
跨模态检索是一个经典的问题。来山东师范大学、悉尼科技大学、电子科技大学、哈尔滨工业大学(深圳)的等学者最新《跨模态检索》综述,对跨模态检索的演变进行了全面回顾,详细阐述了无监督的跨模态实值检索**、有监督的跨模态实值检索、无监督的跨模态哈希检索、有监督的跨模态哈希检索,以及特殊场景下的跨模态检索。值得关注!**

随着多模态数据呈指数型的激增,传统的单一模态检索方法难以满足用户对来自各种模态数据的需求。为了解决这个问题,跨模态检索应运而生,它允许不同模态之间的交互,促进语义匹配,并利用不同模态数据之间的互补性和一致性。尽管先前的文献对跨模态检索领域进行了回顾,但在时效性、分类和全面性方面都存在许多不足。
本文对跨模态检索的演变进行了全面回顾,从浅层统计分析技术到视觉-语言预训练模型。从基于机器学习范例、机制和模型的全面分类开始,本文深入探讨了现有跨模态检索方法的基本原理和架构。此外,还提供了关于广泛使用的基准、度量和性能的概览。最后,本文探讨了当代跨模态检索所面临的前景和挑战,同时就该领域进一步进展的可能方向进行了讨论。为了促进跨模态检索的研究,我们在https://github.com/BMC-SDNU/Cross-Modal-Retrieval开发了一个开源代码库。
https://www.zhuanzhi.ai/paper/ebe5397ee21e742999b111b80161ae3b

