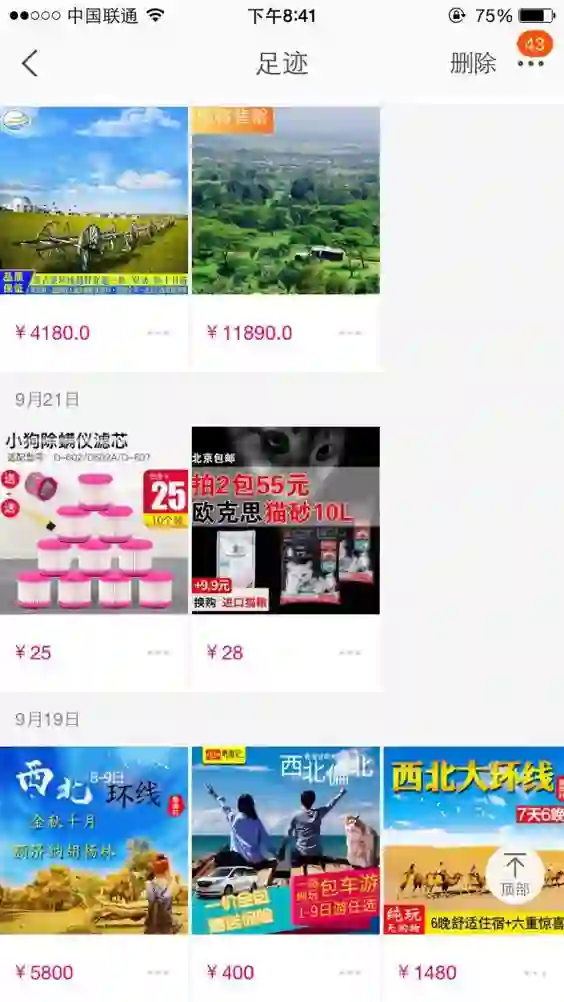
其次 DIN 缺乏对用户兴趣演化的构建。在淘宝这样综合性的电商网站场景,用户的历史行为是很丰富多样的,隐藏在这背后的用户兴趣也是多元的。假设可以用一个兴趣空间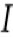
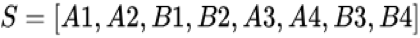
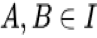
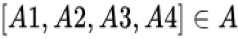
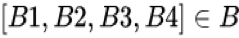

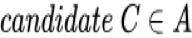
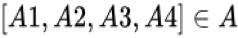
因此,兴趣演化模型由两个核心工作组成:一是兴趣提取模块用于建模隐藏在用户具体历史行为后的抽象用户兴趣;二是建模广告相关的用户兴趣的演化过程和趋势的兴趣演化模块。
兴趣演化模型
模型结构
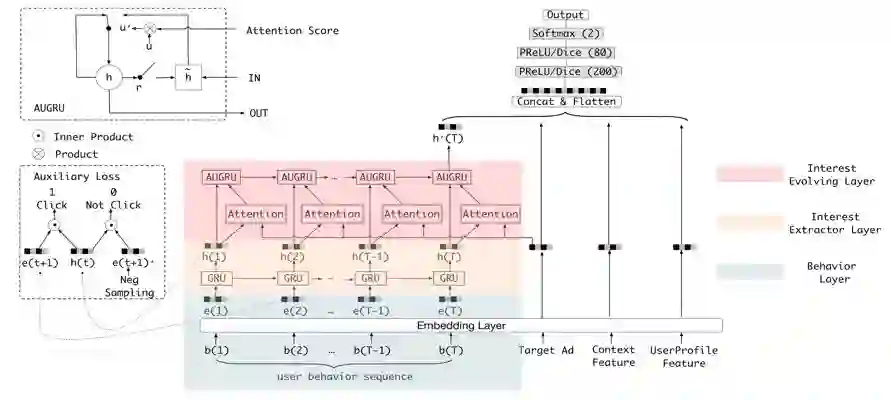
由下往上,其中广告特征、场景特征以及用户的一般画像特征都和大多数的做法一样,即取完 Embedding 后直接 concat 在一起,然后送入全连接层中。用户的历史行为则在通过 Embedding 层后需要先经过兴趣提取层获取每个行为背后的兴趣表达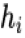

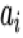

兴趣提取模块
兴趣提取模块由一层 GRU 构成,其输入是用户历史行为序列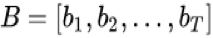
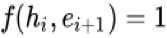
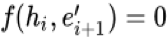




兴趣提取模块使用 GRU 的隐状态来表达用户隐藏在行为背后的兴趣,并且使用辅助 loss 来约束这个隐状态的学习(即通过给定每个隐状态以及一个行为能够准确的预测出用户是否会发生这次行为):从兴趣提取的角度来讲负采样辅助 loss 能够约束 GRU 的每个隐状态更好的表达用户此刻的兴趣。如果不加入这个 loss,所有的监督信号都源于最后的点击样本。点击率预估大多数情况下都会采用某个具体场景的样本,而希望通过某个具体场景样本的反馈信号能提取到用户每一个行为状态背后的兴趣是不现实的,辅助 loss 的设计用一种优雅的方式引入了用户的全网行为反馈信息,同时不会引入多场景之间的点击 bias 以及造成多场景耦合;从优化的角度来讲负采样辅助 loss 可以在 gru 的长序列建模中减少梯度反向传播的难度;最后负采样辅助 loss 能提供更多语义信息来帮助 Embedding 层的学习,能够学习到更好的 Embedding 表达。
