大语言模型(LLMs)为可解释人工智能(XAI)提供了一种前景广阔的研究路径——通过将复杂的机器学习输出转化为易于理解的叙述,使模型预测更贴近用户认知,从而弥合先进模型行为与人类可解释性之间的鸿沟。 当前,最先进的神经网络与深度学习模型等AI系统常因缺乏透明度被视为“黑箱”。由于用户无法充分理解模型的决策逻辑,其对AI结论的信任度往往不足,进而导致决策效率降低、责任归属模糊以及潜在偏见难以察觉。因此,如何构建可解释AI(XAI)模型以赢取用户信任并揭示模型的内在机制,已成为关键研究挑战。随着大语言模型的发展,我们得以探索基于人类语言的LLMs在模型可解释性领域的应用潜力。
本综述系统性回顾了LLMs赋能XAI的现有方法体系与解释生成评估技术,剖析了相关挑战与局限,并考察了实际应用案例。 最后,我们展望未来研究方向,强调需通过LLMs发展更具可解释性、自动化、以用户为中心且融合多学科智慧的XAI新范式。
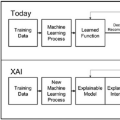
1 引言 近年来,人工智能(AI)技术的飞速进步推动了深度学习等复杂模型的快速发展。AI模型已在医疗、金融等诸多领域展现出卓越能力[72][30]。然而,随着模型复杂度的提升,其决策过程因缺乏透明度而难以追溯[12]——这种被称为"黑箱"的问题严重制约了用户信任,尤其在医疗和金融等关键领域的应用推广[15]。尽管学界持续致力于提升AI模型的可解释性[59],但缺乏机器学习背景的专家仍难以理解系统决策逻辑。
透明度的缺失将直接导致三重困境:
在医疗场景中,医生可能无法理解模型推荐特定治疗方案的原因,导致难以采信其建议;
在金融领域,分析师若无法解读AI市场预测的依据,则可能对模型输出犹豫不决;
更广泛而言,这会降低决策效率、模糊责任归属,并掩盖潜在偏见。
可解释人工智能(XAI)正通过创新方法提升神经网络等前沿模型(如图像识别中的卷积神经网络CNN、序列数据处理中的循环神经网络RNN、图像生成中的对抗生成网络GAN)的可解释性,力求在保持准确率等性能指标的同时增强透明度[12]。XAI的核心在于平衡模型效能与可理解性,这一挑战贯穿所有应用场景[119][144][27]。有效的解释机制能建立用户信任、确保责任追溯,并促进AI伦理应用。
大语言模型(LLMs)的革新价值: 作为连接复杂AI系统与XAI的桥梁,LLMs凭借其自然语言处理能力[90]正在多个领域发挥关键作用:
医疗:辅助诊断与个性化诊疗[130],例如在医学影像分析中,LLMs可解释模型为何将肺部扫描标记为异常,并指出特定疾病关联特征;
金融:支持风险评估与市场预测[143];
自然语言处理(NLP):赋能文本分类、摘要生成与情感分析等任务。
LLMs通过以下方式推动XAI发展:
动态解释生成:理解用户问题后生成情境化解释[109][123][125];
架构可视化:直接解析复杂机器学习模型的结构与输出逻辑[77];
反事实推演:通过简单提示即可识别预测关键特征并生成对比解释(如研究[16][97]所示)。
这些实践印证了LLMs在提升AI决策透明度和可信度方面的巨大潜力,为构建跨领域可解释AI系统开辟了新路径。
如图2与表1所示,本研究系统探讨了基于大语言模型(LLMs)的可解释性实现路径,重点论述以下三类方法:
-
事后解释法(Post-hoc Explanations) 对应因果可解释性,通过分析特定输入如何导致特定输出,为机器学习(ML)模型的预测结果提供归因解释。例如:当图像分类模型将某病理切片判定为恶性肿瘤时,该方法可定位影响决策的关键图像区域。
-
内在可解释设计(Intrinsic Explainability) 面向工程师的可解释性需求,通过LLMs参与机器学习模型架构设计,使模型自身具备解释能力。典型实践包括:利用注意力机制可视化神经网络决策路径,或构建模块化推理链条。
-
人本叙事生成(Human-Centered Narratives) 旨在建立信任导向的可解释性,借助自然语言将模型输出转化为符合用户认知的叙事。以医疗场景为例:当AI预测患者未来五年高血压风险较高时(基于高胆固醇史、家族病史、年龄体重等因素),即使当前血压正常,系统可生成如下解释:
"尽管患者目前血压值在正常范围内,但结合其高胆固醇病史(+37%风险权重)、一级亲属高血压家族史(+28%风险权重)及BMI指数(+15%风险权重),模型预测五年内患病概率达68%。建议加强生活方式干预与定期监测。" 此类叙事帮助医生理解预测依据,从而建立决策信任。
本综述还将探讨解释效果的评估技术及其在实际场景中的应用范式。
图片 挑战与局限分析 如图3所示,我们围绕三个维度讨论LLMs实现AI可解释性的瓶颈:
隐私与社会规范冲突:医疗数据脱敏需求与解释详尽性之间的平衡;
系统复杂性管理:多模态模型(如结合CT影像与电子病历的诊断系统)的跨模态解释生成;
领域适配难题:金融领域术语(如"量化宽松")与法律文书语义的精准转换。
通过图4的显著图(Saliency Maps)对比,我们进一步分析不同LLM架构(如Transformer、MoE)在可解释性侧重上的差异。最后提出未来研究方向:通过模型架构创新与叙事策略的协同优化,构建兼具性能与透明度的新一代可解释AI系统。