

1 智能博弈与推演概述
作为人工智能领域的果蝇,机器博弈(也称计算机博弈)是测试人工智能水平的天使标准。近些年,智能博弈求解技术突飞猛进,在DOTA2、星际争霸、德州扑克、西洋陆军旗等游戏环境中击败了人类。2022年11月,Meta公司研究团队在《科学》杂志上发表论文[5],声明在一款“外交风云”战略博弈棋类游戏中表现出优异水平,AI智能体通过对话理解意图,学会了谈判和欺骗[6]。2022年12月,DeepMind公司在《科学》杂志上发表的AI智能体DeepNash在西洋陆军棋中达到了专业级人类玩家水平[7]。人工智能赋能的机器博弈AI技术发展极大吸引了美军相关智能指控项目的开展。 在军事指控领域,2018年DARPA启动“面向复杂军事决策的非完美信息博弈序贯交互”(serial interactions in imperfect information games applied to complex military decision-making, SI3-CMD)项目,研究信息不完整情况下的博弈问题。2019年,美空军实施了“Alpha Dogfight”试验,旨在挖掘空战领域的新颖自主化和智能化作战决策方案,空军开展“空战演进”(air combat evolution, ACE)项目,开发可信、可扩展、人类水平、AI驱动的空战自主博弈能力。2020年DARPA开展了针对“敌方战术的建设性机器学习作战”(constructive machine learning battle for enemy tactics, COMBAT)项目[8],利用自然语言处理、非结构化文本提取,博弈论与强化学习等方法学习生成应对美军的行动方案,旨在为仿真环境提供敌军旅级兵力行动策略模拟。2020年5月,DARPA通过其官网宣布“打破游戏规则”(Game Breaker)人工智能探索项目,旨在开发程序AI并将其应用于现有任务级兵棋中,以打破复杂的模型所造成的不平衡。2021年11月,美空军发布了“今夜就战”(Fight Tonight)项目[9],尝试利用仿真环境与人类指导生成大量备选行动计划,旨在利用人工智能技术构建、演练和评估空中作战计划。2021年9月,美国国防科学委员会发布了关于美军一直在开展的“战略博弈推演-战役建模与分析-试验与学习-训练-数字工程”(gaming, exercising, modeling and simulation, GEMS)的相关报告[10],探索如何在人工智能赋能的多域战场中提升军事作战与辅助决策能力。2022年1月,美军启动了“权杖”(SCEPTER)项目[11],全称为用于弹性计划、战术与实验的战略混沌引擎,目标是利用人工智能开发作战人员的助理,为战役级战争开发机器生成的战略计划。2022年6月,DARAPA启动了SHADE人工智能探索项目[12],将使用外交的智能体、模拟(博弈)环境来训练和评估全自动人工智能谈判智能体,这些谈判代理能够处理复杂的多方交互,包括欺骗、勾结、分析和其他现实世界的特征。人工智能在智能博弈领域的关键里程碑如图1所示。

