

** ****新智元报道 **
编辑:润 好困**【新智元导读】**艾伦人工智能研究所等5机构最近公布了史上最全的开源模型「OLMo」,公开了模型的模型权重、完整训练代码、数据集和训练过程,为以后开源社区的工作设立了新的标杆。
多年来,语言模型一直是自然语言处理(NLP)技术的核心,考虑到模型背后的巨大商业价值,最大最先进的模型的技术细节都是不公开的。 现在,真·完全开源的大模型来了! 来自艾伦人工智能研究所、华盛顿大学、耶鲁大学、纽约大学和卡内基梅隆大学的研究人员,联合发表了一项足以载入AI开源社区史册的工作—— 他们几乎将从零开始训练一个大模型过程中的一切数据和资料都开源了!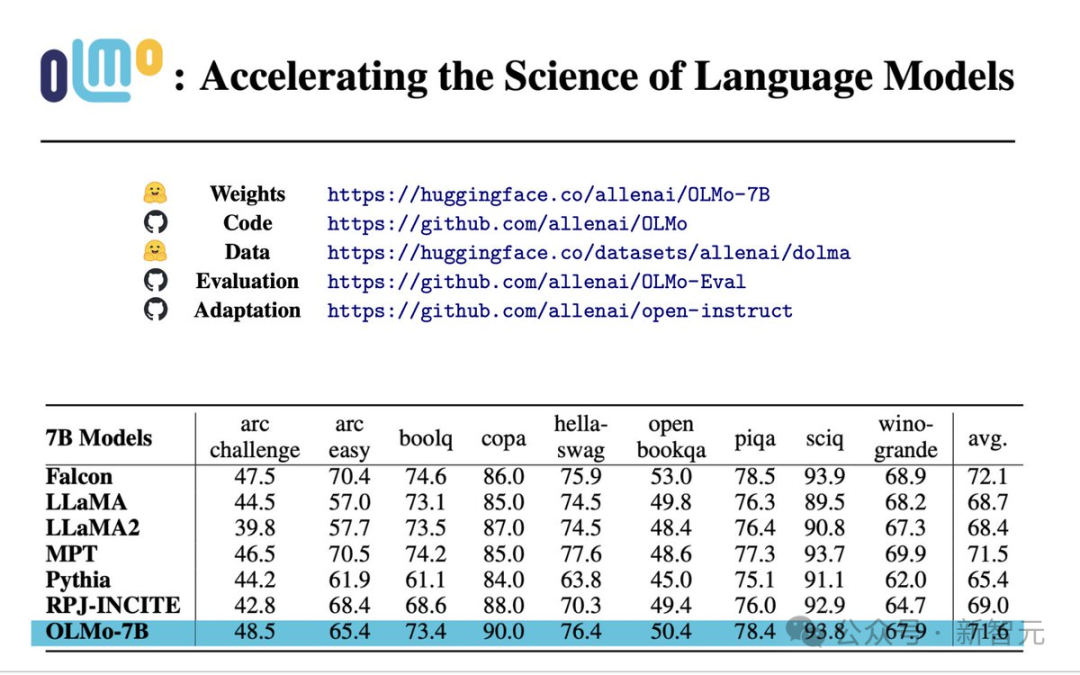

具体来说,艾伦人工智能研究所推出的这个开放大语言模型(Open Language Model,OLMo)实验和训练平台,则提供了一个完全开源的大模型,以及所有和训练开发这个模型有关的数据和技术细节—— **训练和建模:**它包括完整的模型权重、训练代码、训练日志、消融研究、训练指标和推理代码。 **预训练语料:**一个包含了高达3T token的预训练开源语料库,以及产生这些训练数据的代码。
