
转载机器之心 机器之心编辑部如何振兴推特,马斯克选择「流量最大」的打法。 马斯克曾把特斯拉的专利开源,现在推特的算法也被他开源了。 首富伊隆・马斯克去年收购推特前就曾表示,推特的代码应该在 GitHub 上公开,以便公众对其进行检查,这样才算得上健全。在这不久后,马斯克宣布收购推特,推特的 GitHub 主页上很快新增了一个「the-algorithm」仓库,不过这个仓库很快就 404 了。 前几天他又表示,推特会在 3 月 31 日开源推荐代码。这一次,他终于兑现了。
开源地址:https://github.com/twitter/the-algorithm
在 Twitter Spaces 会议上,马斯克解释道:「最初发布的算法会非常尴尬,人们会发现很多错误,但我们会很快修复它们…… 即使你不同意某件事,至少你会知道它为什么在那里,并且你没有被秘密操纵...... 我们的参照物是 Linux ,一个很好的开源操作系统样本…… 理论上,人们可以发现 Linux 的许多漏洞,但实际上社区会识别并修复这些漏洞。」 既然开源,那就表示接受修改建议。马斯克又表示了,每过 24 小时到 48 小时,推特会根据用户建议对推荐算法进行一次更新。

不仅接受人们的监督,还可以提升技术实力,看起来是一举多得的好事。 有趣的是,外媒 Gizmodo 的一篇报道指出, 推特向用户推送的 VIP 列表似乎没有公开。本周 Platformer 报道称,推特有一份值得关注的用户轮换名单,包括 YouTuber Mr. Beast 和 Daily Wire 创始人 Ben Shapiro,它通过看似随意地增加这些「高级用户」的可见性来监控推荐算法的变化。 还有更多证据表明,推特的算法可能会根据来源不同地对待推文。研究人员 Jane Manchun Wong 指出,推特的算法专门标记了「推文作者是否是 Elon Musk」,还有其他标签表明作者是否是「高级用户」等。
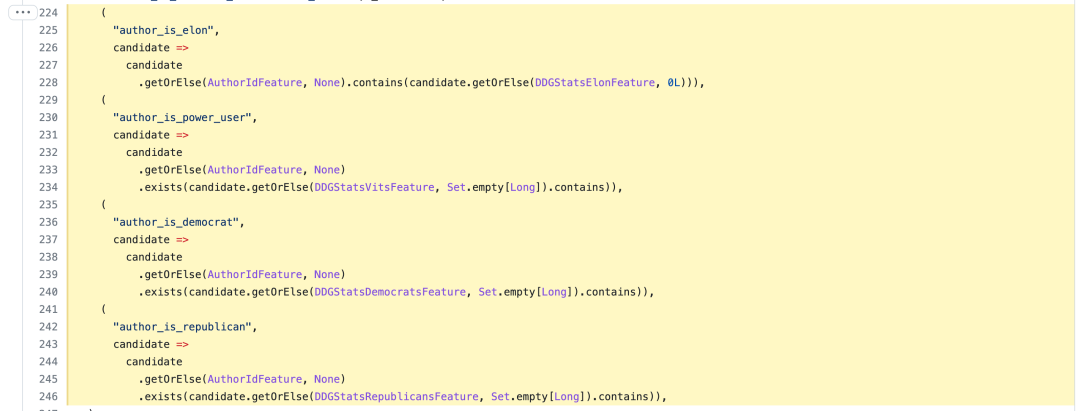
对此,推特在今天下午的 Spaces 会议上也有回应,一位推特工程师表示,这些标签仅用于衡量指标。而马斯克说自己在今天之前不知道这些标签,并表示「它们不应该在那里」。
推特是如何选择推文的?
