分享嘉宾:付子玉 观澜网络 算法工程师 编辑整理:孙佩霞 中国电信研究院 出品平台:DataFunTalk
**导读:**丁香园大数据组旨在为用户提供更优质的内容与服务,使用知识/概念图谱、预训练模型挖掘更深层次的用户意图。本文介绍了丁香园nlp组联合华师大团队发表的文章SMedBERT,在医疗垂直领域下将知识图谱的医学实体和实体的结构化信息引入到预训练模型中,并介绍了丁香园在业务场景下的一些应用。全文主要由四个模块组成: * 业务场景介绍 * 医疗图谱构建 * ACL|SMedBERT * 工业落地和思考
01
丁香园业务场景概述
丁香园起点是打造一个专业的医学学术论坛,为医生、医学生、医疗从业者等提供一个信息交流的平台。丁香园的主要用户是医疗从业人员,会在论坛上发布考博、规培分数线、求助医疗文献等内容。随着业务的不断扩展,发展出了丁香医生、丁香妈妈等APP,为大众用户提供了一个健康信息平台。

目前丁香园从早期的医生用户扩展到了大众用户,实现了ToD(To Dcotor),ToC双核心驱动,业务会覆盖这两类人群的日常需求。比如,对医生为主的医疗从业者来说,会涉及到日常的学术问题、经验分享、疑难病例的讨论以及查阅药品说明书、诊疗指南等。对大众用户来说,包括线上问诊、科普知识、健康商城等服务。在2021年,丁香园C端规模达到1.2亿,医生端拥有全国70%的医生作为注册用户。

02
医疗图谱构建
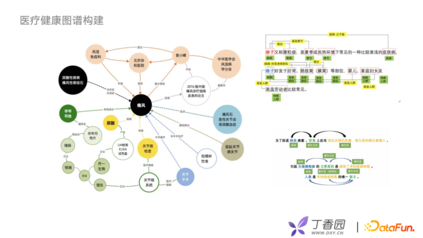
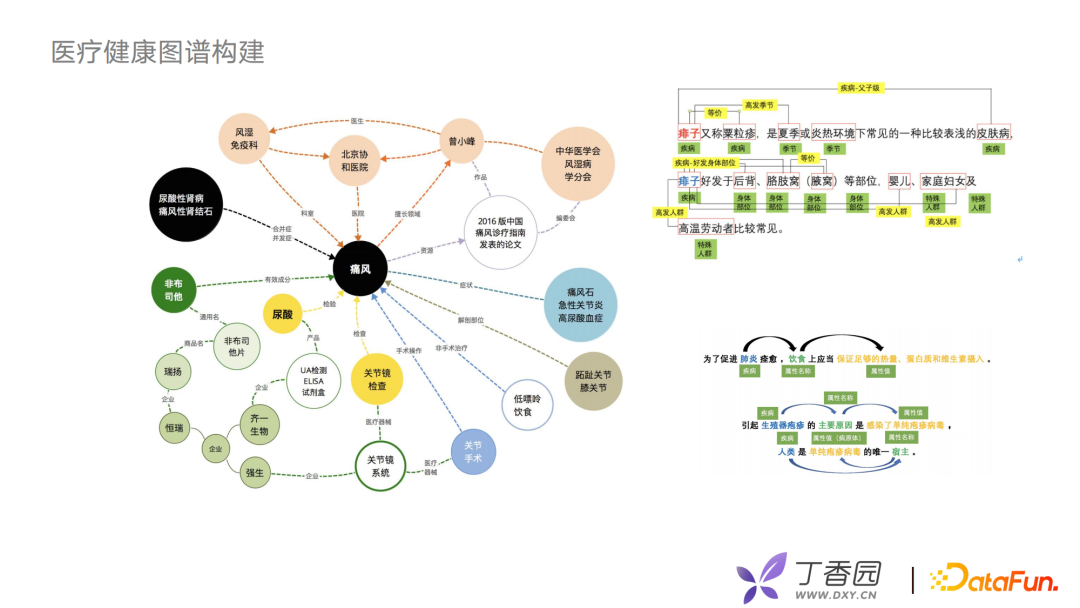
首先介绍一下丁香园应用到的医疗健康图谱。医疗健康图谱构建由专业的医疗团队来维护,有医学背景相关同事维护疾病、症状、手术、药品等医学概念以及60多种医学关系。同时,丁香园nlp组会用一些算法去抽取和意图分类等工作,利用算法与人工相结合的方式对实体、关系、实体属性进行扩充。因为丁香园业务模式较多,需要考虑在图谱应用上如何做迁移、融合工作。