兴趣演化模块
由于用户的兴趣具有多样性,用户的历史行为序列是多种兴趣的采样混合在一起的综合序列,这个序列会存在很多跳变的点(如背景所介绍),因此很难用一个序列建模的方式把这个综合序列的趋势学习好。好在 ctr 任务中需要关注的是给定一个广告用户会不会点击它,因此可以从给定广告出发,只将和广告相关的那些兴趣态连成一个子序列进行建模,这样就能建模和广告相关的兴趣的演化趋势了。
首先这里用广告
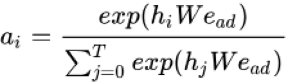
其中

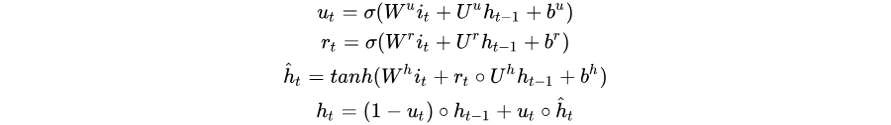
从上述公式可以看到,更新门
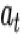
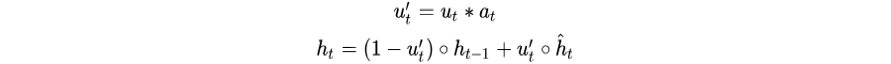
以此来达到「与广告越相关的行为更新隐状态向量越多」的目的。
实验
我们在 amazon 公开数据集(电子类和书籍类)和阿里妈妈精准展示广告的生产数据上均进行了详细的实验,验证了兴趣演化模型的有效性。用到的数据规模如下:
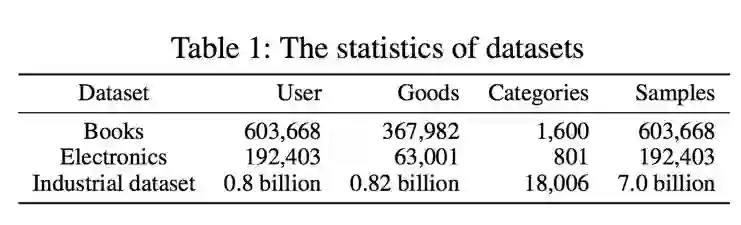
下面我们分别详细的介绍各数据集的实验细节。
公开数据集
我们使用了 amazon 公开数据集中的两个类目的数据做实验,电子类别和书籍类别。训练集和测试集按照 user 进行随机划分(即测试集的 user 不会出现在训练集中),将 user 写过的 review 按照时间进行排序,使用前
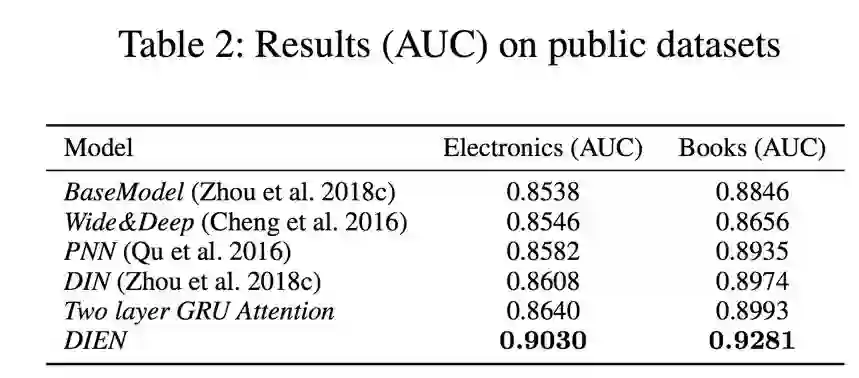
我们对比了现在主流的一些深度学习方法,发现使用我们提出的兴趣演化模型这个数据集上能够取得非常明显的优势。其中 BaseModel 是三层(200,80,2)全连接网络,其他模型都是在此基础上进行改进,全连接部分和 EmbEdding 维度(18)都是完全一致的,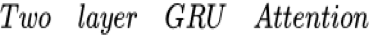
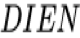
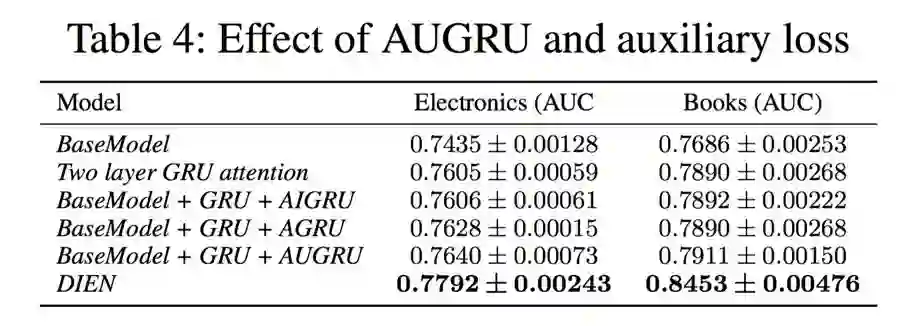
可以看到兴趣提取模块和兴趣演化模块两大贡献点在这份数据上均有显著的提升,尤其是兴趣提取模块的负采样辅助 loss 能够带来大幅的提升。