**
**智能推演方法分类
** 智能兵棋推演决策方法
(1) 知识驱动方法 传统的智能决策主要过程为感知当前任务状态,在可行的动作空间中,对满足既定目标的动作做出响应,从而达到新的任务状态,然后继续进行下一阶段的决策。当前,基于知识的智能决策方法主要有4种:基于STRIPS和PDDL的经典规划、基于HTN的层次任务网络、基于JADE的案例推理和基于BDI的过程推理等。基于规则的兵棋推演智能体的设计主要基于人类兵棋玩家经验形成的知识库,从而实现智能体的动态决策。基于规则的兵棋智能体设计的通用模型框架是OODA决策框架[41],即观察、判断、决策和行动。自2017年国内举办各类兵棋推演大赛以来,大部分参赛团队设计的智能体还是以规则AI为基础,通过对规则AI进行多次迭代优化设计来参加比赛。基于规则AI通常存在一些局限性,如智能体的通用性比较低,但是它的设计过程往往比较简单,并且具有较强的可解释性。目前大多数兵棋智能体都是基于规则知识设计的,即以人类推演的历史经验进行战法总结,通过行为树、有限状态机等框架实现智能体动态决策。 (2) 数据驱动方法 随着AlphaStar、AlphaDogFight等人工智能程序取得的巨大成功,以深度强化学习为基础的策略迭代方式成为了目前智能决策领域的主流技术。李琛等[42]将A3C算法引入兵棋推演中的智能体开发设计,在简单想定(对称态势,双方作战单元为坦克加战车)进行了实验并取得了不错的效果。张振等[43]将PPO应用于兵棋智能体开发设计,并与监督学习结合在智能体预训练的基础上进行了优化,在六角格兵棋环境中实现了策略的快速收敛。尹奇跃等[44]将强化学习和自博弈技术相结合实现了联合策略的学习,它能够同时维护多个不同参数的智能体,使得智能体能够保持多样性,这在一定程度上解决了智能决策过程中存在的策略非传递性问题。施伟等[45]使用深度强化学习技术在“墨子”兵棋系统中进行了多机协同空战的研究,最终模型涌现了多种人人对抗过程中常见的战术战法,如多机自主编队协同对抗、自主机动快速避弹、S型诱骗敌方弹药战法等。梁星星等[46]基于兵棋平台,设计了支持多机并行的行动策略智能学习框架,针对兵棋推演样本数据利用率低,策略收敛速度慢等问题设计了基于预测编码的样本自适应行动策略智能规划框架,提高了对战场态势的感知能力,改善了策略训练效率。(3) 混合驱动方法 基于知识的智能体具有较强的可解释性,但是受限于设计者的经验水平。基于学习的智能体不依赖人类玩家的推演经验,可以通过大规模的对局次数来学习到不同态势下最优的行动策略,具有超越专业兵棋玩家的潜力。部分研究人员将上述两种智能体设计方法归纳为知识驱动和数据驱动方法。蒲志强等[47]分析两种设计方法的优缺点和知识数据协同驱动的可能性方案(架构级协同和算法级协同)。基于规则的设计方法擅长在特定想定中处理兵棋推演过程中前期排兵布阵的问题,该阶段还未发生对抗,无法产生单元损失得分奖励,此时无法通过学习的方式学习到有效策略。基于学习的方法在中后期对抗过程中具有很大的优势,该阶段奖励频繁发生变化,智能体可以通过状态-动作-奖励信息快速学习到有效的策略。黄凯奇等[48]提出了一种融合知识与数据的人机对抗框架,该框架基于OODA理论为基础,提炼出了兵棋智能决策过程中的关键阶段和问题,并认为不同的问题可以通过拆解的方式分别使用基于规则和基于学习的方法进行求解。典型知识与数据混合驱动的兵棋推演框架如图3所示。 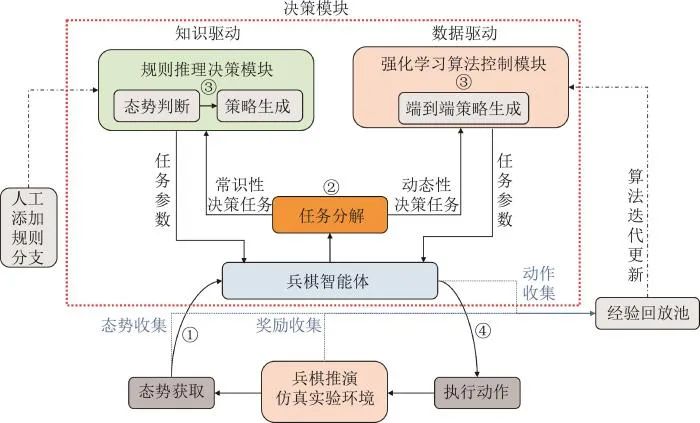
战略博弈推演方法可依据组织形式、组织流程、方式方法和手段运用、功能作战、应用领域、层次范围等分类[14],如表1所示。 表1 战略博弈推演方法分类 Table 1 Strategic wargaming method classification方法分类 组织形式 组织流程 方式方法 手段运用 功能作用 应用领域 层次范围 黑盒/白盒、单方/双方/多方、单层级/多层级 回合交替式、连续同步式、完全自主式 课题研究式、专项论证式、方案演练式 桌面推演式、仿真系统式、综合研讨式 教育训练、课题专项、决策辅助、理论研究 社会公共安全、军事/政治领域、多域融合 发展规划、危机处置、战争行动 新窗口打开| 下载CSV
(1) 净评估方法 净评估是一类交互性、辩证性、对抗性的战略分析方法,最早由马歇尔提出,依赖多学科知识框架,当前已然成为美国战略评估的核心方法。基于SWOT-CLPV的竞争优势分析是净评估的基本模式[49],如表2所示。 表2 SWOT-CLPV矩阵 Table 2 Matrix of SWOT-CLPV
机遇 (Opportunities) 威胁 (Threat) 优势 (Strengths) 杠杆性 (Leverage) 脆弱性 (Vulnerability) 劣势 (Weaknesses) 抑制性 (Control) 问题性 (Problem)
场景分析(Scenario Analysis)、假想敌机制和模型模拟工具是净评估的常用方法[50],其中情景分析法通常“如果-怎样”的方式,分析各种假设、推演各种可能的结果。娄伟[51]对情景分析方法做了区分:定性与定量情景分析,演绎与归纳情景分析,前推式与回溯式情景分析,预测性、探究性与预期性情景分析,描述式与规范式情景分析,基准与可选择性情景分析等。为保持情景内部的一致性,一些研究提出利用形态分析(Morphological Analysis)来构建情景分析框架[52]。 (2) 战略兵棋推演 战略兵棋主要对战争层面主要因素进行模拟,可用于辅助国家领导层的决策、国家安全及军事战略的检验等,参与主体是国家或军队战略层的决策人员,推演问题主要包括国际冲突,政治、经济及外交政策,军事力量建设与运用,军事行动中战争计划的制定等全局性问题。“兰德战略评估系统”主要包括自动化兵棋推演、基于规则建模、结构化兵力分析与作战行动建模四部分,将兵棋推演与仿真建模融合[30],可用于国家政策层面的战略规划、多国联合军事演习和军事理论创新。 (3) 群体决策方法 20世纪80年代钱学森等提出了利用综合集成研讨厅来解决开放复杂巨系统的方法论。综合集成方法采用“以人为主、人机结合,定性定量结合”的方式,为专家提供交互启发的研讨平台环境,将来同领域专家的智慧集成起来,实现“1+1>2”的涌现效果。赵晓哲等[53]提出利用综合集成方法研究军事系统问题,王丹力等[54]综述分析了综合集成研讨厅体系的起源、发展现状与未来趋势,郑楠等[55]分析了综合集成研讨中人-机结合的3个层次(初等结合、人机协同、人机融合)。 为了充分发挥多个领域不同专家的优势,一些研究分析了群体规模更庞大时的大群体决策问题。由于有众多决策者的参与,每个决策主体会根据自身的立场给出备选方案及偏好倾向,为了保证决策因素考量的全面性、决策条件更加实际同时提高决策科学性,需要将多个个体的决策判断及偏好集结为大群体的判断及偏好,形成关于备选方案的最佳选择。当前围绕大群体决策的相关研究可区分为三大类:多属性大群体决策方法(偏好表达形式、权重确定方法、偏好聚类方法、偏好集结方法等),冲突性大群体决策方法(冲突测度、冲突消解、决策主体行为等),风险性大群体决策方法(偏好风险、后悔与前景等心理行为、证据推理及语言挖掘等)[56],其中基于前景理论的相关研究为风险认知、鲁棒决策提供了理论指引[57]。 (4) 博弈分析方法
- 冲突分析方法。早前Schelling等[58]采用博弈论来分析冲突问题。近些年,围绕冲突分析的方法论经历了3个阶段:元博弈分析[59]、F-H冲突分析方法[60],冲突分析图模型[61]。围绕冲突消解图模型(graph model for conflict resolution, GMCR),多位学者陆续作出了全面的理论梳理与扩展。Fang等[62]提出了GMCR的逻辑结构,Kilgour等[63]从群体决策与协商视角对冲突分析相关方法,Sage[64]基于GMCR模型开发了辅助解决现实冲突问题的决策支持系统。此外,Zhou等[65]采用文献计量方式对GMCR进行了综述分析,Hipel等[66]对近30年来的GMCR发展进行了全面综述分析,Fang等[67]对多类面向冲突分析的决策支持系统(GMCR I、GMCR II、GMCR+)进行了分类分析。Hipel等[68]从偏好不确定性(未知、模糊、灰度、概率),解概念(纳什稳定性、一般元理性、对称元理性、序贯稳定性、对称序贯稳定性、混合两步稳定性、混合对称元理性、有限步理性、非短视稳定性)对GMCR进行了对比分析。围绕冲突分析的相关研究主要关注偏好排序与不确定性偏好度量,心理因素(态度、情感、误解、欺骗),联盟分析等。近年来,反向视角下的冲突分析主要通过期望均衡态势反向探索偏好可能,可用于控局塑势、第三方调解、干预与谈判。围绕冲突分析的3个典型视角主要包括前向分析、反向分析与行为分析视角,如图4所示。
图4
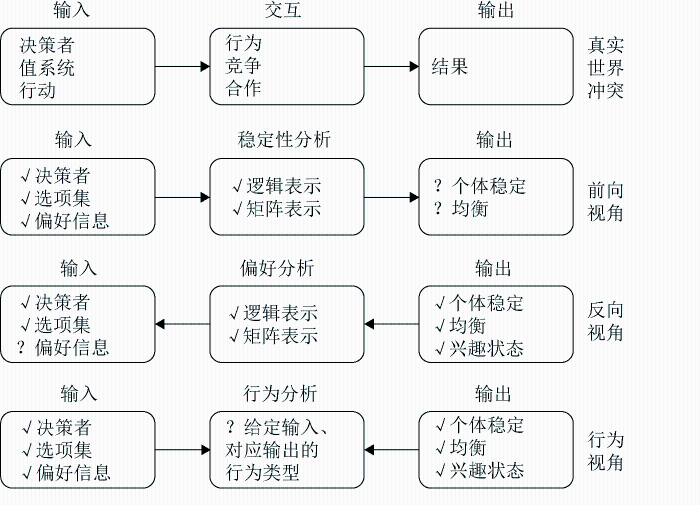
图4 冲突分析研究的三类视角
Fig. 4 Three perspectives of conflict analysis research
- 对抗分析方法。由于冲突分析方法立足全局对战略博弈进行分析,忽略了博弈对抗的多阶段交互过程及细节。早期的戏剧理论采用随意性陈述,对抗分析的核心是将博弈交互过程比拟成戏剧,基于决策者的立场、意图、质疑等主观因素分析冲突困境之间的转化与消除,为战略博弈多阶段推演提供了方案。Howard基于戏剧理论(drama theory)与冲突困境分析(conflict dilemma analysis)提出了对抗分析(confrontation analysis)框架[69]。Bennett [70]构建了面向解决冲突的对抗分析模型,主要包括场景设置、各阶段状态转换、最终结果等。Bryant跟踪分析中东冲突演化[71],全面分析了围绕策略性行动的戏剧理论[72]。Curry等[73]利用对抗分析建模国际冲突的结果,总结扩展了对抗分析中的五类困境(说服、信任、合作、威胁、拒绝)[74]。Fang等[67]对多类面向对抗分析的决策支持系统(Conan, INTERACT, Dilemma Explorer)进行对比。Smith等[75]设计的Decision Commander (C2CC)通过模拟博弈方之间的对抗与合作关系制定对抗策略,Crannell等[76]设计了Confrontation Manager,并提出了快速对抗分析方法。


