
编译 | 曾全晨 审稿 | 王建民 今天为大家介绍的是来自Daniel Shu Wei Ting的一篇综述论文。大型语言模型(LLMs)可以在没有特定训练的情况下回应各种文本查询,这引发了人们对其在医疗环境中使用的兴趣。ChatGPT是通过对LLM进行复杂的微调而生成的生成式人工智能聊天机器人,其他类似的工具也正在通过类似的开发过程中涌现出来。在这里,作者概述了像ChatGPT这样的LLM应用的开发过程,并讨论了它们在临床环境中的应用。作者考虑了LLMs的优势和局限性,以及它们在医学的临床、教育和研究工作中提高效率和效果的潜力。

大型语言模型(LLMs)是人工智能(AI)系统,它们经过数十亿字的训练,这些字来自于文章、书籍和其他基于互联网的内容。通常情况下,LLMs使用神经网络架构来利用深度学习,这种方法已经在医学领域取得了令人印象深刻的成果,用于表示文本训练数据集中单词之间的复杂关联关系。通过这个训练过程,可能是多阶段的,可能涉及不同程度的人工输入,LLMs学习了单词在语言中如何与彼此搭配使用,并可以将这些学习的模式应用于完成自然语言处理任务。自然语言处理描述了一个广泛的计算研究领域,旨在以模仿人类能力的方式促进对语言的自动分析。生成式人工智能开发者的目标是生产出可以按需创建内容的模型,并在应用程序中与自然语言处理相交。经过多年的发展,LLMs现在正出现“少样本”或“零样本”属性,这意味着它们可以在几乎没有特定微调的情况下,识别、解释和生成文本。这些少样本和零样本属性是在模型规模、数据集规模和计算资源足够大的情况下出现的。随着深度学习技术、强大的计算资源以及用于训练的大型数据集的发展,具有潜在颠覆认知工作的能力的LLM应用已经开始在各个领域中出现,包括医疗领域。
ChatGPT(OpenAI)是一种LLM聊天机器人,现在可以对多模态输入产生文本回应(之前只能接受文本输入)。它的后端LLM是GPT-3.5或GPT-4。ChatGPT的影响源于它的对话互动性以及在各个领域中的认知任务中接近人类水平或与人类水平相等的表现,包括医学。ChatGPT已经在美国医学执照考试中取得了及格级别的表现,并且有人提出LLM应用可能已经准备好在临床、教育或研究环境中使用。然而,自主部署的潜在应用和能力是有争议的:书面考试不能验证临床表现,缺乏良好的基准使得评价性能变得相当具有挑战性。目前的LLM技术很可能最有效地作为一种在密切监督下使用的工具。
LLM聊天机器人的发展
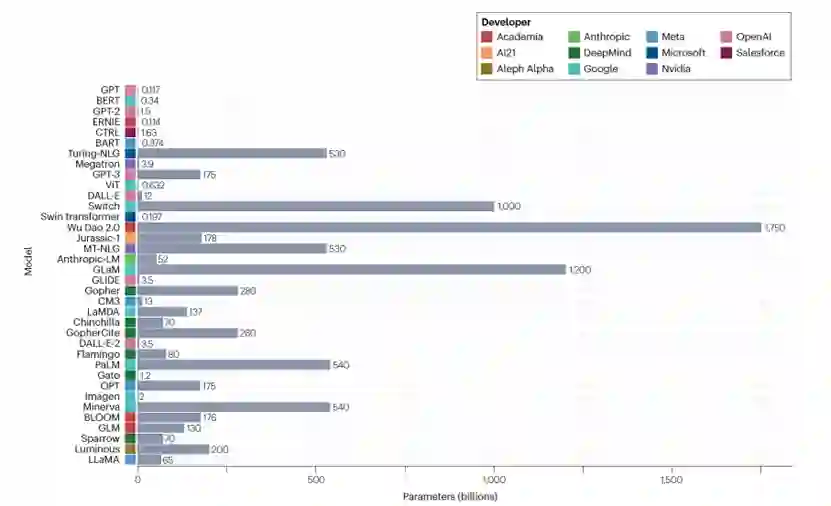
图 1
尽管LLM GPT-3.5并未展现出最多的参数数量(图1),但ChatGPT目前在医疗研究中引起了最大的关注。这得益于精细调整,特别是为了恰当地回应人类输入查询而进行的调整。首个版本的GPT(GPT-1)于2018年发布。GPT-1的训练是半监督的,包括初始的无监督预训练,用于编程单词之间在语言中的联想关系,然后是有监督的精细调整,以优化指定的自然语言处理任务的性能。GPT-2(2019年发布)拥有15亿个参数,是其前任的10倍大。其训练数据来自WebText,这是一个40 GB的数据集,来源于800多万份文档。GPT-2最初在几项自然语言处理任务中进行了评估,包括阅读理解、摘要、翻译和问题回答。在2020年,GPT-3发布了,拥有1750亿个参数,比GPT-2大100多倍。其更广泛的训练赋予了它更强的few-shot和zero-shot能力,在各种自然语言处理任务中实现了最先进的性能。训练数据集包括五个文集,共45 TB。总的来说,GPT-3的发展专门解决了前任模型的弱点,构建了迄今为止最复杂的LLM。GPT-4现已发布,并在自然语言处理以及各种专业能力测试中获得了比GPT-3更高的性能。此外,GPT-4可以接受多模态输入,其体系结构、开发和训练数据仍然保密。
