来自中科院计算所的杨传广博士论文,入选2024年度“CCF博士学位论文激励计划”初评结果! https://www.ccf.org.cn/Awards/Awards/2024-11-15/834347.shtml
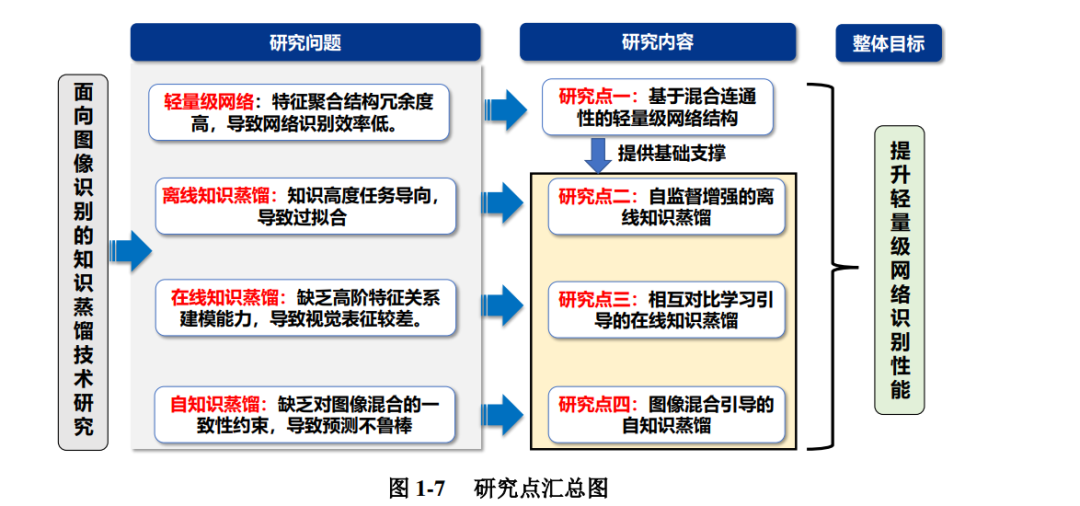
深度卷积神经网络(Convolutional Neural Networks,CNN)已经被广泛地用 于计算机视觉任务,包括图像分类、目标检测和语义分割等。相比于传统神经网 络,CNN 采用了卷积和池化等操作自动提取图像特征,并且通过增加网络的深 度提升模型拟合能力。计算复杂度与模型参数量的增加造就了 CNN 识别精度的 显著提高,但也导致了其存储和计算代价高昂,因而制约了网络在移动端的应 用。采用参数量少的轻量级网络可以应用于资源受限的场景,但是如果按照常 规的方法直接进行训练,往往识别精度较差,难以满足性能要求。图灵奖得主 Hinton 认为知识蒸馏技术是一种能够在神经网络间传递知识的有效手段,为此 本文研究面向图像识别的知识蒸馏技术,通过探索有价值的知识引导轻量级网 络的训练,以提升其识别性能。为了实现上述研究目标,本文首先提出了一种轻 量级网络结构,为知识蒸馏训练算法提供基础的模型支撑;接下来,按照不同的 训练模式,分别研究了离线知识蒸馏、在线知识蒸馏和自知识蒸馏。具体研究内 容如下:
(1) 提出基于混合连通性的轻量级网络结构 知识蒸馏技术需要设计学生网络作为接受知识的轻量化载体,但是现有轻 量级网络通常特征聚合冗余度高,导致图像识别效率低。为此,本文首先设计了 一种基于混合连通性门网络(Hybrid Connectivity with Gate Networks,HCGNet) 的轻量级网络结构,包括构成网络的压缩多尺度激活门(Squeeze, Multi-scale excitation and Gate,SMG)模块和混合连通性的特征聚合模式。SMG 模块包含压 缩单元和多尺度激活单元来提升特征学习,并引入更新门和遗忘门来对特征进行 自适应调节。混合连通性的特征聚合模式在全局使用密集网络(Dense Networks, DenseNet)连接,在局部使用残差网络(Residual Networks,ResNet)连接,因 此该模式既能具备 DenseNet 的高效特征学习能力,又可以拥有 ResNet 的参数共 享机制,解决了 DenseNet 结构冗余度高的问题。在图像数据库(ImageNet)和 由加拿大高等研究院(Canadian Institute For Advanced Research,CIFAR)出版 的 CIFAR-100 数据集上,HCGNet 凭借更少的参数量和计算复杂度超越了流行的 ResNet 和 DenseNet 等网络。与 DenseNet 相比,HCGNet 获得了 2.3% 的 ImageNet 准确率提升和 1.75 倍的加速,表明 HCGNet 具有更好的识别效率,冗余度低。
