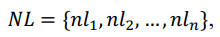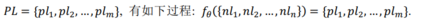代码生成(Code Generation), 是指根据自然语言描述生成相关代码片段的任务. 在软件开发过程中, 常 常会面临大量重复且技术含量较低的代码编写任务, 代码生成作为最直接辅助开发人员完成编码的工作受到学术 界和工业界的广泛关注. 让机器理解用户需求, 自行完成程序编写也一直是软件工程领域重点关注的问题之一.**近年来, 随着深度学习在软件工程领域任务中的不断发展, 尤其是预训练模型的引入使得代码生成任务取得了十分优异的性能. **本文系统梳理了当前基于深度学习的代码生成的相关工作, 并将目前的基于深度学习的代码生成 方法分为三类: 基于代码特征的方法, 结合检索的方法以及结合后处理的方法. 第一类是指使用深度学习算法利 用代码特征进行代码生成的方法, 第二类和第三类方法依托于第一类方法进行改进. 本文依次对每一类方法的已 有研究成果进行了系统的梳理, 总结与点评. 随后本文还汇总分析了已有的代码生成工作中经常使用的语料库与 主要的评估方法, 以便于后续研究可以完成合理的实验设计. 最后, 本文对总体内容进行了总结, 并针对未来值 得关注的研究方向进行了展望.
**1 引言 **
从计算机诞生开始, 虽然编程的形式随着硬件及软件的不断进步而不停迭代, 但是从事计算机技术行业 的人员始终与编写代码的任务紧密联系在一起. 因此如何提高软件开发的效率和质量, 一直是软件工程领域 的重要问题之一. 这一方面是由于在不同软件开发过程中存在大量相似代码复用的情况, 多次编写重复代码 会大大降低开发人员的开发效率以及创造热情; 另一方面, 结构清晰, 功能完备的高质量代码能够使得软件 开发过程明晰, 并能够在后期有效降低维护成本.
除了互联网领域的工作人员, 计算思维在当今信息社会对于每一位从业者都必不可少. 政府也在制定相 关专门文件推动和规范编程教育发展, 帮助学生理解并建立计算思维[1] . 但事实上, 对于大多数没有经过系统 化学习的人而言, 从零开始上手编程并完整完成一段能够实现具体功能的程序是极具挑战的. 编程作为一种 手段来完成人们设想的功能, 本质上是一种工具, 但这样的学习门槛使得想法与实际操作之间存在差异, 在 一定程度上阻碍了许多具有创意性思维程序的诞生.
程序自动生成方法是一项机器根据用户需求自动生成相应代码的技术. 智能化代码生成具有多元形式, 一般地, 根据实际应用场景以及生成过程所需要的信息, 可以将智能化代码生成分为代码生成(Code Generation)和代码补全(Code Completion)两个任务. 前者是指根据开发人员利用自然语言编写代码的需求(部 分会加入输入输出样例), 机器生成特定编程语言的代码片段(部分方法加入后处理环节以保证代码的可执行); 后者则是指在开发人员编写代码过程中, 代码补全算法模型根据已编写代码上文自动理解开发人员的编写意 图并补全代码. 根据补全的代码粒度, 又可以将其分为词元级别(token-level)以及行级别(line-level)[2] . 简单来 说, 代码生成接收的输入是自然语言描述, 输出是能够一定程度实现自然语言描述功能的代码片段; 而代码 补全任务接收的输入是当前代码的上文, 输出的是当前代码的下文. 本文研究的智能化代码生成限定于前者, 即代码生成(Text-to-Code), 旨在根据自然语言描述生成特定编程语言的代码片段. 具体来说, 本任务关注软 件实际开发过程中使用的高级编程语言, 如 C++, Java 和 Python 等. 这里给出代码生成问题的数学定义, 给定自然语言描述:
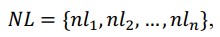
, 智能化代码生成模型, 目的是生成代码片段:
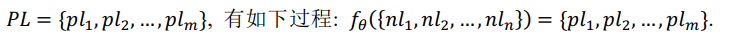
传统的代码生成方法主要依赖于高质量的词汇表, 手工构建的模板和特定领域的语言特性, 要求程序员 人工编写逻辑规则, 以便生成程序能够根据其设定规则生成符合逻辑的代码片段. Little 等人[3] 提出了一种将 关键字(自然语言)转换为 Java 方法调用表达式的算法. Gvero 等人[4] 为 Java 编程语言和 API 调用构建了一种概 率上下文无关语法, 并提出算法可以将英文输入映射为声明, 最终生成有效的 Java 代码片段. 这样人工提取 的方法具有很大的局限性, 不能够适应复杂多变的编程环境, 同时也增加了开发人员编写逻辑规则的开销. 因此随着人工智能和深度学习算法的进步, 自动提取词汇表及特征来生成可执行代码片段也得到长足发展.
事实上, 最近十年来, 利用机器学习和深度学习算法解决计算机各个领域相关问题的研究已成为一种趋 势. Hindle 等人[5] 发现代码与自然语言在统计学上呈现相似的分布, 代码同自然语言一样是重复的, 有规律的 和可预测的. 这样的研究结果为人工智能领域的相关算法模型应用到代码领域相关的问题提供了理论基础, 即 AI(Artificial Intelligence) for SE(Software Engineer). 最近, Chen 等人[6]对代码的自然性及其应用的研究进展进行了系统的综述, 有助于研究者更好地利用自然语言领域的思想来解决代码领域的问题. 对于代码生成任 务而言, 借助机器学习和深度学习算法, 利用数据驱动构建模型, 完成自动代码生成已成为程序自动代码生 成任务的解决范式, 称为智能化代码生成. 智能化代码生成能够有效应对不同的开发环境, 提高软件开发的 效率和质量, 减轻开发人员的压力, 降低代码编写的门槛.
然而, 代码生成问题在研究时也面临诸多严峻挑战: 首先, 自然语言描述形式多种, 表达多样, 对于同样 的函数描述实现可能一百个人就有一百种表达方式. 因此, 能否正确理解自然语言所描述的意图对于代码生 成的质量具有决定性作用. 其次, 代码生成本质是生成类任务, 使用到的模型在解码过程中往往伴随着巨大 的解空间, 针对复杂问题所生成的代码可能存在无法被执行或对于实际问题没有完全解决的情况, 如何在其 中找到正确的符合用户需求的代码仍需要被探索. 因此, 如何更好地利用已有的外部知识库(例如 Stack Overflow 论坛)来提升代码生成模型的效果成为了一个可能的解决方案. 上述这些问题虽随着模型的一步步增 大带来的性能提升有所缓解, 但仍未解决. 最后, 目前对于代码生成的质量评估主要采用了自动评估的方式, 评估的指标从机器翻译领域的指标转向基于测试样例的指标, 这一定程度上有助于实际模型性能的评价. 但 对于实际场景中的代码生成, 缺乏人工评价的板块, 使得目前代码生成模型落地后的表现距开发人员的期待 仍存在一定的差距.
2 研究框架
为了对智能化代码生成相关领域已有的研究工作和取得成果进行系统的梳理, 本文使用 code generation、 generating source code、 generating program、 program synthesis 作为关键词在 ACM Digital Library、 IEEE Xplore Digital Library、 Elsevier ScienceDirect、 Springer Link Digital Library、 Google scholar 和 CNKI 在线 数据库中进行检索. 基于上述论文数据库中检索出来的相关文献, 我们在人工筛选方法的基础上, 通过分析 论文的标题、关键词和摘要去除与代码生成无关的文献. 接着我们递归地对每篇文献进行正向和反向滚雪球 搜索[7] , 最终选择出与主题直接相关的高质量论文共 53 篇(截止到 2022 年 11 月).