生产数据集
生产数据集我们使用 49 天的广告展示和点击样本作为训练集,接下来的一天作为测试集。使用用户前 14 天的历史行为序列作为序列建模的输入。
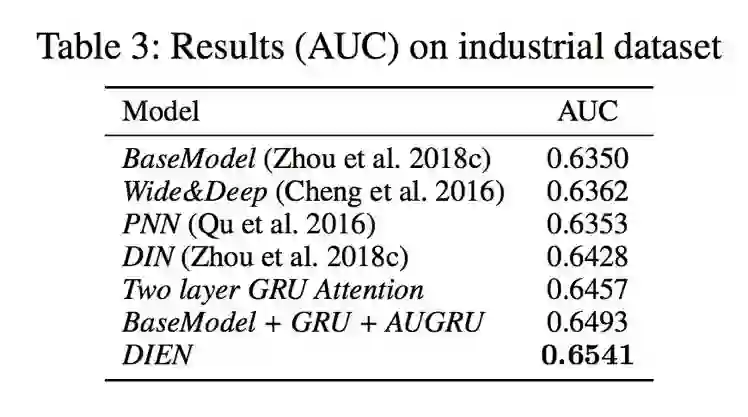
生产数据集上,用户的历史行为非常的丰富,兴趣点也比公开数据集呈现更多的多样性,因此更具有挑战性。可以看到在不使用辅助 loss 的情况下兴趣演化模型能够在 DIN 的基础上提升 7 个千分点(DIN vs BaseModel + GRU + AUGRU),增加辅助 loss 后能再额外提升 5 个千分点。实验结果证明,在用户行为丰富多样的场景,本文提出的兴趣演化模型能够通过提取和捕捉到用户的兴趣而大幅的提升 ctr 预测的准确性。
生产化
要想将兴趣演化模型实际部署到任务是艰巨的,在淘宝我们每秒钟面对的在线请求量都是相当大的,特别是双十一这种流量高峰更是会达到一个天文数字,同时我们的在线响应时间也有非常严苛的限制需要再几毫秒内做出响应。为了将兴趣演化模型 DIEN 全量部署上线,我们主要使用了以下的优化手段:首先在工程实现上,我们对模型中的计算进行充分的合并以减少 gpu 对 kernel 的调用次数;将可以并行的计算尽量的并行起来(比如 gru 的三个门可以拼在一起一次算完);不同用户的请求可以 batch 在一起充分的利用 gpu;使用 blaze 对计算进行加速等;其次在模型本身上我们也进行了一系列的工作来减小模型的 inference 压力,我们采用了之前在 AAAI2018 中提出的 Rocket Launching[5] 的方法让一个小模型在训练过程中跟随大模型学习,最终用更小的参数量拟合到和大模型差不多的效果;使用半精度压缩模型的 Embedding 参数,大大缩小模型的大小,减小在线服务的内存压力,等等。通过这些努力,我们将模型的 inference 延时从 38.2ms 压缩到 5ms,qps 达到 800+,达到上线要求。
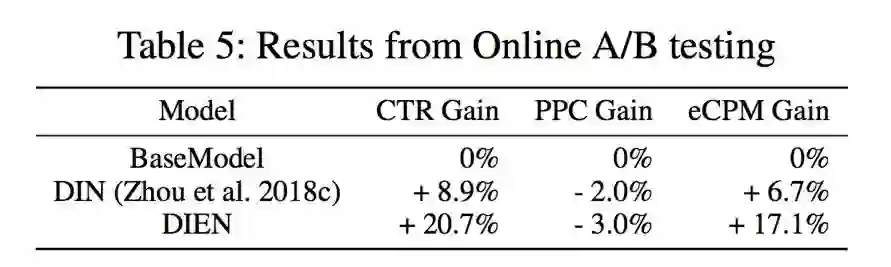
我们进行了为期一个月的在线 A/B test 对比,相比于其他模型取得了显著的线上效果:其中 DIEN 模型在全连接的 BaseModel 上取得了 20.7% 的 CTR 提升,取得了 17.1% 的 eCPM 的提升,这在工业界尤其是淘宝精准展示广告这样巨大的业务场景,是非常令人兴奋的成果,带来了可观的商业价值。目前该模型已经支持线上全流量,服务于精准广告的在线 CTR 预估任务。
[1] Kun Gai, Xiaoqiang Zhu, et al. 2017. Learning Piece-wise Linear Models fromLarge Scale Data for Ad Click Prediction. arXiv preprint arXiv:1704.05194 (2017).
[2] Cheng, H.-T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.;Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.;et al. 2016. Wide & deep learning for recommender systems.In Proceedings of the 1st Workshop on Deep Learning forRecommender Systems, 7–10. ACM.
[3] Guo, H.; Tang, R.; Ye, Y.; Li, Z.; and He, X. 2017. Deepfm:a factorization-machine based neural network for ctr predic-tion. In Proceedings of the 26th International Joint Confer-ence on Artificial Intelligence, 2782–2788.
[4] Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan,Y.; Jin, J.; Li, H.; and Gai, K. 2018c. Deep interest net-work for click-through rate prediction. In Proceedings ofthe 24th ACM SIGKDD International Conference on Knowl-edge Discovery & Data Mining, 1059–1068. ACM.
[5] Zhou, G.; Fan, Y.; Cui, R.; Bian, W.; Zhu, X.; and Gai, K.2018b. Rocket launching: A universal and efficient frame-work for training well-performing light net. In Proceedingsof the 32nd AAAI Conference on Artificial Intelligence.
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


