如何用AI鉴别出垃圾水文?腾讯微信团队ACMMM2020《自媒体在线文章质量的认知表示学习》讲解
作者:腾讯微信团队
自媒体时代,每个公众号都在思考 一个问题: 如何让我的文章被更多人看到? 其实,除了运营之外,本章本 身的质量才是最根本的。 在这篇文章中,腾讯微信数据质量团队解读了他们的自媒 体在线文章质量自动评估算法,告诉你模型眼中的好文章都是什么样的。


据了解,这是解决自媒体在线文章质量自动评估的第一项研究工作。所提出的方法可以很好地模拟人类专家的评分要素和阅读习惯。
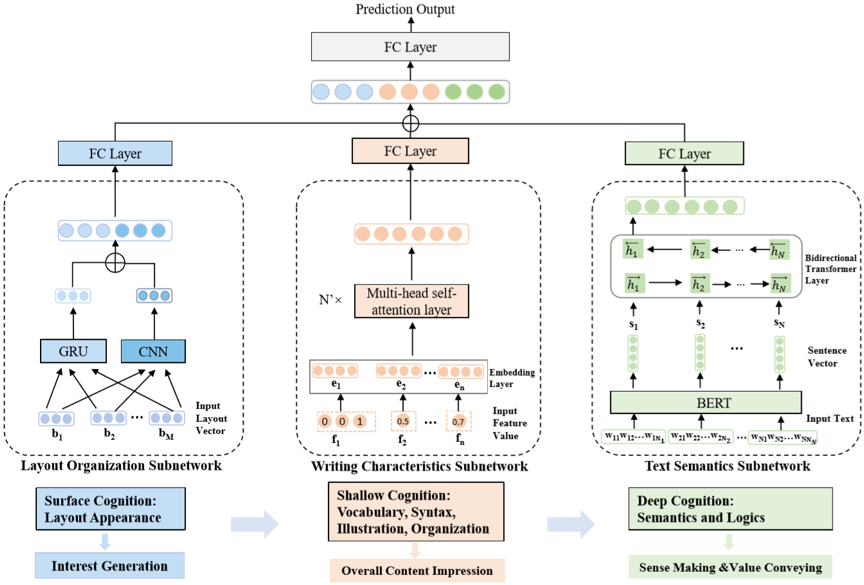
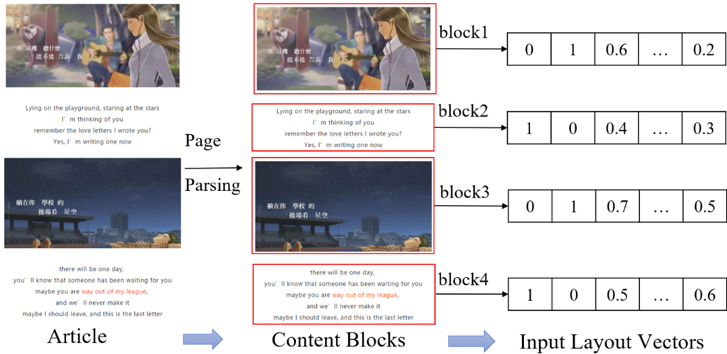
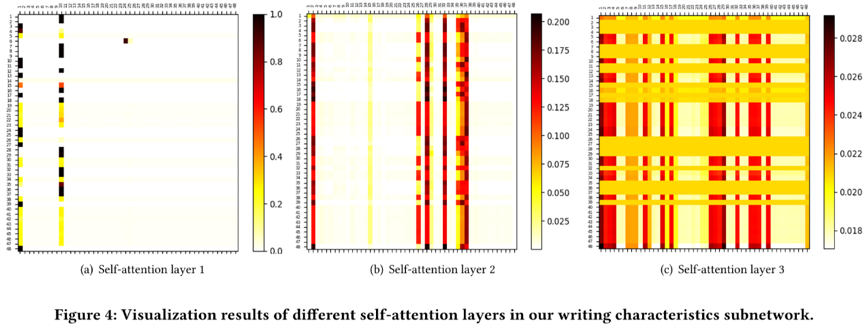
作者提出了一个结合了不同特征空间子网络的联合认知表示学习模型,并构建了自媒体在线文章质量评估的端到端框架。
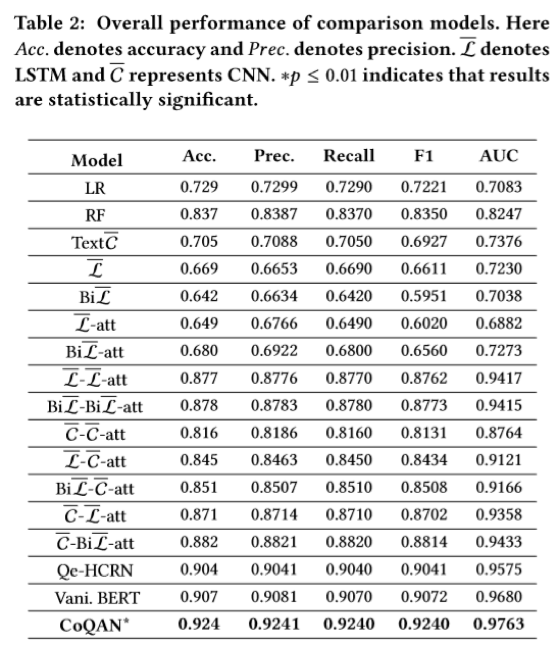
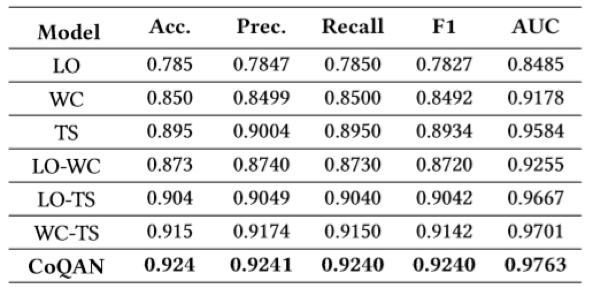
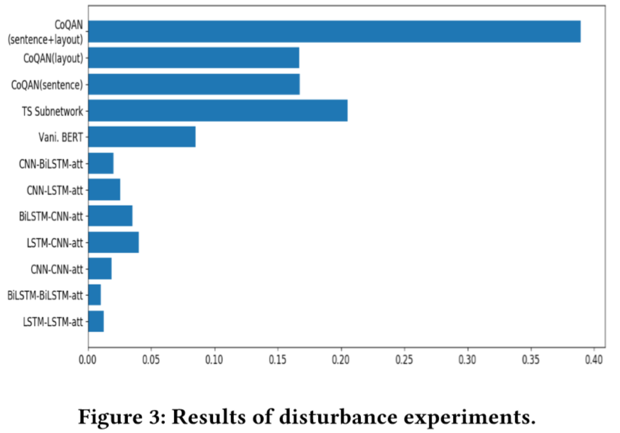
作者构造一个大规模的现实世界数据集。充分的实验结果表明,提出的模型明显优于以往的文档质量评估方法。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“COQAN” 可以获取《腾讯微信团队ACMMM2020《自媒体在线文章质量的认知表示学习》》论文专知下载链接索引


登录查看更多
相关内容
Arxiv
0+阅读 · 2020年10月12日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年10月12日