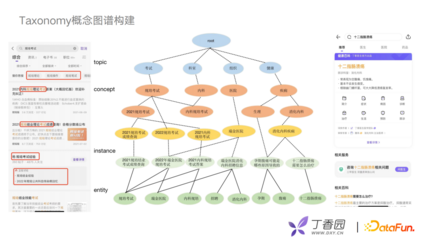
为更好的去分析用户意图,构建用户画像,在实际工作中我们使用一种Taxonomy概念图谱。例如,搜索十二指肠溃疡,丁香医生会给出一个搜索结果:“十二指肠溃疡怎么去治疗”,它是消化内科的一个疾病,可以将其定义为一个消化内科的概念。在丁香园搜索规培考试,给对应的规培考试内容标注相关的标签,比如成绩查询、内科的标签考试答案等。
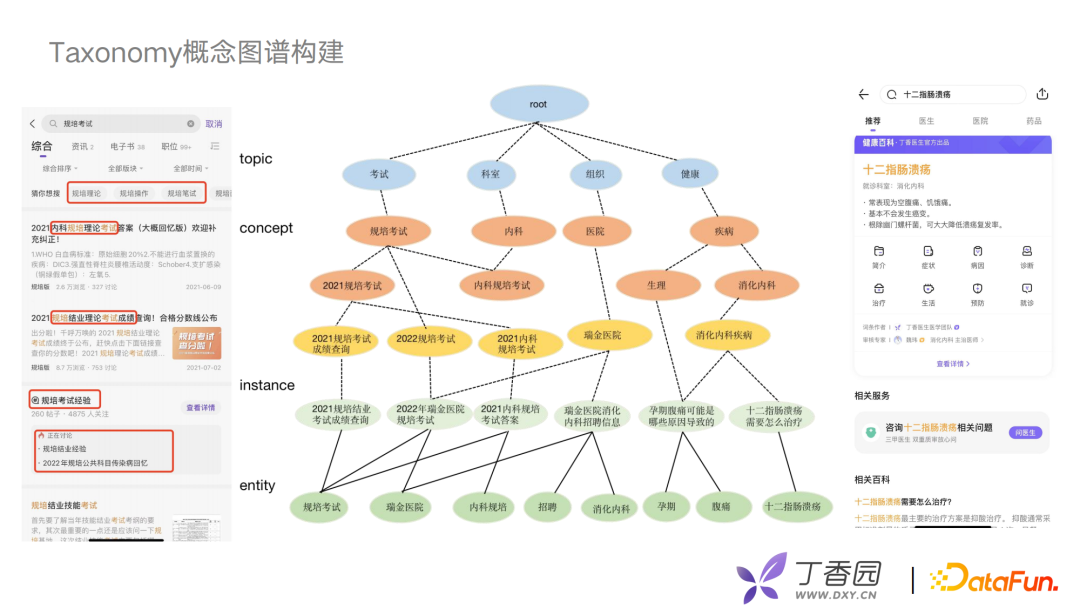
概念图谱会以一个四层结构构建: 第一层底层是entity实体层,例如规培考试、十二指肠溃疡、腹痛等。 往上一层是instance层,也就是文章内容。例如十二指肠溃疡怎么治疗。 concept层是概念层,可以根据文章的用户点击行为、搜索行为、内容聚类,抽象到上层的concept概念结构,比如十二指肠溃疡对应的是消化内科的一种疾病。 最上面一层,建立与业务强相关的topic层。 利用层级关系对长短文本进行多层次、丰富主题的刻画,去分析、理解用户的搜索行为。
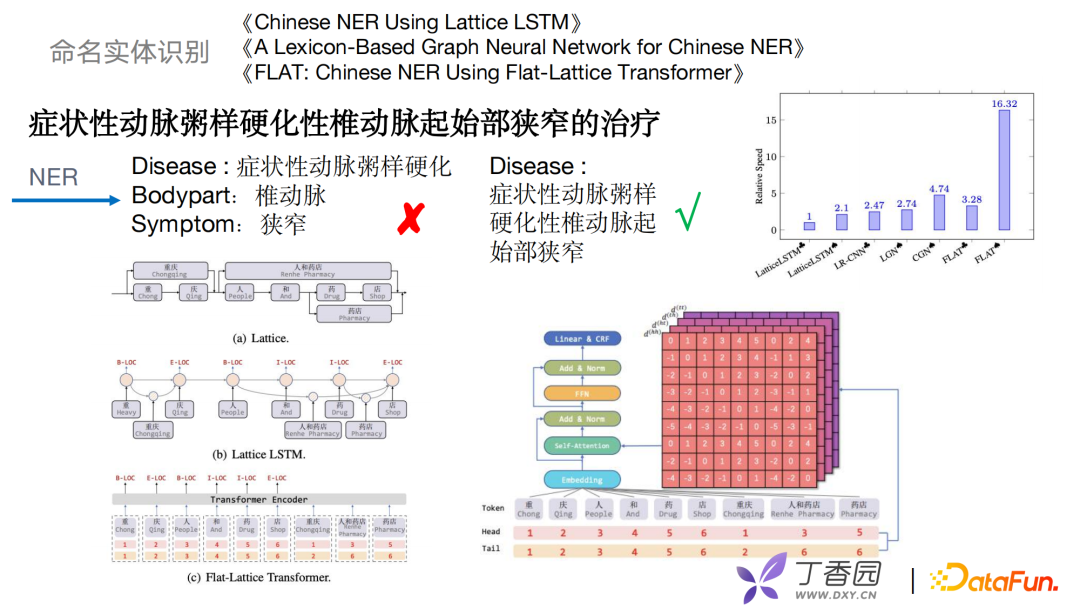
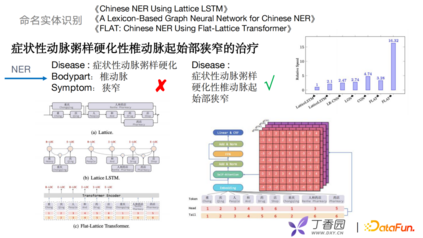
之前提到了两种知识图谱的构建,接下来介绍如何使用算法去优化命名实体识别、关系抽取等。举一个命名实体识别的例子,如“症状性动脉粥样硬化性椎动脉起始部狭窄的治疗”,常规NER可能会把这个识别成三个实体: * 疾病:“症状性动脉粥硬化” * 身体部位:“椎动脉” * 症状:“狭窄”