**模型参数:**OLMo框架提供了四个不同架构、优化器和训练硬件体系下的7B大小的模型,以及一个1B大小的模型,所有模型都在至少2T token上进行了训练。 同时,也提供了用于模型推理的代码、训练过程的各项指标以及训练日志。
7B:OLMo 7B、OLMo 7B (not annealed)、OLMo 7B-2T、OLMo-7B-Twin-2T **评估工具:**公开了开发过程中的评估工具套件,包括每个模型训练过程中每1000 step中包含的超过500个的检查点以及评估代码。 所有数据都在apache 2.0下授权使用(免费商用)。

如此彻底的开源,似乎是给开源社区打了个样——以后不像我这样开源的,就别说自己是开源模型了。

性能评估
从核心的评估结果来看,OLMo-7B与同类开源模型相比略胜一筹。 在前9项评测中,OLMo-7B有8项排名前三,其中有2项超越了其他所有模型。 在很多生成任务或阅读理解任务(例如truthfulQA)上,OLMo-7B都超过了Llama 2,但在一些热门的问答任务(如MMLU或Big-bench Hard)上表现则要差一些。
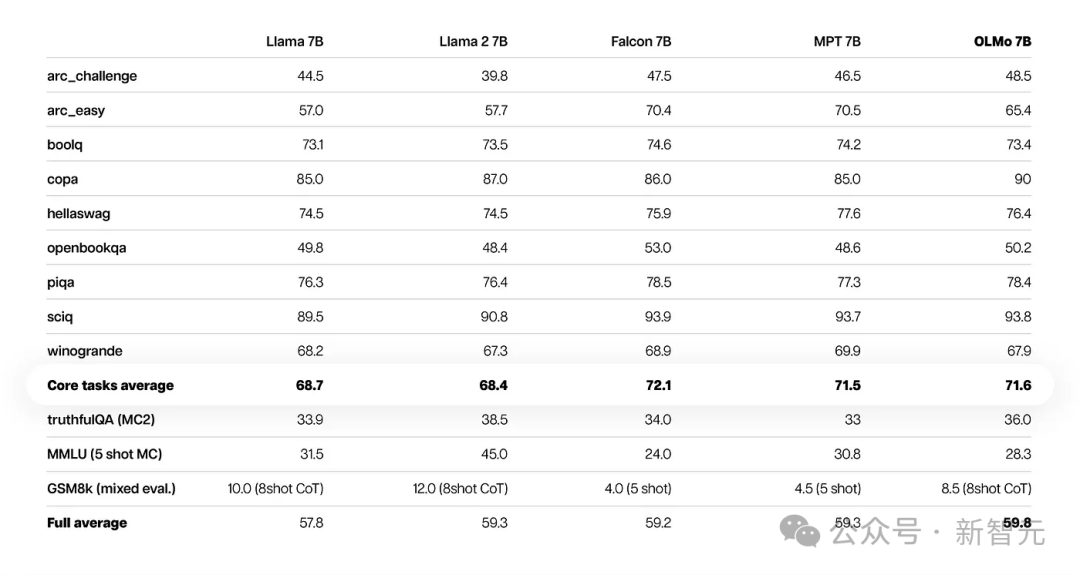
前9个任务是研究人员对预训练模型的内部评估标准,而下面三个任务则是为了完善HuggingFace Open LLM排行榜而加入的 下图展示了9个核心任务准确率的变化趋势。 除了OBQA外,随着OLMo-7B接受更多数据的训练,几乎所有任务的准确率都呈现上升趋势。