在近几十年里,互联网、智能设备和传感器经历了显著的扩展,导致了多模态数据的指数级增长。这包括图像、文本、音频和视频等各种形式,通常用于描述相同的事件或主题。这种多样性的增长导致用户对跨不同模态的数据访问的需求增加,以获得全面的见解[1]。然而,传统的检索方法[2]、[3]主要关注单一模态,在满足这些需求上因异构模态之间的差距而显得不足。因此,有必要提出一种检索策略,这种策略能够促进信息源之间的互动,并支持跨模态的异构搜索。如图1所示,跨模态检索作为一个补救措施浮现出来,通过促进语义对齐和利用多模态数据之间的协同作用,增强了用户体验和信息吸收。它使用户能够迅速发现引人入胜的信息,从不同的角度获得见解,并精确地找出潜在的相关性和模式。
跨模态检索在学术界和工业界都受到了极大的关注和探索,导致在这个动态研究领域出现了大量基于学习的方法。我们可以追溯到2010年左右,当时统计分析技术占据主导地位,从多模态数据中提取特征并将其映射到一个共享空间进行相关性评估[4]。自2014年以来,深度学习技术在跨模态检索中的崛起已经产生了深远的影响,利用深度神经网络的强大能力自主地从多模态数据中提取高级特征表示[5]。近年来,一系列的跨模态检索方法已经被定制应用于多种开放场景,充分利用了视觉-语言预训练模型的潜力[6]。这些进展显著地加强了跨模态检索系统的精度、稳健性和可扩展性,通过引入复杂的学习模型和培训策略。展望未来,跨模态检索仍然是一个充满挑战但很有前景的研究领域,预计将涵盖更广泛的数据模态,克服复杂的开放检索场景,并需要高效的检索模型。
为了使研究者深刻了解跨模态检索的研究格局、实际意义和未来前景,本文提供了对现有代表性方法、技术和框架的有条理的概述和分析。它还深入探讨了实验基准、度量和性能,为未来的研究方向提供了新颖的观点和建议。尽管先前的文献[7]–[10]涉及了跨模态检索,但在时效性、分类、全面性等方面都存在很多不足。