【SCIR Lab】事件表示学习简述
作者:哈工大SCIR 廖阔
1. 简介
事件通常指包含参与者在内的某种动作或情况的发生,或世界状态的改变。在粒度上,事件介于词与句子之间:与词相比,事件通常包含多个词,用来描述事件的发生及事件的组成要素,是一种语义更完备的文本单元;与句子相比,事件更关注对现实世界中动作或变化的描述,是对现实世界一种更细粒度的刻画。在形式上,事件的组成要素通常包括事件的触发词或类型、事件的参与者、事件发生的时间或地点等,与纯自然语言形式的文本相比,事件是现实世界中信息的一种更为结构化的表示形式。事件在粒度上与形式上的特点使得对其进行表示时面临着与其他文本单元不同的问题,由此引出了事件表示学习的概念。将结构化的事件信息表示为机器可以理解的形式对许多自然语言理解任务都十分必要,例如脚本预测与故事生成。早起的研究大多采用离散的事件表示,后随着深度学习的发展,人们开始尝试使用深度神经网络为事件学习稠密的向量表示,同时逐步有研究探索将事件内信息、事件间信息、外部知识等多种类型的信息融入事件表示中。下面我们将分别对以上研究进行介绍。
2. 离散的事件表示
3. 稠密的事件表示
基于词向量参数化加法的事件表示
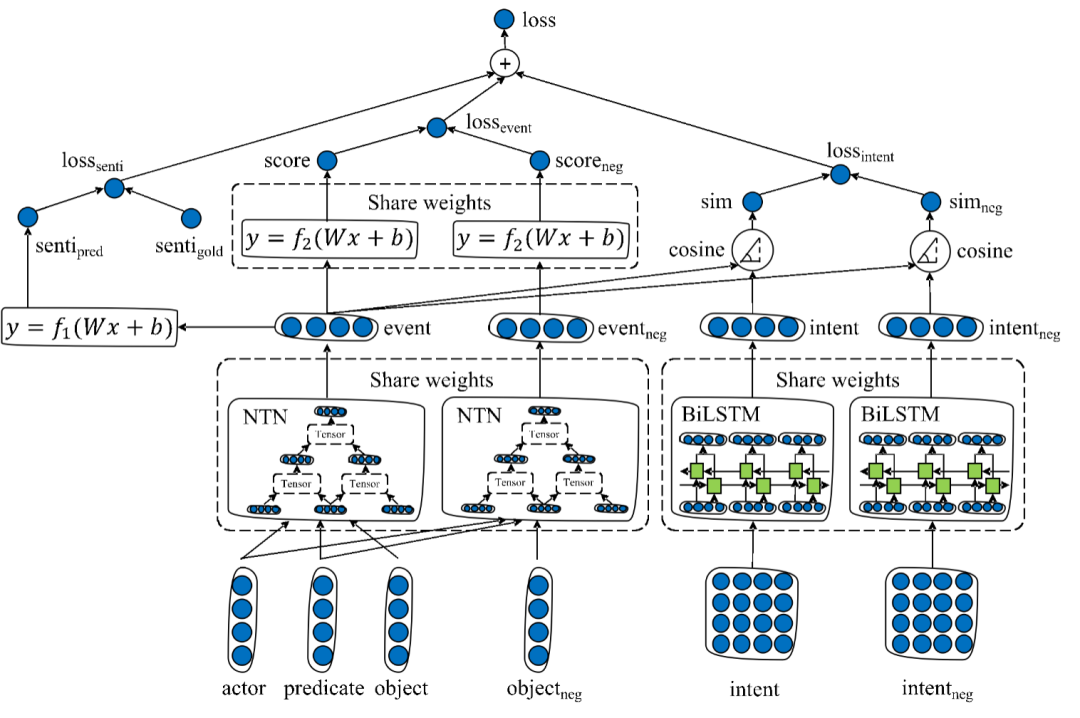
基于张量神经网络的事件表示
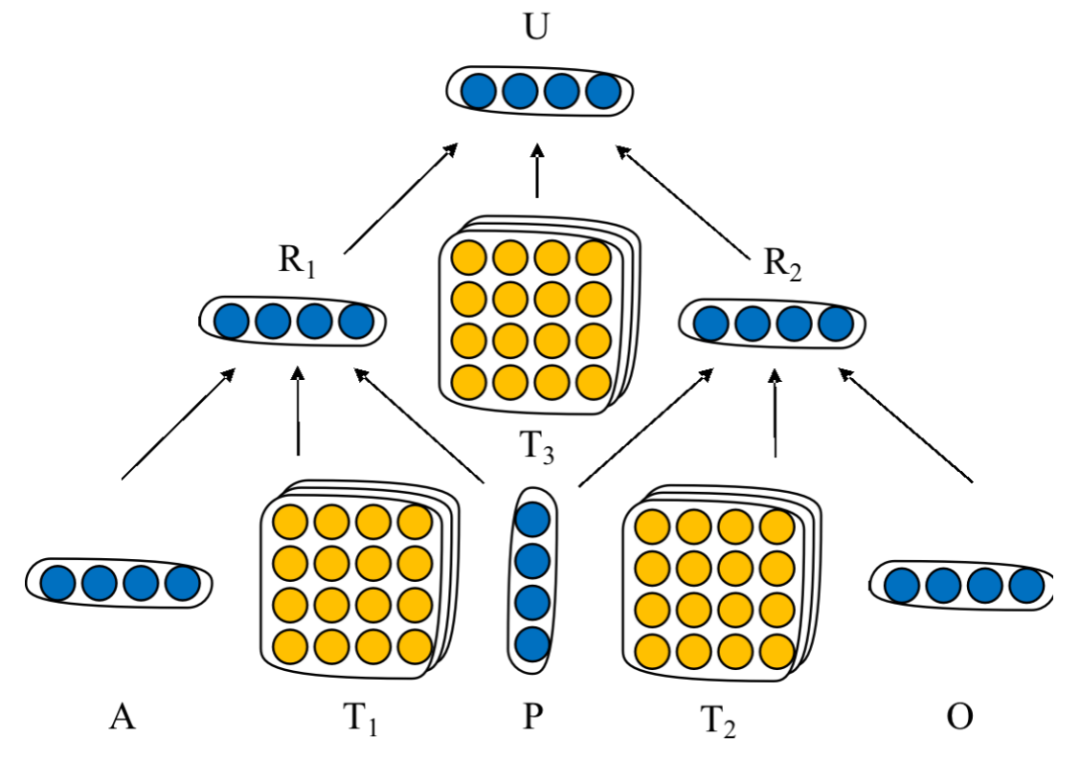
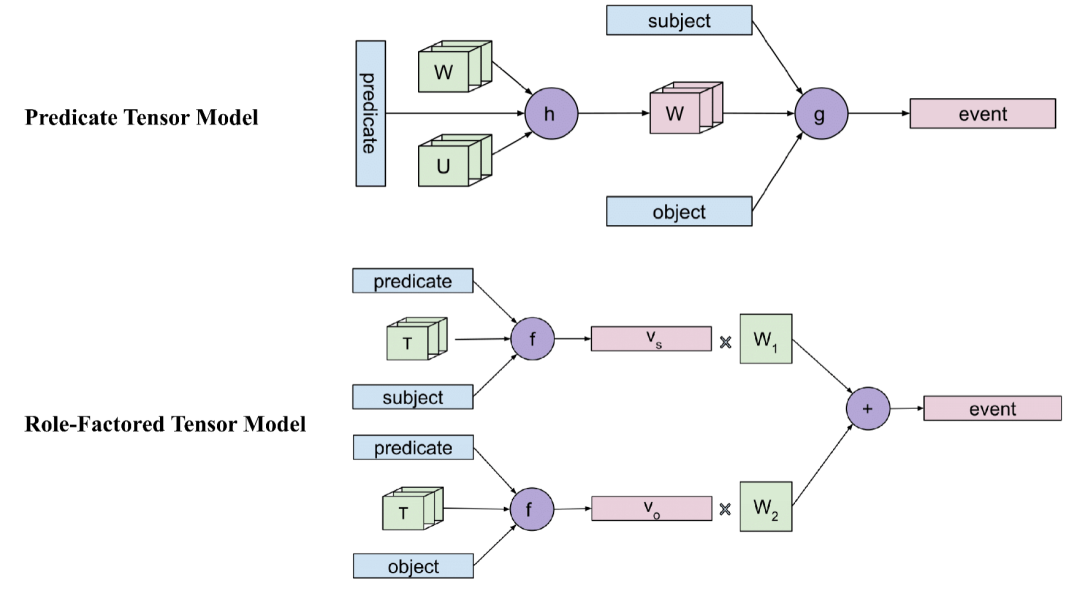
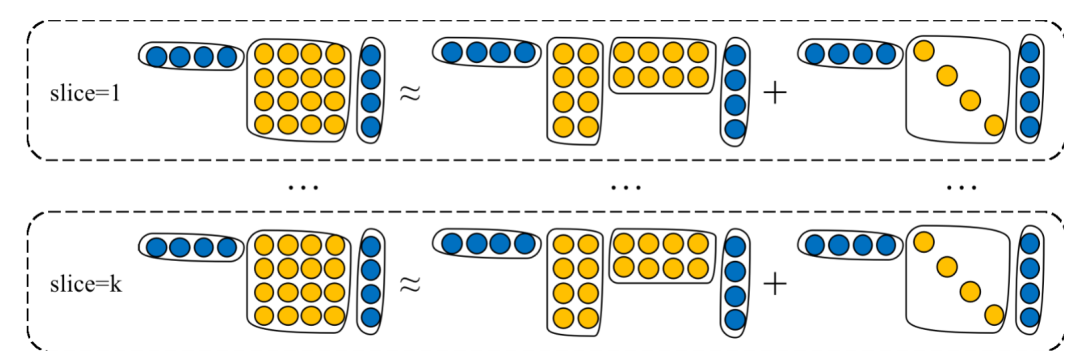
4. 事件表示的学习方法
基于事件内信息的事件表示学习