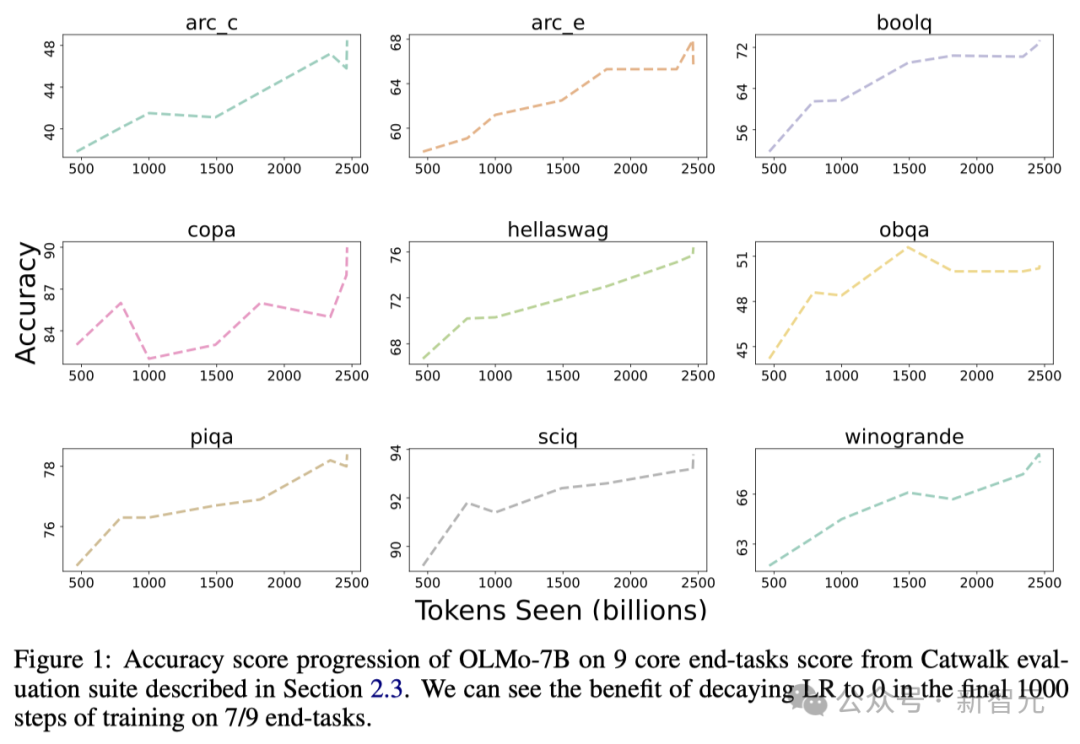
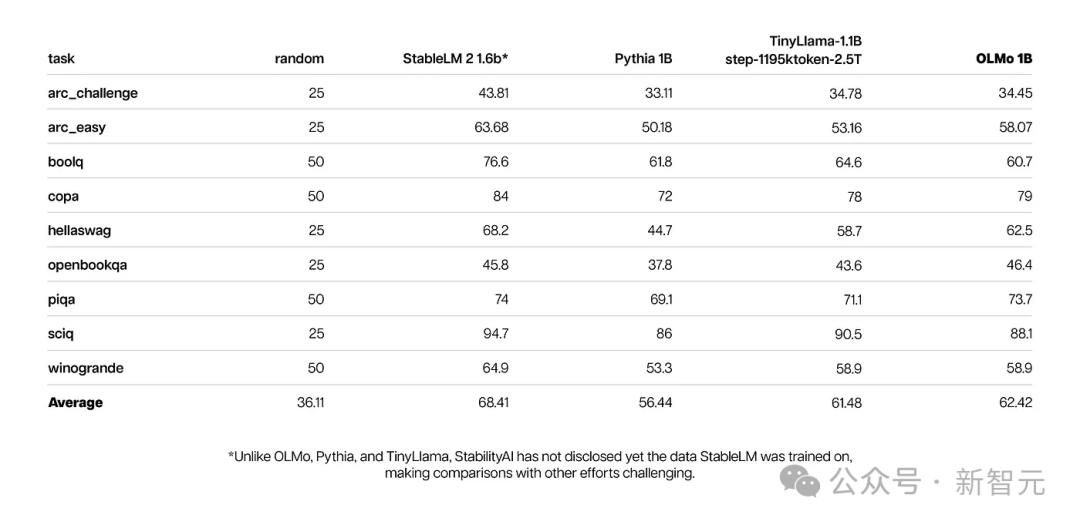
与此同时,OLMo 1B与其同类模型的核心评估结果表明,OLMo与它们处于同一水平。
通过使用艾伦AI研究所的Paloma(一个基准测试)和可获取的检查点,研究人员分析了模型预测语言能力与模型规模因素(例如训练的token数量)之间的关系。 可以看到,OLMo-7B在性能上与主流模型持平。其中,每字节比特数(Bits per Byte)越低越好。
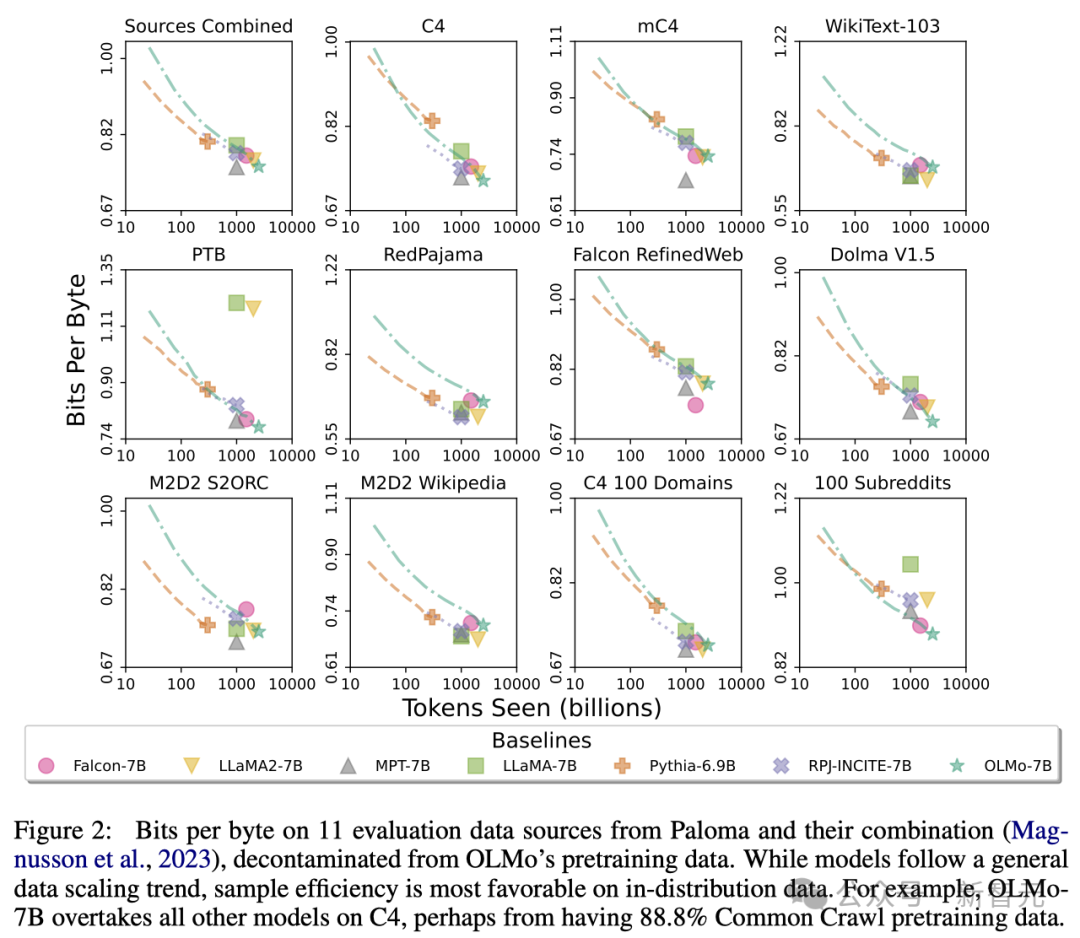
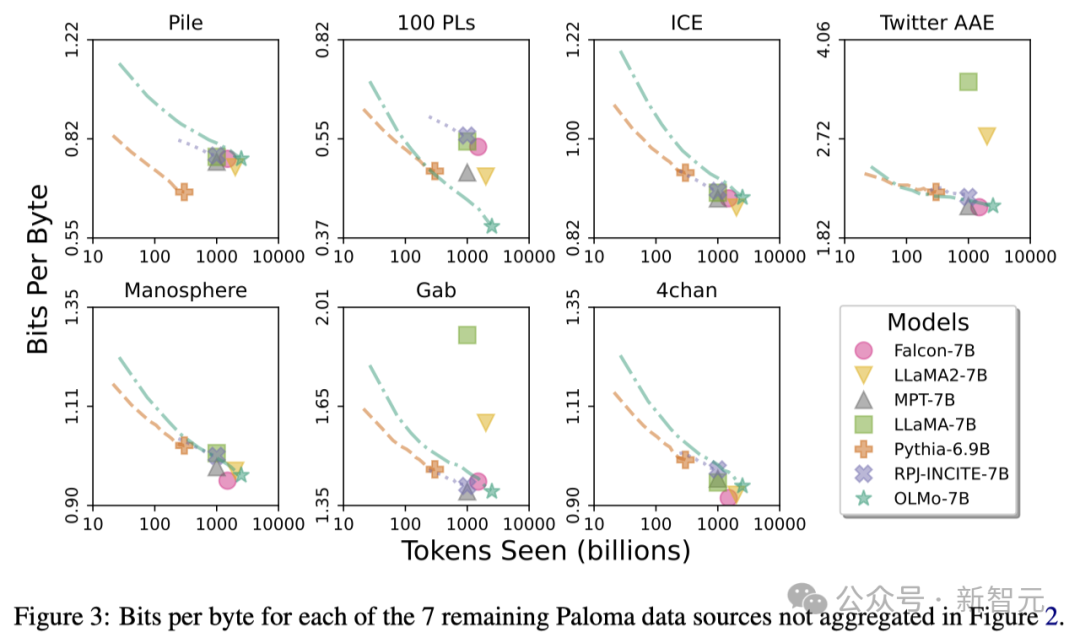
通过这些分析,研究人员发现模型在处理不同数据源时的效率差异较大,这主要取决于模型训练数据与评估数据的相似度。 特别地,OLMo-7B在主要基于Common Crawl的数据源上表现出色(比如C4)。 不过,在与网络抓取文本关系不大的数据源上,如WikiText-103、M2D2 S2ORC和M2D2 Wikipedia,OLMo-7B与其他模型相比效率较低。 RedPajama的评估也体现了相似的趋势,可能是因为它的7个领域中只有2个来源于Common Crawl,且Paloma对每个数据源中的各个领域给予了相同的权重。 鉴于像Wikipedia和arXiv论文这样的精选数据源提供的异质数据远不如网络抓取文本丰富,随着预训练数据集的不断扩大,维持对这些语言分布的高效率会很更加困难。
OLMo架构
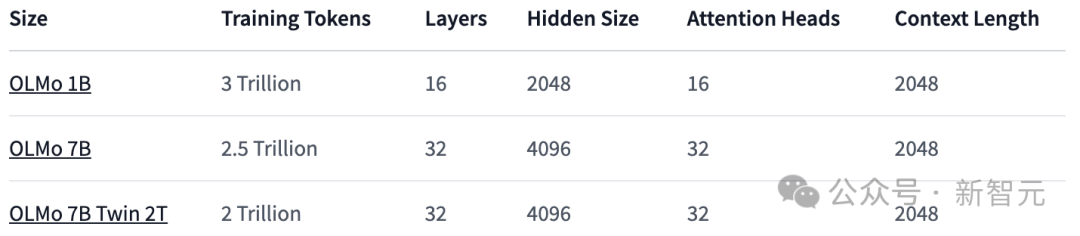
在模型的架构方面,团队基于的是decoder-only的Transformer架构,并采用了PaLM和Llama使用的SwiGLU激活函数,引入了旋转位置嵌入技术(RoPE),并改进了GPT-NeoX-20B的基于字节对编码(BPE)的分词器,以减少模型输出中的个人可识别信息。 此外,为了保证模型的稳定性,研究人员没有使用偏置项(这一点与PaLM的处理方式相同)。 如下表所示,研究人员已经发布了1B和7B两个版本,同时还计划很快推出一个65B的版本。
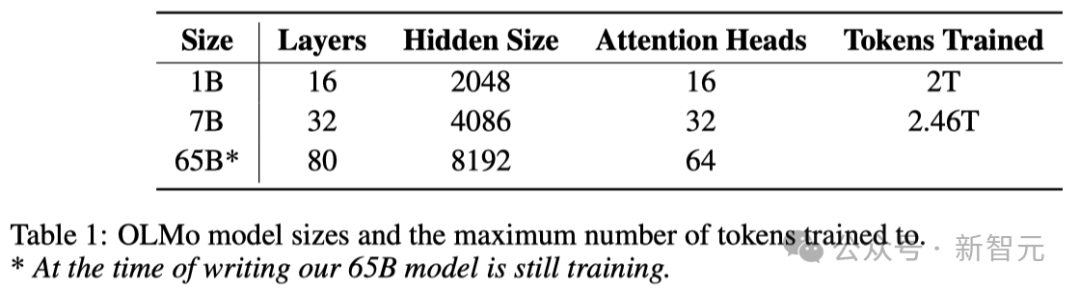
下表详细比较了7B架构与这些其他模型在相似规模下的性能。
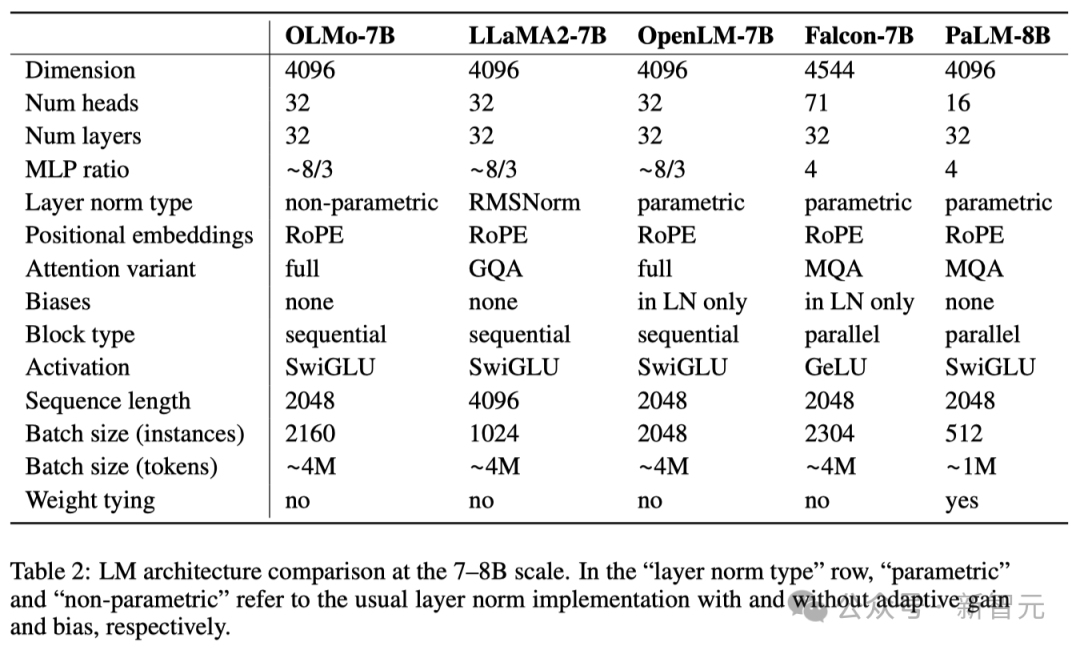
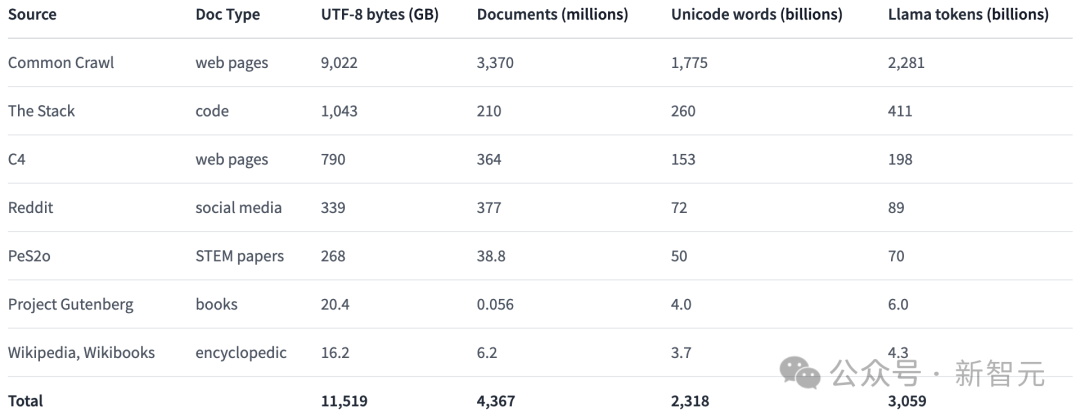
预训练数据集:Dolma
虽然研究人员在获取模型参数方面取得了一定的进展,但开源社区目前预训练数据集的开放程度还远远不够。 之前的预训练数据往往不会随着模型的开源而公开(闭源模型就更不用说了)。 而且有关这些数据的说明文档也常常缺乏足够的细节,但是这些细节对于想要复现研究或完全理解相关工作至关重要。 这一情况加大了语言模型研究的难度——比如,了解训练数据如何影响模型能力和其局限性。 为了推动语言模型预训练领域的开放研究,研究人员构建并公开了预训练数据集Dolma。 这是一个包含了从 7 种不同数据来源获取的3万亿个token的多样化、多源语料库。 这些数据源一方面在大规模语言模型预训练中常见,另一方面也能被普通大众所接触。 下表给出了来自各个数据源的数据量的概览。
Dolma的构建过程包括六个步骤:语言过滤、质量过滤、内容过滤、去重、多源混合和token化。 在整理和最终发布Dolma过程中,研究人员确保各数据源的文档保持独立。 他们还开源了一套高效的数据整理工具,这套工具能够帮助进一步研究Dolma、复制成果,并简化预训练语料库的整理工作。 此外,研究人员也开源了WIMBD工具,以助于数据集分析。

网络数据处理流程

代码处理流程 训练OLMo
分布式训练框架