但这整个长句是属于一个完整的疾病。早期抽取的方式会充分地理解句中显式的词和词序信息。近几年采用一些格子结构做LSTM,把词的表征和潜在的词信息整合到字符CRF中去。如2018年Lattice提到把每个字作为词根或者词尾加入到模型训练中。到2019年Lattice LSTM把类似的短语用Lexicon的方式把字和词构建一个graph,再把graph特征融合到NER。但这种方式的复杂度非常高,而且耗时长。在2020年复旦大学提到FLAT的方式,引入了Transformer结构,利用Transformer的self-attention解决长文本依赖问题。FLAT可以充分利用Transformer格子结构,具备出色的并行化的能力,效率上得到了很大的提升。
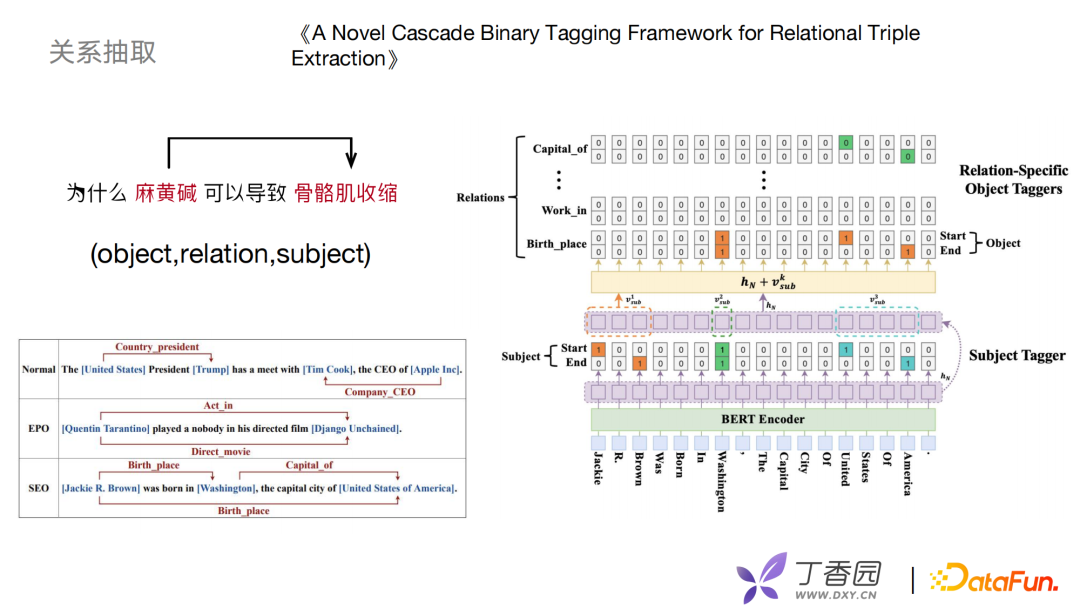
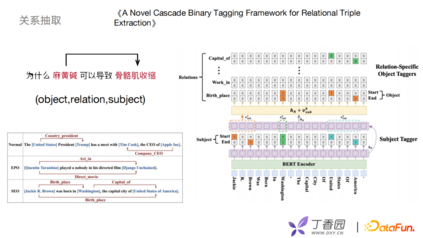
图谱构建中肯定涉及关系抽取工作,早期关系抽取采用pipeline的方式进行,先做实体识别再做关系分类。但是,pipeline的方式可能会造成实体识别错误,间接会导致关系抽取也出现问题。借鉴了《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》文章联合学习的方式,实现二分标注的框架。该框架对object、relation、subject 做函数映射,而不像以前地方式去做离散的标签。它分为两个模块subject Tagger和 relation-specific object Taggers:subject Tagger先使用一个二分类去识别出subject的起始位置和结束位置,拿到subject去做表示特征,然后根据关系做一个多分类任务。每一个关系,都是一个二分类识别。根据映射得到object起始位置和结束位置,这样以一种联合的方式拿到实体关系三元组。
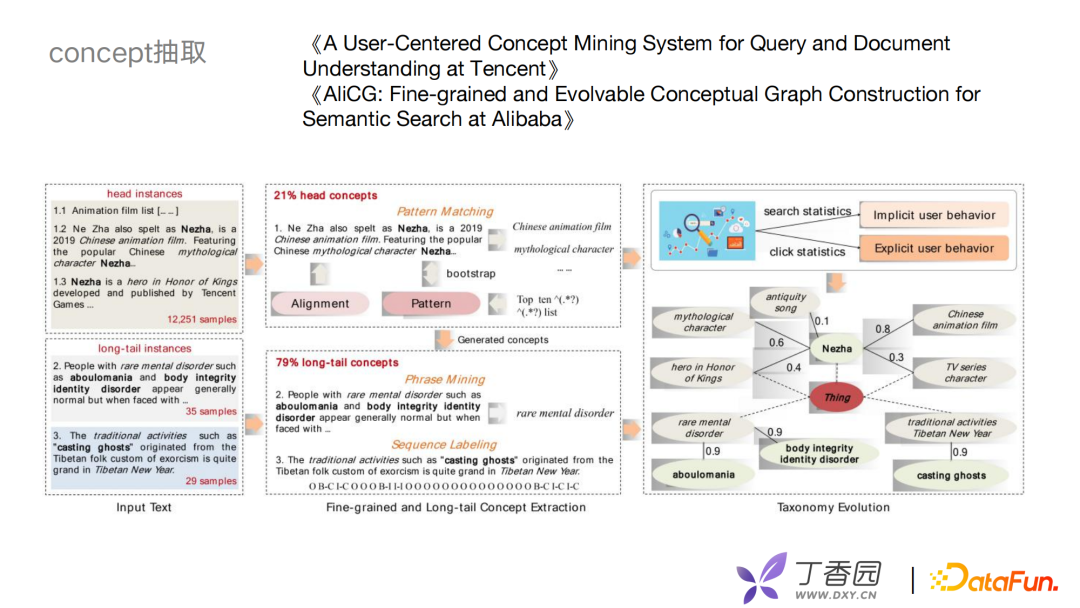
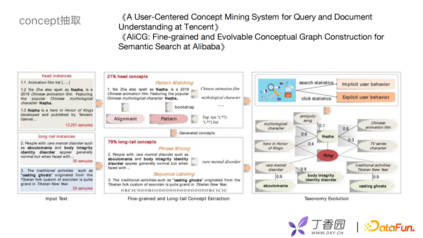
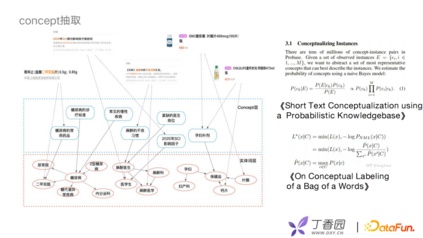