在推特同期发布的技术博客上,工程师们对推荐系统算法进行了一番解释。 推特推荐系统的基础是一套核心模型和功能,从推文、用户和相关数据中提取潜在的信息。这些模型旨在回答关于 Twitter 网络的重要问题,例如,「你未来与另一个用户互动的概率是多少?」或者,「Twitter 上有哪些社区,其中有哪些流行的推文?」准确地回答这些问题使 Twitter 能够提供更相关的推荐。 推荐流程由三个主要阶段组成:
- 从不同的推荐源中获取最佳推文,这个过程被称为候选搜寻(candidate sourcing)。2. 使用机器学习模型对每条推文进行排名。3. 应用启发式方法和过滤器,例如过滤掉你已经屏蔽的用户的推文、NSFW 内容,以及你已经看过的推文。 负责构建和服务 For You 时间线的服务被称为 Home Mixer。Home Mixer 建立在 Product Mixer 上,这是推特定制的 Scala 框架,可以方便地构建内容提要。这项服务作为软件主干,连接不同的候选推文来源、评分功能、启发式方法和过滤器。 下面这张图说明了用于构建时间线的主要组件:
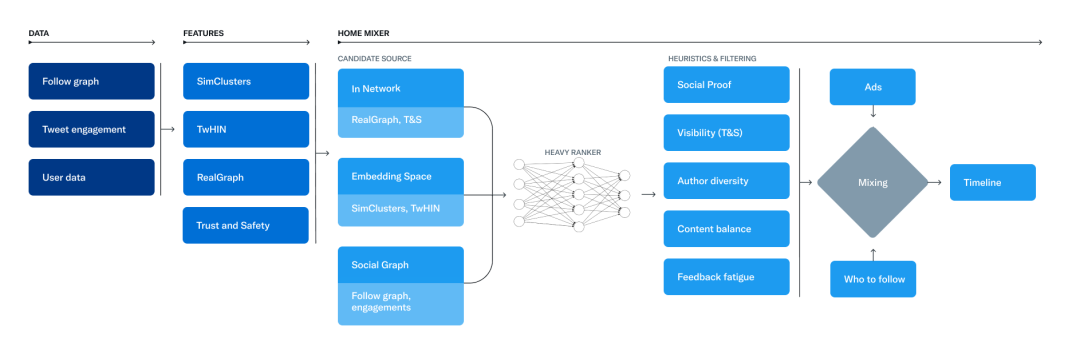
接下来探讨一下这个系统的关键部分,大致按照在一次时间线请求中的调用顺序,从检索候选推文源开始。 候选推文源
Twitter 有几个候选推文源,他们用这些候选源来为用户检索最近的相关推文。对于每个请求,他们试图通过这些来源从数以亿计的推文池中提取最好的 1500 条推文。他们从你关注的人(网络内)和你不关注的人(网络外)中找到候选推文。今天,For You 时间线平均由 50% 的网络内(In-Network)推文和 50% 的网络外(Out-of-Network)推文组成,尽管这可能因用户而异。
网络内推文源
网络内推文源是最大的候选推文来源,旨在提供你所关注的用户的最相关、最近的推文。它使用一个逻辑回归模型,根据相关性对你所关注的人的推文进行有效排名。然后,排名靠前的推文被送到下一个阶段。 对网络内推文进行排名的最重要的组件是 Real Graph。Real Graph 是一个预测两个用户之间接触的可能性的模型。你和推文作者之间的 Real Graph 得分越高,推荐内容中就会包含更多他们的推文。 网络内推文源一直是推特最近工作的主题。他们最近停止了 Fanout 服务的使用,这是一项有 12 年历史的服务,以前用来从每个用户的推文缓存中提供网络内推文。他们也正在重新设计逻辑回归排名模型,该模型最后一次更新和训练是在几年前!
网络外推文源
在用户网络之外寻找相关的推文是一个比较棘手的问题:如果你不关注作者,推特怎么能知道某条推文是否与你有关?为了解决这个问题,推特采取了两种方法: 1、社交图谱(Social Graph) 第一个方法是通过分析你所关注的人或有类似兴趣的人的参与情况,来估计与你相关的内容。 推特遍历上述分析内容的图,以回答以下问题:
- 我关注的人最近参与了哪些推文?
- 谁喜欢与我相似的推文,他们最近还喜欢什么?
推特会根据这些问题的答案生成候选推文,并使用逻辑回归模型对生成的推文进行排名。这种类型的图遍历对于网络外推荐至关重要。团队开发了 GraphJet 图处理引擎,以维护用户和推文之间的实时交互图,以执行这些遍历。虽然这种用于搜索推特参与度和关注网络的启发式方法已被证明是有用的(这些目前服务于大约 15% 的主页时间线推文),但嵌入空间方法已成为网络外推文的更大来源。 2、嵌入空间 嵌入空间方法旨在回答一个关于内容相似度的普遍问题:「哪些推文和用户与我的兴趣相似?」 嵌入的工作原理是生成用户兴趣和推文内容的数字表征,然后推特就可以计算该嵌入空间中任意两个用户、推文或用户 - 推文对之间的相似度。如果生成了准确的嵌入,推特可以使用这种相似性作为相关性的替代。 推特最有用的嵌入空间之一是 SimClusters。SimClusters 使用自定义的矩阵因子化算法,发现由有影响力的用户集群锚定的社区。这里有 14.5 万个社区,每三周更新一次。用户和推特在社区的空间中被表示出来,并且可以属于多个社区。社区的规模从个人朋友圈的几千个用户到新闻或流行文化的几亿个用户不等。这些是一些最大的社区:
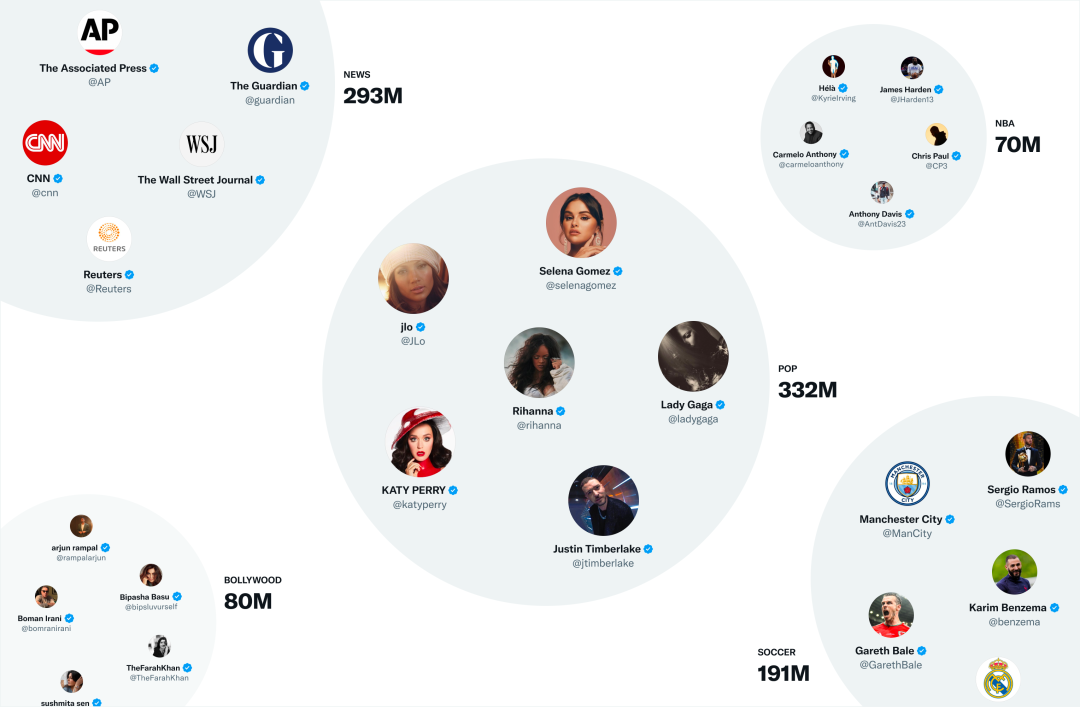
此外,推特还可以通过查看推文在每个社区中的当前流行度来将推文嵌入到这些社区中。喜欢推文的社区用户越多,推文与该社区的关联度就越高。 排序
「For you」时间线的目标是为用户提供相关的推文。在 pipeline 的这一点上,有大约 1500 个可能是相关的候选项。分数会直接预测每个候选推文的相关性,是在用户时间线上对推文进行排序的主要信号。在这个阶段,所有的候选项都被平等对待,而不考虑它来自哪个候选来源。 排序是通过一个约 4800 万参数的神经网络实现的,该网络在推特互动数据上不断训练,以优化积极的参与(例如,赞、转发和回复)。这个排序机制考虑到了成千上万的特征,并输出十个标签来给每条推文打分,其中每个标签代表了参与的概率。然后,推特根据这些分数对推文进行排名。 启发式、滤波器和产品功能
在排序阶段之后,推特应用启发式和滤波器来实现各种产品功能。这些功能会协同工作以创建平衡且多样化的提要。一些例子包括:
- 可见性过滤:根据内容和用户偏好过滤掉推文。例如,删除其屏蔽或静音的帐户的推文。
- 作者多样性:避免来自同一作者的太多连续推文。
- 内容平衡:确保推特提供网络内和网络外推文的公平和平衡。
- 基于反馈的疲劳分析:如果用户提供了负面反馈,则降低某些推文的分数。
- 社会证明:排除与推文没有二级关联的网络外推文作为质量保障。换句话说,确保你关注的人参与了这条推文或关注了推文的作者。
- 对话:通过将回复与原始推文串连在一起,为回复提供更多上下文。
- 已编辑的推文:确定设备上当前的推文是否过时,并发送指令以将其替换为已编辑的版本。
混合与服务
至此,Home Mixer 已准备好发送到用户设备的一组推文。作为流程的最后一步,系统将推文与其他非推文内容(如广告、关注推荐和 Onboarding prompt)混合在一起,这些内容将返回到用户设备上进行显示。 上述 pipeline 每天运行大约 50 亿次,平均完成时间不到 1.5 秒。单个 pipeline 执行需要 220 秒的 CPU 时间,几乎是在应用程序上看到的延迟的 150 倍。
推特正在开发更多新功能,为用户提供更多的透明度。下一步计划包括:
- 为创作者提供更好的推特分析平台,提供更多关于影响力和参与度的信息;
- 提高应用到用户推文或帐户的任何安全标签的透明度;
- 更好地了解推文出现在时间线上的原因。
最后,在代码公开的几个小时内,已经有人在推特代码中找到了一些「奇怪」的地方。 比如马斯克在推特算法中有自己的特征类:

或许马斯克在神经网络中也有自己的特殊嵌入向量。 另外还有专属的变量:

毕竟人家是公司老板。

不知在网友的挖掘之下,还能发现推特代码里哪些有趣之处? 参考链接:https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm