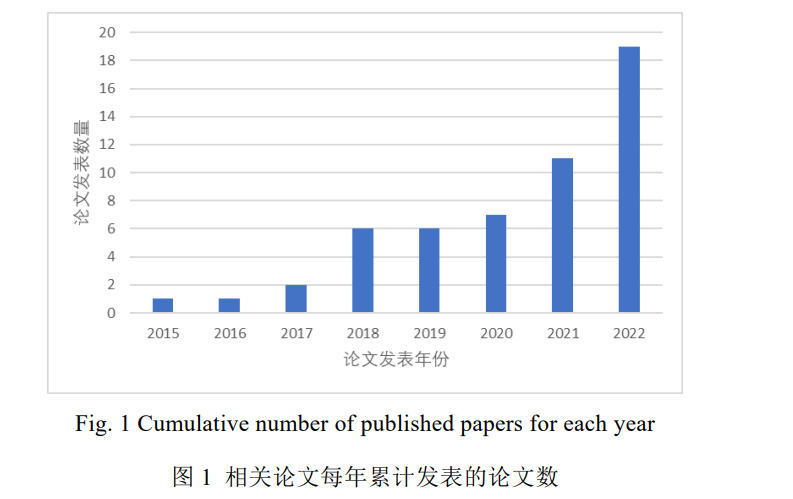
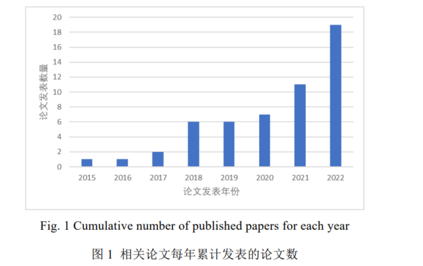
如图 1 所示, 从 2015 年到 2019 年, 智能化代码生成相关论文的数量呈上升趋势, 说明智能化代码生成任 务逐渐被学界关注, 完成了部分研究并取得了一些成果. 随着 2020 年 CodeBERT[26] 提出, 智能化代码领域也 掀起了利用大型语言模型在代码语料进行预训练, 并在下游相关任务进行微调的热潮. 因此 2021 年和 2022 年 相关的论文大幅增加. 尤其是 2022 年, 论文数量达到了 19 篇, 相关话题也在学界和工业界之外引起了社会的 广泛讨论. 值得一提的是企业的论文(如 PANGUCoder 与 AlphaCode)常常直接在网上进行模型架构的公开, 为 产品做技术支撑. 虽然这些论文不会在期刊或会议上发表, 但是其背后的思想及解决问题的工程方法具有很强的借鉴意义, 不容忽视. Hu 等人曾在 2019 年对基于深度学习的程序生成与补全技术进行了系统完备的中文综述[8] , 但是随着后 续智能化代码生成任务相关研究成果的急剧增加, 领域内亟需对于此任务进行回顾与总结, 方便后续研究者 在此领域继续深耕. 本文将主要内容放在生成高级程序语言所编写的代码生成任务上, 主要讨论基于深度学 习(即神经网络架构)的相关模型. 根据代码生成方法的主要思想和核心部件, 本文主要将代码生成方法分为三 类, 基于代码特征的代码生成方法, 结合检索的代码生成方法和结合后处理的代码生成方法, 后两者可以视 作基于第一类方法进行改进的代码生成模型, 而第一类又可以根据使用的范式不同分为基于监督学习的代码 生成方法和基于预训练的代码生成方法. 表 1 展示了本文所收集论文分类的概况. 本文主要关注智能化代码生成任务使用的模型以及算法的创新性, 算法的评估指标(及优劣), 使用数据集 以及适用编程语言(即适用场景)四方面内容. 同时对之前工作中涉及到的数据集及评价指标单独进行了整理, 并对于不同数据集涉及的编程语言类型, 规模和相关论文使用的情况进行了统计. 除此之外, 本文还针对拥 有检索增强模块以及后处理环节相关的论文进行单独讨论. 本文第 1 章为引言, 第 2 章介绍综述的整体研究框架. 第 3 - 5 章分别介绍基于代码特征, 结合检索以及 基于后处理的代码生成方法的相关研究工作, 并进行讨论. 第 6 章汇总常用的代码生成数据集. 第 7 章介绍代 码生成评估指标. 第 8 章对全文进行总结并对未来值得研究的领域进行展望.

3 基于代码特征的代码生成方法
直观上, 代码生成任务可以简单抽象为机器翻译的问题, 即将自然语言描述翻译为代码表示. 在机器翻 译问题中最常用的模型是序列到序列模型(Squence2Sequence Model), 其主要思想就是从训练数据中学习自然 语言特征, 并利用代码特征进行生成. 在这个过程中需要用到大量的自然语言-代码对(), 以便模 型能够从训练数据中学习到双模态数据的对应关系, 因此在本文中被称作基于监督学习的代码生成方法. 自 2017 年 Transformer 模型[9] 的提出, 大型预训练模型在自然语言处理领域不断发展, 对计算机视觉甚至 通用人工智能领域都产生了巨大的影响. 同样, 代码生成任务也积极引入大型预训练模型, 试图在已有挖掘 代码特征的基础上结合预训练范式进一步提升模型性能. 预训练模型主要存在两个特征, 第一个是在预训练 阶段其所需数据往往是无标注的数据, 通过还原掩藏掉的部分词元或片段来进行训练[10] , 这样的训练过程被 称为自监督训练. 第二个是模型的规模以及所需数据量都非常大, 这是因为许多工作[11,12] 都发现随着模型规 模的增大, 数据量的增多和计算量的提升, 模型的性能就会不断提高. 直到本文完成的时刻, 尚未有工作发现 预训练模型性能的瓶颈. 与其他领域任务一样, 基于预训练的代码生成方法显著提高了代码生成的下限, 并 逐渐成为最近几年研究代码生成问题的主要解决方案. 因此, 本文将基于预训练模型进行代码生成任务的代 码生成方法单独列出, 作为本章的第二部分.