构建概念图谱首先要解决两个问题,第一个问题是如何抽取concept,第二个问题是如何构建concept之间的层级关系,这里借鉴了两篇论文,分别是腾讯的《A User-Centered Concept Mining System for Query and Document Understanding at Tencent》和阿里的《AliCG: Fine-grained and Evolvable Conceptual Graph Construction for Semantic Search at Alibaba》。 在实体抽取方面,主要分为头部和尾部两部分。头部的instance,由于头部的文章内容丰富,可以用模板去识别。长尾部一直都是比较难的问题,可以通过Phrase Mining,或者数据标注的方式解决。如何构建概念间的层次关系?可以通过用户的搜索点击行为去计算文章和概念的关联程度,根据关联程度判断概念之间的层级。
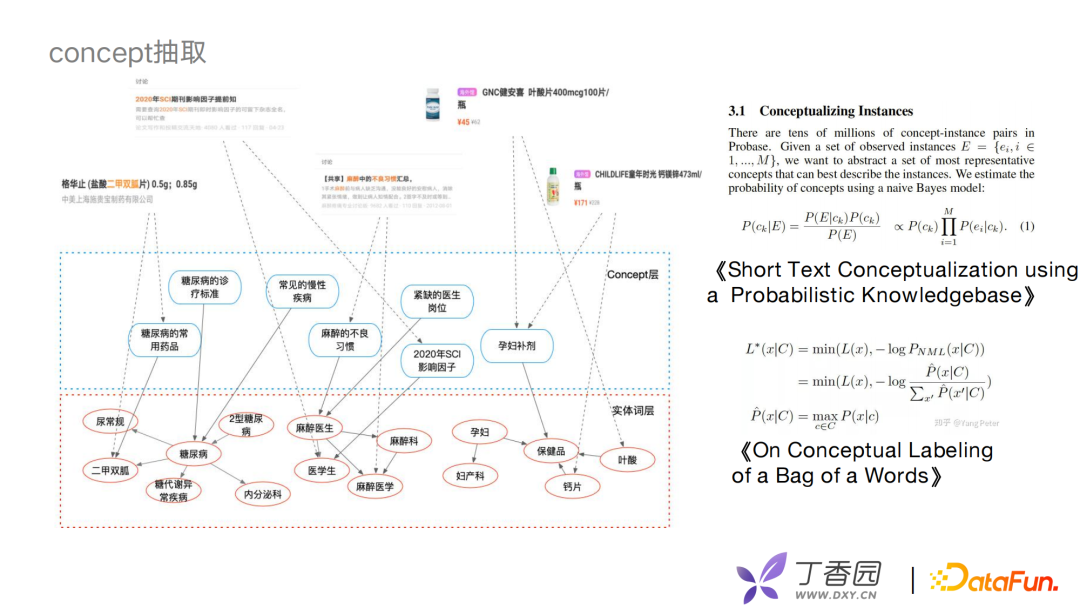
利用concept层次联合底层的专业医学实体和上层的业务,构建一个完整的业务图谱。以贝叶斯模型为基础去判断一对一的边关系,考虑全局的统计量或者文本的局部特征,生成一些多边的关系。我们借鉴了王仲远老师的一些相关工作,如MDL的原则等去做concept筛选。例如,论坛帖子、药物、商品信息等可以通过中间的concept层与实体之间进行关联。
03
SMedBERT
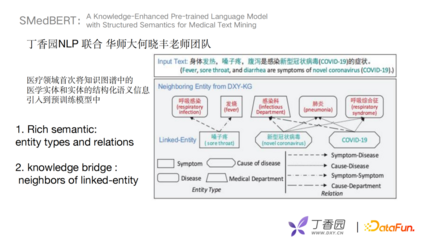
接下来介绍去年丁香园NLP组联合华师大何晓丰老师团队在ACL发表的文章《A Knowledge-Enhanced Pre-trained Language Model with Structured Semantics for Medical Text Mining》。这篇文章在医疗垂直领域下首次将知识图谱的医学实体和实体的结构化语义信息引入到预训练模型中。