具体来说,文献[7]、[8]为跨模态检索的早期阶段提供了见解,但由于时间上的差距,它们对代表性方法和当代进展的描述受到了阻碍。在过去五年中开发的有影响力的跨模态检索技术,这些技术对该领域产生了巨大的影响,尚未被包括在内。值得注意的是,Transformer架构和视觉-语言预训练模型的最近出现对深度学习领域产生了深远的影响,从根本上重塑了跨模态检索研究格局。尽管近年来已经发表了文献[9]、[10],但它们的范围和分类都明显不足。在文献[9]中,关于基于自注意机制或大规模预训练模型的跨模态检索方法的论述非常稀少。另一方面,文献[10]主要集中在图像-文本匹配领域,未能全面综合有监督的跨模态实值检索和整个跨模态哈希检索的方法。与此同时,文献[9]、[10]将基于深度学习的跨模态检索方法归入一个过于简化的类别,这种方法不适合深度学习的当前先进状态。在这个领域内,不同的深度技术具有其核心概念,将它们合并为一个单一的类别阻碍了对不同网络架构中固有的独特属性的全面了解。此外,这些作品都没有深入探讨如何解决各种实际场景中遇到的实际挑战的策略。考虑到解决这些实际问题现在已经成为跨模态检索研究的一个焦点,这种遗漏尤为值得注意。鉴于此,我们对从创始到现在的两百多篇跨模态检索论文进行了全面的回顾,总体目标是为这个领域提供一个全面的概览。总之,本文的主要贡献可以总结如下:
我们介绍了一个详尽且细致的跨模态检索分类法,将现有方法分为五大类和四十三个子类。通过提供这些技术所采用的原理和架构的详细阐述,本文为整个跨模态检索领域提供了一个全面的回顾,涵盖了基本概念和进步的创新。
