

在图 1 中简要介绍了布朗大学团队的研究工作。在美国国防部高级研究计划局(DARPA)的 "少标签学习"(LwLL)项目中,团队的工作包括技术领域 1(TA1)和技术领域 2(TA2)。技术领域 1 的目标是开发以下学习算法 (1) 将从头开始建立模型所需的标注数据量减少至少 10^6 倍;以及 (2) 适应具有数百个标注示例的新环境。TA2 的目标是正式证明解决特定机器学习问题所需的标注数据量的限制。具体来说,我们的贡献有两个方面:首先,我们开发了广泛适用的系统和方法,以减少学习对标注数据的需求;其次,我们定义了稳健的理论分析和框架,这些分析和框架是程序化弱监督和零点学习范例的基础。
在该计划中,预训练的大型语言和视觉语言模型的出现带来了新的挑战,因为这些模型出色的泛化能力大大提高了基准性能。虽然这些进步降低了针对新目标任务完善模型时对标注数据的需求,但能否获得足够的特定目标数据仍然至关重要,尤其是对于远离模型训练数据的领域。考虑到这一点,我们的团队将注意力转向了在资源有限的情况下对这些大型模型进行参数高效调整。
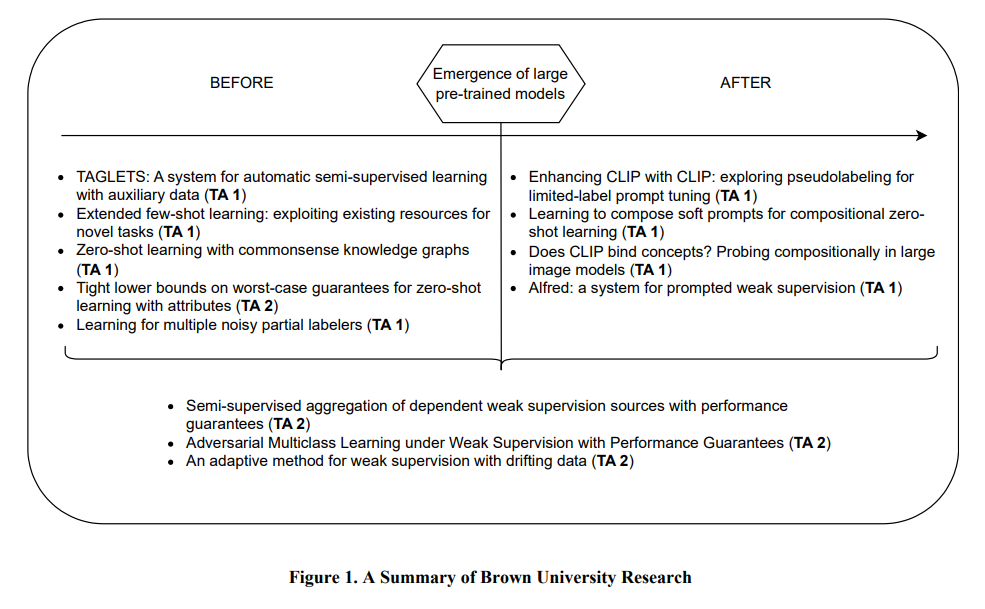
总的来说,贡献总结如下:
-
推出了 TAGLETS [1],这是首个端到端机器学习系统,能以统一的方式自动整合数据和模型生态系统。在数据量较少的情况下,没有经验法则可以事先选出最佳学习策略。TAGLETS 包括来自不同学习范式的多种算法,如迁移学习、半监督学习和零点学习。每个模型最初都会在目标相关的辅助数据上进行微调,这些数据是从其他任务的标注数据集合中提取的[1, 2]。然后,将训练好的模型作为弱标签器,为未标签数据生成伪标签。新标注的数据和为数不多的标注数据被送入最终模型,成为系统的输出结果。TAGLETS 最初使用较小的预训练模型作为模型的骨干。用更大的预训练模型取代这些骨干模型的进一步实验表明,TAGLETS 的架构和任务相关辅助数据的重点,即使是更大的预训练模型,也能从中获益。(TA1)
-
设计了一种新颖的零点学习方法(zero-shot learning approach),利用常识知识图谱来丰富未见目标类的信息(ZSL-KG)[3]。在使用描述类别的属性进行零点学习的背景下,我们首次提出了从属性到类别的最佳映射的最坏情况误差的非难下限,即使有完美的属性检测器也是如此[4]。该下界描述了基于可用信息--类-属性矩阵--的零点问题的理论内在难度,而且该下界实际上是可计算的。(TA1 和 TA2)
-
探索了如何在不同的低资源学习范式[5]下利用伪标记来提高视觉语言模型(VLM)在新任务上的能力。我们的主要观察结果是,在半监督、无监督和转导式零点学习设置中使用相同的学习策略,通过伪标签学习可持续提高对比语言-图像预训练(CLIP)的性能。此外,通过使用假标签进行提示来调整 CLIP,可减轻 CLIP 对某些类别的偏差。(TA1)
-
开发了一种使用 CLIP(组合软提示)[6] 学习如何组合概念的新方法。我们的方法在组合零点学习(即预测未见属性-对象组合(如老猫和小老虎)的任务)方面表现良好。除了提出这种新方法外,我们还研究了 CLIP 编码组合概念的能力,以及以对结构敏感的方式绑定变量的能力(例如,区分球体后面的立方体和立方体后面的球体)[7]。(TA1)
-
从理论上研究并提供了在去除独立性假设后组合弱标签器的新方法。特别是,我们设计了具有误差理论保证的解决方案[8, 9]。我们将这一分析扩展到漂移数据 [10]。此外,为了克服标签输出单一类标签的假设,我们研究了用户可以创建部分标签输出可能类标签子集的情况 [11]。(TA1 和 TA2)
-
在大型语言模型和视觉语言模型出现后,我们开发了 Alfred:第一个允许通过提示对大量未标记数据进行标记的框架[12]。(TA1)
方法对项目整体范围的影响。
- 布朗大学在 JPL 设计的图像和视频分类任务中评估了其 TAGLETS 系统。此外,我们还评估了 GRIP,这是一种利用伪标签的基于 CLIP 的提示调整方法,用于解决 JPL 的零镜头学习任务。
- 在图像分类任务中,TAGLETS 的表现跻身前六名。
- 在视频分类任务中,当标记数据量增加时,TAGLETS 是表现最好的方法。
- 在零镜头学习任务中,GRIP 的表现一直名列前茅,与基线相比提高了 20%。