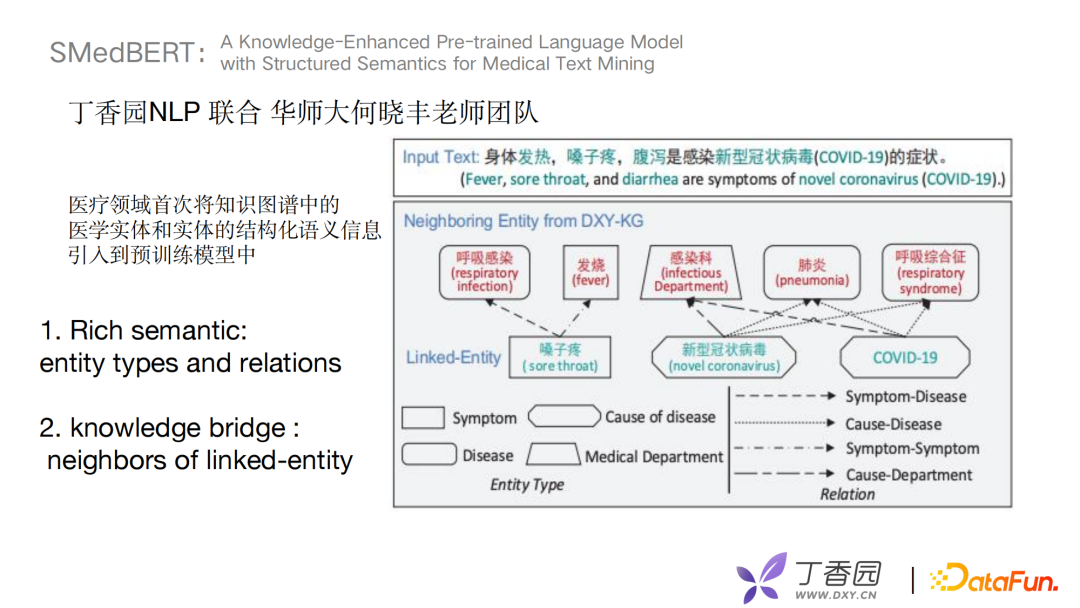
SMedBERT优化方向主要有两个,第一个考虑实体类别和关系来丰富语义, 第二个是构建knowledge bridge,将有一跳连接关系的邻居实体加入预训练模型中。
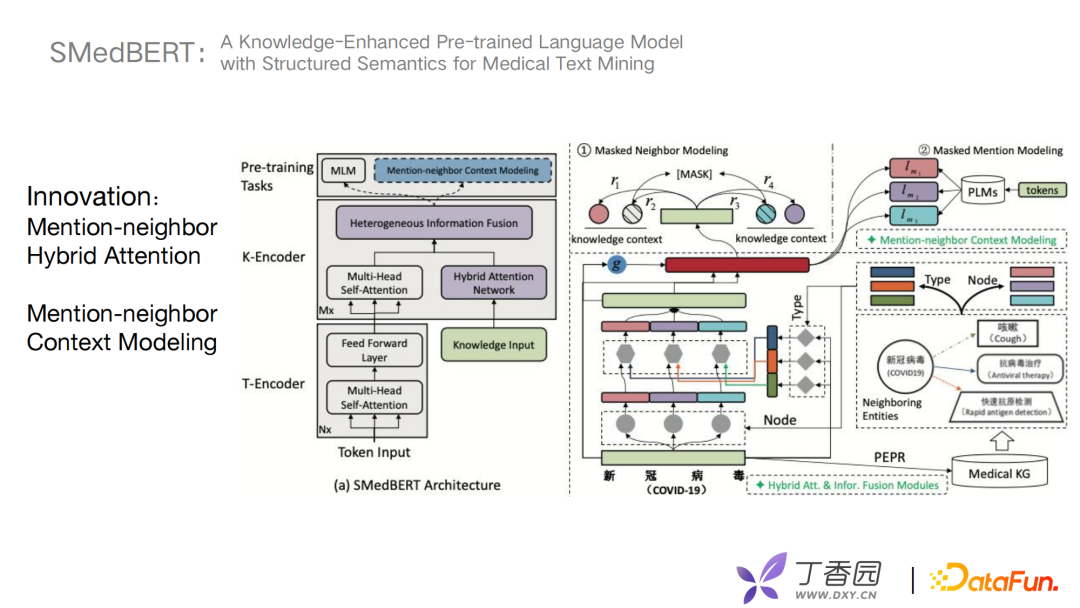
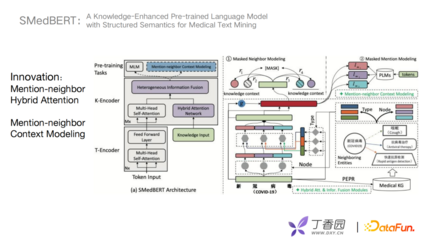
SMedBERT对于结构信息捕捉,有两个创新点:
首先是Mention-neighbor Hybrid Attention用来学习捕捉异构实体信息。什么是异构实体信息?图谱中有一个新冠病毒节点,与它相关的节点有疾病症状、治疗方案、检测方法等。将与新冠病毒节点一跳的相关实体取出,根据type和节点node信息融合到encoder层。 第二个创新点是Mention-neighbor Context Modeling,主要是将链接实体的上下文信息做mask处理去预测。模型主要由三个模块组成T-Encoder、K-Encoder、Pre-training Tasks。首先T-Encoder可以挑选出比较重要的相邻实体,使用方法是类似于PageRank的一种方式。其次K-Encoder进行mask操作,self attention获得关键实体的信息,对mask任务进行融合。
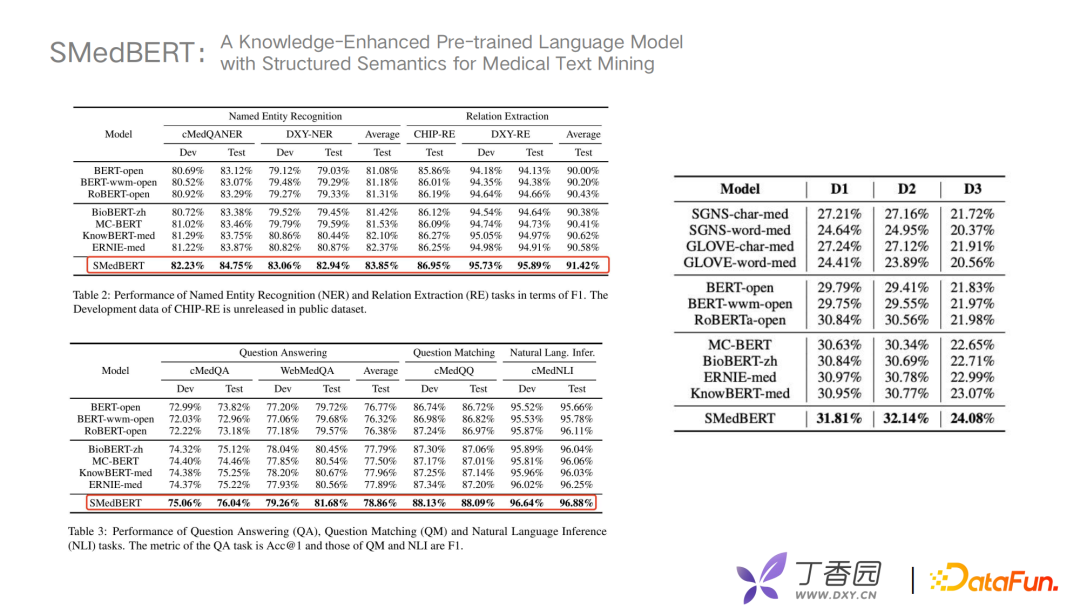
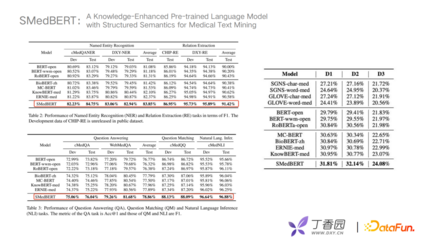
在训练数据方面,我们收集了约5G大小的中文医疗文本、30亿左右的token。在实验对比上,选择了openkg、丁香园的KG、丁香园的RE;在Graph Embedding上选用Trans-R;在验证数据上选择了四组公开数据集如CHIP、WebMedQA等进行比较;在模型方面选择了Bert、RoBert、Knowledge-Bert等进行比较。从对比效果上来看准确率有很高的提升,并且在多个任务上都有明显提升效果,然后对不同模型进行实体Embedding相似性能力比较。