基于事件间信息的事件表示学习
融合外部知识的事件表示学习
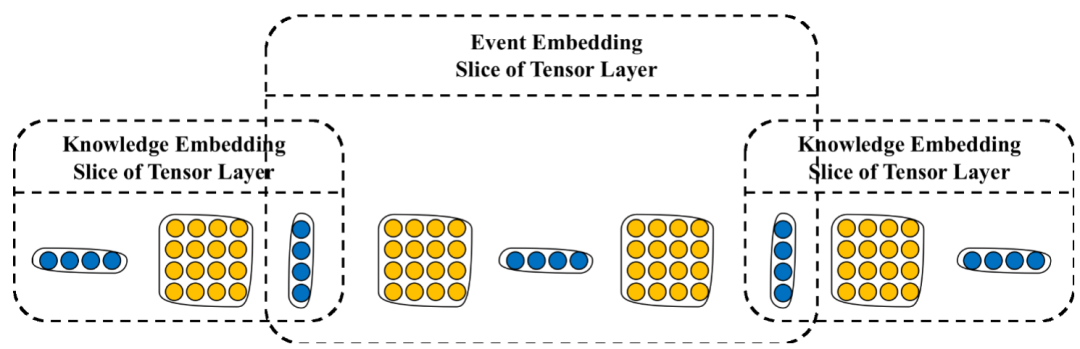
5. 总结
参考资料
KIM J. Supervenience and mind: Selected philosophical essays[M]. Cambridge University Press, 1993.
[2]RADINSKY K, DAVIDOVICH S, MARKOVITCH S. Learning causality for news events prediction[C]. Proceedings of the 21st international conference on World Wide Web. 2012: 909–918.