从LLM到生成式聊天机器人
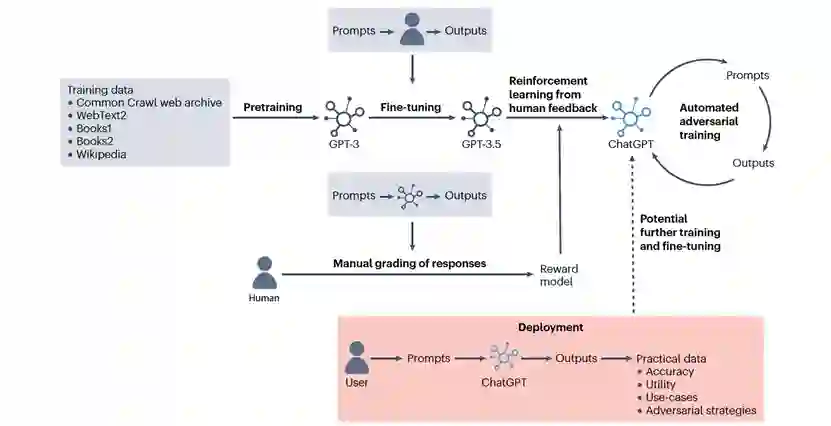
图 2
为了开发有用的应用程序,LLM需要进一步的精调,正如GPT-3.5的设计工程所示,它可以对自由文本输入提示做出适当的回应(图2)。在这里,精调包括将GPT-3暴露于由人类研究人员扮演应用程序用户和AI助手角色产生的提示和回应中,这有助于模型学习如何正确回答定制查询。接下来,使用由人类评分员根据一组查询对GPT-3.5的回应进行排名生成的数据进行“从人类反馈中的强化学习”(RLHF),以此进行强化学习。该奖励模型使得自主RLHF的规模远远超过了通过人工对每个模型回应进行评分所能达到的规模。为了提高安全性和安全性,还使用模型生成的输入查询和输出完成了进一步的自主对抗训练。ChatGPT的后端现在集成了GPT-4,新的体系结构、数据集和训练是保密的。即使在单个对话中,ChatGPT也表现出了非常出色的“学习”能力,特别是通过提供任务示例来提高性能。
除了ChatGPT之外,还有其他的LLM聊天机器人可以供临床医生和患者使用。必应的AI聊天机器人(Microsoft)可在没有ChatGPT高级访问权限的情况下访问GPT-4。Sparrow(DeepMind)是使用LLM“Chinchilla”构建的,通过利用谷歌搜索结果、人类反馈和一个包含23条明确规则的长达591个字的初始化提示来减少不准确和不适当的使用情况。BlenderBot 3(Meta Platforms)利用互联网访问来提高准确性,其在发布后可能会通过使用有机生成的数据来持续改进性能,就像ChatGPT一样(图2中的虚线箭头)。Google Bard最初是使用LaMDA构建的,但现在利用PaLM 2为基础,其在部分领域能力方面与GPT-4相媲美。
以它们当前的表现,LLMs并不能取代医生,因为在专业考试中的表现还远非完美,存在严重的不准确和不确定性问题。尽管最近报告的专业基准性能令人印象深刻,但需要具体的评估和验证来证明在任何特定背景下的有效性和实用性。从根本上讲,临床实践与正确回答考试问题并不相同,找到适当的基准来衡量LLMs的临床潜力是一个重大挑战。然而,鼓舞人心的结果表明,现有的技术已经适用于影响临床实践,并且进一步的发展可能会加速和扩大自然语言处理人工智能在医学领域的应用。
LLM的医学应用
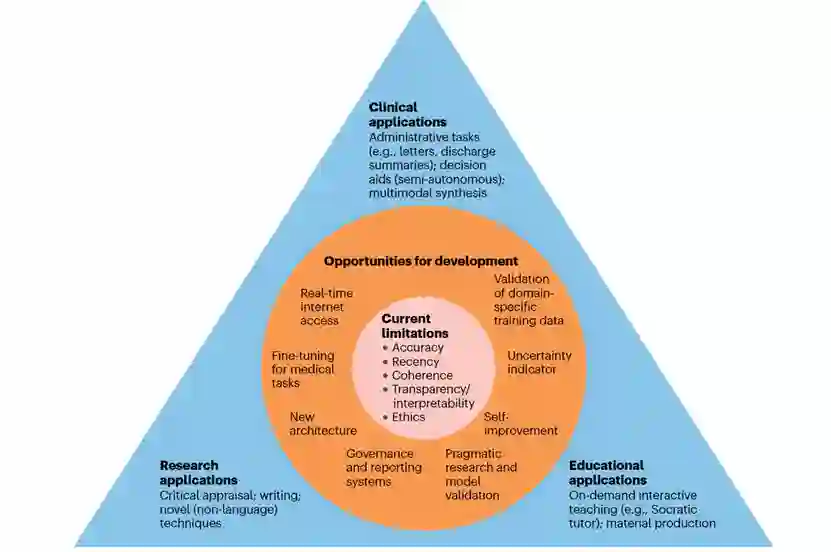
图 3
在最近几个月中,LLM(大型语言模型)技术,特别是ChatGPT,已经被广泛应用于各种场景(如图3所示)。尽管有必要进行高质量的研究来了解新技术的优势和局限性,但目前仍然缺乏经过良好设计和实用性试验,旨在评估将创新的LLM基础工具引入临床、教育或研究环境的实际效用。
