增强外部数据的大型语言模型(LLMs)在完成现实任务方面展现出卓越的能力。外部数据不仅增强了模型的领域特定专业知识和时间相关性,还减少了幻觉现象,从而提升了输出的可控性和可解释性。将外部数据集成到LLMs中的技术,如检索增强生成(RAG)和微调,正受到越来越多的关注和广泛应用。然而,数据增强LLMs在各个专业领域的有效部署面临重大的挑战。这些挑战涵盖了广泛的问题,从检索相关数据和准确理解用户意图,到充分利用LLMs在复杂任务中的推理能力。我们认为,数据增强LLM应用没有通用的解决方案。在实践中,表现不佳往往源于未能正确识别任务的核心重点,或是因为任务本质上需要多种能力的结合,这些能力必须分解以便更好地解决。在这项调查中,我们提出了一种RAG任务分类方法,根据所需外部数据类型和任务的主要重点将用户查询分为四个层级:
显性事实查询、隐性事实查询、可解释的推理查询和隐含推理查询。我们定义了这些查询层级,提供相关数据集,并总结了应对这些挑战的关键挑战和最有效的技术。最后,我们讨论了将外部数据集成到LLMs中的三种主要形式:上下文、小模型和微调,强调它们各自的优缺点及适合解决的问题类型。本研究旨在帮助读者全面理解和解析构建LLM应用的数据需求和关键瓶颈,提供针对不同挑战的解决方案,并作为系统开发此类应用的指南。
引言
大型语言模型(LLMs)展现出卓越的能力,包括广泛的世界知识和复杂的推理技能。尽管取得了这些进展,在各种专业领域有效部署LLMs仍面临重大挑战。这些挑战包括模型幻觉、与领域特定知识的不一致等问题。整合领域特定数据,特别是无法包含在初始训练语料中的私有或本地数据,对于定制LLM应用以满足特定行业需求至关重要。通过像RAG和微调这样的技术,数据增强的LLM应用在多个方面展示了相较于仅基于通用LLMs构建的应用的优势:
-
增强的专业性和时效性:用于训练LLMs的数据往往滞后,且可能未能全面覆盖所有领域,特别是用户拥有的专有数据。数据增强的LLM应用通过提供更详细和准确的复杂问题答案,允许数据更新和定制,从而解决了这一问题。
-
与领域专家的对齐:通过使用和学习领域特定数据,数据增强的LLM应用可以展现更像领域专家(如医生和律师)的能力。
-
减少模型幻觉:数据增强的LLM应用基于真实数据生成响应,将其反应扎根于事实中,从而显著减少幻觉的可能性。
-
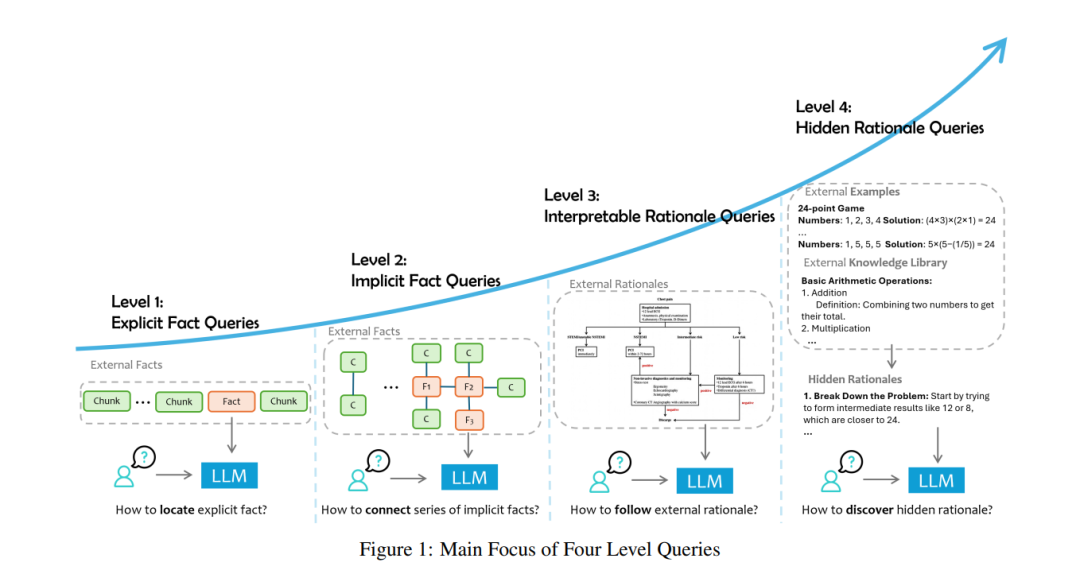
改进的可控性和可解释性:所使用的数据可以作为模型预测的参考,从而增强可控性和可解释性。 尽管对这些进展充满热情,开发人员通常面临挑战,并需要投入大量人力以满足预期(例如,达到高成功率的问答)。许多研究 [1, 2, 3, 4, 5] 强调了构建基于RAG和微调等技术的数据增强LLM应用所面临的挑战和挫折,尤其是在法律、医疗、制造等专业领域。这些挑战涵盖广泛的范围,从构建数据管道(如数据处理和索引)到利用LLMs的能力实现复杂的智能推理。例如,在金融应用中,通常需要理解和利用高维时间序列数据,而在医疗领域,医疗图像或时间序列医疗记录通常至关重要。使LLMs能够理解这些多样的数据形式是一个反复出现的挑战。另一方面,在法律和数学应用中,LLMs通常难以掌握不同结构之间的长距离依赖关系。此外,根据特定应用领域,对LLM响应的可解释性和一致性有更高的需求。LLMs的固有特性往往表现为低可解释性和高不确定性,这带来了显著的挑战。增强LLMs的透明度并降低其不确定性对于提高其输出的信任度和可靠性至关重要,尤其是在精确性和问责制至关重要的领域。通过与领域专家和开发人员的广泛讨论,并仔细分析他们面临的挑战,我们深刻理解到数据增强的LLM应用并非通用解决方案。现实世界的需求,特别是在专家领域,具有高度复杂性,并且在与给定数据的关系以及所需推理的困难程度上可能有显著差异。然而,开发人员常常未能意识到这些区别,最终导致解决方案充满性能陷阱(就像一个到处漏水的房子)。相反,如果我们能够全面理解不同层级的需求及其独特挑战,我们就可以相应地构建应用,并使应用逐步改善(就像一步一步构建一个坚固可靠的房子)。然而,研究工作和现有相关调查 [6, 7, 8, 9, 10, 11, 12, 13] 通常只关注其中一个层级或特定技术主题。这促使我们编写这份全面的调查,旨在清晰定义这些不同层级的查询,识别与每个层级相关的独特挑战(见图1),并列出相关的研究和应对这些挑战的努力。此调查旨在帮助读者构建数据增强LLM应用的全景视图,并作为系统开发此类应用的手册。
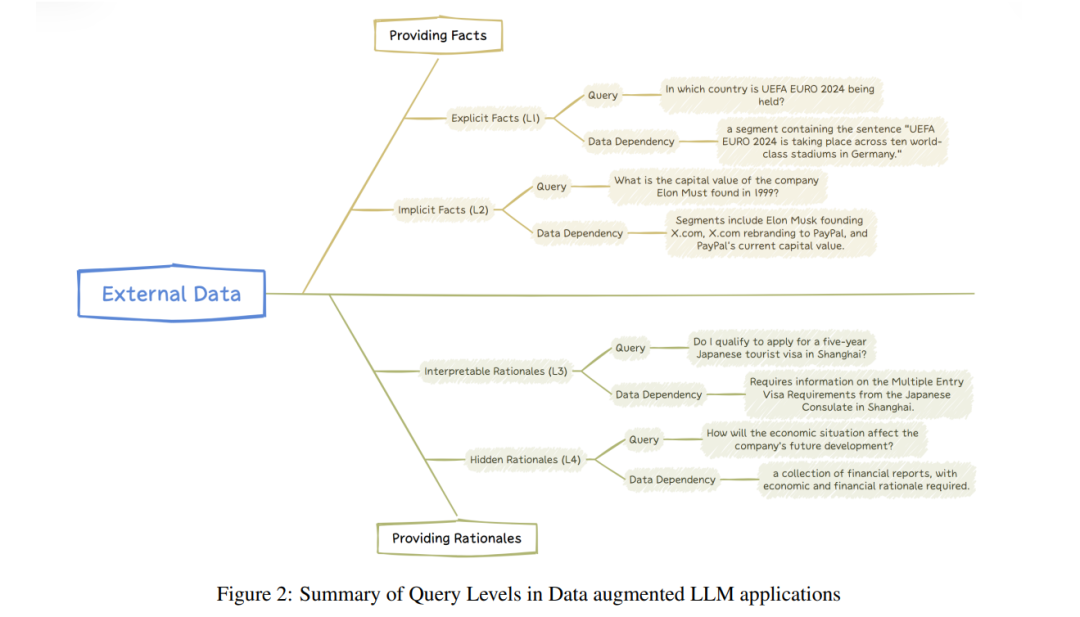
在数据增强LLM应用的领域中,查询可以根据其复杂性和所需数据交互的深度进行分层。这种分层有助于理解LLM生成准确和相关响应所需的不同认知处理水平。从简单的事实检索到对隐含知识的细致解读,每个层级代表了LLM处理任务的复杂性上升。以下是这些层级的详细说明,提供了各阶段所需的独特挑战和能力的洞察。
第一级:显性事实
这些查询直接询问给定数据中明确存在的事实,无需任何额外推理。这是最简单的查询形式,模型的任务主要是定位和提取相关信息。例如,“2024年夏季奥运会将在何处举行?”这是一个目标明确的事实查询。
第二级:隐性事实
这些查询询问数据中的隐性事实,这些事实并不显而易见,可能需要一定的常识推理或基本逻辑推导。所需的信息可能分散在多个部分,或需要简单的推断。例如,“堪培拉所在国家目前的执政党是什么?”可以通过结合“堪培拉在澳大利亚”与“澳大利亚当前执政党”来回答。
第三级:可解释的推理
这些查询不仅要求理解事实内容,还需要掌握和应用特定领域的推理,这些推理与数据的上下文密切相关。这些推理通常在外部资源中明示提供,在通用大型语言模型的预训练阶段中通常不会出现或很少遇到。例如,在制药领域,LLM必须解读FDA指南文件——这代表了FDA的最新观点——以评估特定药物申请是否符合监管要求。同样,在客户支持场景中,LLM必须导航预定义工作流程的复杂性,以有效处理用户询问。在医疗领域,许多诊断手册提供权威和标准化的诊断标准,例如急性胸痛患者的管理指南。通过有效遵循这些外部推理,可以开发一个专门的LLM专家系统来管理胸痛,这涉及理解支持人员与客户互动时的程序步骤和决策树,确保响应不仅准确,还符合公司的服务标准和协议。
第四级:隐含推理
这一类查询深入探讨更具挑战性的领域,其中推理并没有明确记录,而必须从外部数据中观察到的模式和结果中推断出来。这些隐含推理不仅指隐含的推理链和逻辑关系,还包括识别和提取每个特定查询所需的外部推理的内在挑战。例如,在IT运营场景中,云运维团队可能已经处理了众多事件,每个事件都有其独特的情况和解决方案。LLM必须善于从这一丰富的隐性知识库中挖掘,以识别成功的隐性策略和决策过程。同样,在软件开发中,以前bug的调试历史可以提供丰富的隐性见解。虽然每个调试决策的逐步推理可能没有系统记录,但LLM必须能够提取指导这些决策的基本原则。通过综合这些隐含推理,LLM可以生成不仅准确,还反映出经验丰富的专业人员长期以来所积累的无形专业知识和解决问题的方法。
总之,查询的层级分类反映了复杂性梯度和LLM所需理解的类型。如图1所示,并在图2中举例,前两个层级——显性事实和隐性事实,侧重于检索事实信息,无论是直接陈述的还是需要基本推断的。这些层级挑战着LLM提取和综合数据成连贯事实的能力。相反,后两个层级——可解释的推理和隐含推理,则将重点转向LLM学习和应用数据背后推理的能力。这些层级要求更深层次的认知参与,LLM必须与专家思维对齐或从非结构化历史数据中提取智慧。根据这一标准,常见的事实查询数据集的分类见表1。
每个层级都有其独特的挑战,因此需要量身定制的解决方案来有效应对它们。在接下来的章节中,我们将深入探讨这些层级的复杂性,探索使LLM能够在各种查询类型中导航数据增强应用的具体策略和方法。这一探索不仅将突显LLM当前的能力,还将揭示该领域的持续进展和潜在未来发展。