[3]DING X, ZHANG Y, LIU T等. Using structured events to predict stock price movement: An empirical investigation[C]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 1415–1425.
[4]CHAMBERS N, JURAFSKY D. Unsupervised learning of narrative event chains[C]. Proceedings of ACL-08: HLT. 2008: 789–797.
[5]MILLER G A. WordNet: A Lexical Database for English[J]. Communications of the ACM, 1995.
[6]SCHULER K K. VerbNet: A Broad-Coverage, Comprehensive Verb Lexicon[J]. Dissertation Abstracts International, B: Sciences and Engineering, 2005.
[7]ZHAO S, WANG Q, MASSUNG S等. Constructing and embedding abstract event causality networks from text snippets[C]. Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. 2017: 335–344.
[8]MIKOLOV T, CHEN K, CORRADO G等. Efficient estimation of word representations in vector space[C]. 1st International Conference on Learning Representations, ICLR 2013 - Workshop Track Proceedings. 2013.
[9]PENNINGTON J, SOCHER R, MANNING C D. GloVe: Global vectors for word representation[C]. EMNLP 2014 - 2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference. 2014.
[10]WEBER N, BALASUBRAMANIAN N, CHAMBERS N. Event representations with tensor-based compositions[C]. Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[11]LI Z, DING X, LIU T. Constructing narrative event evolutionary graph for script event prediction[J]. arXiv preprint arXiv:1805.05081, 2018.
[12]GRANROTH-WILDING M, CLARK S. What happens next? event prediction using a compositional neural network model[C]. Thirtieth AAAI Conference on Artificial Intelligence. 2016.
[13]LEE I-T, GOLDWASSER D. Feel: Featured event embedding learning[C]. Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[14]TILK O, DEMBERG V, SAYEED A等. Event participant modelling with neural networks[C]. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016: 171–182.
[15]HONG X, SAYEED A, DEMBERG V. Learning distributed event representations with a multi-task approach[C]. Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics. 2018: 11–21.
[16]DING X, ZHANG Y, LIU T等. Deep learning for event-driven stock prediction[C]. Twenty-fourth international joint conference on artificial intelligence. 2015.
[17]DING X, LIAO K, LIU T等. Event Representation Learning Enhanced with External Commonsense Knowledge[J]. arXiv preprint arXiv:1909.05190, 2019.
[18]FADER A, SODERLAND S, ETZIONI O. Identifying relations for Open Information Extraction[C]. EMNLP 2011 - Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference. 2011.
[19]WANG Z, ZHANG Y, CHANG C Y. Integrating order information and event relation for script event prediction[C]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 57–67.
[20]HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, MIT Press, 1997, 9(8): 1735–1780.
[21]LI Y, ZEMEL R, BROCKSCHMIDT M等. Gated graph sequence neural networks[C]. 4th International Conference on Learning Representations, ICLR 2016 - Conference Track Proceedings. 2016.
[22]DING X, ZHANG Y, LIU T等. Knowledge-driven event embedding for stock prediction[C]. COLING 2016 - 26th International Conference on Computational Linguistics, Proceedings of COLING 2016: Technical Papers. 2016.
[23]SUCHANEK F M, KASNECI G, WEIKUM G. Yago: A core of semantic knowledge[C]. 16th International World Wide Web Conference, WWW2007. 2007.
[24]BOLLACKER K, EVANS C, PARITOSH P等. Freebase: A collaboratively created graph database for structuring human knowledge[C]. Proceedings of the ACM SIGMOD International Conference on Management of Data. 2008.
[25]SAP M, LE BRAS R, ALLAWAY E等. ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019.
[26]CAMBRIA E, PORIA S, HAZARIKA D等. SenticNet 5: Discovering conceptual primitives for sentiment analysis by means of context embeddings[C]. 32nd AAAI Conference on Artificial Intelligence, AAAI 2018. 2018.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记