**3.1 基于监督学习的代码生成方法 **
**3.1.1 简述 **
在基于监督学习的代码生成方法中, 最常用的模型是序列到序列模型[13] , 其对应的是编码器-解码器范式, 主要包含编码器(Encoder)和解码器(Decoder)两部分, 被广泛应用于自然语言处理中的生成类任务, 同样也被 代码生成类任务广泛使用. 对于代码生成任务而言, 编码器将输入自然语言描述转变为固定长度的向量表示, 解码器则将编码器所产生的向量表示转变为可运行程序输出. 下面提到的相关模型均基于这样的模型框架进 行, 由于比起自然语言, 代码自身具有规律化和模块化的特点, 因此模型往往对解码的相关操作以及应用信 息进行改进. 使用到的数据均为的形式, 目的是从数据对中挖掘出文本和代码之间的对应关系, 从而完成生成任务. **3.1.2 已有工作的分析 **
高级程序设计语言的智能化代码生成流程首先由 2016 年 Ling 等人[14] 的工作定义. Ling 等人希望在卡牌 游戏万智牌(Magic the Gathering)和炉石传说(Hearth Stone)中, 可以通过自然语言描述某一张卡牌的能力或效 果, 让模型自动地去生成对应的卡牌定义代码(高级程序语言, 即 Java 和 Python)来减少开发人员编写卡牌效 果的时间成本. 作者利用序列到序列模型来实现自然语言到代码片段之间的转换. 在传统注意力机制模型中, 输入的注意力是由 RNN(Recurrent Neural Network, 循环神经网络)中每一个单元的输出经过计算加权得来. 作 者将注意力机制模型进行改进, 在计算输入的注意力时考虑了每一个输入域并将各个输入域都用作计算注意 力值. 但是由于每一个输入域的值域和输入规模都不一样, 因此作者利用线性投影层将不同输入投影到同一 个维度和值域上. 为了统一自然语言和代码之中的实体(如变量名等)信息, 作者利用选择预测器(select predictor)来预测自然语言中需要保留的字段, 并且结合序列到序列模型来生成代码的主体框架, 然后填入自 然语言中的保留字段来实现对应卡牌代码的生成. 2017 年, Yin 等人[15] 在 Ling 的工作上[14] 做出了进一步改进, 作者利用语法模型显式地对目标语言的语法 进行建模, 并且作为先验知识融入模型训练之中. 模型的编码器和之前工作一样利用双向长短期记忆网络 (Long Short-Term Memory, LSTM)对自然语言进行编码, 但是在解码器端, 模型的目标生成是抽象语法树 (Abstract Syntax Tree, AST)的构建动作序列而非可执行代码. 得到构建动作序列之后再生成树, 并转化为相应 的可执行代码. 经过实验, 模型在多个数据集中达到了最好的结果. Rabinovich 等人[16] 则是引入抽象语法网络(Abstract Syntax Networks, ASNs)作为标准编码器-解码器范式的 扩展. 与常规的序列到序列模型相比, 抽象语法网络的输出为抽象语法树, 核心在于改变解码器, 使其具有与 输出树结构平行的动态确定的模块化结构. 作者在文中使用了抽象语言描述框架(Abstract Syntax Description Language, ASDL)将代码片段表示为具有类型化节点的树. 模块化解码器本质为相互递归的模块集合, 其包含 的四个模块根据给定输入分别以自顶向下的方式递归生成可执行代码的抽象语法树. 经过这样流程所产生树 的语法结构就反映了生成过程的调用图, 即完成了代码生成任务. 2018 年, 在上述模型的基础上, Iyer 等人[17] 在编码器端构造了类型矩阵(Type Matrix)来标识方法名和变量 名数据类型, 并将矩阵拼接到编码器输入之后, 来一起计算输入的嵌入向量; 在解码器端, 作者利用两步注意 力计算每一个 token 的注意力以及每一种类型和变量名的注意力, 最终利用第二步的注意力结果作为最后生 成代码的先验. 除此之外, 由于当下模型生成的类中有可能包含没有被学习过的域信息, 所以作者利用监督 复制机制来决定哪一个标识符是需要复制到代码中生成. Iyer 等人[18] 在一年后对此方法进行改进, 提出了一种 迭代方法, 通过反复整理大型源代码体的最常出现的深度 - 2 子树, 从大型源代码语料库中提取代码习语的语 法树, 并训练语义分析器在解码过程中应用这些习语. 这里的代码习语是指代码片段中最常见的结构(比如嵌 套循环, 条件判断等), 文中用语法解析树中经常出现的子树表示. 相比于利用语法树解析代码习语并得到一 颗很深的语法树, 直接将代码习语应用到解码过程中可以提升训练速度和性能. 作者将所有的代码习语压缩 到一颗深度为 2 的简化语法树之中, 使得模型可以更精准地输出对应的代码. 同样是在 2018 年, Yin 等人[19] 则是在之前自己工作的基础上[14] 提出了 TranX, 一个基于 transition 的代码生成模型. TranX 的核心在于 transition 系统, 其能将输入的自然语言描述根据一系列树构造动作映射到抽象语 法树上. 模型以抽象语法树作为中间表示, 对目标表示的特定领域结构进行抽象. 最后再利用一个由神经网 络参数化的概率模型对每一个假定的抽象语法树进行评分, 从而得到目标代码的抽象语法树, 进而完成代码 生成的目的. 一年后, 作者又在此基础上加以重排序(Reranking)技术[20] 进行优化, 主要使用了重排序模型对 代码生成结果进行重排序来提升模型性能. 重排序主要由两个方面内容完成, 一方面是根据生成的代码来重 构真实输入文本的概率进行评估; 二是利用匹配模型直接评估代码与输入文本的相关程度. 重排序模型也同 样分为两个部分来完成上面两方面的评估, 一是生成重构模块(Generative Reconstruction Feature), 使用一个带 注意力机制的序列到序列模型, 通过生成的代码极大似然估计出输入的文本; 二是利用判别匹配模块 (Discriminative Matching Feature), 将生成代码与输入文本的 token 借助注意力机制的神经网络计算出结果. 2019 年, Sun 等人[21] 发现了程序代码比起自然语言描述包含有更多有意义的 token, 因此之前工作使用 RNN来捕获长距离序列可能并不恰当. 作者在文中提出了基于语法的结构化卷积神经网络(Convolution Neural Network, CNN), 根据抽象语法树中的语法构造规则来完成代码生成任务. 详细来讲, 文章主要针对解码器部 分进行了部分抽象语法树(即已生成的代码所构成的抽象语法树)信息的补充, 并为提取抽象语法树中不同粒 度的信息分别设计了卷积层, 最终将多种信息聚合达到增强模型的效果. 同年, Wei 等人[22] 提出代码生成任务和代码总结任务两者是对偶任务(dual task), 于是作者利用对偶任务 学习的方法来同时提高两者的性能, 即代码生成(Code Generation)模型和代码摘要(Code Summarization)模型 被同步地训练, 其思想也被运用到后续的研究当中[23] . 2020 年, Sun 等人[24] 使用 Transformer 架构来解决代码元素之间存在的长依赖问题, 并对模型进行修改提 出 TreeGen, 使其能够结合代码的结构信息. 具体来说, TreeGen 共分为三个部分: NL Reader, AST Reader 和 Decoder. 其中, NL Reader 用于对自然语言描述进行编码, AST Reader 用于对已生成的部分代码的语法树进行 编码, Decoder 则是用于聚合带有自然语言描述的生成代码的信息并预测接下来的语法规则. 本文将基于 AST 的代码生成任务视作通过语法规则来扩展非终结符节点, 直至所有的叶子结点均为终结符停止的过程.
**3.2 预训练模型 **
**3.2.1 简述 **
近些年来, 预训练模型在自然语言处理领域取得了巨大的成功. 从预训练模型架构来看, 可以分为编码 器-解码器架构(Encoder-Decoder), 仅编码器架构(Encoder-only)和仅解码器架构(Decoder-only). 虽然模型总体 架构并无形式创新, 但是其核心思想与之前的基于监督学习的模型不同. 预训练模型从大规模无标注的数据 中通过自监督的训练策略获取知识, 且绝大多基于 Transformer 架构进行. 首先在大规模的无标注的数据集上 对模型进行预训练, 然后利用预训练得到的表征在下游的有标注数据集上进行微调. 实验证明这种方式可以 极大地提高模型的泛化性, 在多项任务上取得了很好的结果. 类似地, 研究人员在代码领域也提出了对应的 预训练模型, 并且在代码生成任务上取得了优异的效果.