ChatGPT在医学领域引起了特别的关注,因为它在美国医学许可考试中取得了及格分数,而GPT-4的表现明显优于其前身GPT-3.5。最近,Google推出的Med-PaLM 2,一种在医疗数据上进行细调的PaLM 2版本,取得了最先进的成果,达到了接近专业人类临床医生水平。当将ChatGPT对患者问题的回答与医生提供的回答进行比较时,根据医生评判的定性指标,LLM的输出在质量和共情方面更受欢迎。这导致了有人提出AI已经可以取代医生,但事实并不如此。即使在医学生考试中,其性能也远非完美,没有任何已知报告的分数接近100%。ChatGPT在医生专科考试中失败,并在回答有关心血管疾病预防的真实问题时提供不准确的信息。
ChatGPT在不需要专业知识或在用户提示中提供专业知识的任务中表现出更强的性能。这为其在实施方面提供了比临床决策辅助工具更为直接的前景。LLM能够快速吸收、概括和重新表述信息,从而减轻临床医生的行政负担。出院总结是一个有意义的例子,它涉及到对信息的解释和压缩,几乎不需要问题解决或回忆。新兴的多模态模型将扩展模型能力,并与更多的数据源兼容;甚至医生的手写字也可以自动准确地解释。
GPT-4和Med-PaLM 2在医学测试中的强劲表现表明,LLM可能是学生在这些测试中获得较低分数时有用的教学工具。GPT-4的元提示功能允许用户在对话过程中明确描述聊天机器人所扮演的期望角色;有用的示例包括“苏格拉底导师模式”,通过逐渐降低难度的问题来鼓励学生自己思考,直到学生能够解决更全面的问题。对话记录可以使人类教师监测进展并根据学生的弱点进行教学,以直接解决学生的不足之处。非盈利教育机构卡恩学院(Khan Academy)正在积极研究如何在“卡恩米格”中利用AI工具,来优化在线教学。
生成型AI LLMs的障碍

表 1
有几个问题和限制阻碍了ChatGPT和其他类似应用在临床规模上的实施(见表格1)。首先,训练数据集不足以确保生成的信息准确和有用。其中一个原因是缺乏最新性:GPT-3.5和GPT-4主要使用截至2021年9月的文本进行训练。由于研究和创新在各个领域,包括医学,都是持续不断的,缺乏更新的内容可能会加剧不准确性。在语言突然变化的情况下,问题尤为严重,例如研究人员发明新术语或更改用于描述新发现和方法的特定词汇的用法。问题还会在范式转变中出现,例如,一些被认为不可能实现的事情实际上被实现了。案例包括以前所未有的速度开发新冠病毒病2019(COVID-19)疫苗以及针对先前被认为“无法药物靶向”的目标如KRAS的抗肿瘤药物。如果类似事件超出了训练数据集的截止日期,模型无疑会对相关查询提供质量较差的响应。因此,与医疗专业人员的咨询仍然至关重要。
结论
LLMs已经彻底改变了自然语言处理领域,最先进的模型,如GPT-4和PaLM 2,现在在医学领域的人工智能创新中占据着核心地位。这项新技术在临床、教育和研究工作中充满了机遇,特别是在多模态和插件工具的新兴应用中。然而,潜在的风险引发了专家和社会的广泛关注。目前,自主部署LLM医学应用是不可行的,医疗专业人员仍将负责为患者提供最佳和人性化的护理。经过验证的应用程序可能是改善患者和医疗保健的有价值工具,但前提是解决伦理和技术问题。
参考资料 Thirunavukarasu, A.J., Ting, D.S.J., Elangovan, K. et al. Large language models in medicine. Nat Med (2023). https://doi.org/10.1038/s41591-023-02448-8