研究人员利用PyTorch的FSDP框架和ZeRO优化器策略来训练模型。这种方法通过将模型的权重和它们对应的优化器状态在多个GPU中进行分割,从而有效减少了内存的使用量。 在处理高达7B规模的模型时,这项技术使研究人员能够在每个GPU上处理4096个token的微批大小,以实现更高效的训练。 对于OLMo-1B和7B模型,研究人员固定使用大约4M token(2048个数据实例,每个实例包含2048个token的序列)的全局批大小。 而对于目前正在训练中的OLMo-65B模型,研究人员采用了一个批大小预热策略,起始于大约2M token(1024个数据实例),之后每增加100B token,批大小翻倍,直至最终达到大约16M token(8192个数据实例)的规模。

为了加快模型训练的速度,研究人员采用了混合精度训练的技术,这一技术是通过FSDP的内部配置和PyTorch的amp模块来实现的。 这种方法特别设计,以确保一些关键的计算步骤(例如softmax函数)始终以最高精度执行,以保证训练过程的稳定性。 与此同时,其他大部分计算则使用一种称为bfloat16的半精度格式,以减少内存使用并提高计算效率。 在特定配置中,每个GPU上的模型权重和优化器状态都以最高精度保存。 只有在执行模型的前向传播和反向传播,即计算模型的输出和更新权重时,每个Transformer模块内的权重才会临时转换为bfloat16格式。 此外,各个GPU间同步梯度更新时,也会以最高精度进行,以确保训练质量。
优化器
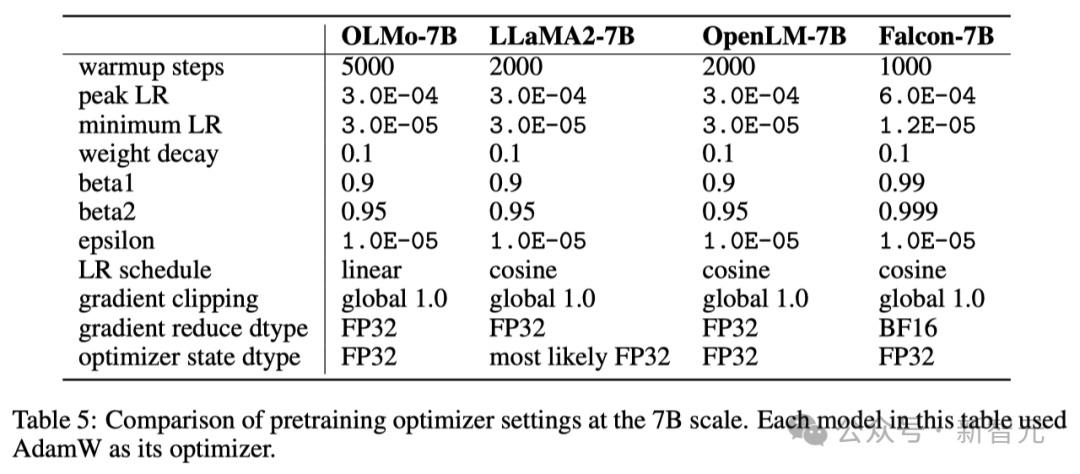
研究人员采用了AdamW优化器来调整模型参数。 无论模型规模大小如何,研究人员都会在训练初期的5000步(大约处理21B个token)内逐渐增加学习率,这一过程称为学习率预热。 预热结束后,学习率将按线性规律逐渐减少,直到降至最高学习率的十分之一。 此外,研究人员还会对模型参数的梯度进行裁剪,确保其总的 L1 范数不会超过 1.0。 在下表中,研究人员将自己在7B模型规模下的优化器配置与近期其他使用AdamW优化器的大型语言模型进行了对比。
数据集
研究人员利用开放数据集Dolma中的一个2T token的样本,构建了他们的训练数据集。 研究人员将每篇文档的token连接起来,每篇文档的末尾都会加上一个特殊的 EOS token,接着将这些 token 分成每组 2048 个,形成训练样本。 这些训练样本在每次训练时都会以同样的方式进行随机打乱。研究人员还提供了一些工具,使得任何人都可以复原每个训练批次的具体数据顺序和组成。 研究人员已经发布的所有模型至少都经过了一轮(2T token)的训练。其中一些模型还进行了额外的训练,即在数据上进行第二轮训练,但采用了不同的随机打乱顺序。 根据之前的研究,这样重复使用少量数据的影响是微乎其微的。
英伟达和AMD都要YES!
为了确保代码库能够同时在英伟达和AMD的GPU上都能高效运行,研究人员选择了两个不同的集群进行了模型训练测试: 利用LUMI超级计算机,研究人员部署了最多256个节点,每个节点搭载了4张AMD MI250X GPU,每张GPU 拥有128GB内存和800Gbps的数据传输速率。 通过MosaicML (Databricks) 的支持,研究人员使用了27个节点,每个节点配备了8张英伟达A100 GPU,每张GPU拥有40GB内存和800Gbps的数据传输速率。 虽然研究人员为了提高训练效率对批大小进行了微调,但在完成2T token的评估后,两个集群的性能几乎没有差异。
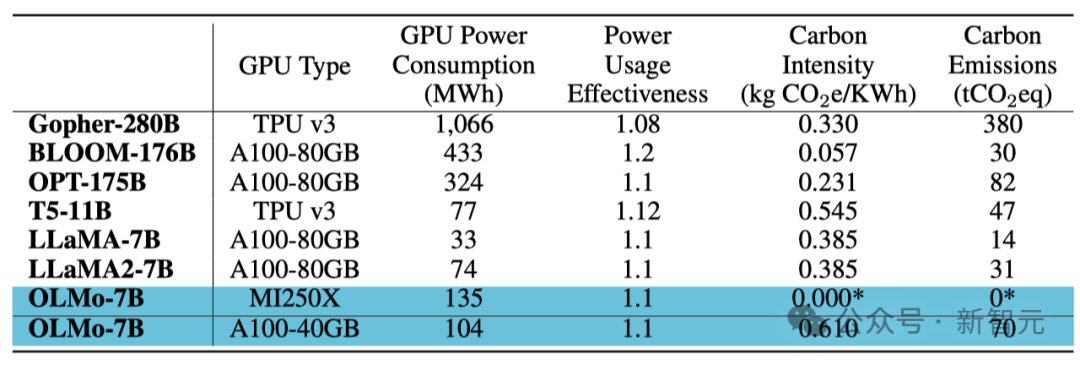
训练能耗 总结
与以往大多数仅仅提供模型权重和推理代码的模型不同,研究人员开源了OLMo的全部内容,包括训练数据、训练和评估代码,以及训练日志、实验结果、重要发现以及Weights & Biases的记录等等。 此外,团队正在研究如何通过指令优化和不同类型的强化学习(RLHF)来改进OLMo。而这些微调代码、数据和经过微调后的模型也都会被开源。 研究人员致力于持续支持和发展OLMo及其框架,推动开放语言模型(LM)的发展,助力开放研究社区的发展。为此,研究人员计划引入更多不同规模的模型、多种模态、数据集、安全措施和评估方法,丰富OLMo家族。 他们希望通过今后持续进行的彻底开源工作,增强开源研究社区的力量,并引发新一轮的创新浪潮。 团队介绍
**
**
Yizhong Wang(王义中)

Yizhong Wang是华盛顿大学Paul G. Allen计算机科学与工程学院的博士生,导师是Hannaneh Hajishirzi和Noah Smith。同时,也是艾伦人工智能研究所的兼职研究实习生。 此前,他曾在Meta AI、微软研究院和百度NLP进行实习。此前,他在北京大学获得了硕士学位,在上海交通大学获得了学士学位。 他的研究方向是自然语言处理(Natural Language Processing)、机器学习(Machine Learning),以及大语言模型(LLM)。
- LLM的适应性:如何更有效地构建和评估能够跟随指令的模型?在微调这些模型时,我们应该考虑哪些因素,它们又如何影响到模型的通用性?哪种类型的监督方式既有效又能扩展?
- LLM的持续学习:预训练和微调之间的界限在哪里?有哪些架构和学习策略能够让LLM在预训练之后继续进化?模型内部已有的知识如何与新学的知识相互作用?
- 大规模合成数据的应用:在生成模型迅速产生数据的今天,这些数据对我们的模型开发乃至整个互联网和社会有何影响?我们如何确保能够在大规模下生成多样且高质量的数据?我们能否区分这些数据与人类生成的数据?
Yuling Gu

Yuling Gu是艾伦人工智能研究所(AI2)Aristo团队的一位研究员。 2020年,她在纽约大学(NYU)获得学士学位。除了主修的计算机科学外,她还辅修了一个跨学科专业——语言与心智,这个专业结合了语言学、心理学和哲学。随后,她在华盛顿大学(UW)获得了硕士学位。 她对机器学习的技术和认知科学的理论的融合应用充满了热情。参考资料:https://allenai.org/olmo/olmo-paper.pdf