**3.2.2 已有工作的分析 **
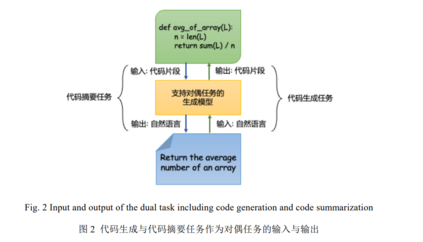
CuBERT[25] 是首个提出代码预训练模型的工作, CuBERT 继承 BERT[10] 的架构, 利用代码语料进行训练, 但和 CodeBERT[26] 相比, 其影响力较小. CodeBERT 是第一个多编程语言的大型双模态(指自然语言描述 NL 与 编程语言 PL)预训练模型, 后续在各个下游任务上被广泛使用, 影响力较大. CodeBERT 的预训练的任务为掩 蔽语言建模(Mask Language Modeling, MLM)[10] , 通过随机掩盖模型中的某些词并让模型去预测被掩盖的词, 在预训练阶段提高模型的理解能力. 在实际场景当中, CodeBERT 被用来作为编码器对输入的文本或代码进行 编码, 然后应用到各式各样的下游任务中, 例如代码生成, 代码摘要以及代码检索等. 由于 CodeBERT 仅仅包含文本的语义信息, 所以 Guo 等人[27] 在 2021 年提出将代码的结构信息数据流纳 入预训练的过程之中并提出 GraphCodeBERT, 同样采用 MLM 对模型进行预训练. 但不仅仅掩盖文本信息中 的一些单词, 而是也会在代码的数据流图之中随机掩盖某些数据节点然后让模型去预测. 实验证明在预训练 过程中显式地去考虑代码的结构信息可以极大地提高代码对模型的理解能力, 并提高在下游任务当中的性能. 上述预训练模型仅仅包含编码器端, 这种架构的预训练模型在理解任务上的效果较好, 但无法很好地完 成生成式任务. 为了更好地完成根据自然语言描述进行代码生成(Text-to-Code)的任务, CodeXGLUE[2] 中提出 了 CodeGPT 模型, 这是一个由代码语料进行训练, 与 GPT-2[28] 完全同架构的 12 层 Transformer 解码器模型. 与仅编码器架构的模型相比, 仅解码器架构能够更好地完成生成代码的任务. 除了单独使用 Transformer 的编码器或解码器结构, 后续也有相关工作同时使用了 Transformer 的两端. Clement 等人[29] 对于代码和自然语言描述采用了同一个词汇表, 基于 T5(text-to-text transfer transformer)[30] 提出了多模态的翻译模型 PYMT5, 通过单个模型既可以同时学习到代码/自然语言生成并且理解二者之间的 关系. PYMT5 使用 T5 利用相似子序列掩藏目标(similar span-masking objective)进行预训练, 其本质是一个基 于编码器-解码器架构的 Transformer 模型. 子序列掩藏目标是指随机采样一些连续的 3 个 token 的子序列使用 特殊标记(例如[MASK 0])对其进行掩藏, 然后训练序列到序列模型来补全这些掩藏的 token, 训练目标包含了 被隐藏 token 及其序号. 作者将 PYMT5 与在同样数据集上进行预训练的 GPT-2 相比取得了很大提升. Ahmad 等人[31] 提出的 PLBART 也是一个编码器-解码器模型, 在预训练过程当中, 与 CodeBERT 做法一 样, 作者随机掩盖某些单词, 但是 PLBART 输出的是一个完整的文本或单词, 其中包括了被掩盖的单词. 通过 这种训练方式, 作为一个序列到序列模型的 PLBART 就可以在预训练阶段在编码器和解码器端同时学习到很 好的初始化点, 让预训练好的模型可以更快更好地应用到下游任务当中. PLBART 提高了模型在生成任务上的 能力, 也提高了模型在代码生成任务上的表现. 更进一步地, Wang 等人[32] 在 2021 年提出了 CodeT5, CodeT5 在预训练阶段充分考虑到了代码的特点, 作 者从代码片段中抽取标识符, 并重点让模型去预测这些在代码中具有实际意义的单词, 实验证明 CodeT5 在包 括生成任务在内的多项软件工程领域任务均取得了更好的效果. 同一时间, Phan 等人提出了 CoTexT[33] , 同样 使用了编码器-解码器架构, 模型初始化也使用了 T5. 唯一的区别在于为了缩小预训练和调优之间的差异, CodeT5 利用了双模态数据去训练模型完成一个双向生成的转换. 具体来说, CodeT5 将 NL→PL 的生成与 PL→NL 的生成视作对偶任务(dual task), 并同时对模型进行优化. 根据两篇文章中实验结果的对比, CodeT5 的效果要好于 CoTexT, 但是如果只是在 T5 的基础上利用多任务学习来提升代码生成任务的性能, CodeT5 和 CoTexT 效果相当. 简单来说, CodeT5 和 CoTexT 两个模型在完成代码生成任务的具体实现上最大 的差别在于是否使用代码生成与代码摘要作为对偶任务进行训练. 这样的实验结果侧面证明了将代码生成和 代码摘要任务作为对偶任务能够提升模型的生成能力. Nijkamp 等人[34] 开源了大型预训练模型 CodeGEN, 模型参数高达 16.1B, 依次在 THEPILE, BIGQUERY, BIGPYTHON 三个数据集上进行训练, 数据量超过 800G. 与之前直接将自然语言输入给预训练模型不同, 作 者提出利用大型预训练模型进行对话式程序生成的方法: 作者将编写规范和程序的过程描述为用户和系统之 间的多轮对话. 用户分多次为系统提供自然语言, 同时以合成子程序的形式接收来自系统的响应, 这样用户 与系统一起在多轮对话后完成代码生成. 分步提供自然语言规范的方式可以将较长且复杂的意图分解为多个 简单的意图, 减少每一轮对话中模型的搜索空间. 除此之外, 作者还开发了一个多轮编程基准来衡量模型的 多轮程序综合能力, 实验结果表明以多轮方式提供给 CodeGEN 的相同意图与单轮提供的相比显着改进了代码 生成的性能, 验证了对话式代码生成范式的有效性. 之前的代码生成模型都是从左到右生成代码序列, 然而在实际开发过程中, 代码很少直接以从左到右的 方式编写, 而是完成部分代码编写后反复编辑和完善. InCoder[35] 打破了先前从左至右的代码生成预训练模型 范式. 这是一种统一的生成模型, 可以执行程序合成(通过从左到右生成)以及编辑(通过掩蔽和填充). InCoder 的模型架构继承自 GPT 架构, 不同点在于其对训练语料进行顺序打乱预测. 该方法随机选择一个跨度并将其 替换为掩码 token, 并将跨度放置在序列之后作为目标. 利用这样处理后的语料进行训练, 使得模型具有填充 双向上下文的能力. 这样 InCoder 不仅可以从左到右预测 tokens, 而且可以根据两端的 tokens 预测中间的 tokens, 实现了填充式的代码生成技术. 这是第一个能够填充任意代码区域的大型生成代码模型, 这种以双向 上下文为条件的能力大大提高了代码生成任务的性能.
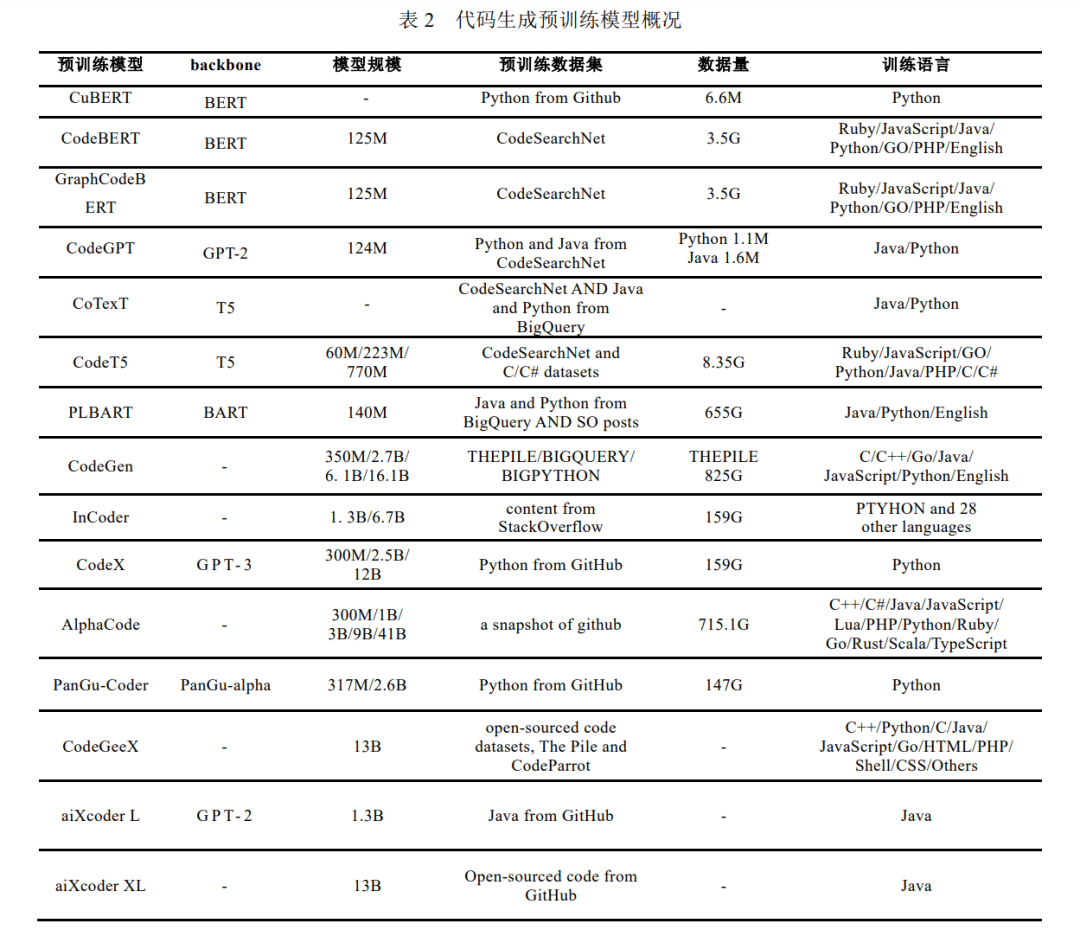
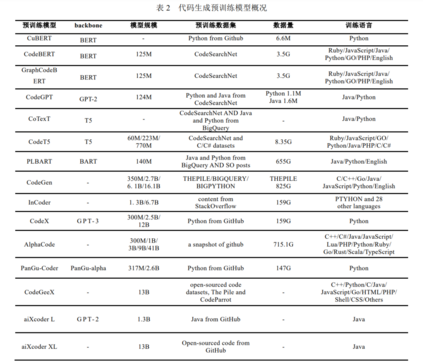
越来越多基于 Transformer 体系结构的大型预训练模型被提出并在代码生成任务上取得最优结果. 因此, 一些企业机构着手于将大型预训练代码生成模型落地, 试图为广大开发人员提供便利, 并在此过程中为业界 提供了大量优质的代码生成模型. 2021 年年末, OpenAI 最早发布的 CodeX[36] , 是基于 GPT-3 在公开数据集上预训练得到的大规模模型, 基 于 CodeX 的 Copolit[37] 插件也已成为代码生成辅助工具的标杆, 在 CodeX 论文中提出的 HumanEval 数据集也 成为后续代码生成的常用基准数据集之一. 2022 年年初, DeepMind 公司研发的展现出强大编程能力的 AlphaCode[38] 在新闻上号称打败了一半的程序 员, 本质上也是基于公开代码仓库进行预训练的大规模模型. 与 CodeX 不同, AlphaCode 更专注于竞赛题目的 编写, 因此选用了完整的 Transformer 架构的模型, 便于更好地理解较长的由自然语言描述的题目, 同时在调 优时也选择了 CodeForces[39] 的竞赛题目. 国内, 华为推出的 PanGu-Coder[40] 是基于 PanGu-alpha 模型在公开代码数据集上进行预训练. 之后基于此开发的 CodeArts 插件也已在实际开发场景中拥有不错的表现, 对标基于 CodeX 的 Copoilt. 2022 年, aiXcoder[41] 团队陆续推出了用于 Java 代码补全的 13 亿参数量的 aiXcoder L 和 130 亿参数量的 aiXcoder XL 服务. aiXcoder L 基于 GPT-2, 在开源 Java 代码上训练得到. aiXcoder XL 基于自研的 masked language model 框架, 能做到单行、多行以及函数级代码补全和生成. 最近, 清华大学联合鹏城实验室共同推出的大规模代码生成预训练模型 CodeGeeX[42] , 采用了标准的 Transformer 架构, 在公开代码仓库超过 20 多种编程语言上进行预训练, 能够支持较其他开源基线更高精度的 代码生成性能, 能够支持代码片段在不同编程语言间进行自动翻译转换. 如表 2 所示, 汇总了本节涉及到的代码生成预训练模型相关内容. 除以上专门用于进行代码生成任务的相关模型, ChatGPT[43] 虽作为问答模型, 但也被证实具有代码编写 的能力, 自 2022 年 12 月发布以来就引起了学术界和工业界的广泛讨论. ChatGPT 能够适应不同的问题情境给 出接近甚至超过人类的回答, 并具有一定推理和代码编写能力. ChatGPT 与 InstructGPT[44] 使用了相似的训练 方式. 主要流程分为三个步骤, 第一步是搜集带标记的数据使用监督学习策略对已有的 GPT 模型进行调优; 第二步是搜集来自人类反馈的比较数据来训练一个分类器(称为 reward model)用于比较 GPT 模型生成若干答 案的好坏; 第三步是借助第二步训练好的 reward model, 利用强化学习策略对模型进行进一步优化. 原有的提 示学习范式是通过调整模型的输入使得下游任务更好地适配模型, 而通过 InstructGPT 的训练过程及 ChatGPT 的出色表现可以发现, 模型的性能尚未被充分挖掘, 且可以通过人为标注反馈的方式, 让模型更好地去理解 用户的意图, 达到让模型适配用户的目的.
**3.3 小结 **
本章主要对基于代码特征的代码生成方法相关工作进行了叙述与梳理, 并按照监督学习与预训练-调优 范式分为两节进行概述. 在基于监督学习的代码生成方法中, 主要依托于编码器-解码器架构进行自然语言描述与代码特征的挖 掘, 试图从训练数据中学习到自然语言与代码之间的对应关系. 除此之外, 一些工作针对解码器生成代码的 部分进行了改动, 试图将更多代码相关的规则性信息融入其中, 取得了比仅使用 token 进行代码生成更好地性 能. 在基于预训练的代码生成方法中, 主要对引入代码生成任务的预训练模型进行了简单介绍. 这一小节的 方法的骨干模型(backbone)均来自于自然语言处理领域的大型语言预训练模型. 将其应用于代码生成任务的 一个大致流程为: 收集大量无标注的代码语料, 其中包含代码注释, 利用试图还原掩藏掉的部分代码片段对 模型进行预训练, 最后再使用对数据对预训练模型进行调优. 最近, ChatGPT 所具备强大的语言理解能力和一定程度的推理能力引起学术界和工业界的广泛关注, 其 背后通过反馈调整使模型来匹配用户的思想, 为进一步挖掘大规模语言预训练模型提供了新的解决思路.
**4 结合检索的代码生成模型 **
**4.1 简述 **
对于第三章中的代码生成模型而言, 其代码生成过程的解空间过大, 这种现象在预训练模型中的表现愈 发明显[36] . 互联网上存在的代码片段数量非常庞大, 对于用户的绝大部分要求而言, 其他开发人员可能存在 过类似的需求, 并已经与他人协作或自行完成相关代码的设计与编写. 因此, 检索出类似已存在的代码模板 这个任务本身就是有利于用户更深刻理解任务的. 同时, 基于前人相关任务的代码模板进行的改动也比直接 生成的代码更具有实用价值. 编写代码是一个开放域(open-domain)的问题, 即在编写代码过程中不可避免需要参考前人工作与他人的 编程思路, 而在第二章中介绍的大部分工作则是直接将其视作封闭性质的任务(closed-book)[45] , 即只是根据训 练数据的模式来完成代码生成的任务. 从这个角度来看, 引入外部知识库对原有训练的模型进行补充是有意义有价值的. 事实上, 利用自然语言描述的编码作为编码过程中的先验可能是不足的. 为了让已有代码生成 模型与外部代码知识数据库相结合, 有相关工作利用检索操作对代码生成过程进行增强. 通过检索相似代码 帮助解码器进行代码生成, 以减小解码空间, 最终提升生成代码的质量.

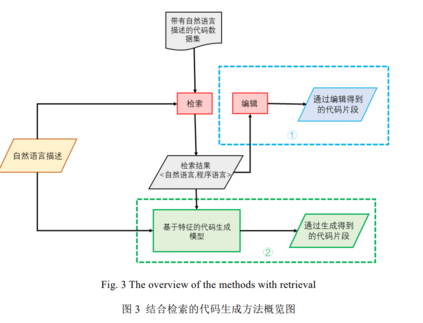
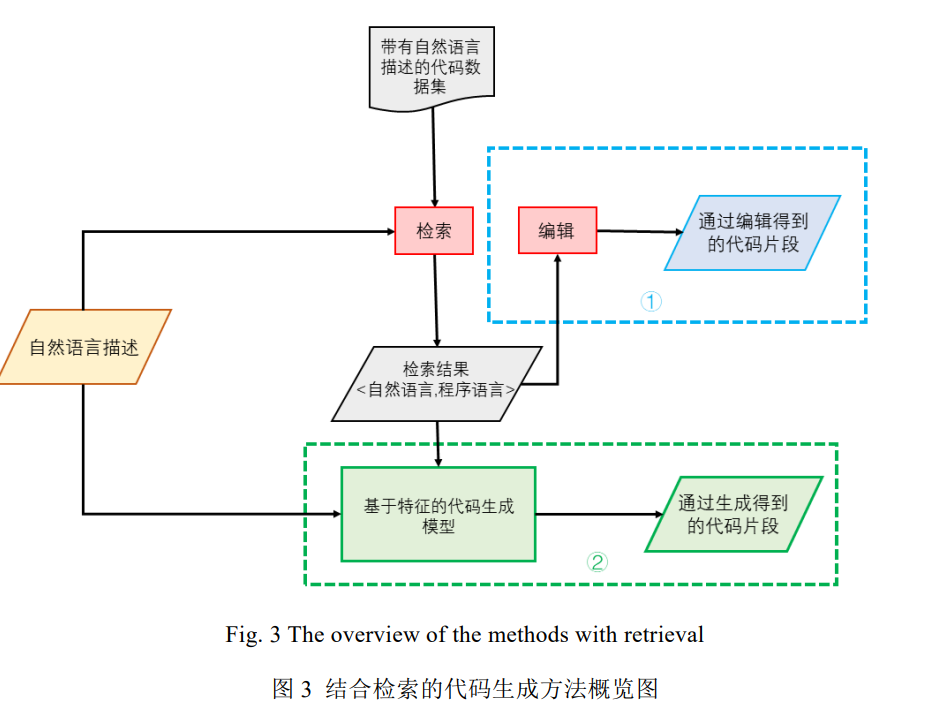
本章主要对结合检索的代码生成方法相关工作进行了简单介绍.本章中提到的方法并没有设计新的模型 架构, 而是通过结合检索的方式生成代码片段. 如图 3 所示,结合检索的代码生成方法大致可以分为两种形式, 第一种是图 3 的上半部分(即图中①部分): 从训练数据或是外部知识库检索出与目标代码相关或相似的代码 片段, 将其作为模板进行编辑并返回结果; 第二种是图 3 的下半部分(即图中②部分): 将检索得来的借过作为 原有模型的输入, 试图通过为自然语言描述补充代码信息的方式提升模型的性能. 结合检索的代码生成方法 能够大大降低生成模型解空间的规模, 同时也能在一定程度上利用外部知识库使模型跳脱出自己训练的固有 规则, 对于代码生成任务是有帮助的. 在检索的过程中, 往往将自然语言描述作为查询的键(key), 并经模型处理后借助向量进行表示, 在训练 数据或外部数据库查找与查询键(key)相关的代码片段进行返回. 在这个过程中, 模型向量表示的能力决定了 检索结果的质量. 因此, 尝试多种自然语言表示形式与不同的模型表征方法可能是检索增强的一条未来之路.
**5 基于后处理的代码生成方法 **
**5.1 简述 **
大规模预训练语言模型往往将代码视作普通的文本, 因此难以理解代码更深层次的语法或语义[55] , 也就 不能够产生具有质量和正确性保证的模型. 针对大规模预训练语言模型, 一个重要的改进方向是通过测试样 例对模型生成过程及生成结果进行测试并试图加以改进[56, 57, 58] , 也有工作直接在模型的训练过程中利用测试 样例对其进行强化, 提升模型性能[60] . 通过测试样例对生成的代码进行改进可以视作机器执行过程的后处理, 而开发人员对生成代码进行评估 可以视作人为测试代码的过程, 因此有工作利用开发人员评估意见对已有代码生成模型进行改进, 这可以被 视作人工测评过程的后处理[52] . 本章主要对结合后处理的模型生成方法进行了简单介绍. 程序设计的目的就是解决实际问题, 测试样例 与开发环境在一定程度上能够作为实际场景中问题的采样. 因此, 基于测试样例与代码实际运行环境对模型 进行改进一定程度上模拟了实际开发过程中所遇到的情形. 而对于遇到的问题或是错误进行修改就被称为后 处理. 这种方式的处理流程类似于程序员面向 Bug 编程, 直观而有效. 目前对于测试样例的生成主要分为两类, 人工编写及模型自动生成. 对于生成测试样例的质量仍未有一 个清晰的度量. 对于其他部署环境的后处理少有工作涉及.
6 代码生成数据集
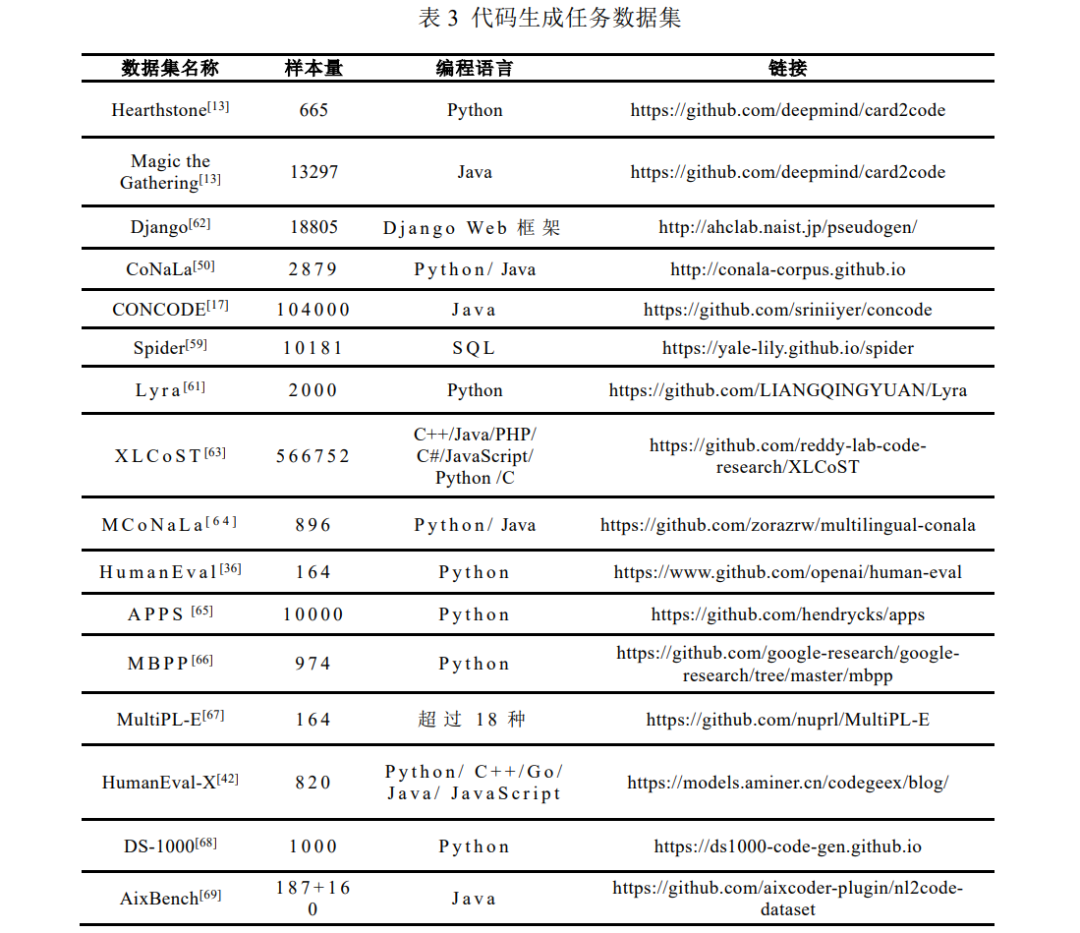
代码生成任务用于训练, 验证和测试的数据集通常包含自然语言描述和对应的代码片段. 一个代码生成 数据集一般仅包含一种高级编程语言. 目前的代码生成数据集有 Python 语言的 HearthStone[13] 和 CoNaLa[50] 、 Java 语言的 CONCODE[17] 、 SQL 语句的 Spider[59] 和 Lyra[61] 数据集, 以及基于 Django Web 框架的 Django[62] 数据集等. 目前有如下常见数据集用于训练, 验证和测试代码生成任务: (1) HearthStone[13] : 2016 年首次使用该数据集来解决代码生成问题. 该数据集是为纸牌游戏 HearthStone 实现的 Python 类集合, 包含 665 张不同的 HearthStone 游戏卡片, 每张卡片带有一组字段和对应的 Python 代码片段. 其中字段是卡牌的半结构化描述, 包含卡名, 成本, 攻击, 描述和其他属性.(2) Magic the Gathering[13] : 该数据集是为纸牌游戏 Magic the Gathering 实现的 Java 类集合, 包含 13297 张不同的游戏卡片. 和 HearthStone 数据集类似, 每张卡片带有一组字段和对应的 Java 代码片段. (3) Django[62] : Django 数据集是 Django Web 框架中的代码的集合, 该数据集由 Oda 等人提供. 为了制作 该数据集, Oda 等人聘请了一名工程师撰写代码, 最终获得了 18805 对 Python 语句和对应的英语伪代 码. 该数据集最初创立是为了用于源代码生成伪代码的任务, 后续被用于代码生成任务中. (4) CoNaLa[50] : 为了得到与自然语言具有细粒度对齐的代码, Yin 等人提出一种新方法. 该方法可以在 Stack Overflow 中挖掘高质量对齐数据. 实验表明该方法大大扩展了过往挖掘方法的覆盖范围和准确 性. Yin 等人使用该方法创建了 CoNaLa 数据集, 其中包含 2879 个手动注释的问题及其在 Stack Overflow 上的 Python 解决方案示例, 这些示例涵盖了由具有不同意图的程序员发出的真实自然语言 查询. (5) CONCODE[17] : 在 GitHub 上收集了大约 33000 个 Java 项目, 根据存储库划分 10 万个样本用于训练, 4000 个样本用于验证和测试. 基于存储库的划分使测试集中的域与训练集中的域保持分离, 因此提 供了接近零样本的条件. 每个示例是由自然语言描述, 代码环境和代码段组成的元组. 其中代码环境 为类中的其他成员变量和成员函数. (6) Spider[59] : 该数据集由 11 名大学生注释完成, 是一个大规模的自然语言到 SQL 的数据集, 它由 10181 个问题和 5693 个独特的复杂 SQL 查询组成. (7) Lyra[61] : Liang 等人认为, 在实际开发中, SQL 语句通常以字符串的形式嵌入 Python 中. 为了贴合实 际应用场景, Liang 等人提出了 Turducken-Style 代码生成:为给定的自然语言注释生成具有嵌入式语 言的代码, 同时发布了 Lyra 数据集. 该数据集内含自然语言注释及其对应的 Python 程序, 且该 Python 程序内含嵌入式 SQL 语句. (8) XLCoST[63] : Zhu 等人从 GeeksForGeeks 收集了一个包含 8 种语言(C++, Java, Python, C#, JavaScript, PHP, C 和英语)的数据集 XLCoST (Cross-Lingual Code SnippeT dataset), 能够支持 10 种跨语言任务的 评估. 其中, 比起之前的代码生成数据集主要针对 Python 和 Java, XLCoST 能够适应更多其他语言代 码生成任务(例如 C 和 C++)的评估. (9) MCoNaLa[64] : 为了根据英语以外的自然语言生成代码, Wang 等人提出了一个多语言数据集 McoNaLa, 用西班牙语, 日语和俄语三种语言标注了 896 个对.
**7 代码生成评估 **
为了使用统一的标准对生成代码的质量进行快速评估, 研究人员使用多种指标进行评估, 本章节主要使 用以下自动化指标进行测试. 7.1 Exact Match accuracy 代码生成任务中常使用精确匹配(Exact Match)作为模型评价指标, 该精确度指标表示模型生成代码与参 考代码之间完全匹配的百分比. 7.2 BLEU BLEU[70] 是用来评价机器翻译质量的指标, 在代码生成技术中可以将生成的代码看做看作是翻译产生的 语句 7.3 CodeBLEU Ren 等人[71] 认为, 用于评价自然语言的 BLEU 指标忽略了代码的语法和语义特征, 并不适合评估代码. 为 了弥补这一缺陷, 引入了一个新的评价指标 CodeBLEU. 它吸收了 n-gram 匹配中 BLEU 的优点, 并进一步通 过抽象语法树( AST )注入代码语法, 通过数据流注入代码语义. 7.4 pass@k BLEU 指标使用的是模糊匹配, 难以衡量生成代码的可执行性. 针对这一问题, 2019 年 Kulal[72] 等人提出 pass@k 指标.
**8 总结与展望 **
**8.1 总结 **
本文对高级程序代码生成任务目前国内外最新进展进行了比较详尽的阐述与总结. 我们将当前的智能化 代码生成技术分为了三类, 第一类是基于代码特征的代码生成方法, 第二类是结合检索的代码生成方法, 第 三类是结合后处理的代码生成方法. 基于代码特征的代码生成方法又可以根据模型训练的范式分为基于监督学习的代码生成方法和基于预训 练的代码生成方法. 前者使用了传统的编码器-解码器架构以及 RNN 与 CNN 模型, 并通过加入结构化信息, 对解码器的改进等操作, 在相关数据集上取得了不错的效果. 后者则是从自然语言处理领域的预训练大规模 模型得到灵感, 使用软件工程领域相关代码数据对大规模模型进行预训练与调优, 从而大幅提升模型的性能. 结合检索的代码生成方法和结合后处理的代码生成方法可视作对基于第一类方法部分模块的改进, 试图 提升代码生成模型的性能. 对于结合检索的模型而言, 检索的方式常常用于对已有的代码生成模型进行增强, 可视作即插即用的组 件式模块. 一方面, 检索到的内容更多作为输入数据的增强帮助原有模型更好地完成生成任务[44, 51] ; 另一方 面, 检索能够作为桥梁以便更加直接利用外部的文本和源码信息作为原有模型的补充[49] . 结合后处理的模型通过实际运行过程借助测试样例和开发环境对生成的代码进行处理, 以提升其实际运 行表现, 一个趋势是测试样例的产生由人为编写[56] 转变为模型产生[58] . 不同的模型对于不同的测试样例的用 法不尽相同, 但是核心思想和真实场景下编程相似, 即通过一些可能的错误来使得代码本身更加健壮. 除此之外, 本文还概括介绍了智能化代码生成任务中常用的数据集与评价指标, 以方便该领域后续研究 能够进行合理的实验设计. **8.2 展望 **
虽然目前的代码生成方法在相关的数据集上已经取得了较好的结果, 但是相关技术仍然拥有许多挑战值 得关注. **(1) 自然语言描述与代码的对齐问题 **
自然语言与代码在描述信息的角度与方法上有着巨大差异, 传统上直接利用 token 训练得到的序列到序 列模型很难去理解并提取自然语言中的功能表述并翻译成对应的代码. 基于此, 将代码表示为树来有效引入 代码的结构信息成为提升模型性能的重要举措, 但这并不是一项容易的任务, 因为语法树中的节点数量通常 大大超过其对应自然语言描述的长度, 这样的不对称性会增加代码生成任务的难度. 因此, 如何将自然语言 描述与代码进行对齐对于传统的序列到序列模型是一个极大的挑战. 另一方面, 模型对于输入自然语言的理解对于代码生成任务的效果也格外重要. 自然语言描述多种多样, 对于同样的意思可能有多种表达的方式. 对输入的多种自然语言进行重构, 为生成的代码提供更加清晰明了 的需求, 可能是一项解决方法. 除此之外, 之前有工作[22, 23, 51, 52] 将代码生成与代码摘要两个任务作为对偶任务对同一模型进行训练取得 了不错的效果, 尤其是 CodeT5 添加对偶任务后与 CoTexT 相比在代码生成任务上的性能有显著提升. 因此如 何将代码生成与代码摘要生成两个任务更好的结合在一起仍需要被探索.
(2) 大规模预训练模型的语法正确性问题
基于 AST 和语法的模型能够产生语法正确的代码, 但是一定程度上忽略了语义的正确性[27] ; 预训练模型 大多能保证语义的信息, 但是不能保证语法的正确性[55] . 由于自然语言和代码之间本身就存在的语义鸿沟, 直接基于语言模型的代码生成模型在生成过程没有足 够的规则约束, 因此生成目标代码时具有非常庞大的解空间. 这样的问题在预训练模型上表现尤为明显, 虽 然在大量代码库上进行预训练所得的大规模模型可以生成语义相关的代码片段, 但是很容易导致生成代码中 有语法错误以及生成代码的可读性较低. 如何在解空间中找到最优解或较优解成为了难题, 这导致输出结果 中容易出现具有语法错误的, 无法通过编译的代码. 如何提取并学习源代码中有效的结构信息, 填补自然语 言与代码之间的差异, 从而对解码过程进行约束仍是一个待探究的问题. 现有的预训练模型大多都是继承于自然语言处理领域的相关技术, 代码领域相关研究一直沿着自然语言 处理领域的道路前进. 因此, 自然语言处理中的语法正确性问题在代码生成任务中也普遍存在. 但有研究表 明, 自然语言处理中的标记化和嵌入方法可能在代码领域中不是最优的, 脱离自然语言处理思维模式可能是 一种优化的思路[73] .
**(3) 大规模预训练模型能力的挖掘 **
虽然近年来应用于代码生成任务的大规模语言模型层出不穷, 但是已有许多论文[11, 12] 表明随着训练的继 续进行, 模型的性能还能够提高, 且一些预训练模型还根据模型的大小将模型分为 small, base 和 large 来适应 不同的硬件条件下模型的应用. Wang 等人[74] 将自然语言处理中的提示学习(prompt learning)应用到代码相关的 分类任务上, 取得的性能的提升. 2022 年初随着思维链(chain-of-thought)[75] 的提出, 大规模预训练模型的知识 被进一步挖掘. 鉴于 ChatGPT 强大的性能, 以及人类程序员在代码编写过程中的步骤化和模块化的考量, 将 提示学习引入代码生成任务, 更深一步挖掘已有大规模预训练模型的性能在未来可能会成为一个重要的研究 方向. 除此之外, 还有相关研究[76, 77] 发现了将 Stack Overflow 中的问题和代码答案作为双模态数据用于模型调 优有助于模型性能的提升以及错误代码生成的抑制, 证明了这样的外部数据能够成为挖掘大规模模型性能的 有效工具.
(4) 模型适应多种不同编程语言的能力 目前虽然能够完成代码生成任务的模型有很多, 但是对于高级程序语言而言, 大多围绕 Java 和 Python 展 开. 这一方面是由于数据集的原因, 作为当今最为主流的两大语言, Java 和 Python 在数据量和数据质量上都拥有得天独厚的优势. 另一方面是结构的问题, Java 和 Python 都是面向对象的编程语言, 与其它编程语言(比如 C 语言)相比, 因为完备的库与 API 接口为相关功能的实现提供支撑, 所以他们可以完成具有更为简洁直观的 编写方式, 在一定程度上与自然语言相匹配. 最近, 有一些工作创建了多种语言的代码库[38, 59, 63] , 如何合理利 用这样的代码库让模型能够适应多种不同编程语言, 或许是提升模型性能的一种方式.
(5) 大型预训练模型压缩的问题 目前对于代码生成类工具的普遍解决方案是将本地的代码和软件开发人员的相关需求传送给服务器端, 由服务器端完成计算并将结果回传给本地. 由于服务器端的模型需要实时的代码和需求说明才能够进行计算 并反馈结果, 因此代码泄露成为不可忽视的一个隐藏问题. 为解决代码泄漏的问题, 如何将高性能模型移植 到本地或其他受限资源的平台上逐渐成为一项巨大的挑战. 此外, 代码生成任务的训练和推理过程都对服务器端产生了巨大的压力, 伴随着模型的不断增大, 如果 将训练及推理代价与实际的计算资源进行权衡, 使得模型性能维持相对较高水平的情况下节省资源, 缩短代 码生成时间, 为用户带来更好的体验成为了第二项重大的挑战. 以上两项挑战的解决可以归结于大型模型的压缩, 一方面可以将模型的规模变小, 使其能够部署在一些 较低资源的平台上, 节省计算资源; 另一方面可以提升模型的推理速度, 带来代码生成工具的体验的提升.
**(6) 人工评估代码生成方法性能 **
代码生成技术的意义在于辅助软件开发人员在实际开发过程中进行编码, 要想评估代码生成技术的实际 价值, 就需要对其进行人工评估, 人为地评判该技术在工程实践中所发挥的作用. 但目前人工评估存在着评 判标准模糊, 评价指标不统一, 难以大规模快速评估的问题, 同时考虑到人工评估的代价巨大, 因此目前仅有 少量研究进行人工评估[78] , 但如果想要现在的优秀模型能够落地成为普惠广大用户的代码生成工具, 人工评 估方法的确定, 实际测试和广泛讨论必不可少.