此外,本研究提供了一个简洁的多模态数据集、评估指标和性能基准的汇编。这个汇编为跨模态检索研究者提供了一个宝贵的参考,帮助他们选择适当的数据集和指标来进行实验验证和性能评估。
此外,鉴于当前的发展状况和应用要求,本文探讨了跨模态检索领域面临的机会和挑战。从这一分析中,提出了潜在的解决方案和研究方向,重点关注该学科中的前沿挑战和新兴趋势。
本文的后续部分组织如下:第二部分提供了跨模态检索中使用的基本概念和分类标准的全面概述。第三部分深入探讨了各种跨模态检索方法,详细阐述了它们的复杂细节和架构。第四部分展示了跨模态检索研究中广泛使用的数据集、评估指标和性能比较的大量汇编。第五部分突出了跨模态检索技术找到相关性的实际应用场景。第六部分对该领域的未来发展趋势进行了深入的分析。最后,第七部分总结了本文,概述了主要的发现和贡献。
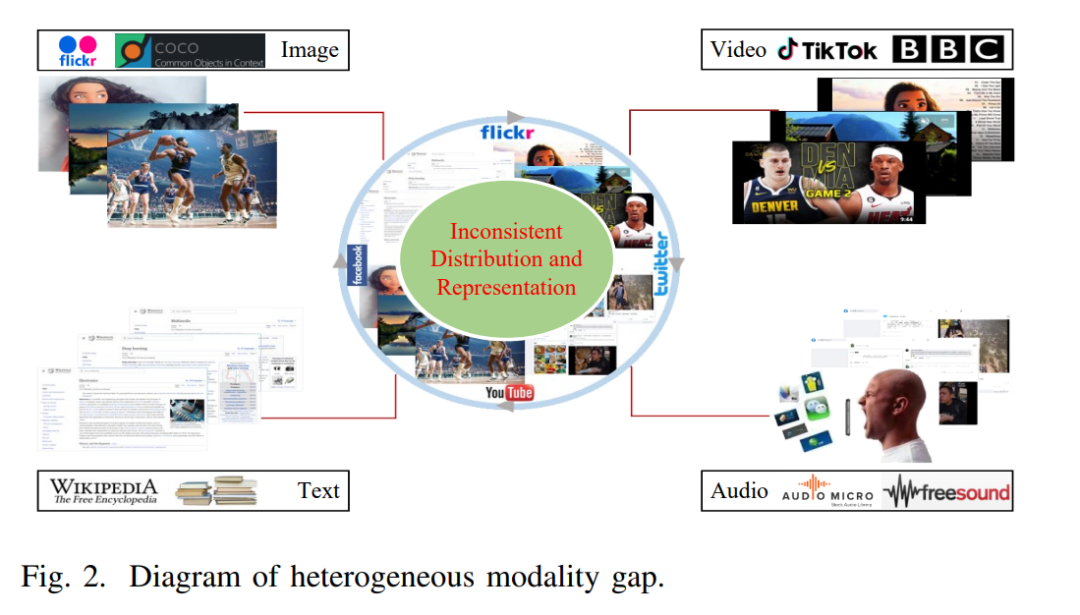
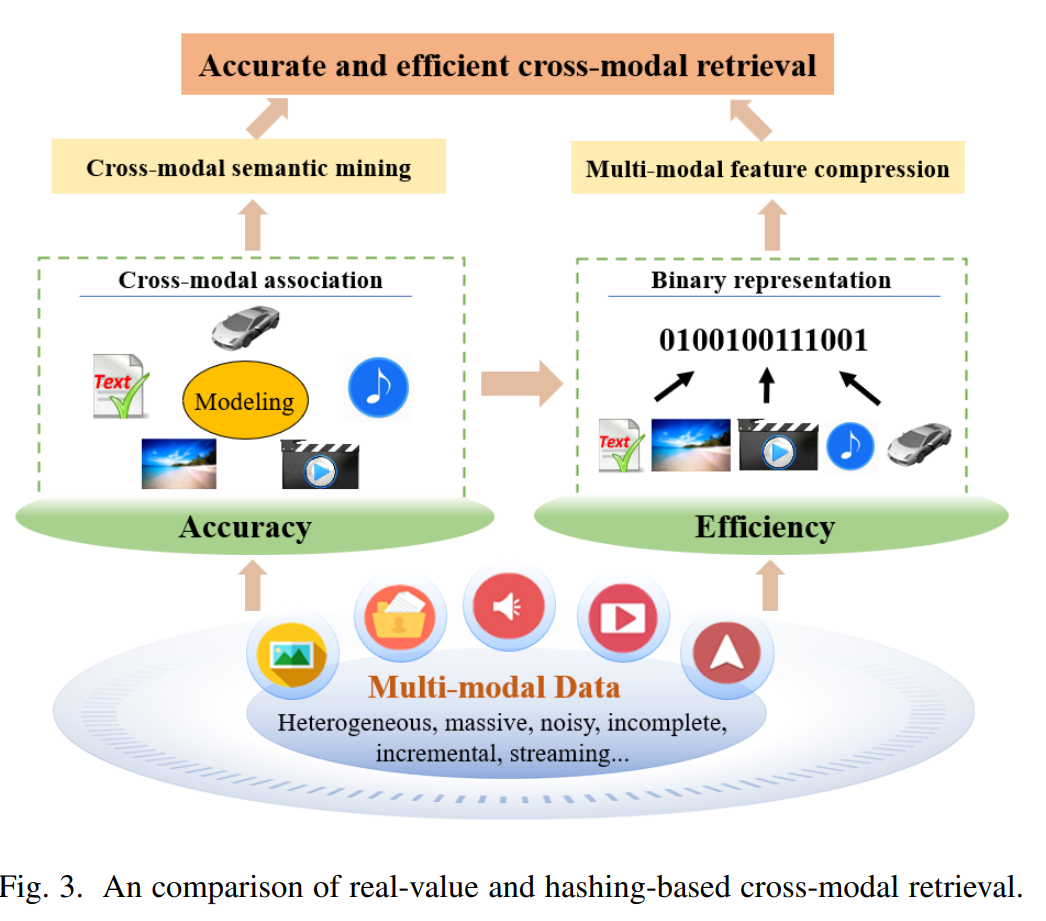
跨模态检索在多媒体检索中占据了关键的地位,在人工智能领域拥有巨大的潜力。其目的是从不同的模态中提取语义上相关的信息,利用如文本、图像或视频等模态线索。然而,跨模态检索的景观是崎岖的,其中最主要的挑战是在异构模态数据中评估内容的相似性,这一难题通常被称为异构模态间的差距,如图2所示。这一困境源于模态之间在数据结构、特征空间和语义描绘上的差异,导致直接比较和对齐的巨大障碍。因此,跨模态检索研究的核心是为多模态数据创建一个共享的框架,从而便于计算跨模态的相似性。为了应对这一挑战,研究者提出了一系列的共同表示学习方法。