D1、D2、D3,主要对不同程度的邻实体覆盖进行划分。如D2使用了高频重合的实体,D3是低频实体去做比较。实验表明SMedBert对具有结构信息的捕捉能力较强。最终我们得到一个结论,将相邻相似实体、相关实体的信息引入到语义信息中,在下游任务上可以得到很明显的提升,其中留下了我们的一些思考:我们现在选择的邻居实体都是在一跳或者是两跳以内的,如果有"farther neighboring"远端的实体关系该如何应用?未来可以考虑如何更好地从长尾低频的医学实体学习语义信息。
04
工业落地与思考
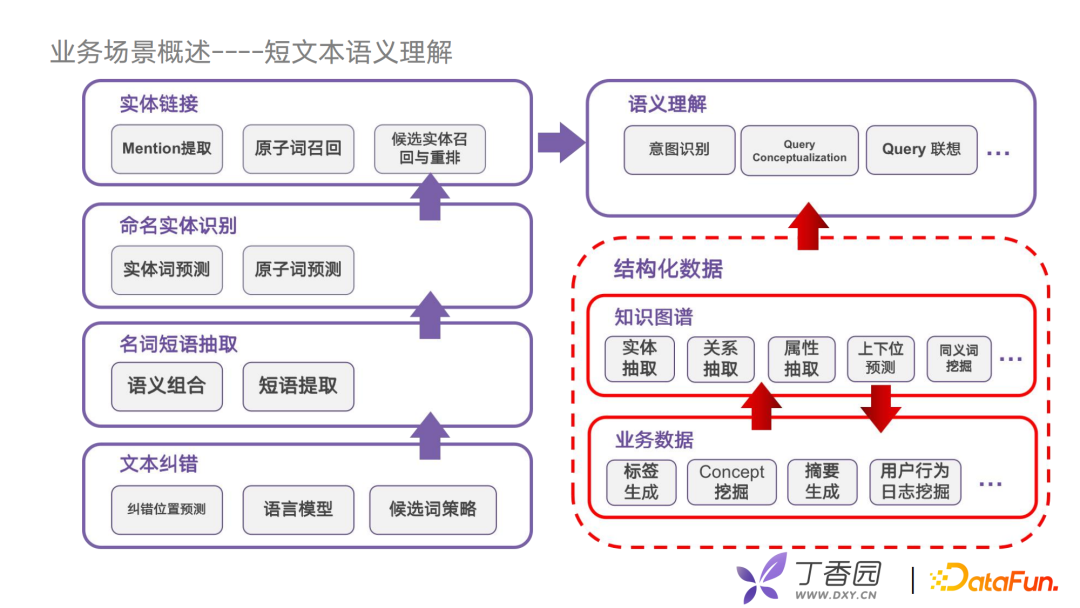
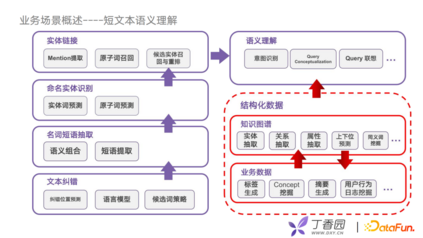
接下来介绍目前丁香园在业务场景的一些应用。 先介绍我们在优化搜索上的底层架构。我们尝试把用户使用搜索的语义理解任务拆分成为五个步骤,每个步骤解决实体识别准确性的问题,包括文本纠错、名词短语抽取、命名实体识别、实体链接、语义理解。我们会通过结构化好的图谱对语义理解做优化,例如进行意图识别时,可以把graph embedding的特征拿过来,也可以通过推理的方式获得相关实体,还可以进行Query联想,联想相关的实体词,例如用户提到了某个品牌的商品,它的主要功能是什么,有什么类似的商品。

我们利用concept结构图谱对文本结构化上做了一些提升。文本结构化对于提升搜索效果起到了非常重要的作用,有了concept之后可以帮助我们从抽象的层面完成对文本打标签的工作,那业界中比较好的方案就是先用TransE之类的知识表示模型,把知识图谱train出Embedding,然后将这些embedding融合进LDA的模型里面,在模型中,会用vMF分布代替原来的高斯分布去处理实体词的部分。如此以来,我们就会对一篇如“麻醉不良习惯”的帖子中的讨论帖子抽出如“麻醉医学”和“麻醉的不良习惯”这样的关键词。

