
机器之心报道
编辑:蛋酱
近年来,生成式大模型(如大语言模型、扩散模型)已显示出卓越的性能,但它们需要大量的计算资源。为了让这些模型更易于使用,提高它们的效率至关重要。 在最新的一季 MIT 6.5940 课程中,MIT 学者韩松将深入解读生成式大模型时代的「AI 计算的模型压缩与加速技术」。
课程全名为《TinyML 和高效的深度学习计算》。概括来说,这门课程将介绍高效的人工智能计算技术,以便在资源有限的设备上实现强大的深度学习应用。
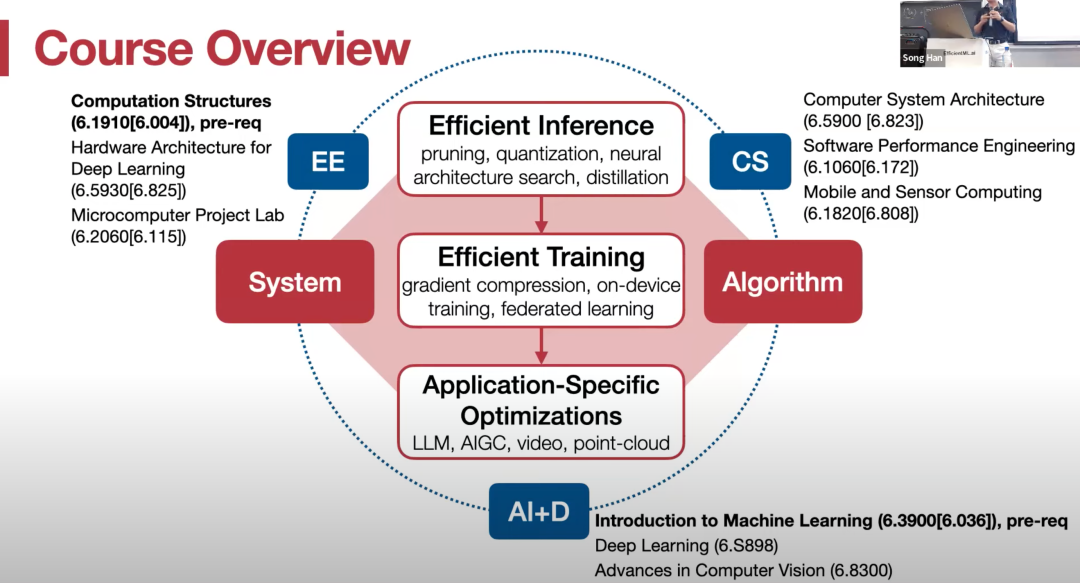
课程主题包括模型压缩、剪枝、量化、神经架构搜索、分布式训练、数据 / 模型并行化、梯度压缩和设备微调,还介绍了针对大语言模型、扩散模型、视频识别和点云的特定应用加速技术,并涵盖了量子机器学习的相关主题。此外,学生将获得在笔记本电脑上部署大型语言模型(如 LLaMA 2)的实践经验。 最重要的是,这门课程的全部视频资源将上传到 Youtube 平台。

播放列表地址:https://youtube.com/playlist?list=PL80kAHvQbh-pT4lCkDT53zT8DKmhE0idB&feature=shared 课程大纲**
**课程整体规划如下图所示:
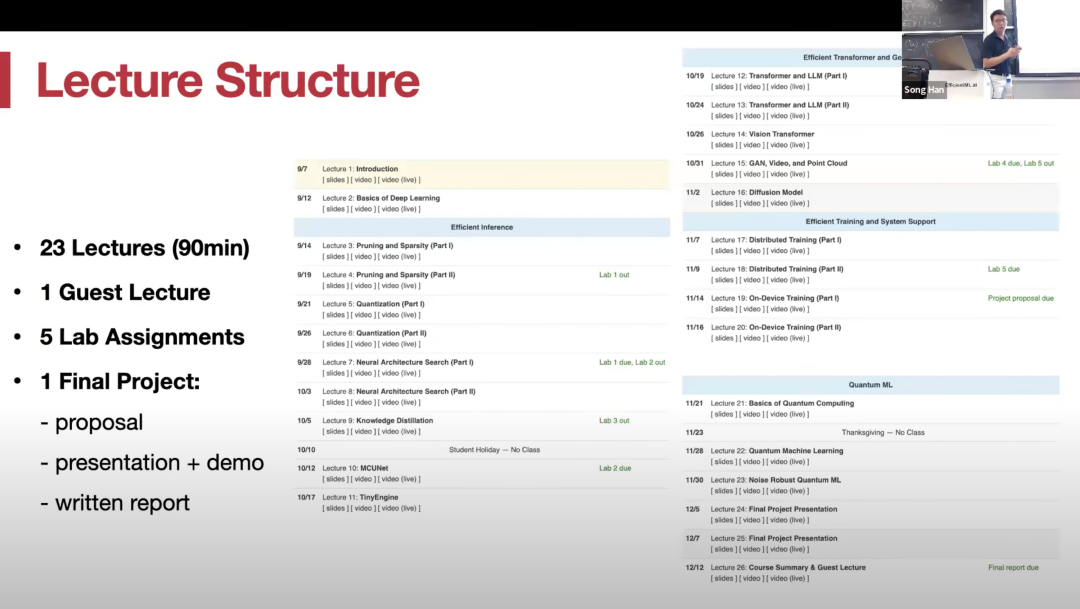
目前,Youtube 栏目中已经更新了前五章的授课内容:第一章 Introduction,第二章是神经网络基础,第三、四章是剪枝和稀疏性,第五章是量化。
鉴于目前课程还在进行中,如果你对即将要学的内容非常好奇,也可以先行参考其 2022 年秋季的授课资料,包含视频和 PPT。 下载地址:https://www.dropbox.com/sh/0ftluqbd1afzqpy/AADqxwkYrt1FbGnSQ4KP3Kpva?dl=0 讲师介绍**
**这门课程由MIT副教授韩松主讲,并由他的两位博士生林吉和蔡涵担任助教。

韩松在斯坦福大学获得博士学位,2018 年加入 MIT,现为电子工程科学系副教授,研究广泛涉足深度学习和计算机体系结构。

韩松团队在硬件感知神经架构搜索(once-for-all network)方面的工作使用户能够设计、优化、缩小人工智能模型,并将其部署到资源受限的硬件设备上。 他曾提出包括剪枝和量化在内的「深度压缩」(Deep Compression)技术。 他还提出了「高效推理引擎」(Efficient Inference Engine,EIE),首次将权重稀疏性引入现代 AI 芯片,并影响了英伟达公司带有稀疏张量核心的安培 GPU 架构。 顺便一提,韩松博士的两次创业,均获得了 AI 领域的高度关注。 博士期间,韩松与同为清华大学毕业的汪玉、姚颂联合创立了深鉴科技(DeePhi Tech),其核心技术之一为神经网络压缩算法,随后深鉴科技被美国半导体公司赛灵思收购。 2021 年,韩松与吴迪、毛慧子共同成立 AI 边缘计算公司 OmniML,旨在通过创建深度学习模型来弥合 AI 应用程序与边缘上的各种设备之间的差距,从而提高 AI 的速度、准确性和效率。今年,该公司被英伟达收购。