这些方法努力将多模态数据映射到一个共享的、低维度的空间。在这个空间里,具有相似语义的数据聚集在一起,而不相似的数据则相互疏远。广义上,跨模态检索方法可以基于其数据编码形式分为两种原型:实值检索和哈希检索,如图3所示。跨模态实值检索努力提取多模态数据在实数领域的低维向量表示。虽然这种方法保留了更丰富的语义数据,但它会带来更高的存储成本和计算需求。与之相反,跨模态哈希检索寻求提取多模态数据的压缩二进制表示,并将其拟合到汉明空间。这种发展使得检索更加高效。然而,这种效率可能需要牺牲部分语义信息。每种方法都有其独特的优势和劣势,选择哪种方法取决于实际应用的特定要求和限制。
在数据编码形式旁,监督信息也是划分跨模态检索方法的关键决定因素。通过结合这些考虑,我们将所有的跨模态检索方法分类为五大主要类别:无监督的跨模态实值检索、有监督的跨模态实值检索、无监督的跨模态哈希检索、有监督的跨模态哈希检索,以及特殊场景下的跨模态检索。此外,每个主要类别进一步细分为几个子类别,如表I所示。前四个主要类别基于统计分析技术、深度神经网络和其他辅助结构进行了细致的修饰。这些包括典型相关分析(CCA)、主题模型、谱图、矩阵分解、字典学习、特征映射、度量学习、量化、自编码器、卷积神经网络-循环神经网络(CNN-RNN)、生成对抗网络(GAN)、图神经网络(GNN)、Transformer、视觉-语言预训练模型(VLP模型)、跨模态生成、知识蒸馏和记忆网络。最后一个主要类别涵盖了为特殊场景设计的跨模态检索,如不完整数据、增量数据、噪声数据、跨域检**索、零/少示例检索、在线检索、层次/细粒度检索、文本-视频/音频检索和对跨模态检索的对抗。在这些特定场景中,基于实值和哈希的跨模态检索方法提供的解决方案显示出相似性。**因此,我们将它们统一为一个子类别,无需明确的区分。