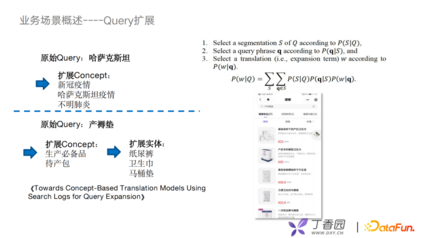
目前Query扩展的问题主要有两类方法:
第一种,利用query词和document词的相关性去构建一个贝叶斯模型,扩展的结果是document词或document中出现的一些词组,帮助在召回阶段扩大潜在用户想要的那些文本。 第二种,把它作为一种翻译模型,思路是从query词翻译到document词。早期比较朴素的方案是用一个EM算法去找两类词的对齐关系。现在新的方案都是上神经网络去train一个生成模型来做这个工作。 有了concept层之后,用一些很简单的策略就能有不错的效果,比如我们会直接使用相关性的方式,也就是第一类方法去建模,就可以把原始query向concept层上扩展。比如,“哈萨克斯坦”可以扩展出“新冠疫情”或“不明肺炎”;同样,在电商场景下,我们可以利用扩展的concept和其他的实体关系做二级扩展,比如“产褥垫”可以扩展出“待产包”,然后再从待产包扩展出“卫生巾”“纸尿裤”。这样的应用也带了一点推荐的意思。
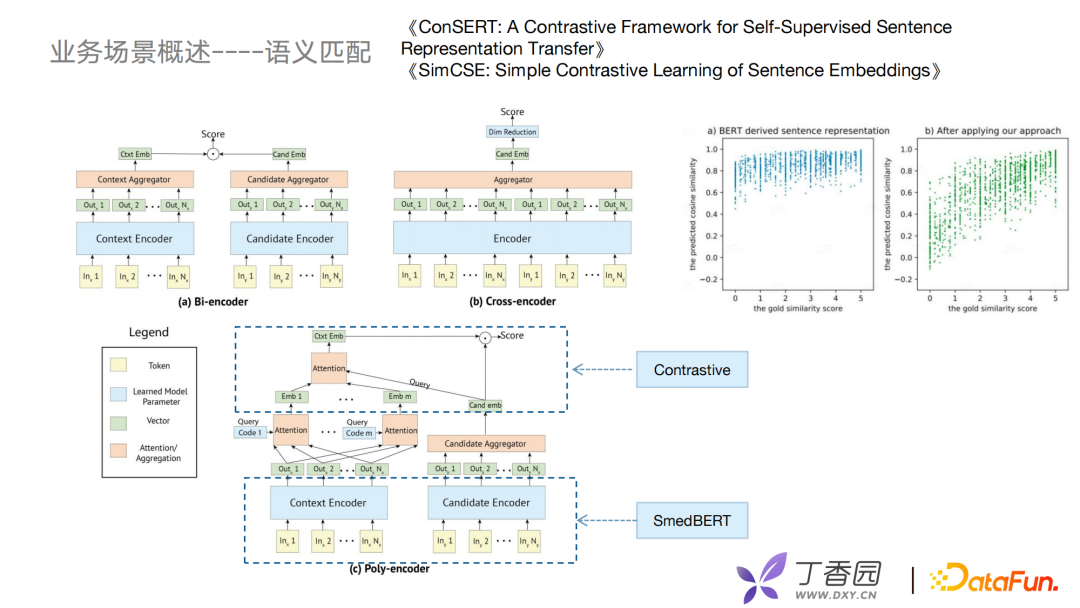
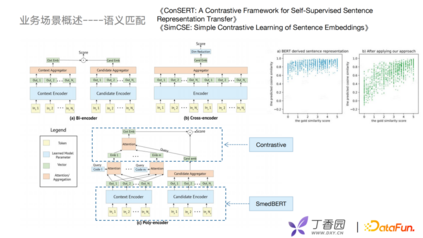
接下来介绍语义匹配,早期语义匹配使用双塔模型Bi-Encoder实现。Bi-Encoder优势是可以将候选集向量进行离线计算,线上预测只计算Context Encoder。但其中有个问题——把所有的实体信息放到一个固定的向量中去,可能会导致细粒度的语义缺失,无法精准地做匹配。于是,出现了Cross Encoder,它类似Bert预训练的方式,把两个句子进行一个拼接,放入Encoder中去,再去打分。这种方式可以达到很好的语义学习效果,但没办法实时,复杂度比较高,并且比较慢。 前几年出现Poly Encoder,将Context Encoder多个向量进行self-attention后融合,这种方式比Bi-Encoder更好地保留丰富的语义信息,又将candidate embedding做好离线计算,再用向量索引方式去做召回和打分。
我们在Poly Encoder之上做了一些改进,例如把SMedBERT引入到表示层,并且引入对比学习的优化,比较经典的是ConSERT和SimCSE,例如美团去年提到的一个对比学习的方法,实际应用中在计算句子相似度的时候会有很高的打分。这样虽然可以获得想要的内容,但在召回时不好控制召回的数量,误差也比较大。加入对比学习后会发现可以更好地解决BERT坍缩问题。 未来挑战主要有三个方面:
首先,训练数据成本高,因为医学领域数据资源比较少,如何降低人工成本形成一个良性的数据闭环是我们首先要做的。
第二,随着业务的不断扩展,当出现一个新的业务时数据量会比较少,怎么提升已有图谱的复用性,历史相关内容怎么去利用,怎么去做高质量的图谱融合。 最后,对于长尾低频的用户行为,如何更好地理解识别用户意图是未来的一个挑战。
05
Q&A
Q1:SMedBert是否有公开? A1:在GitHub上已经公开。 Q2:Token Embedding后如何与知识图谱进行融合? A2:通过Trans方式将知识图谱获得Graph Embedding表示向量与token Embedding进行拼接。之前提到的Poly Encoder可以把context encoder做整合进行self-attention获得更多语义信息,再进行下游任务。在过程中不仅做匹配单任务也对多任务进行优化。之前提到的instance做concept聚类,也可以表示学习上的多任务。 Q3:丁香数据来源有哪些? A3:医学书籍、药品说明书、科普文章等。 今天的分享就到这里,谢谢大家。
分享嘉宾: