

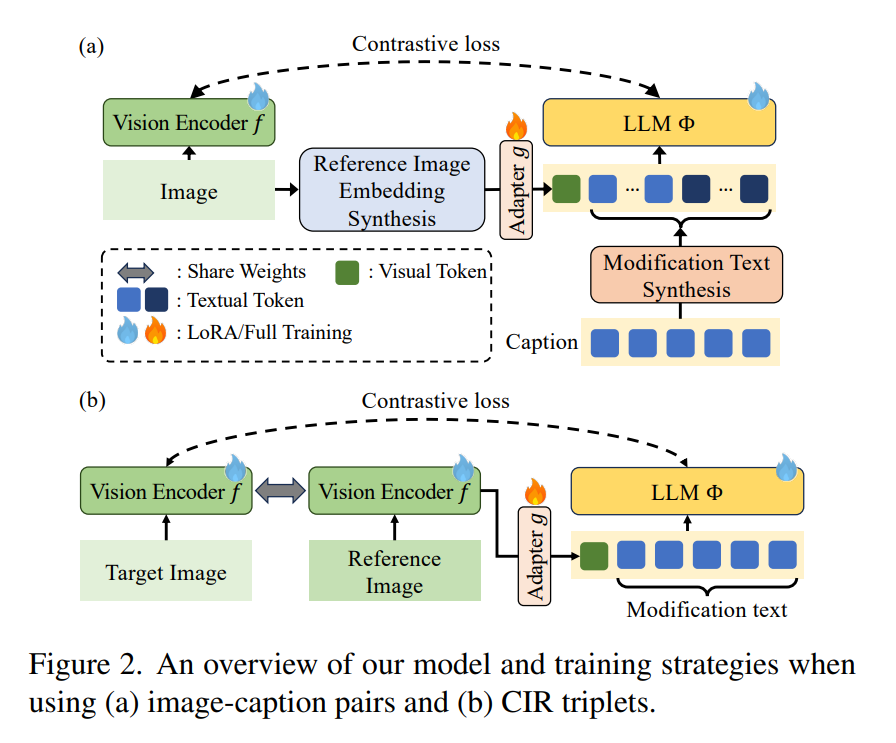
组合图像检索(CIR)是一项复杂的多模态查询任务,其目标是根据参考图像与文本修改描述检索目标图像。传统方法依赖包含(参考图像、修改文本、目标图像)的三元组数据进行训练,但此类数据获取成本高昂且耗时。现有CIR数据集的稀缺性催生了零样本方法,例如利用合成三元组或基于网络爬取的图像-标题对训练视觉-语言模型(VLMs)。然而,这些方法存在显著缺陷:合成三元组存在规模有限、多样性不足、修改文本不自然等问题;而图像-标题对由于缺乏三元组结构,难以学习多模态查询的联合嵌入表示。此外,现有方法对需要深度视觉-语言融合的复杂语义修改文本处理能力不足。本文提出CoLLM——一个端到端解决方案框架,有效解决了上述限制。该框架的创新性体现在:动态三元组生成:从图像-标题对中实时生成训练三元组,无需人工标注即可实现监督学习;深度多模态融合:利用大语言模型(LLMs)构建参考图像与修改文本的联合嵌入表示;数据集贡献:发布MTCIR大规模数据集(含340万样本);优化现有CIR基准(CIRR与Fashion-IQ),提升评估可靠性。实验表明,CoLLM在多个CIR基准测试中达到SOTA性能,MTCIR数据集可带来最高15%的性能提升。优化后的基准为CIR模型提供了更可靠的评估体系。项目页面详见collm-cvpr25.github.io。
成为VIP会员查看完整内容
相关内容
Arxiv
37+阅读 · 2023年4月19日
Arxiv
203+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
37+阅读 · 2023年4月19日
Arxiv
203+阅读 · 2023年4月7日