A. 无监督的跨模态实值检索
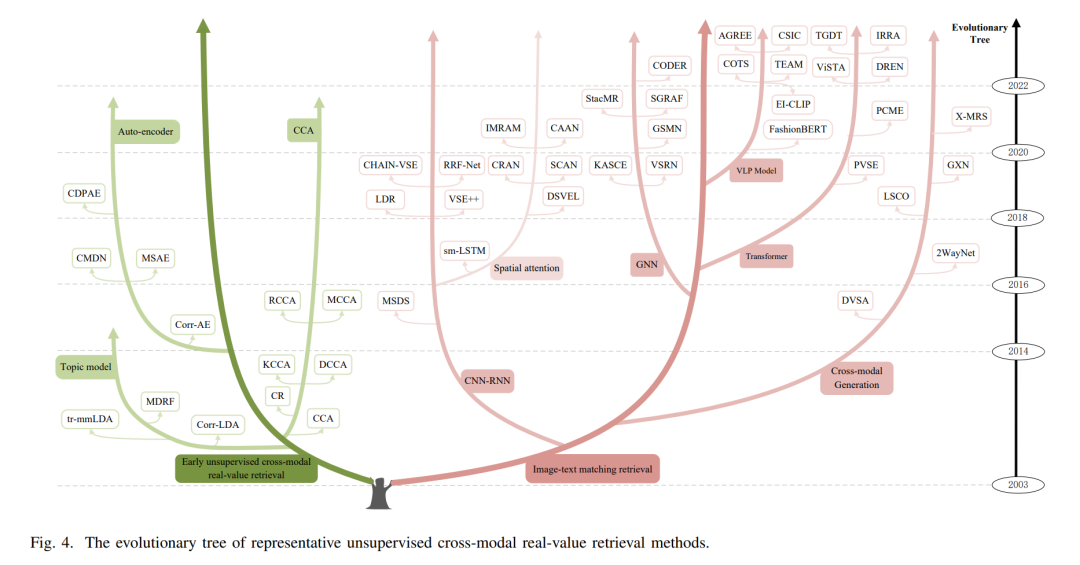
无监督的跨模态实值检索旨在利用多模态数据的共同出现,如文本和图像一起出现,以捕获它们的语义关联。根据设计原则和评估措施,它可以分为两种类型:早期的无监督跨模态实值检索和图像-文本匹配检索。
B. 有监督的跨模态实值检索
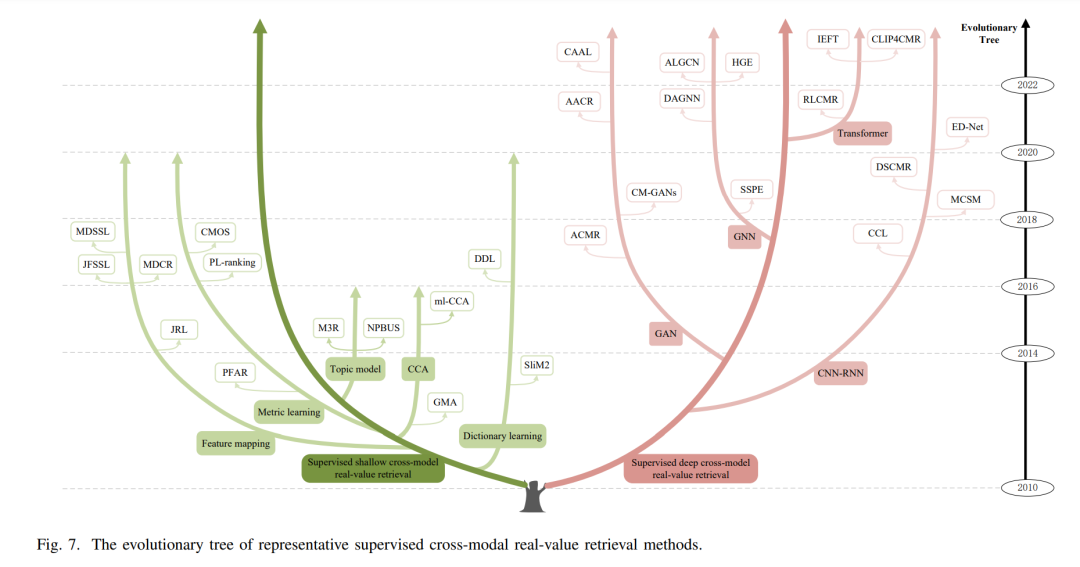
有监督的跨模态实值检索受益于手工注释,广泛探索多模态数据中的语义类别区分和关联,以增强跨模态检索任务。根据不同的学习原则,区分出两种主要方法:浅层和深层跨模态实值检索。浅层方法使用矩阵分解和特征映射来模拟多模态数据中的关联。相反,深层方法使用深度神经网络来捕捉复杂的关系。有监督的浅层跨模态实值检索,在这类方法中,根据使用的技术区分出典型相关分析(CCA)方法、字典学习方法、特征映射方法和主题模型方法。有监督的深层跨模态实值检索,有监督的深层跨模态实值检索包括CNN-RNN方法、GAN方法、GNN方法和Transformer方法。这些方法通过使用复杂的深度学习结构,例如卷积神经网络和循环神经网络,以及最新的Transformer架构,使得在多模态数据中能够捕捉到更加深入和细致的语义关系,从而实现更高精度的跨模态检索。
C. 无监督跨模态哈希检索
与无监督的跨模态实值检索相似,无监督跨模态哈希检索利用共同出现的多模态数据(例如,文本-图像对)来捕获它们之间的语义相关性。这种方法可以根据不同的原则分为两类:无监督的浅层和深层跨模态哈希检索。浅层方法主要依赖于矩阵分解和谱图来发现多模态数据中的关联,而深层方法则使用各种深度网络来建模多模态数据。无监督的浅层跨模态哈希检索:在这个类别中,可以根据使用的技术进一步将技术分类为矩阵分解方法、谱图方法、量化方法和度量学习方法。这些方法主要集中在为跨模态数据生成紧凑的二进制哈希码,从而实现高效的相似性检索。无监督的深层跨模态哈希检索: 无监督的深层跨模态哈希检索可以细分为CNN-RNN方法、GAN方法、GNN方法、Transformer方法和知识蒸馏方法。这些深度学习方法通过在多模态数据中捕获更深入和细致的语义关系,为数据生成有意义的二进制哈希码,从而实现高质量的跨模态检索。
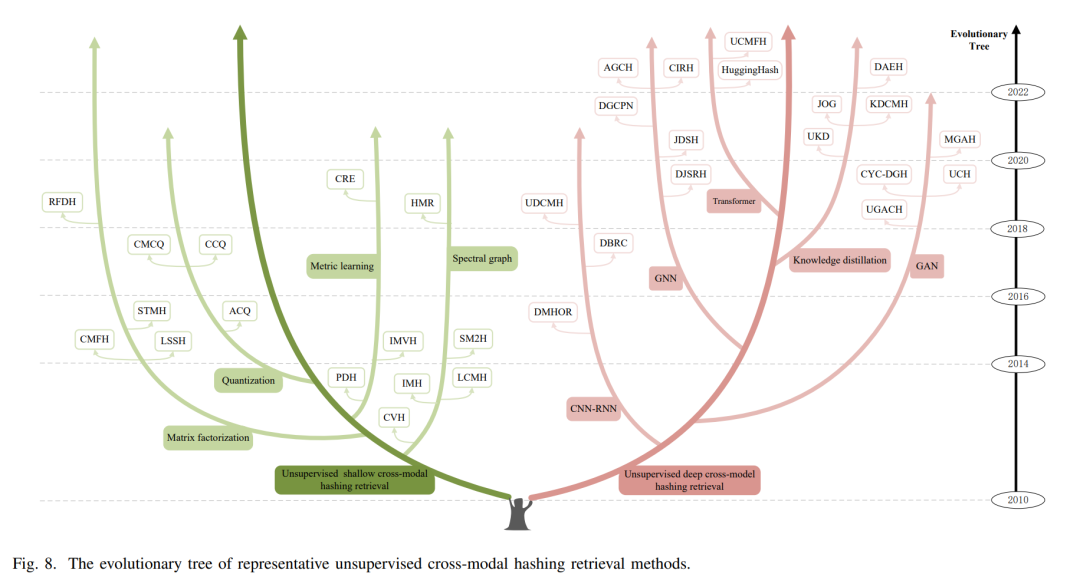
D. 监督跨模态哈希检索
受益于手动标注,监督的跨模态哈希检索能够充分利用多模态数据中的类别区分和语义关联,有效地将其映射到低维的哈明空间以进行高效搜索。根据不同的原则,此方法可分为监督浅层跨模态哈希检索和监督深层跨模态哈希检索。监督浅层跨模态哈希检索: 这一方法采用矩阵分解和特征映射技术为多模态数据生成一个公共表示。基于使用的技术,它可以进一步细分为矩阵分解方法和特征映射方法。这些浅层方法的核心在于寻找最优的线性或非线性变换,使得跨模态数据在映射到共享的哈明空间后,相似的数据具有接近的哈希码。监督深层跨模态哈希检索: 深度学习技术在此类别中被引入,以捕获数据中的复杂关系。这包括了CNN-RNN方法、GAN方法、GNN方法、Transformer方法和量化方法。这些深层方法旨在通过训练深度神经网络模型,自动学习从原始多模态数据到哈希码的映射函数,从而实现高质量的哈希编码。监督的跨模态哈希检索在大数据应用中具有巨大的潜力,因为它旨在将多模态数据映射到一个紧凑的哈明空间,这可以大大提高搜索的速度和效率,同时保持良好的检索质量。
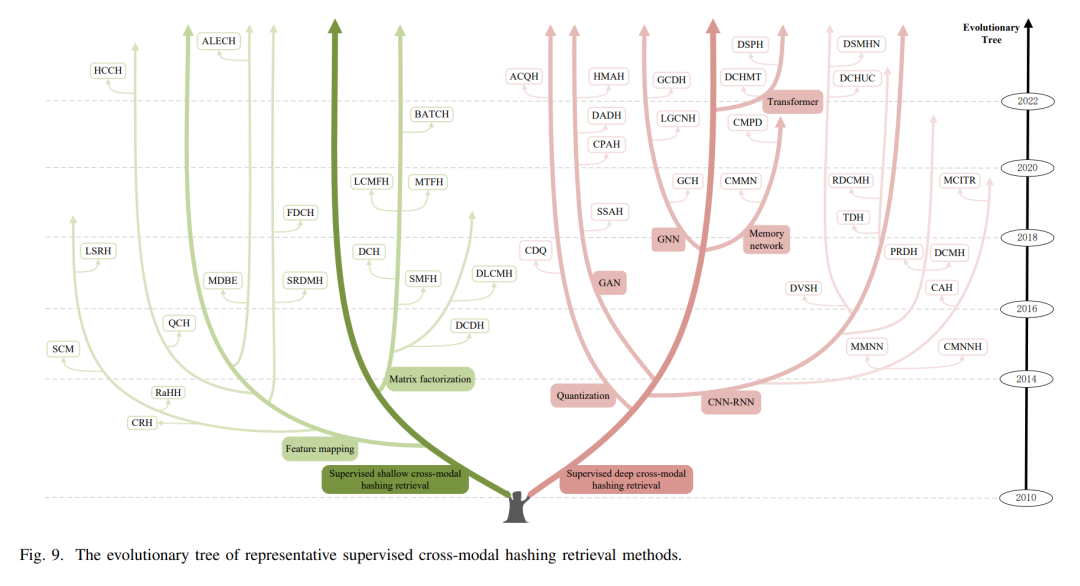
E. 在特殊检索场景下的跨模态检索
前述的跨模态检索方法基于理想的假设,并适用于通用检索场景。然而,由于实际限制,如数据收集不完整、注释噪声以及特定的检索需求,一些跨模态检索方法已经被提出来解决在特殊检索场景中可能遇到的各种问题。 跨模态检索数据集和实验结果
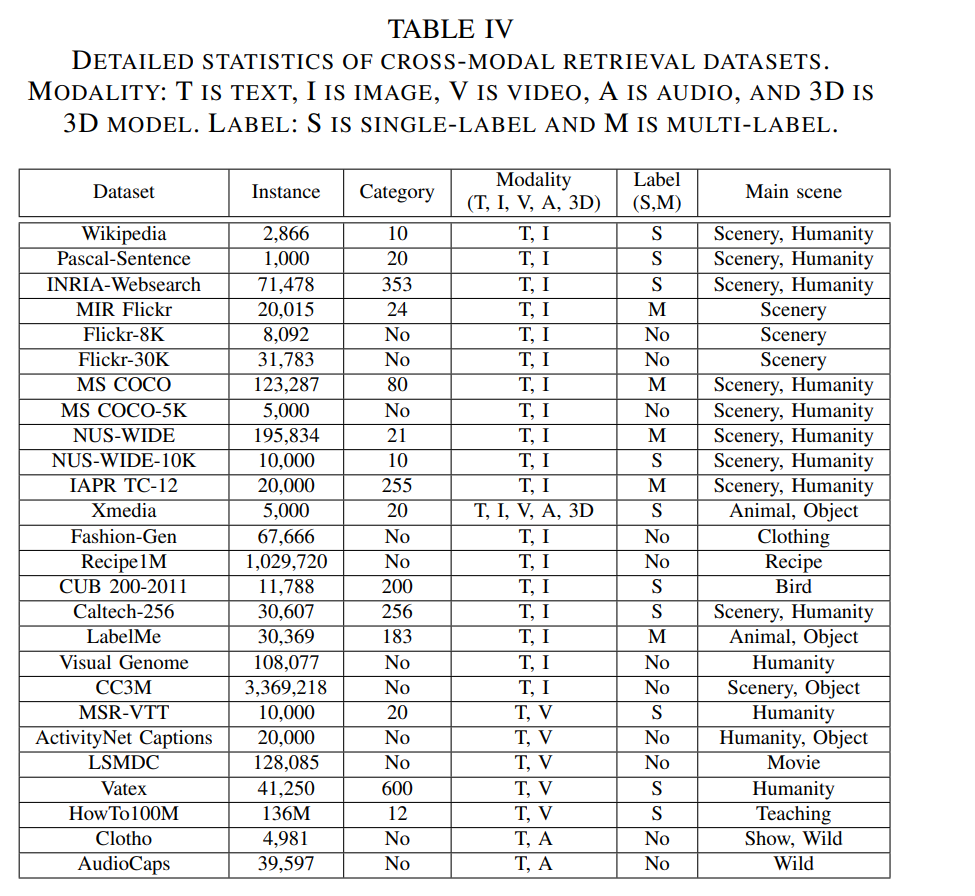
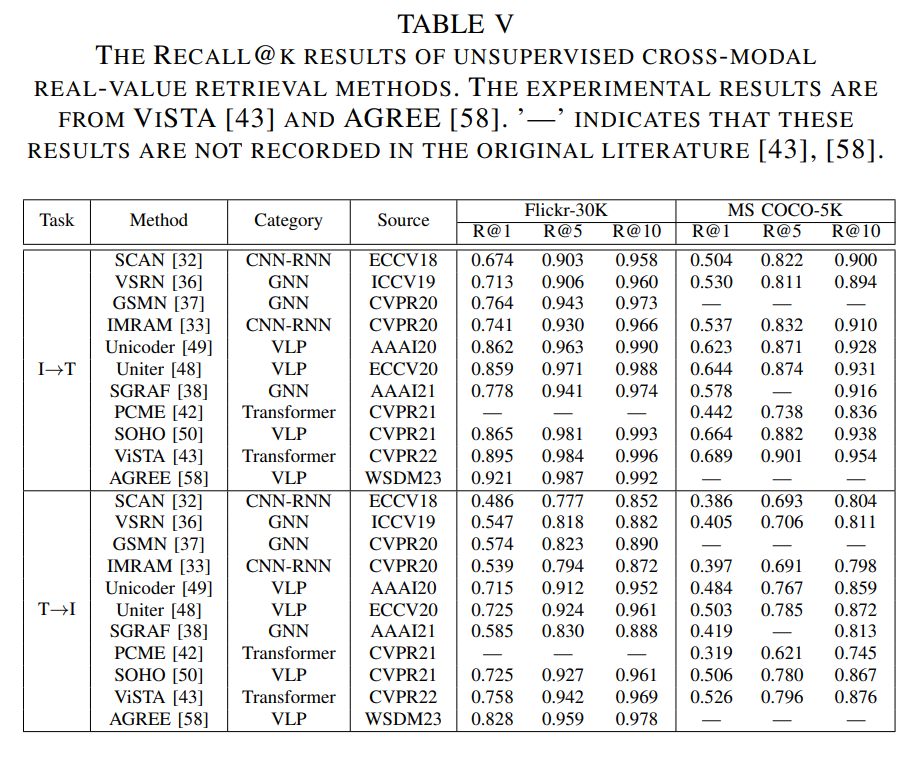
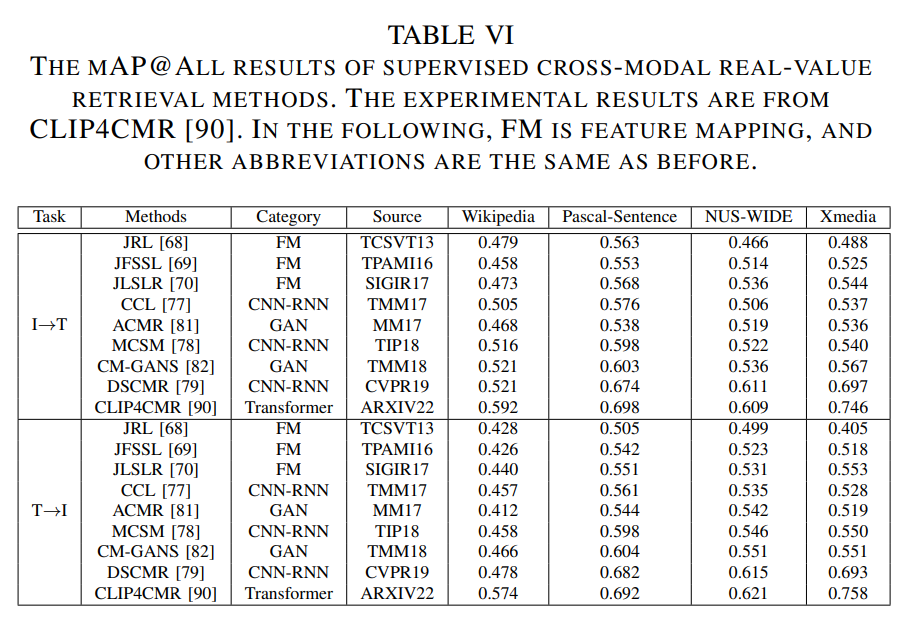
为了使研究者全面了解跨模态检索中的数据来源和特性,以及性能评估方法,本节将介绍在跨模态检索中广泛使用的评估数据集、指标以及代表性的跨模态检索结果。
结论
跨模态检索满足了获取和利用多种多模态数据的日益增长的需求。这一领域研究的演进提高了检索系统的准确性、稳定性和可扩展性。本文提供了一个全面的分类体系,回顾了大量的文献,并为跨模态检索方法和架构提供了深入的见解。它还提供了关于数据集选择和性能评估指标的指导。本文探讨了机会、挑战以及未来的研究方向,为跨模态检索的理解和发展做出了贡献。鼓励在这一领域进一步的探索和创新。
