

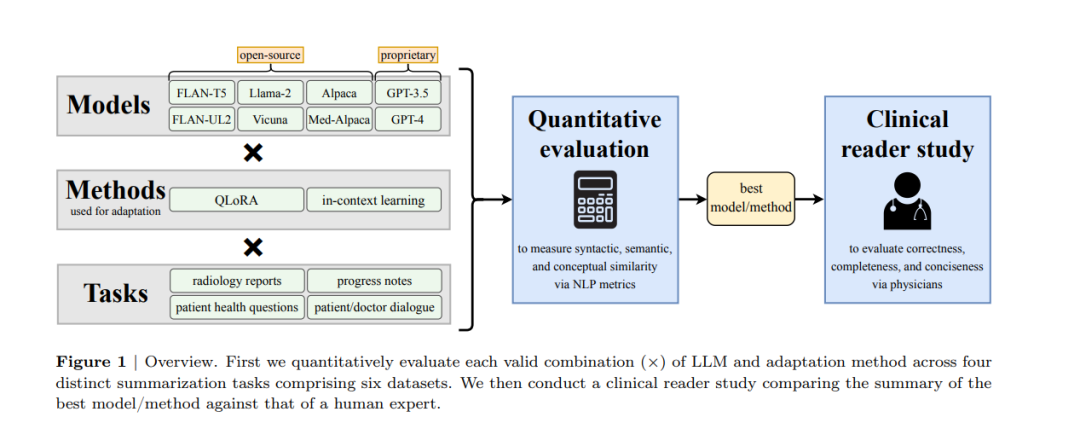
在大量文本数据中筛选并总结关键信息对于医生如何分配他们的时间构成了巨大的负担。虽然大型语言模型(LLMs)在自然语言处理(NLP)任务中展现了巨大的潜力,但它们在多样的临床总结任务中的有效性尚未被严格检验。在这项工作中,我们使用领域适应方法对八个LLMs进行了调整,这些模型覆盖了六个数据集和四个不同的总结任务:放射科报告、患者问题、进展注释和医患对话。我们全面的量化评估揭示了模型和适应方法之间的权衡,以及最新进展在LLMs上可能不会带来改进结果的情况。进一步,在与六名医生进行的临床阅读研究中,我们描述了最佳适应的LLM生成的摘要在完整性和准确性方面优于人工摘要。我们接下来的定性分析描绘了LLMs和人类专家共同面临的挑战。最后,我们将传统的量化NLP指标与阅读研究分数进行了相关性分析,以增强我们对这些指标如何与医生偏好一致的理解。我们的研究标志着LLMs在多个临床文本总结任务中首次超过人类专家的证据。这意味着将LLMs整合到临床工作流程中可能减轻文档负担,使医生能够更多地专注于个性化患者护理和医学中其他不可替代的人类方面。
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日