(2) 提出自监督增强的离线知识蒸馏方法 离线知识蒸馏是通过使用预训练的教师网络指导轻量级学生网络学习的方 法。现有离线知识蒸馏算法通常只在原始任务上进行蒸馏,因此传递的知识存 在高度任务导向的特点,导致模型易产生过拟合的问题。本文提出了一种层级 自监督增强的知识蒸馏方法(Hierarchical Self-Supervision Augmented Knowledge Distillation,HSSAKD)。该方法的核心思想是在离线知识蒸馏中引入了一种自监 督增强的辅助任务来使得教师网络和学生网络产生自监督增强的知识分布,之后引导学生网络去学习教师网络所产生的信息。在图像分类数据集 CIFAR-100 和 ImageNet 上,HSSAKD 训练的轻量级网络结构相比基线分别获得了 6.0% 和 2.2% 的平均准确率提升。在 HCGNet-C 网络的监督下,HCGNet-B 通过 HSSAKD 方法 在 ImageNet 数据集上相比基线提升了 1.7% 的准确率。在自主学习(Self-Taught Learning,STL)-10 和微小版 ImageNet(TinyImageNet)数据集上的零样本迁移 实验结果上,HSSAKD 相比基线分别获得了 6.9% 和 7.9% 的准确率增益。实验 结果显示 HSSAKD 不仅在训练任务上超越了同类方法,在零样本的迁移实验上 也具备优越的表现,表明此方法提升了网络的泛化能力,缓解了过拟合问题。
(3) 提出相互对比学习引导的在线知识蒸馏方法 在线知识蒸馏是同时训练多个网络,并在网络间互相传递知识的方法。现有 在线知识蒸馏算法仅在类别概率层面进行蒸馏,缺乏在高阶特征关系层面的建 模能力,导致模型学习到的视觉表征较差。本文提出了一种逐层相互对比学习 (Layer-wise Mutual Contrastive Learning,L-MCL)引导的在线知识蒸馏方法。该 方法的核心思想是在多个网络之间使用交互式对比学习来促进知识交互,即锚 样本与对比样本来自于不同的网络,优化该误差被本文从理论上证明等价于最 大化两个交互网络互信息的最低界,从而可以相互学习到对方的特征表达信息。 在图像分类数据集 CIFAR-100 和 ImageNet 上,L-MCL 训练的轻量级网络结构相 比基线分别获得了 4.7% 和 1.6% 的平均准确率提升。HCGNet 通过 L-MCL 方法 在 ImageNet 数据集上相比基线得到了 1.2% 的准确率提升。L-MCL 训练的特征 提取器迁移到上下文常用目标(Common Objects in COntext,COCO)-2017 的目 标检测和分割任务上相比基线分别获得了 1.7% 和 1.8% 的检测精度提升,表明 了相互对比学习引导网络学习到了优越的视觉表征。
(4) 提出图像混合引导的自知识蒸馏方法 自知识蒸馏是仅采用一个网络,通过优化网络对于不同图像增强的预测分 布,来实现网络精度提升的方法。现有自知识蒸馏算法缺乏对图像混合的一致性 约束,导致模型不能产生鲁棒的预测分布。本文提出了一种图像混合引导的自知 识蒸馏(Mixture-guided Self-Knowledge Distillation,MixSKD)方法,通过引入图 像混合(Mixup)技术,并将其与自蒸馏规则化为一个联合的框架。该方法核心 思想是对于 Mixup 混合图像概率预测分布与两张原始图像集成的概率预测分布 进行一致性的约束,进而使得网络对特征空间和输出概率表现出线性行为。在图 像分类数据集 CIFAR-100 和 ImageNet 上,MixSKD 训练的轻量级网络结构相比 基线分别获得了 3.0% 和 1.3% 的平均准确率提升。HCGNet 通过 MixSKD 方法在 ImageNet 数据集上相比于基线得到了 0.8% 的准确率提升。通过对样本的攻击实 验以及对预测标签的对数概率直方图统计,MixSKD 提升了网络预测分布的鲁棒 性。