面向B端算法实时业务支撑的工程实践

一 背景
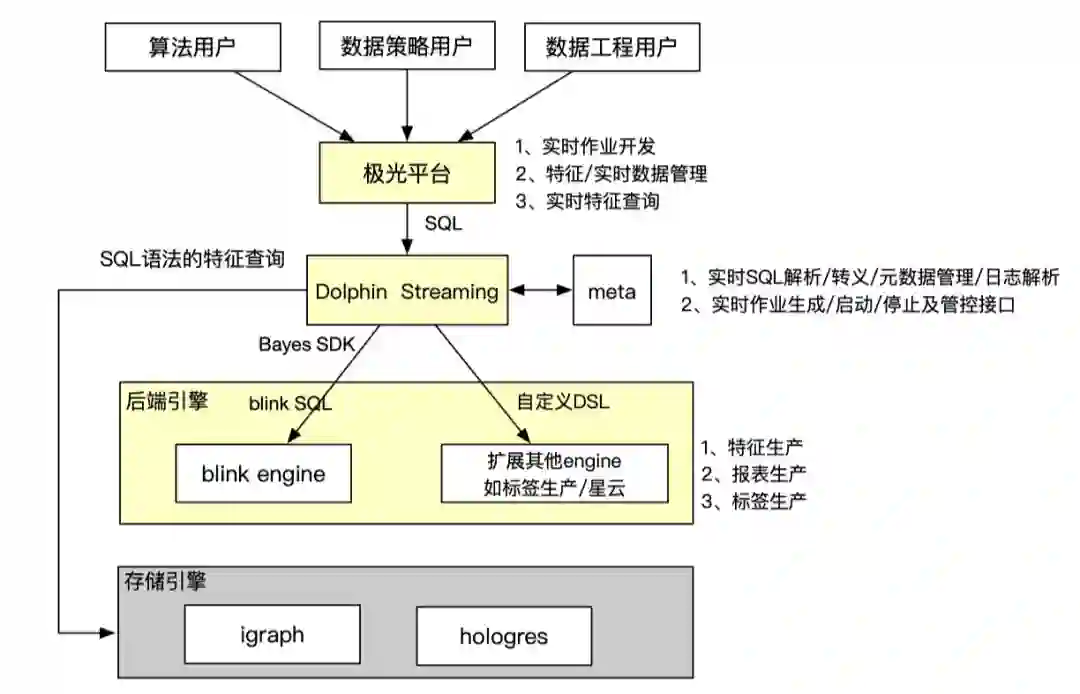
二 技术选型
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三 主要场景
1 实时replay出价策略评估
业务背景
主要挑战
-
1千万物料数据如何加载; -
高qps(100万)下线ad的实时同步;
-
业务侧解耦,整个实时job链路如何实现和业务解耦
解决方案
-
物料数据加载:直接在blink启动时加载所有数据,避免高qps情况下,对igraph访问造成压力;另外采用广播模式,仅一次加载,每个节点都可以使用,避免多次加载odps数据;
-
下线的ad信息采用分桶的方式存入到IGraph中,并周期性cache方式全量读取全量下线ad,将查询的200W+qps控制在1w左右,并使用RateLimit限流组件控制访问并发,把IGraph并发控制限制在40万左右,实现整体流量平滑;
-
整体实时工程框架,预留UDF接口,让业务侧仅实现SDK即可,其他工程性能、并发、限流、埋点等逻辑内部实现即可,支持工程框架和算法策略Replay解耦。


总结
2 实时特征
业务背景
-
获取用户近50条特征数据值,并产出到igraph中。 -
输出具有某种特征的用户id,并按照分钟时间聚合
-
输出某种特征近1小时的和、均值或者数目

主要挑战
-
实时特征数据开发数量非常多,对于每个特征数据都需要开发实时数据链路、维护,开发成本、运维成本较高,重复造轮子;
-
特征数据开发要求开发者了解:
-
数据源头,会基于事实数据源进行ETL处理; -
-
计算引擎,flink sql维护了一套自己的计算语义,需要学习了解并根据场景熟练使用; -
-
存储引擎,实时数据开发好需要落地才能服务,故需要关系存储引擎选型,例如igraph、hbase、hologres等; -
-
查询优化方法,不同存储引擎都有自己的查询客户端、使用及优化方法,故要学习不同引擎使用方法。 -
解决方案
-
不需要了解实时数据源
-
不需要了解底层存储引擎
-
只用sql就可以查询实时特征数据,不需要学习不同引擎查询方法
--- 注册输入表create table if not exists source_table_name( user_id String comment '', click String comment '', item_id String comment '', behavior_time String comment '') with ( bizType='tt', topic='topic', pk='user_id', timeColumn='behavior_time');
---- 创建输出表create table if not exists output_table_name ( user_id STRING click STRING) with ( bizType='feature', pk='user_id');
-
含义:从输入表输入的记录中,选取1个字段,按照timestamps倒序排成序列,可以配置参数按照id和timestamp去重,支持用户取top k个数据
-- 用户最近点击的50个商品idinsert into table ${output_table_name}select nickname, concat_id(true, item_id, behavior_time, 50) as rt_click_item_seqfrom ${source_table} group by user_id;
-- 1分钟内最近有特征行为用户id列表insert into table ${output_table_name}select window_start(behavior_time) as time_id, concat_id(true, user_id) as user_id_listfrom ${source_table} group by window_time(behavior_time, '1 MINUTE');
-
含义:从输入表输入的记录中,选取1个字段,对指定的时间范围进行求和、求平均值或计数
-- 每小时的点击数和曝光数insert into table ${output_table_name}select user_id, window_start(behavior_time) as time_id, sum(pv) as pv, sum(click) as clickfrom ${source_table} group by user_id,window_time(behavior_time, '1 HOUR');
总结
3 关键词批量同步
业务背景

主要挑战
-
blink批处理作业需要进行小时级调度
-
faas函数调用需要限流
解决方案
-
使用Blink UDF实现对request请求调用HSF的函数服务功能
-
blink UDF使用RateLimiter进行限流,访问函数服务的QPS可以严格被节点并行度进行控制
-
在Dataworks平台配置shell脚本,进行Bayes平台批计算任务调度
总结
四 未来展望
学习参考
对flink比较感兴趣或者是初步接触flink的同学可以参考以下内容进行一个初步学习:
Flink官方博客:https://flink.apache.org/blog/
Flink Architecture:https://flink.apache.org/flink-architecture.html
Flink技术专栏:https://blog.csdn.net/yanghua_kobe/category_6170573.html
Flink源码分析:https://medium.com/@wangwei09310931/flink-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-streamexecutionenvironment-4c1cd9695680
Flink基本组件和逻辑计划:http://chenyuzhao.me/2016/12/03/Flink%E5%9F%BA%E6%9C%AC%E7%BB%84%E4%BB%B6%E5%92%8C%E9%80%BB%E8%BE%91%E8%AE%A1%E5%88%92/
关系型数据库课程
点击阅读原文查看详情
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月19日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日